plotting기초 (plot)
plot 메서드는 matplotlib 라이브러리를 이용해 dataframe 객체를 시각화 하는 메서드 입니다.
사용법
df.plot(args, kwargs)
자세한 다른 함수의 설명은 실습
먼저 기본적인 사용법 예시를위하여 두가지 데이터를 만들어 보겠습니다.
df는 0~100까지의 x축 값을 갖는 sin 값 tan 값의 데이터 입니다.
val = np.linspace(0,100,101)
sin = np.sin(np.pi/25*val)
tan = np.tan(np.pi/25*val)
df = pd.DataFrame(data={'val':val,'sin':sin,'tan':tan})
print(df)
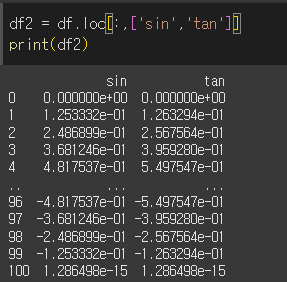
df2는 df에서 sin, tan값만 추려낸 데이터 입니다.
기본적인 사용법
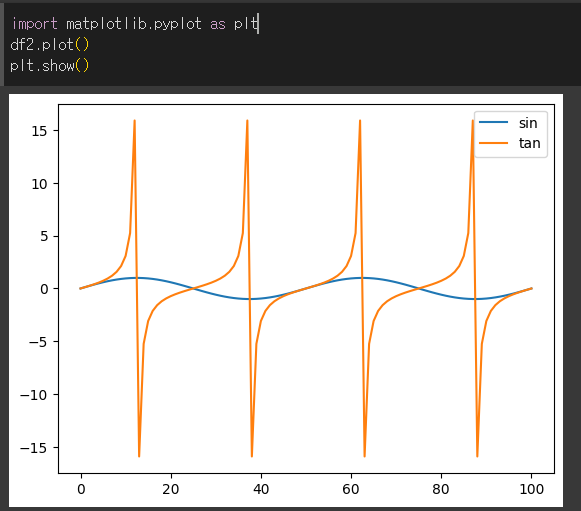
기본 적인 사용법은 df.plot() 형태 입니다. line 형태로 모든 열을 plot하게 됩니다.
sin, tan 그래프가 출력됨
kind, x, y 인수의 사용
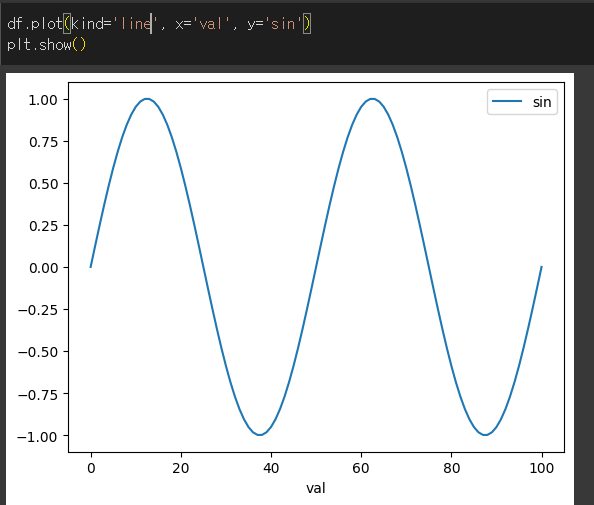
kind인수를 통해 원하는 형태의 그래프를 출력 할 수 있으며, x와 y로 해당 그래프의 x와 y를 지정할 수 있습니다.
종류 : {line / bar / barh / hist / box / kde / density / area / pie / scatter / hexbin}
kind값을 다양하게 수정하면서 다양한 그래프의 모습을 볼 수 있다.
x축의 값은 0~100, y축의 값은 sin값으로 line 을 plot한 것을 확인할 수 있다.
ax 인수의 사용
ax인수를 통해 현재 axes값을 별도의 값으로 지정하여 plot에 사용할 수 있습니다.
각각의 ax로 구분한 Axes를 2칸짜리 subplot에 배열하여 plot한것을 확인 할 수 있다.
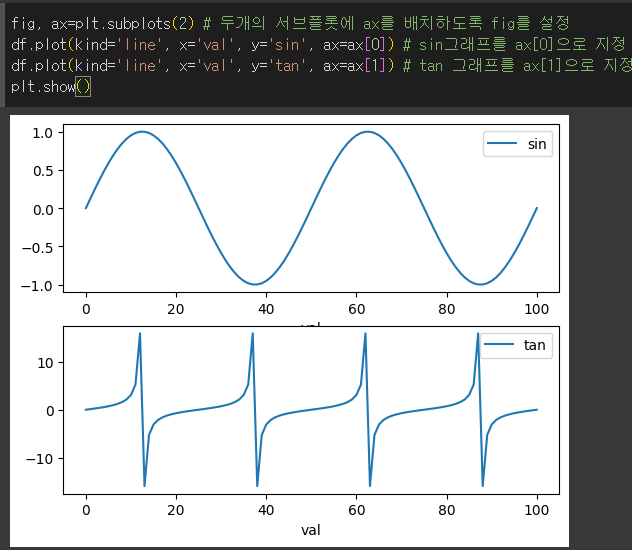
subplots 인수의 사용
subplots인수를 사용할 경우 각각의 열을 별도의 axes로 하여 subplot를 생성합니다.
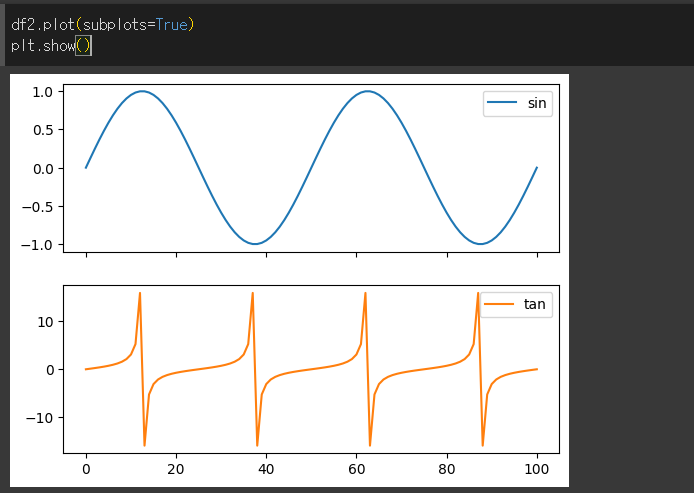
sharex / sharey 인수의 사용
subplot을 이용할 경우 두 Axes의 x축이나 y축값을 맞출 수 있습니다.
이때 공유된 축의 경우 한쪽은 보이지 않게 됩니다.
sharex의 기본값은 True로 x축은 맞추게 되고, sharey의 기본값은 False로 y축은 별도로 출력하는것이 기본입니다.
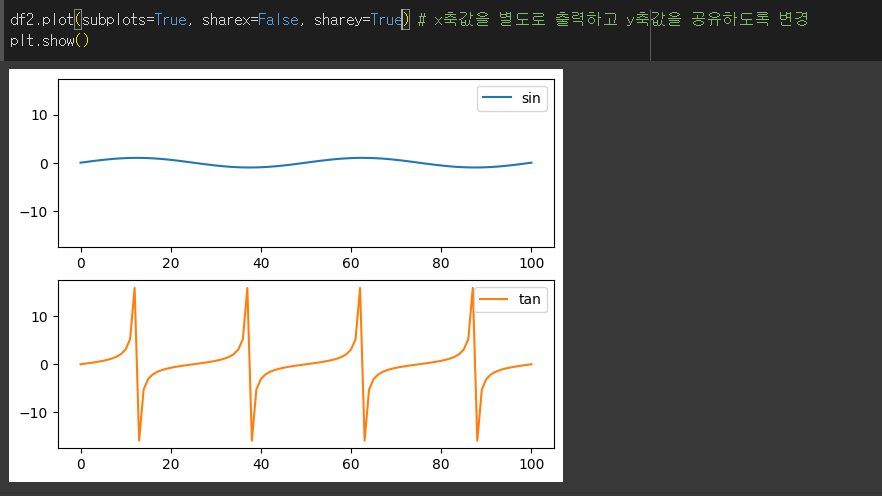
layout인수의 사용
layout인수를 이용하여 subplot의 배열을 설정할 수 있습니다. 튜플 형태로 값을 입력합니다.
figsize인수의 사용
figsize 인수를 이용해서 figure의 크기를 지정할 수 있습니다. 단위는 inch입니다.
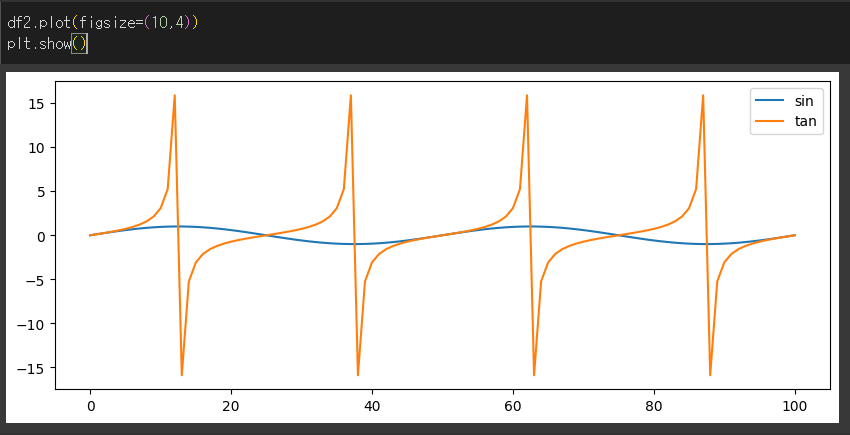
title / grid 인수의 사용
title인수는 figure의 제목을 설정하고, grid인수는 격자 출력 여부를 설정할 수 있습니다.
격자 설정, 제목 추가
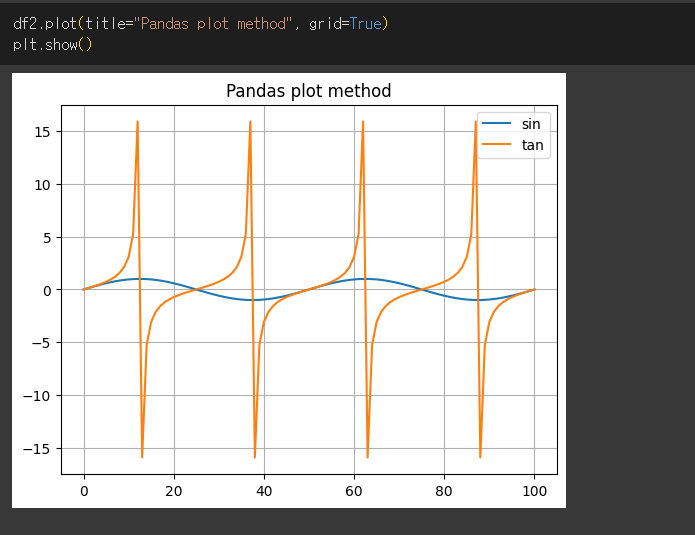
linestyle 인수의 사용
linestyle 인수를 지정하여 출력되는 그래프의 선 스타일을 지정할 수 있습니다.
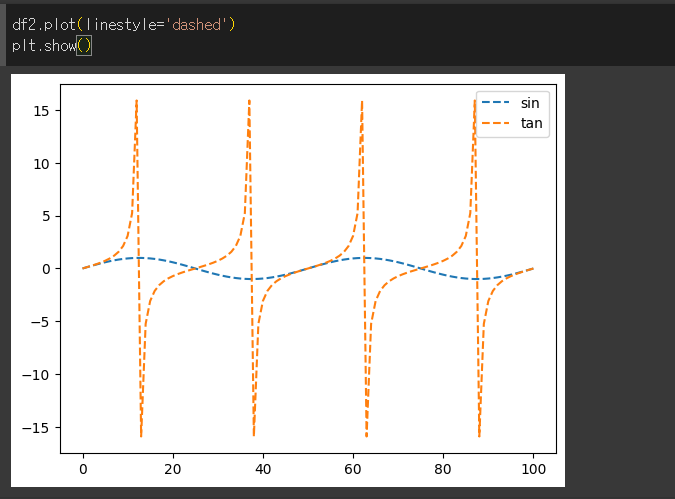
logx / logy / loglog인수의 사용
logs / logy / loglog인수를 이용해 각 축의 표시형식을 log스케일로 변경할 수 있습니다.
loglog인수는 모든 축의 값을 로그스케일로 변경합니다.
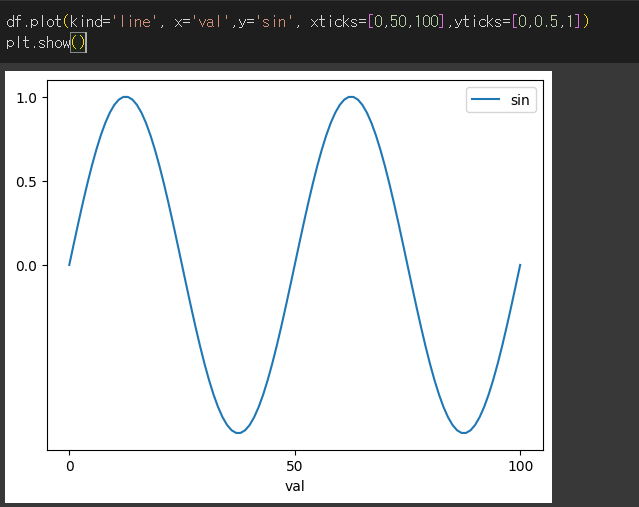
xticks / yticks 인수의 사용
xticks / yticks 인수에 리스트 형태의 값을 입력하여 특정 눈금의 값을 출력할 수 있습니다.
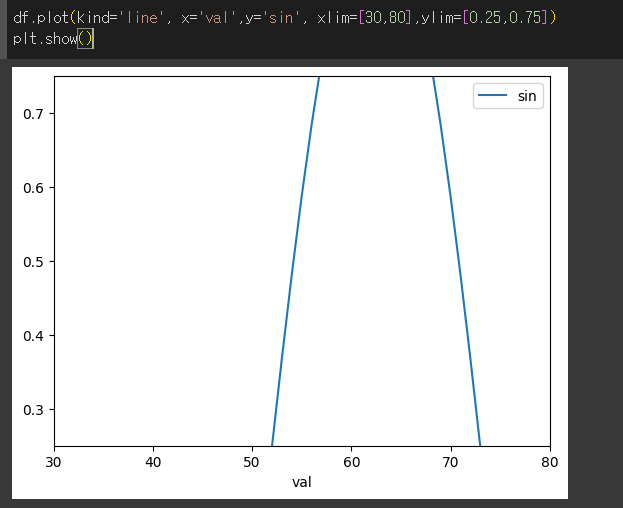
xlim / ylim 인수의 사용
xlim / ylim 인수를 사용해 그래프의 출력 범위를 지정할 수 있습니다.
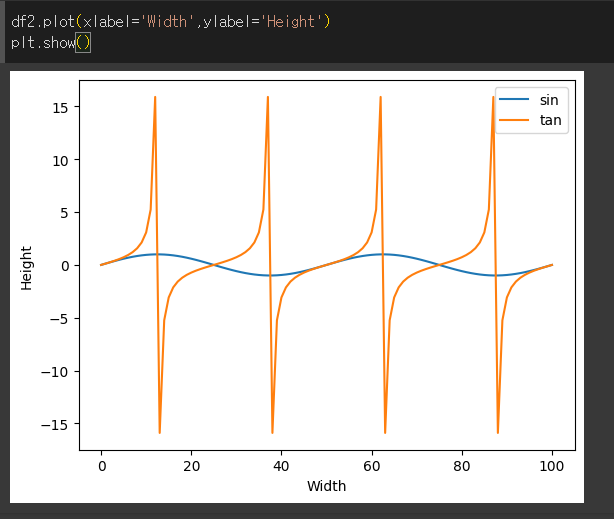
xlabel / ylabel 인수의 사용
xlabel / ylabel 인수를 사용해 각 축의 라벨을 출력할 수 있습니다.
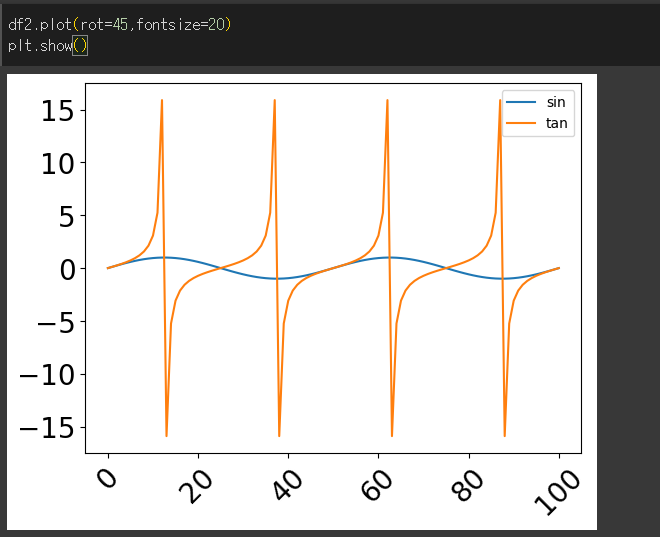
rot / fontsize 인수의 사용
rot 인수를 이용해 눈금값의 기울기를 지정할 수 있고, fontsize 인수를 통해 눈금값의 크기를 지정할 수 있습니다.
colormap / colorbar 인수의 사용
colormap 은 출력되는 그래프의 값을 특정 색 범위로 표현하는 matplotlib의 기능입니다. colorbar는 색에 해당하는 값의 범위를 막대 형태로 출력하는 기능입니다.
colorbar의 기본값은 True이기 때문에, False로 지정해주어야 출력이 안됩니다.
colorbar를 적용하기 위해서는, 각 값에 대해서 색을 지정해 주어야합니다. c인수에 색의 값을 지정하는 열을 입력하여 가능합니다.
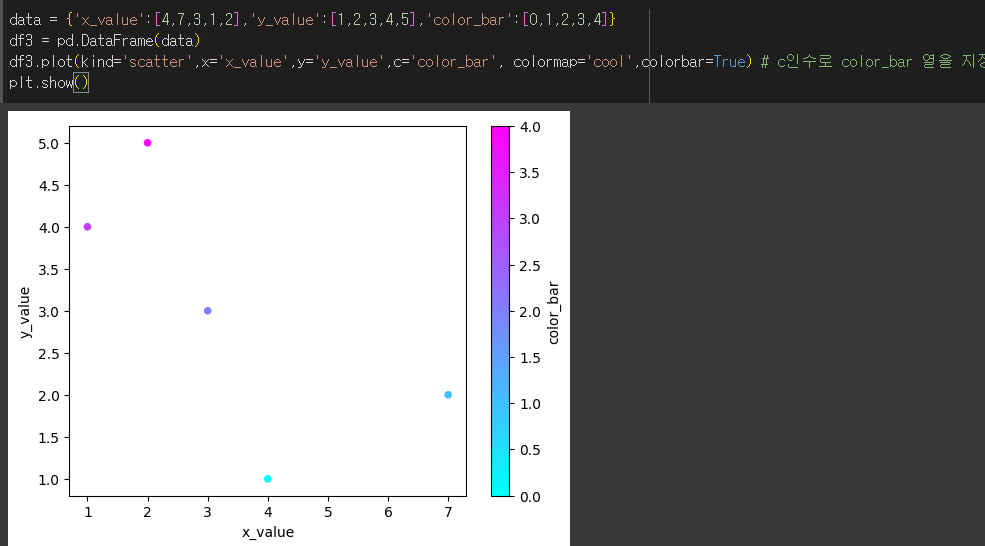
position 인수의 사용
position인수는 막대그래프 'bar / barh'에대해서 막대의 위치가 눈금의 위치 {좌측(0), 중(0.5), 우측(1)}를 지정할 수 있습니다
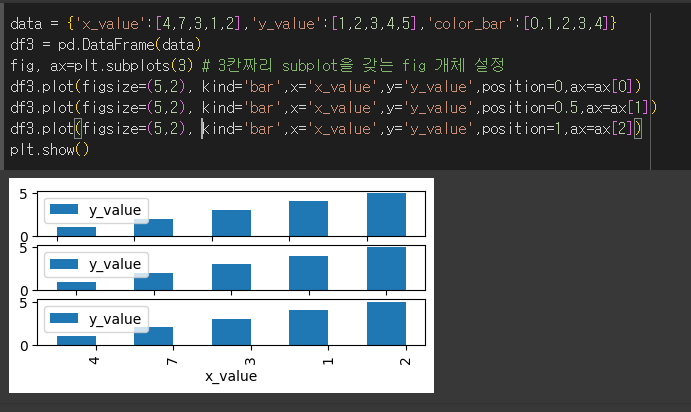
xerr / yerr인수의 사용
xerr / yerr인수는 특정 축을 기존그래프의 오차범위로 설정하는 인수 입니다.
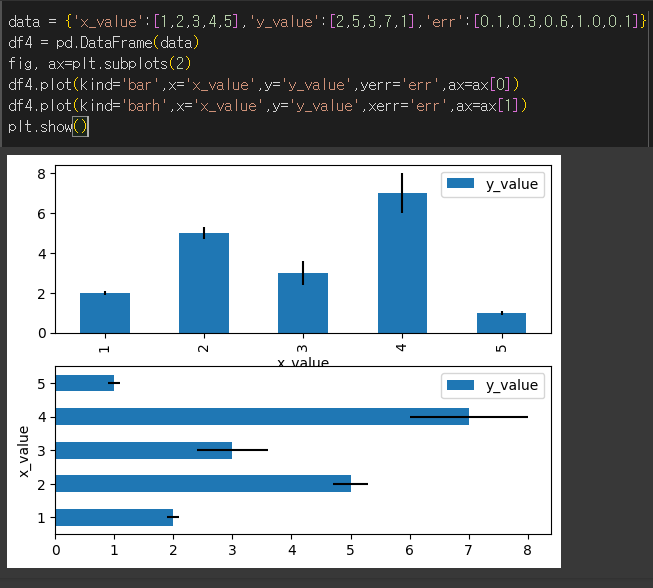
stacked 인수의 사용
막대그래프의 경우 값이 여러개라면 stacked인수를 통해 누적 막대그래프의 형태로 변환이 가능합니다.
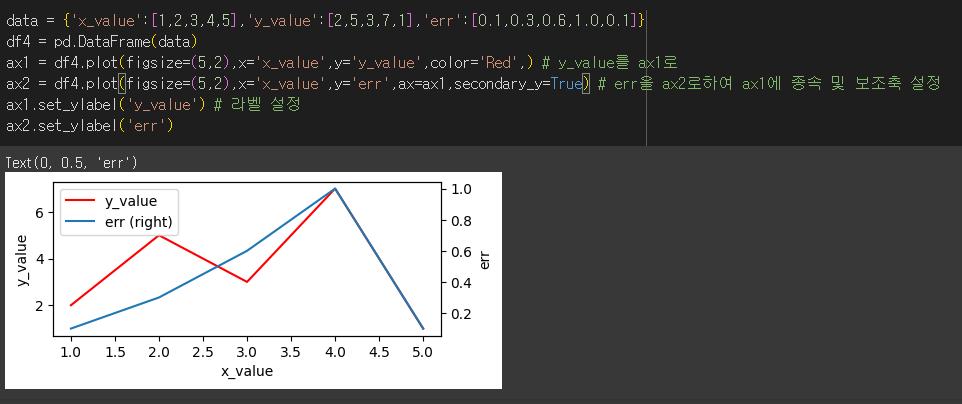
secondary_y 인수의 사용
두 그래프를 출력 할 경우 한 Axes를 다른 Axes에 종속시킴으로서 종속된 Axes를 secondary_y 인수를 이용해 보조 축으로 표현할 수 있습니다.
x,y축 지정 (area / bar / barh / line)
plot.[area / bar / barh / line] 메서드는 pandas에서 지원하는 matplotlib
메서드 중에서 x축 / y축(값) 에 해당되는 열을 입력하여야 하는 메서드 입니다.
기본적으로 df.plot.(kind = [area / bar / barh / line], x=x축, y=y축(값))과 완벽히 동일합니다.
사용법
df.plot.[area / bar / barh / line].(x, y, kwargs)
x / y: 각 축으로 설정할 값(컬럼명) 입니다.
kwargs: 그 외에 matplotlib 중 plot에서 지원하는 인수의 사용이 가능합니다.
먼저 기본적인 사용법 예시를위하여 데이터를 만들어 보겠습니다.
df는 0~100까지의 x축 값을 갖는 sin 값 cos값에 1을 더한 데이터 입니다.
val = np.linspace(0,100,101)
sin = np.sin(np.pi/25*val)+1
cos = np.cos(np.pi/25*val)+1
df = pd.DataFrame(data={'val':val,'sin+1':sin,'cos+1':cos})
print(df)
기본적인 사용법
plot.[area / bar / barh / line] 메서드는 반드시 x축과 y축(값)을 지정해주어야 합니다.
area메서드의 사용
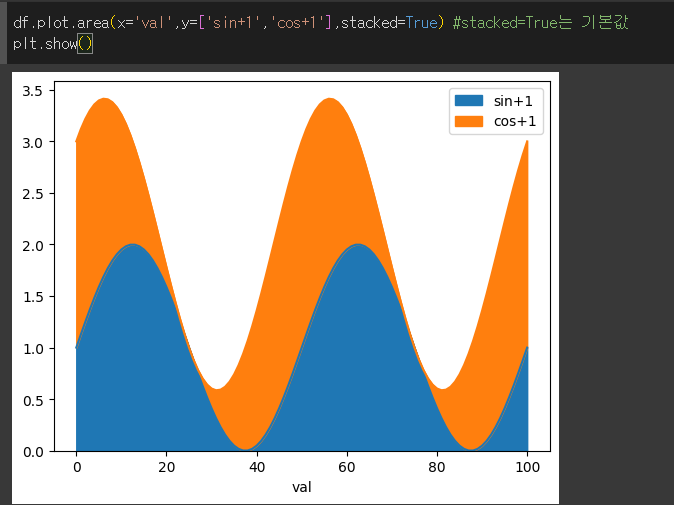
plot.area 메서드는 데이터를 면적 그래프의 형태로 반환합니다. 기본적으로 stacked=True 이므로, 면적이 누적되는 형태로 출력됩니다.
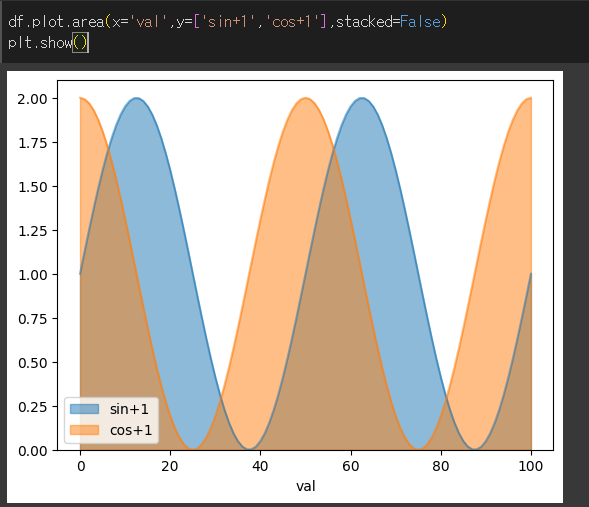
stacked=False인 경우 면적이 겹치는것을 시각화 하여 보여줍니다.
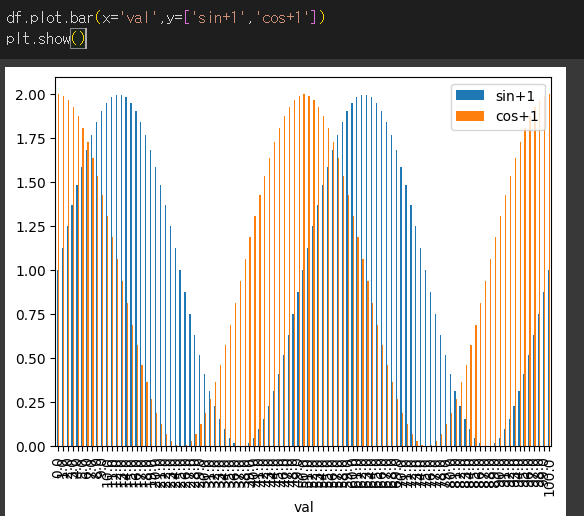
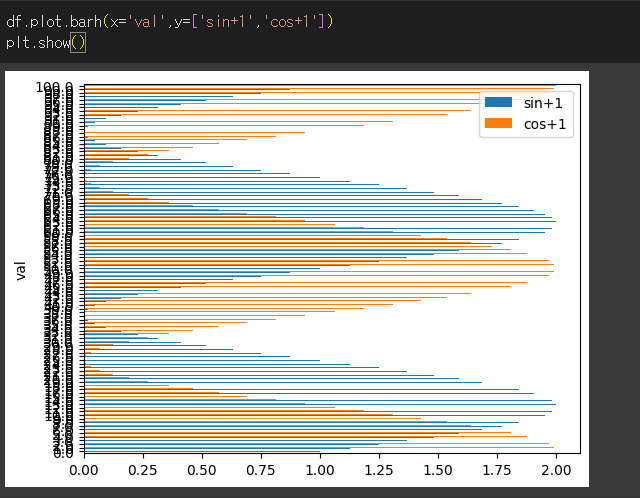
bar / barh 메서드의 사용
plot.bar / plot.barh는 각각 세로 막대그래프, 가로 막대 그래프를 반환합니다.
line 메서드의 사용
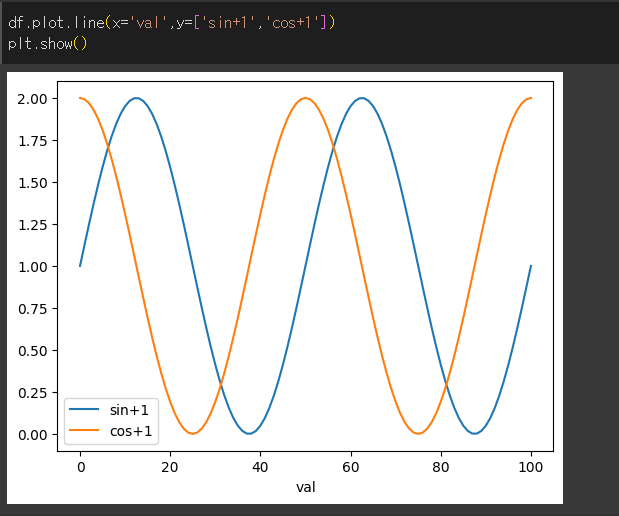
plot.line 메서드는 선형 그래프를 반환합니다.
x,y축, c값 지정 (hexbin / scatter)
plot.[hexbin / scatter] 메서드는 pandas에서 지원하는 matplotlib 메서드 중에서 x축 / y축(값) /c (colorbar status) 에 해당되는 열을 입력하여야 하는 메서드 입니다.
기본적으로 df.plot.(kind =[hexbin / scatter], x=x축, y=y축(값)), c=c값(colorbar status)과 완벽히 동일합니다.
사용법
df.plot.[hexbin / scatter].(x, y, c, kwargs)
x / y: 각 축으로 설정할 값(컬럼명) 입니다.
c: 각 값에 대한 colorbar의 값을 지정할 수 있습니다.
kwargs: 그 외에 matplotlib 중 plot에서 지원하는 인수의 사용이 가능합니다.
먼저 기본적인 사용법 예시를위하여 데이터를 만들어 보겠습니다.
df는 크기 10000짜리 가우시안 표준 정규분포 x와 y, 그리고 0~10까지의 난수를 갖는 1000개짜리 c열 의 데이터입니다.
df = pd.DataFrame({'x':np.random.randn(10000),
'y':np.random.randn(10000),
'c':np.random.randint(0,10,size=10000)})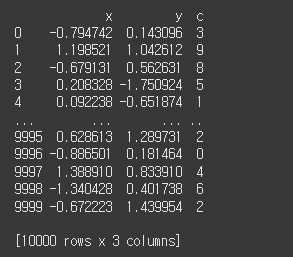
기본적인 사용법
plot.[hexbin / scatter]] 메서드는 반드시 x축과 y축(값)을 지정해주어야 합니다. (colormap은 자동으로 지정되며, c는 선택)
hexbin메서드의 사용
hexbin 메서드는 육각형의 그리드형태로 값을 반환하는 그래프 입니다. gridsize 인수 는 x축 기준 그리드 한칸의 크기를 의미합니다.
colormap 인수는 자동 지정되나, 원하는 colormap으로 지정이 가능합니다.
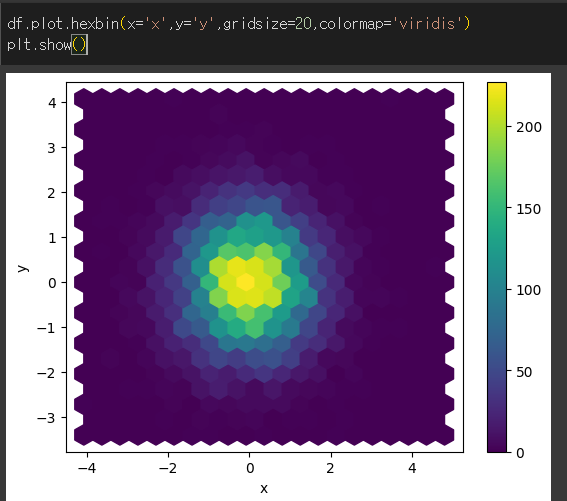
C 인수의 사용
C 인수를 통해 colormap 기준으로 각 값이 colorbar에서 어떤 값을 취할지 지정할 수 있습니다.
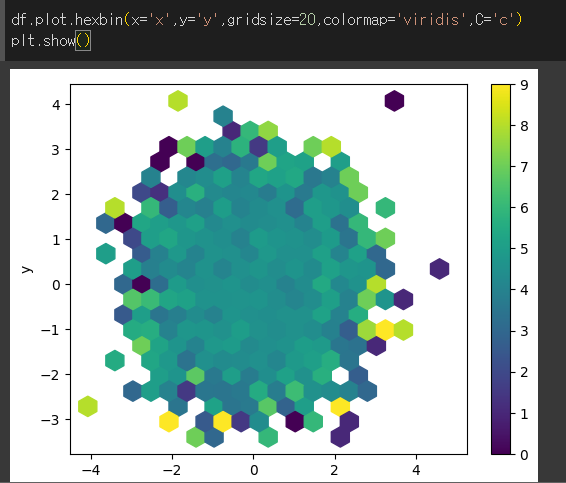
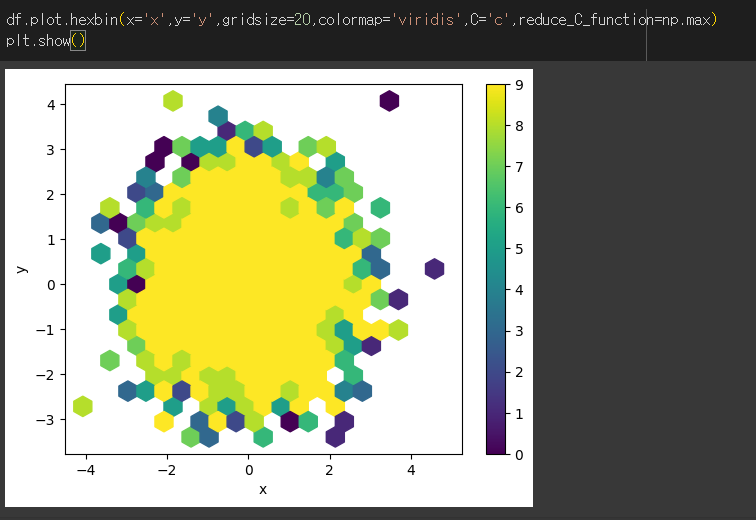
reduce_C_function 인수의 사용
reduce_C_function 인수는 colorbar의 값에 대해서 그래프의 bin(한칸의 가로사이즈)에 속하는 값들이 하나의 대표값으로 통일하게 해주는 np 메서드를 지정하는 인수입니다.
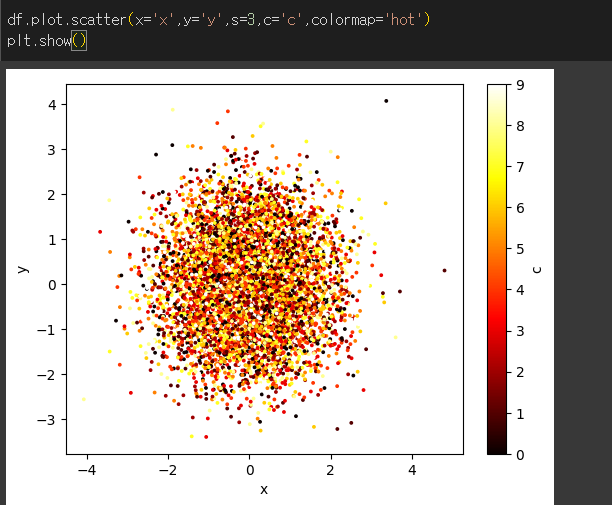
scatter메서드의 사용
scatter는 점산도 그래프를 반환하는 메서드입니다.
s인수는 점의 크기를 스칼라값으로 지정 가능하며, c인수를 통해 각 값이 colorbar에서 어떤 값을 취할지 지정 가능합니다.
축 설정 불필요 (box / hist / pie)
plot.[box / hist / pie] 메서드는 pandas에서 지원하는 matplotlib 메서드 중에서 데이터를 그대로 가져와 플롯 하는 메서드 입니다.
기본적으로 df.plot.(kind =[box / hist / pie], kwargs과 완벽히 동일합니다.
사용법
df.plot.[box / hist / pie].(kwargs)
kwargs: matplotlib 중 plot에서 지원하는 인수의 사용이 가능합니다.
먼저 기본적인 사용법 예시를위하여 데이터를 만들어 보겠습니다.
df는 크기 100짜리 가우시안 표준 정규분포 x와 y열의 데이터입니다.
data = np.random.randn(100,2)
df = pd.DataFrame(data, columns = ['x','y'])
print(df)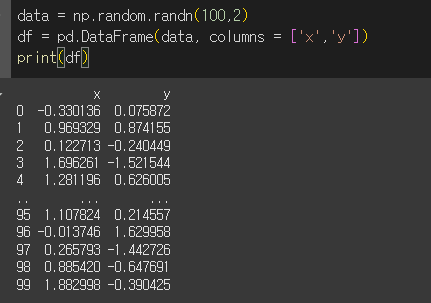
기본적인 사용법
plot.[box / hist / pie]] 메서드는 각 열의 데이터를 가져오기 때문에 x축, y축등을 지정해 줄 필요가 없습니다.
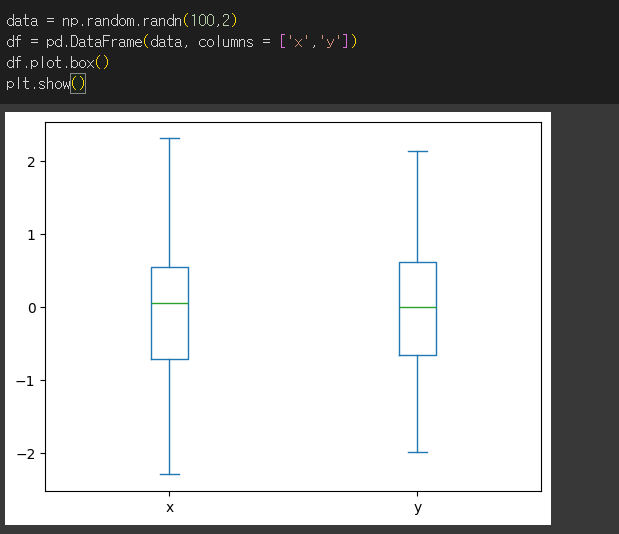
box메서드의 사용
box 메서드의 경우 boxplot을 출력합니다.
df.plot.box메서드는 df.boxplot메서드와 동일한 기능을 수행합니다.
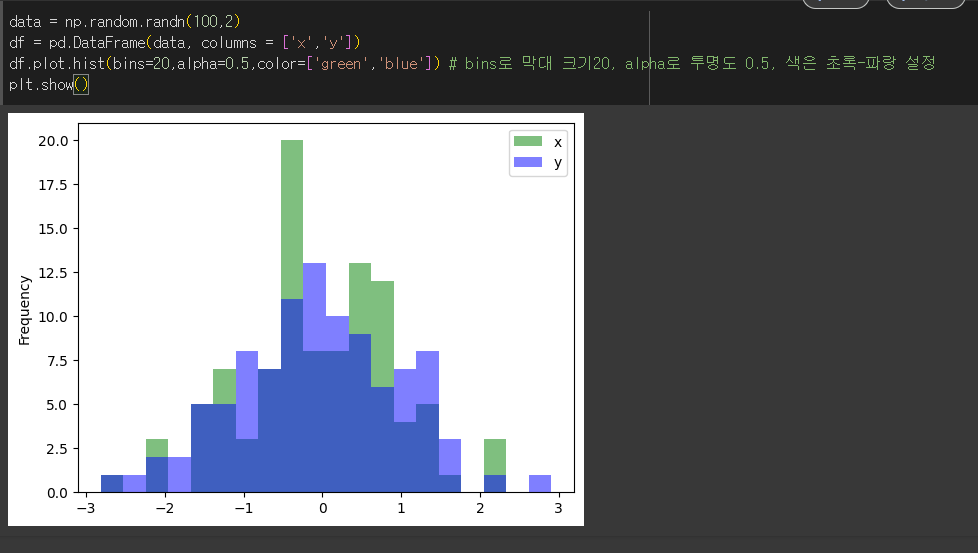
hist 메서드의 사용
hist 메서드의 경우 histogram을 출력합니다. bins 인수를통해 막대 하나의 크기를 정할 수 있으며, alpha를 통해 투명도를 설정할 수 있습니다.
df.plot.hist메서드는 df.hist메서드와 동일한 기능을 수행합니다.
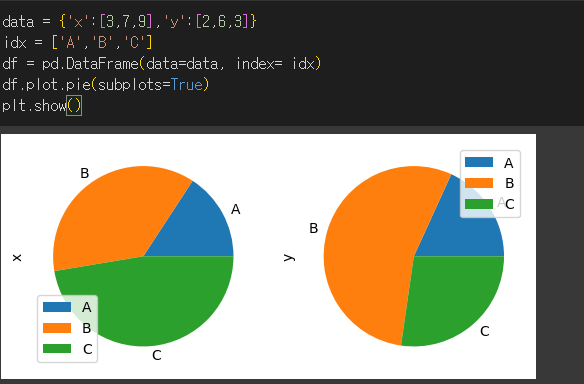
pie 메서드의 사용
pie메서드는 원형 그래프를 출력하는 메서드 입니다. 열의 갯수만큼의 원형그래프가 생성되므로 서브플롯을 설정해주어야합니다.
커널밀도추정 그래프 (kde / density)
lot.[kde / density] 메서드는 pandas에서 지원하는
matplotlib 메서드 중에서 커널밀도추정(KDE)에 대한 그래프를 반환하는 메서드입니다.
보다 심층적으로 설명하면 확률변수의 확률밀도함수(pdf)를 추정하는 비모수적인 방법입니다.
간단히 말하면 histogram을 smoothing 하는 메서드라고 할 수 있습니다.
사용법
df.plot.[kde / density].(bw_method, ind, kwargs)
bw_method: 대역폭을 지정합니다. 대역폭이 작을수록 더 자세한 smoothing이 가능하고, 대역폭이 크면 러프한 smoothing이 수행됩니다.
ind: 예상 PDF에 대한 평가 포인트입니다. 기본값은 1000개의 타점이며, numpy array나 리스트형태로 입력 할 경우 해당 포인트로 계산이 수행됩니다.
kwargs: matplotlib 중 plot에서 지원하는 인수의 사용이 가능합니다.
먼저 기본적인 사용법 예시를위하여 데이터를 만들어 보겠습니다.
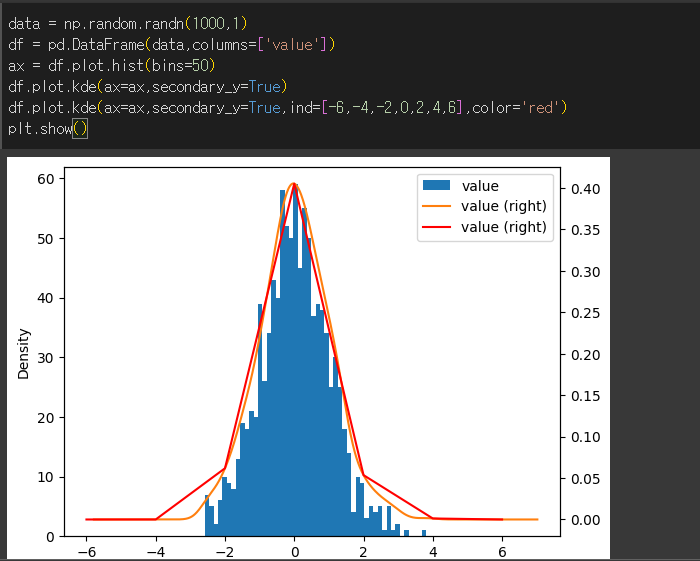
df는 크기 1000짜리 가우시안 표준 정규분포 value열의 데이터입니다.
data = np.random.randn(1000,1)
df = pd.DataFrame(data,columns=['value'])
print(df)
기본적인 사용법
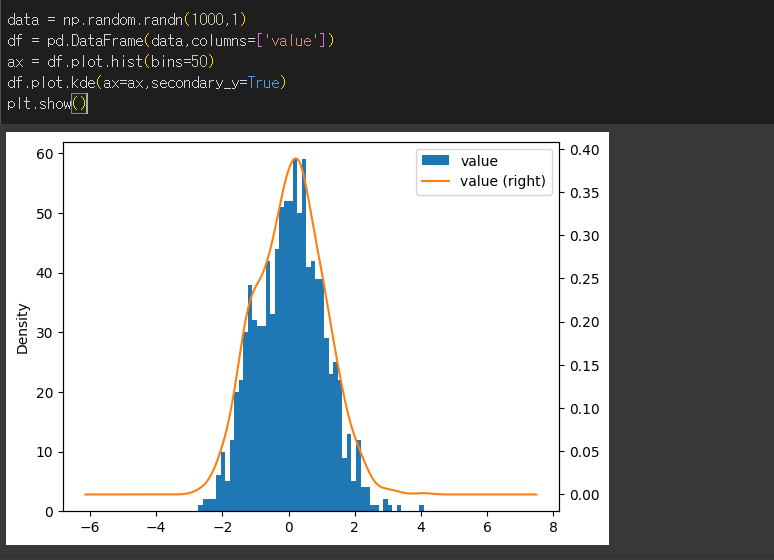
커널밀도추정(KDE)는 간단히 말하면 데이터의 histogram을 smoothing하는 것이라고 볼 수 있습니다.(실제로는 더 복잡한 의미를 가집니다.)
50bin 짜리 histogram과 함께 kde 메서드를 수행해서 비교해보겠습니다.
bw_method 인수의 사용
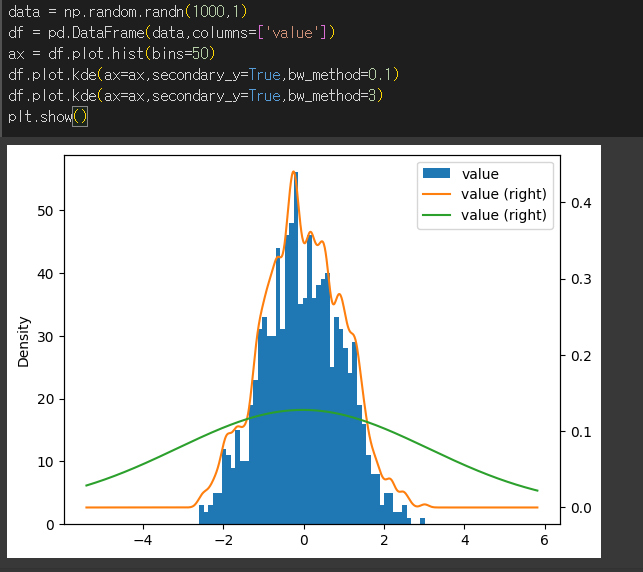
bw_method 인수를이용해 대역폭(bandwidth)를 설정할 수 있습니다. bw_method가 작을수록 더욱 세부적인 계산이 수행됩니다.
ind 인수의 사용
ind 인수를 통해 계산이 수행되는 지점을 지정할 수 있습니다.