열 인덱스 반복자 반환 (iter)
_iter__ 메서드는 열 인덱스를 map 오브젝트 형태의 반복자(iterator)로 반환하는 메서드입니다.
사용법
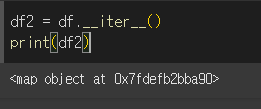
df.__iter__( )
먼저 기본적인 사용법 예시를위하여 2x2 짜리 데이터를 만들어 보겠습니다.
data = {'col1':[1,2],'col2':[3,4]}
df = pd.DataFrame(data = data)
print(df)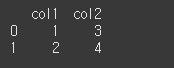
기본적인 사용법
기본적으로 df.__iter__( ) 형태로 사용하며, 열 인덱스의 map 오브젝트를 반환합니다.
map오브젝트는range함수처럼 하나씩 꺼내서 쓰는형태이기 때문에 단순 print로는 출력이 불가합니다.
반복자(iterator)이기 때문에next메서드를 통해 하나씩 확인할 수 있습니다.
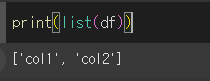
print(list(df)) # 이것으로 하나하나 주소를 옆으로 반환list 메서드를 이용하면 리스트 형태로 반환이 가능합니다.
열과 내용의 반복자 반환
(items, iteritems)items 메서드는 데이터의 열-행/데이터 정보를 튜플 형태의 generator 객체로 반환하는 메서드입니다. (열 이름, 내용의 Series객체) 형태로 반환하는데, Series객체는 행, 값 형태로 반환됩니다.
사용법
df.items()
먼저 기본적인 사용법 예시를위하여 2x2 짜리 데이터를 만들어 보겠습니다.
data = {'col1':[1,2],'col2':[3,4]}
idx = ['row1','row2']
df = pd.DataFrame(data = data, index=idx)
print(df)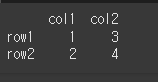
기본적인 사용법
기본적으로 df.items() 형태로 사용하며, 출력 시 generator 객체인 것을 확인 할 수 있습니다.
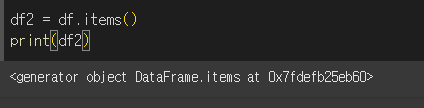
generator 역시 iterator(반복자) 로 for문이나 list로 내용을 확인 할 수 있습니다.
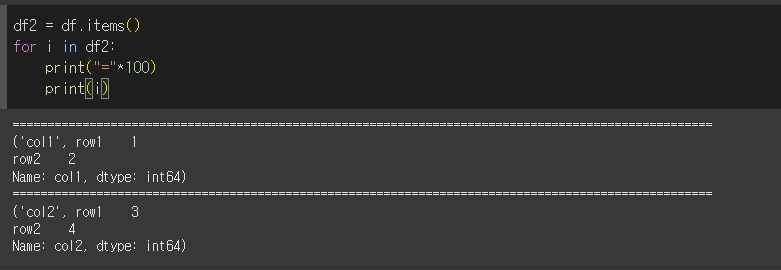
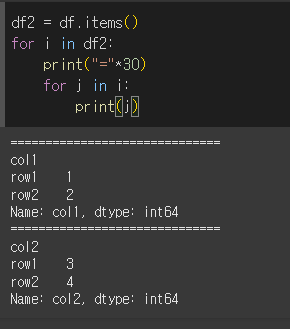
for문을 한번 더 사용해서 튜플의 내용을 한 줄마다 출력하면 보다 더 직관적으로 확인할 수 있습니다.
행과 내용의 반복자 반환 (iterrows)
iterrows 메서드는 데이터의 행-열/데이터 정보를 튜플 형태의 generator 객체로 반환하는 메서드입니다.
(행 이름, 내용의 Series객체) 형태로 반환하는데, Series객체는 열 - 값 형태로 반환됩니다.
사용법
df.iterrows()
먼저 기본적인 사용법 예시를위하여 2x2 짜리 데이터를 만들어 보겠습니다.
data = {'col1':[1,2],'col2':[3,4]}
idx = ['row1','row2']
df = pd.DataFrame(data = data, index=idx)
print(df)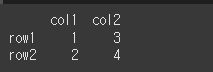
기본적인 사용법
기본적으로 df.iterrows() 형태로 사용하며, 출력 시 generator 객체인 것을 확인 할 수 있습니다.
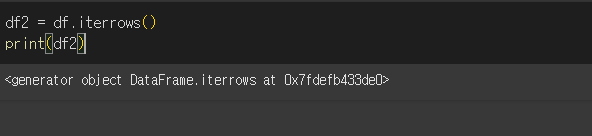
generator 역시 iterator(반복자) 로 for문이나 list로 내용을 확인 할 수 있습니다.
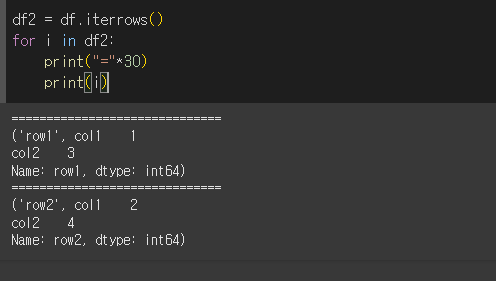
for문을 한번 더 사용해서 튜플의 내용을 한 줄마다 출력하면 보다 더 직관적으로 확인할 수 있습니다.
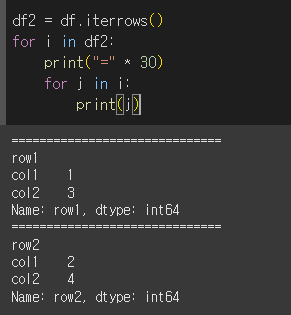
튜플형태 반복자 반환 (itertuples)
itertuples 메서드는 데이터의 인덱스, 열-값 정보를 map오브젝트의 튜플 형태로 반환하는 메서드입니다.
튜플은 name인수를 통해 원하는named tuple로 출력이 가능합니다.
사용법
df.itertuples(index=True, name='Pandas')
index: 인덱스를 출력할지 여부 입니다.
name: 출력하게 될 named tuple의 이름을 지정합니다. None으로 하면 일반 튜플로 출력되며 기본값은Pandas입니다.
먼저 기본적인 사용법 예시를위하여 2x2 짜리 데이터를 만들어 보겠습니다.
data = {'col1':[1,2],'col2':[3,4]}
idx = ['row1','row2']
df = pd.DataFrame(data = data, index=idx)
print(df)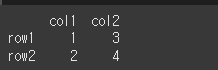
기본적인 사용법
df.itertuples() 형태로 사용가능하며 기본적으로 map 오브젝트로 반환하기 때문에, list, next, for문 등으로 확인이 가능합니다.
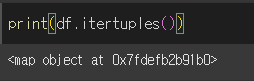
list를 이용해 출력해보면, 구성이 튜플(인덱스, 열=값, 열=값...) 형태인 것을 확인할 수 있습니다.

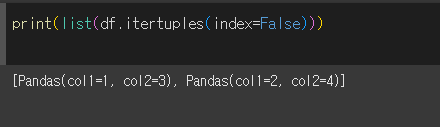
index인수의 사용
index=False로 입력할 경우 반환되는 튜플값에서 인덱스 정보가 제외됩니다.
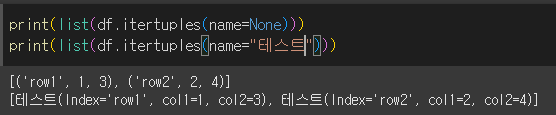
name인수의 사용
name인수를 지정해주면, 튜플이 namedtuple 형태로 반환됩니다. 기본값은 Pandas이며 None 입력시 일반 튜플로 반환합니다.
csv으로 변환 (to_csv)
to_csv 메서드는 데이터프레임 객체를 csv 형식으로 변환하는 메서드입니다.
사용법
path_or_buf: 저장할 경로 및 파일명
sep: 구분자 (기본값: ,)
na_rep: 결측값 표시 (기본값: '')
columns: 출력할 열 선택
header: 열 이름 출력 여부 (기본값: True)
index: 인덱스 출력 여부 (기본값: True)
mode: 파일 열기 모드 ('w' 새로 작성, 'a' 추가)
encoding: 파일 인코딩 (기본값: 'utf-8')
compression: 압축 형식 (gzip, zip, 등)
quoting: 인용 처리 옵션 (0, 1, 2, 3)
quotechar: 인용문자 (기본값: ")
chunksize: 한 번에 처리할 행 수
date_format: 날짜 형식 지정
decimal: 숫자 구분 기호 (기본값: .)
먼저 기본적인 사용법 예시를위하여 3x2 짜리 데이터를 만들어 보겠습니다.
data = [[1,np.NaN],['A',4.1],['-','3']]
df = pd.DataFrame(data)
address = 'C:\\Users\\lifcr\\OneDrive\\바탕 화면\\pandas\\' #기본 경로 설정해줌(코딩이 길어지므로)
기본적인 사용법
기본적으로 path_or_buf에 경로와 파일 이름을 지정해주면, 해당 경로에 df가 변환된 csv파일이 생성됩니다.
df.to_csv(path_or_buf=address+'test1.csv')
sep 인수의 사용
sep 인수는 csv파일의 구분자를 설정해 줍니다. 기본값은 쉼표(,)입니다.
df.to_csv(path_or_buf='test3.csv', sep='-')
na_rep인수의 사용
na_rep인수는 데이터의 결측값(NaN)을 어떤 값으로 출력할지를 지정할 수 있습니다.
df.to_csv(path_or_buf=address+'test3.csv', na_rep=100)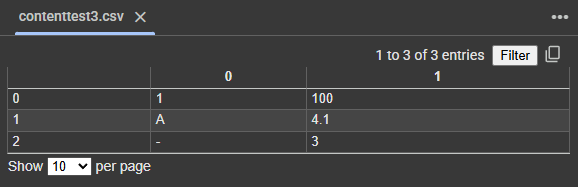
float_format 인수의 사용
float_format인수는 부동소수점 형식 데이터의 출력 포맷을 설정할 수 있습니다.
만약 값으로 그냥 string 형태의 값을 입력할 경우 해당 값이 출력됩니다.
df.to_csv(path_or_buf=address+'test4.csv', float_format='%.2f')
columns인수의 사용
columns인수는 출력할 대상 열을 지정하는 인수입니다. 따로 입력하지 않는경우 모든 열이 csv변환 됩니다.
df.to_csv(path_or_buf=address+'test5.csv', columns=[0]
header 인수의 사용
header인수는 열의 이름을 지정하는 인수입니다. False일 경우 열 이름을 출력하지 않습니다.
df.to_csv(path_or_buf=address+'test6.csv', header=['col1','col2'])
index인수의 사용
index인수는 인덱스의 출력 여부를 지정할 수 있습니다. 기본값은 True 입니다.
df.to_csv(path_or_buf=address+'test7.csv', index=False) 
index_label인수의 사용
index_lable인수는 출력되는 csv파일의 인덱스명을 지정하는 인수 입니다.
df.to_csv(path_or_buf=address+'test8.csv', index_label=['index'])
mode 인수의 사용
mode 인수는 기본값이 w로 기존 데이터에 새 데이터를 덮어씌웁니다. mode='a'인 경우 기존 데이터 아래에 새 데이터를 추가해서 입력합니다.
df.to_csv(path_or_buf=address+'test9.csv', mode='w')
df2 = pd.DataFrame(data=[[7,8],[9,10]],index=[3,4])
df2.to_csv(path_or_buf=address+'test9.csv', mode='a')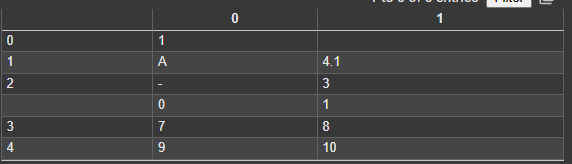
이렇게 단순히 추가하는경우 열 이름이 새로 추가되기 때문에, 보기에 깔끔하지 않습니다. 이경우 header=False하여 새로 추가하는 데이터의 열 이름을 삭제해서 깔끔하게 합치는것이 가능합니다.
df.to_csv(path_or_buf=address+'test10.csv', mode='w')
df2.to_csv(path_or_buf=address+'test10.csv', mode='a',header=False)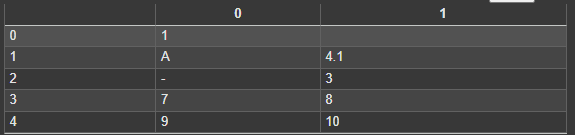
excel로 변환 (to_excel)
Adress를 지정하지 않을 경우 기본 Adress로 지정이 된다.
사용법
excel_writer: 저장할 경로와 파일명, 또는 ExcelWriter 객체
sheet_name: 시트 이름 (기본값: 'Sheet1'), 중복 시 덮어씀
na_rep: 결측치 대체 값 (기본값: ' ' 공백)
float_format: 부동소수점 숫자의 표현 형식
columns: 저장할 열 선택
header: 열 이름 출력 여부 (None이면 열 이름 안 출력)
index: 인덱스 출력 여부 (True 기본값)
index_label: 인덱스 이름 지정 (MultiIndex는 리스트 형식)
startrow/startcol: 데이터 입력 시작 위치 (행, 열)
engine: 사용할 엔진 지정 ('openpyxl', 'xlsxwriter', 등)
merge_cells: 중복된 인덱스를 병합할지 여부 (기본값: True)
encoding: 엑셀 파일의 인코딩 (xlwt에만 필요)
inf_rep: 무한 값 처리 방식 ('inf' 기본값)
verbose: 오류 로그에 추가 정보 표시 여부 (기본값: True)
freeze_panes: 틀 고정 위치 지정 (튜플로 (row, col))
storage_options: 특정 스토리지 연결을 위한 추가 옵션
먼저 기본적인 사용법 예시를위하여 3x2 데이터 하나와 Multi Index 데이터 하나를 만들어 보겠습니다.
data1 = [[1,np.nan],['A',4.1],[math.inf,'3']]
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data=[[5,6],[7,8],[9,10]],index=[['A','B','B'],[3,4,5]]) #멀티인덱스 객체
print(df1)
print(df2)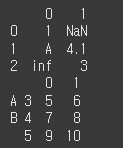
기본적인 사용법
기본적으로는 excel_writer에 단순히 경로를 지정하는것 만으로 엑셀로의 변환이 실행됩니다.
df1.to_excel(excel_writer=adress+'test1.xlsx')
sheet_name 인수의 사용
sheet_name인수를 통해 데이터가 변환되는 엑셀의 시트명을 지정할 수 있습니다.
df1.to_excel(excel_writer='test2.xlsx',sheet_name='test_sheet')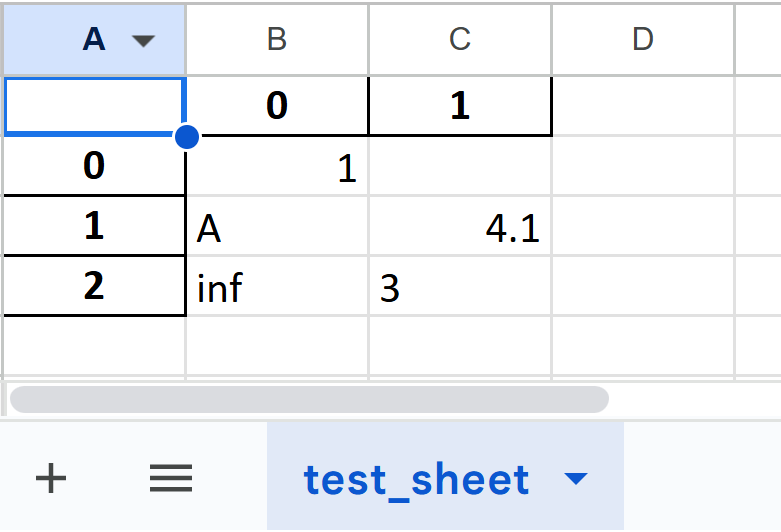
여러 시트에 데이터를 적용하고자 할 경우 ExcelWriter 객체로 writer를 지정해 입력하면 됩니다.
with pd.ExcelWriter('test3.xlsx') as writer:
df1.to_excel(writer, sheet_name='test_sheet_1')
df2.to_excel(writer, sheet_name='test_sheet_2')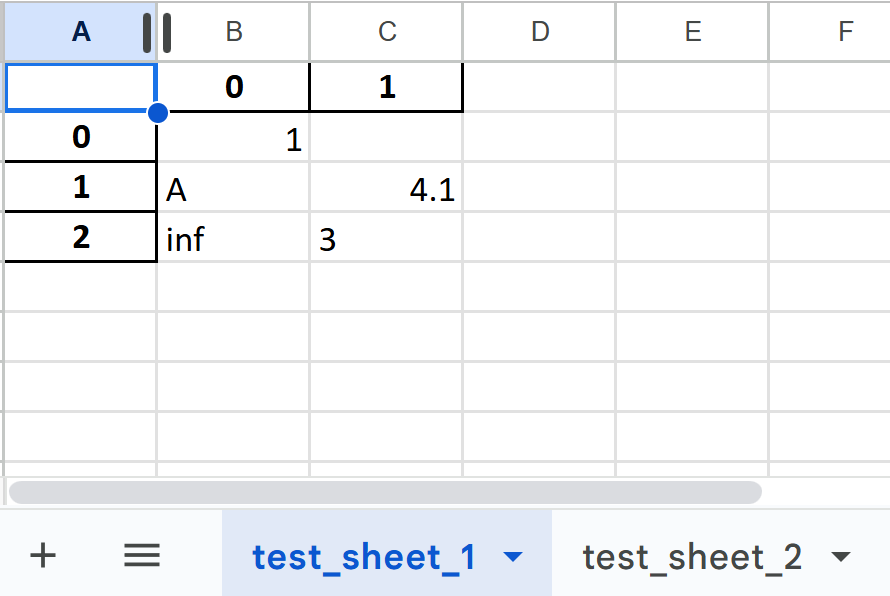
na_rep 인수의 사용
na_rep 인수를 통해 결측치를 대체할 값을 지정할 수 있습니다. 기본값은 공백(" ")입니다.
df1.to_excel(excel_writer='test4.xlsx',na_rep='BLANK')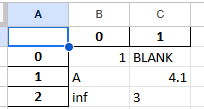
columns인수의 사용
columns인수를 통해 변환할 열을 따로 지정할 수 있습니다.
df1.to_excel(excel_writer='test6.xlsx',columns=[0])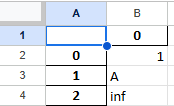
header 인수의 사용
header인수를 통해 변환될 데이터의 열 이름을 지정할 수 있습니다.
df1.to_excel(excel_writer='test7.xlsx',header=['col1','col2'])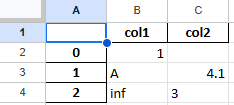
Index 인수의 사용
Index 인수를 통해 인덱스를 출력할지 여부를 지정할 수 있습니다. 기본값은 True로 인덱스를 출력합니다.
df1.to_excel(excel_writer='test8.xlsx', index=False)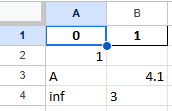
Index_label인수의 사용
Index_label 인수를 통해 인덱스명을 지정할 수 있습니다. Multi Index라면 리스트 형식으로 입력해주어야합니다.
df2.to_excel(excel_writer='test9.xlsx', index_label=['idx1','idx2'])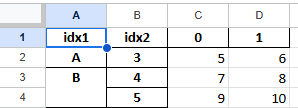
startrow / startcol 인수의 사용
startrow / startcol 인수는 엑셀 변환시 데이터의 위치를 지정하는 인수입니다. 양수를 입력할 경우 처음 시작위치에서 행의 경우 아래로, 열의 경우 우측으로 해당 숫자만큼 이동하여 변환됩니다.
df1.to_excel(excel_writer='test10.xlsx', startrow=2,startcol=4)
merge_cells인수의 사용
merge_cells의 기본값은 True로 인덱스에 중복값이 있을 경우 병합하여 출력합니다.
False인 경우 각각 인덱스가 그대로 출력됩니다.
merge_cells=True인 경우
df2.to_excel(excel_writer='test11_1.xlsx')
merge_cells=False인 경우df2.to_excel(excel_writer='test11_2.xlsx', merge_cells=False)
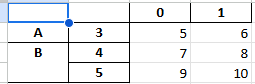
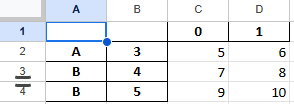
inf_rep 인수의 사용
inf_rep 인수는 무한 값의 엑셀 변화시 표현값을 지정합니다. 기본값은 inf입니다. (엑셀에는 무한값에 대한 기본 표현값이 없습니다.)
df1.to_excel(excel_writer='test12.xlsx', inf_rep='∞')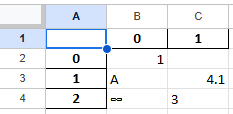
freeze_panes인수의 사용
freeze_panes인수의 값을 튜플로 입력함으로써 해당 (행,열) 기준으로 틀고정을 설정할 수 있습니다.
df1.to_excel(excel_writer='test13.xlsx', freeze_panes=(1,1))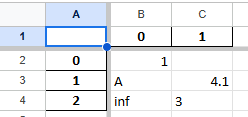
클립보드에 저장 (to_clipboard)
to_clipboard 메서드는 데이터를 클립보드에 저장하도록 하는 메서드입니다.
사용법
df.to_clipboard(excel=True, sep=None, kwargs)
excel: 엑셀에 붙여넣기 하기 쉽도록 데이터를 csv형태로 클립보드에 저장할지 여부입니다.
sep: csv형태로 클립보드에 저장 할때 구분자를 지정합니다.
kwargs: csv형태로 클립보드에 저장하기때문에, kwargs에 to_csv에서 사용하는 인수를 그대로 사용할 수 있습니다.
먼저 기본적인 사용법 예시를위하여 3x2 데이터를 만들어 보겠습니다.
df = pd.DataFrame([[1,np.nan],['A',4.1],[math.inf,'3']])
print(df)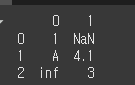
기본적인 사용법
기본적으로 메서드를 사용하면 데이터의 값이 csv 형태로 클립보드에 저장되게 됩니다.
