기간/데이터 쉬프트 (shift)
shift메서드는 시계열 데이터의 데이터나 인덱스를 원하는 기간만큼 쉬프트 하는 메서드 입니다.
freq 인수를 입력하지 않으면 데이터가 이동하고, 인수값을 입력하게되면 인덱스가 freq값 만큼 이동하게됩니다.
사용법
df.shift(periods=1, freq=None, axis=0, fill_value=NoDefault.no_default)
periods: 이동할 기간입니다.
freq: 입력 할 경우 인덱스가 이동하게 됩니다. Y, M, D, H, T, S 나 Timestamp, 'Infer'등이 올 수 있습니다.
fill_value: shift로 인해 생긴 결측치를 대체할 값입니다.
먼저 기본적인 사용법 예시를위하여 5x3 짜리 데이터를 만들어보겠습니다.
pd.date_range를 이용해 기준시간에 대해 일정 간격을 가진 datetime index를 생성하겠습니다.
idx = pd.date_range(start='2022-01-01',periods=5,freq='2D')
# 2일 간격으로 5행의 인덱스 생성
data={'col1':[10,20,30,40,50],'col2':[1,3,6,7,9],'col3':[43,13,82,47,31]}
df = pd.DataFrame(data=data, index=idx)
print(df)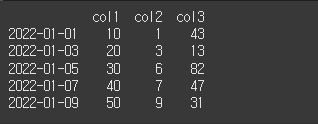
기본적인 사용법
period 인수를 입력할 경우 데이터가 행 기준으로 이동하게됩니다.
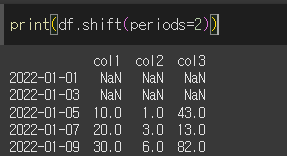
axis인수를 설정해줄 경우, 데이터의 이동을 행 기준으로할지 열 기준으로할지 설정할 수 있습니다.
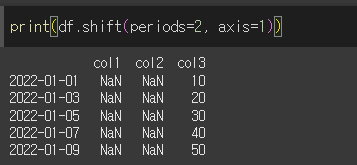
fill_value 인수를 사용하면, shift되면서 NaN처리된 결측치를 원하는 값으로 채울 수 있습니다.
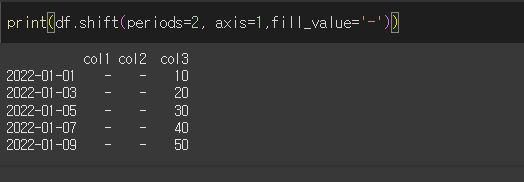
freq 인수의 사용
freq 인수를 설정해주면, 데이터가 아닌 인덱스가 freq에 입력한 값 만큼 쉬프트 됩니다.
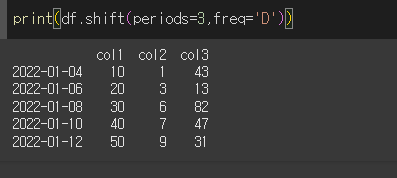
freq='infer'인 경우, 현재 인덱스의 간격을 분석해서 적당한 freq를 추론해줍니다.
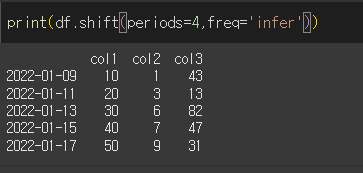
위의 예시의 경우, 인덱스의 인터벌(간격)이 2일이므로 freq='2D'로 추론하였으며, period=4이기 때문에 8일이 쉬프트 된것을 알 수 있습니다.
period로 변환 (to_period)
to_period 메서드는 DatetimeIndex를 PeriodIndex로 변환하는 메서드 입니다.
DatetimeIndex : 년, 월, 일, 시, 분, 초 다 표기
사용법
df.to_period(freq=None, axis=0, copy=True)
freq: 원하는 시간 단위로 변환할 수 있습니다.
axis: 변환할 기준 축 입니다.
copy: 사본을 형성할지 여부입니다.
먼저 기본적인 사용법 예시를위하여 DatetimeIndex 만들어 보겠습니다.
idx = pd.date_range(start='2021-08-01',periods=5,freq='45D') # 45일 간격 인덱스
>>
DatetimeIndex(['2021-08-01', '2021-09-15', '2021-10-30', '2021-12-14',
'2022-01-28'],
dtype='datetime64[ns]', freq='45D') # 형식은 datetime64
기본적인 사용법
freq값을 지정하여 원하는 시간간격으로 출력이 가능합니다.
freq="Y"(년도만 표기)

freq="M"(달도 표기)

freq="W"(주 표기)
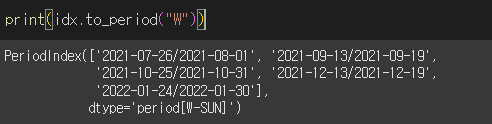
freq="H"(시간도 표기)

하위분류반환 (xs)
xs는 멀티인덱스 객체에 대해서 하위 분류를 출력하는 메서드입니다.
사용법
df.xs(key, axis=0, level=None, drop_level=True)
key: 분류의 기준이 되는 값입니다. Multi Index의 값을 지정합니다.
axis: 하위 분류 출력의 기준이되는 축을 지정합니다.
level: 멀티인덱스에 키가 부분적으로 포함되어있는경우, 레벨 지정을 통해 분류할 수 있습니다.
drop_level: 기본값은 True로 필터링하는 값을 제외하고 하위 분류만 출력합니다. False면 필터링하는 값이 있는 분류까지 출력합니다.
먼저 기본적인 사용법 예시를위하여 멀티인덱스 데이터를 만들어보겠습니다.
data = {'col1':[0,1,2,3,4], 'col2':[5,6,7,8,9],
'level0':['A','A','A','B','B'],
'level1':['X','X','Y','Y','Z'],
'level2':['a','a','b','c','a']}
df = pd.DataFrame(data=data)
df = df.set_index(['level0', 'level1', 'level2'])
print(df)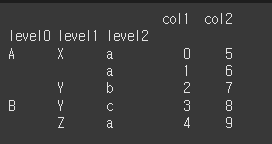
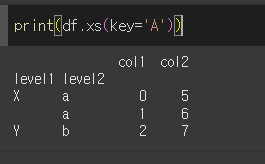
기본적인 사용법
기본적으로 key값을 지정하면 해당 값의 하위 분류를 출력합니다.
key값을 여러 값으로 지정할 수 도 있습니다.

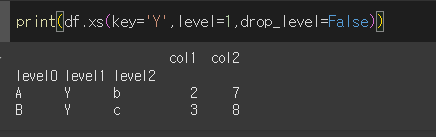
level을 지정하여 하위분류를 진행할 수 있습니다.

drop_level=Fale로 할 경우 key값으로 지정된 레벨을 포함해서 줄력합니다.
피벗화, 열의 인덱스화 (stack)
stack 메서드는 열을 피벗하여 하위 인덱스로 변환하는 메서드입니다.
df.stack(level=- 1, dropna=True)
level: MultiColumns의 경우 하위인덱스로 변환할 열의 레벨입니다. 기본값은 -1로 최하위 레벨이 선택됩니다.
dropna: {True / False} 기본값은 True로 피벗화로인해 생성된 하위인덱스의 모든 값이 결측치(NaN)인 경우 해당 열이 제거됩니다.
먼저 기본적인 사용법 예시를위하여 멀티인덱스 데이터를 만들어보겠습니다.
data = [[0,1,2,3],[4,5,6,7],[8,9,10,11],[12,13,14,15]]
idx = [['idx1','idx1','idx2','idx2'],['row1','row2','row3','row4']]
col = [['val1','val1','val2','val2'],['col1','col2','col3','col4']]
df = pd.DataFrame(data = data, index = idx, columns = col)
print(df)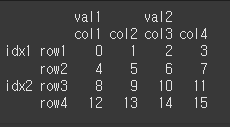
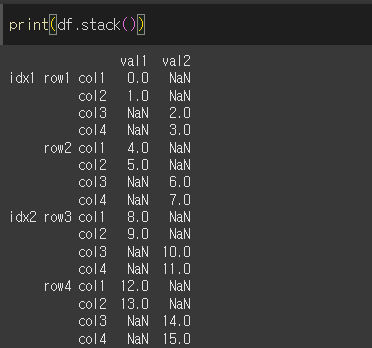
기본적인 사용법
'level'의 기본값은 '-1'로 최하위 레벨이 선택됩니다. 위 df에서는 level=1이 최하위 계층이기 때문에,
df.stack( ) = df.stack(level=1) 입니다. 함수 실행 시 level=1의 열이 인덱스로 피벗된걸 확인할 수 있습니다.
위 결과를 보면 최하위 레벨인
col1을 기준으로idx1,row1이면서col1인val1의 값은 0이고
col1을 기준으로idx1,row1,col1인val2의 값은 존재하지 않으므로NaN이 뜬다.
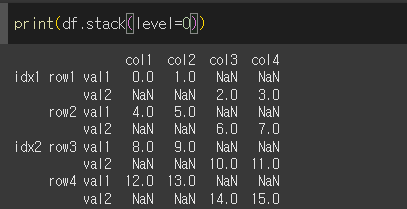
level=0인 경우 아래와같이 'val1', 'val2'가 포함된 level=0의 열이 피벗화 되는것을 볼 수 있습니다.
위 결과를 보면 레벨 0인
val1을 기준으로idx1,row1,val1인col1의 값은 0이고
val1을 기준으로idx1,row1,val1인col3의 값은 없으므로NaN이 뜬다.
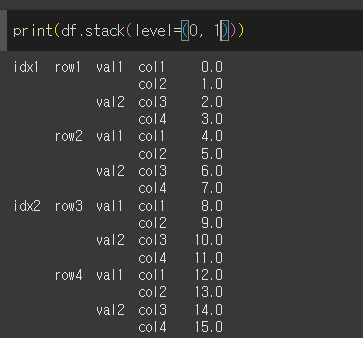
level=(0,1)처럼 튜플로 묶어줄 경우 해당되는 모든 계층에 대해 피벗화를 할 수 있습니다.
모든 계층(레벨)이 피벗화 될 경우 Serise 객체로 출력됩니다.
dropna인수의 사용
dropna인수는 기본값이 True로 열이 피벗화된 인덱스의 값이 NaN이면 해당 열을 출력하지 않습니다.
예시를 위해 간단한 2x2 짜리 데이터를 만들어보겠습니다.
data = [[np.nan,1],[2,3]]
idx = ['row1','row2']
col = ['col1','col2']
df = pd.DataFrame(data = data, index = idx, columns = col)
print(df)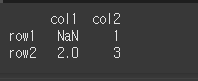
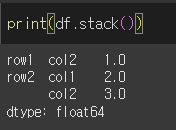
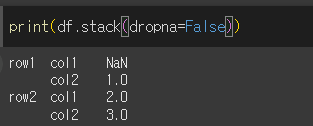
stack메서드를 사용할 경우 col1, col2 열이 인덱스로 피벗화되는데, row1-col1의 값은 NaN이기 때문에 제거되지만, Dropna를 False로 할 경우 제거 되지 않습니다.
언피벗화, 행의 열로 변환 (unstack)
unstack 메서드는 행을 언피벗하여 하위 열로 변환하는 메서드입니다.
df.unstack(level=- 1, fill_value=None)
level: MultiIndex의 경우 하위열로 변환할 행의 레벨입니다. 기본값은 -1로 최하위 레벨이 선택됩니다.
fill_value: 생성된 열의 값에 결측치가 있을 경우 대체할 값입니다.
먼저 기본적인 사용법 예시를위하여 멀티인덱스 데이터를 만들어보겠습니다.
data =[1,2,3,4,5]
idx = [['idx1','idx1','idx2','idx2','idx2'],['row1','row2','row1','row2','row3']]
df = pd.Series(data=data, index = idx)
print(df)
기본적인 사용법
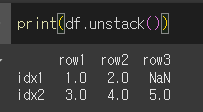
level은 기본값이 -1이며, 최하위 레벨의 행에 대해 열로 언피벗 합니다.
아래 예시를 보면 최 하위 계층인 row1,row2가 속한 인덱스가 열로 언피벗 된것을 확인할 수 있습니다.
fill_value 인수를 사용할 경우, 언피벗으로 인해 행성된 결측치를 특정 값으로 지정할 수 있습니다.
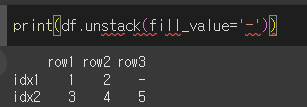
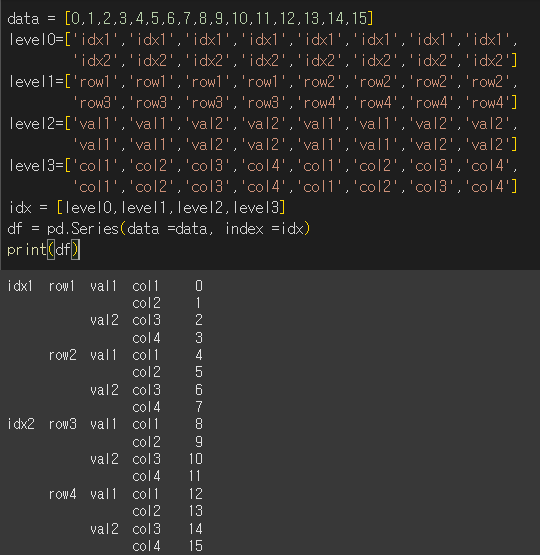
좀 더 큰 다중인덱스에 대해서 예시를 들어보기위해 4레벨의 멀티인덱스를 생성해보겠습니다.
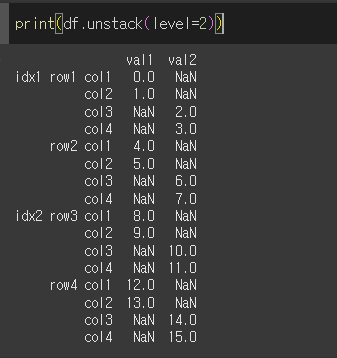
val1, val2가 속한 level=2로 unstack메서드를 실행해보겠습니다.
level에 튜플을 이용하여 Multi Columns로 unstack을 실행할 수 있습니다.

인덱스 순서변경 (swaplevel)
swaplevel메서드는 Multi Index (또는 Munti Columns)에서 두 인덱스의 순서를 변경하는 메서드입니다.
사용법
df..swaplevel(i=- 2, j=- 1, axis=0)
i , j: 순서를 변경할 두 인덱스의 레벨입니다. 기본적으로 제일 낮은 두 레벨의 인덱스가 교환됩니다.(-2, -1)
axis: 기본값은 0으로 axis=1로 변경할 경우 Multi Columns에 대해 메서드가 수행됩니다.
먼저 기본적인 사용법 예시를위하여 멀티인덱스 데이터를 만들어보겠습니다.
data = {'col':[0,1,2,3,4,5]}
level0 = ['idx1','idx1','idx1','idx1','idx2','idx2']
level1 = ['val1','val1','val2','val2','val3','val4']
level2 = ['row1','row2','row3','row4','row5','row6']
idx = [level0, level1, level2]
df = pd.DataFrame(data = data, index=idx)
print(df)

기본적인 사용법
i, j인수에 아무것도 입력하지 않는다면, 제일 낮은 두 레벨의 인덱스가 교환됩니다.
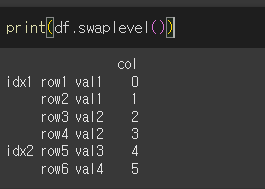
인수로 한 숫자만 입력하게되면, 가장 낮은 레벨의 인덱스와 인수로 입력한 숫자에 해당하는 레벨의 인덱스가 교환됩니다.
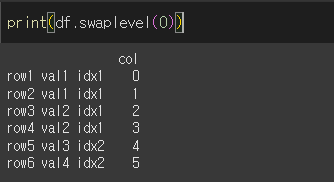
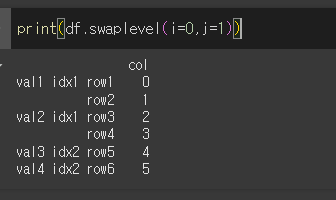
두 값을 지정하여 원하는 인덱스끼리의 교환이 가능합니다. 레벨명이 있다면 레벨명을 쓸 수도 있습니다.
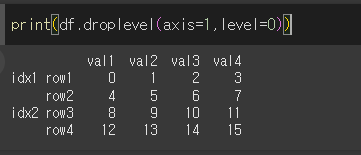
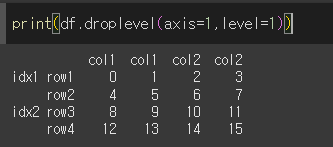
인덱스 제거 (droplevel)
droplevel 메서드는 Multi Index나 Multi Columns에서 특정 레벨을 제거하는 메서드입니다.
df.droplevel(level, axis=0)
level: 제거할 단계 입니다.
axis: 특정 레벨을 제거할 축 입니다.
먼저 기본적인 사용법 예시를위하여 멀티인덱스 데이터를 만들어보겠습니다.
data= [[0,1,2,3],[4,5,6,7],[8,9,10,11],[12,13,14,15]]
idx = [['idx1','idx1','idx2','idx2'],['row1','row2','row3','row4']]
col = [['col1','col1','col2','col2'],['val1','val2','val3','val4']]
df = pd.DataFrame(data=data, index = idx, columns = col)
print(df)
기본적인 사용법
level에 제거를 원하는 레벨을 입력함으로서 해당 레벨을 제거하여 값을 출력할 수 있습니다.
level=0인 경우 Multi Index의 level=0인 idx1, idx2가 제거된 것을 알 수 있습니다.
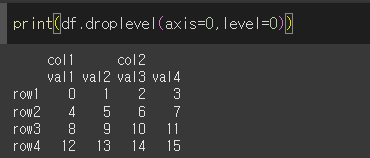
level=1인 경우 Multi Index의 level=1인 row1, row2, row3, row4가 제거된 것을 알 수 있습니다.

axis=1인 경우 Multi Columns에 대해서 특정 레벨을 제거 할 수 있습니다.