dict로 변환 (to_dict)
to_dict 메서드는 데이터프레임 객체를 dict 형태로 변환하는 메서드 입니다.
사용법
df.to_dict(orient='dict', into=)
orient: 출력할 dict의 형태를 지정합니다. 형태는 아래와 같습니다.
into: 반환값의 모든 매핑에 사용되는 collections.abc.Mapping 하위클래스입니다.
먼저 기본적인 사용법 예시를위하여 2x2 데이터를 만들어 보겠습니다.
df = pd.DataFrame([[1,2],[3,4]], columns=['col1','col2'],index=['row1','row2'])
print(df)
기본적인 사용법
orient 인수를 설정함으로써 출력되는 dict객체의 형태를 정할 수 있습니다.
orient = 'dict'인 경우 {열 : {행 : 값, 행 : 값}, 열 : {행 : 값, 행 : 값} 형태로 변환합니다.

orient = 'list'인 경우 {열 : [ 값 ], 열 : [ 값 ] } 형태로 변환합니다.
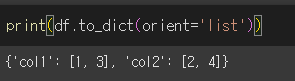
orient = 'series'인 경우 {열 : Series, 열 : Series} 형태로 변환합니다.
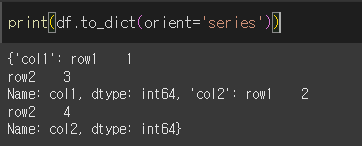
orient = 'split'인 경우 { index : [ 행, 행 ], columns : [ 열, 열 ], data : [ 값, 값 ] } 형태로 변환합니다.

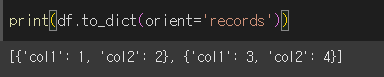
orient = 'records'인 경우 [ { 열 : 값 , 열 : 값 }, { 열 : 값, 열 : 값 } ] 형태로 변환합니다.
orient = 'index'인 경우 { 행 : {열 : 값, 열 : 값}, 행 : {열 : 값, 열 : 값} } 형태로 변환합니다.

Markdown으로 변환 (to_markdown)
to_markdown은 DataFrame 객체를 마크다운 형식으로 변환해주는 메서드입니다.
사용법
df.to_markdown(buf=None, mode='wt', index=True, storage_options=None, kwargs)
buf: 쓸 버퍼입니다. 입력하지 않으면 문자열이 반환됩니다.
mode: 파일을 열때 모드입니다. 기본값은 'wt'입니다.
index: 인덱스를 출력할지 여부입니다. 기본값은 True입니다.
storage_options: 특정 스토리지 연결에 적합한 추가 옵션을 지정합니다. (예 : 호스트, 포트, 사용자 이름, 비밀번호 등)
kwargs: 추가 적용 가능한 tabulate의 키워드입니다.
먼저 기본적인 사용법 예시를위하여 2x2 데이터를 만들어 보겠습니다.
df = pd.DataFrame([[1,2],[3,4]], columns=['col1','col2'],index=['row1','row2'])
print(df)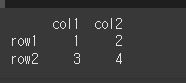
기본적인 사용법
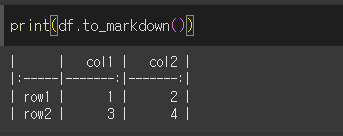
아무 인수 없이 df.to_markdown()을 실행하면 마크다운 형태의 값이 출력됩니다.
index인수의 사용
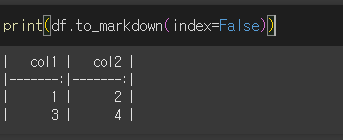
index=False로 입력할 경우 인덱스가 제외됩니다.
string으로 변환(to_string)
to_string 메서드는 데이터 객체를 단순 string 형태로 변형하는 메서드입니다.
먼저 기본적인 사용법 예시를위하여 3x2 데이터를 만들어 보겠습니다.
data = [[1,np.NaN],['A',4.179],['<&>',32000]]
df = pd.DataFrame(data,columns=['col1','col2'])
df=df.rename_axis(columns='index')
print(df)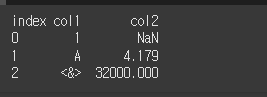
기본적인 사용법
to_string( )메서드를 사용하면 데이터 객체의 기본 타입인 pandas.core.frame.DataFrame을 string으로 변경합니다.
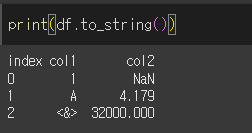
columns 인수의 사용
columns 인수를 입력하여 특정 열만 출력이 가능합니다. list 형태로 입력하여야합니다

header 인수의 사용
header 인수를 입력하여 열 이름을 지정할 수 있습니다. True 나 False, None를 입력하여 출력 여부를 설정할 수도 있습니다.

index인수의 사용
index 인수를 이용해 index의 출력 여부를 정할 수 있습니다.

na_rep 인수의 사용
na_rep인수를 입력하여 결측치(NaN등)의 표현값을 변경할 수 있습니다.

index_names인수의 사용
index_names를 설정함으로서 인덱스명의 출력 여부를 정할 수 있습니다. 기본값은 True입니다.
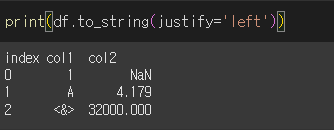
max_rows / max_cols 인수의 사용
max_raws / max_cols 인수를 사용해 출력할 최대 행/열 수를 지정할 수 있습니다. 초과분은 ( ... )로 함축되어 표현됩니다.
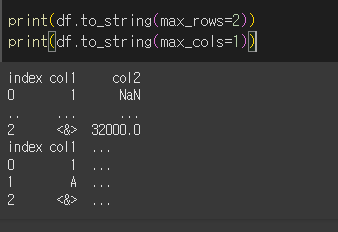
show_dimensions인수의 사용
show_dimensions인수를 이용하여 데이터의 차원을 출력할 수 있습니다.
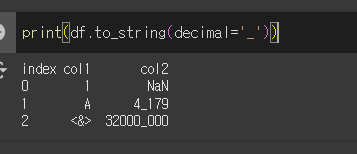
decimal 인수의 사용
decimal인수를 사용하여 1000단위 표현값을 지정할 수 있습니다. 기본값은 콤마( , ) 입니다.
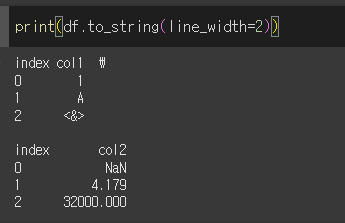
line_width인수의 사용
linde_width인수값을 입력하여 줄바꿈할 열의 너비를 지정할 수 있습니다.
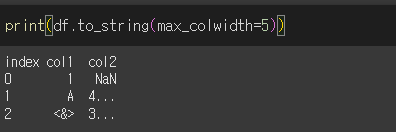
max_colwidth인수의 사용
max_colwidth 인수를 이용하여 열 내의 문자열 길이를 제한할 수 있습니다. 초과하는 문자는 ( ... ) 으로 함축됩니다.
numpy로 변환 (values)
DataFrame 요소를 Numpy 형태(numpy.ndarray)로 반환합니다. 레이블은 삭제됩니다.
먼저, 아래와 같이 기본적인 4x4 행렬을 만듭니다. col1은 숫자, col2는 문자, col3은 float, col4는 bool의 dtype을 가집니다.
col1 = [1, 2, 3, 4]
col2 = ['one', 'two', 'three', 'four']
col3 = [1.5, 2.5, 3.5, 4.5]
col4 = [True, False, False, True]
index = ['row1','row2','row3','row4']
df = pd.DataFrame(index=index, data={"col1": col1, "col2": col2, "col3": col3, "col4": col4})
print(df)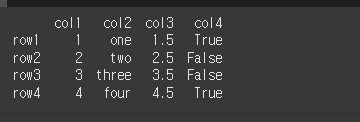
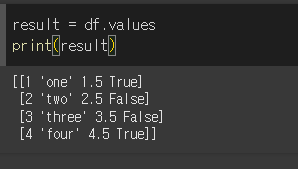
여기에 values함수를 적용할 경우 아래와 같은 결과가 반환됩니다. 결과값은 numpy.ndarray형태로
반환되며, 레이블이 사라진것을 확인할 수 있습니다.
dict에서 변환 (from_dict)
from_dict메서드는 dict객체로부터 DataFrame 객체로 변환하는 메서드입니다.
사용법
df.from_dict(data, orient='columns', dtype=None, columns=None)
data: dict 형태의 데이터 입니다.
orient: {index / columns / tight} 변환 방식입니다. index은 행을 키값으로 지정, columns는 열을 키값으로 지정, tight는 키값으로[index / columns / data / index_names / columns_names]를 가집니다.
dtype: 데이터의 type을 강제로 지정할 수 있습니다.
columns: index인수를 사용할 경우 columns인수를 통해 열 이름을 지정할 수 있습니다.
기본적인 사용법
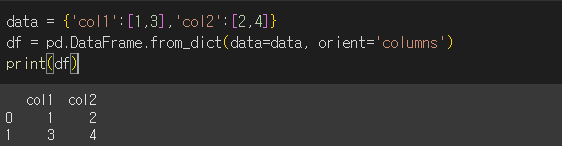
orient인수의 기본값은 'columns'로 키값으로 열 이름을 사용하게 됩니다.
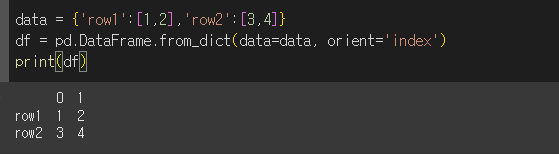
orient인수가 'index'인 경우 키 값으로 행 이름을 사용하게 됩니다.
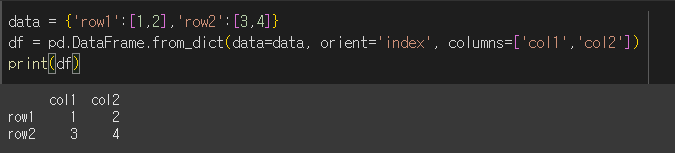
orient인수가 'index'인 경우 columns인수를 통해 열 이름을 추가로 설정할 수 있습니다.
dtype 인수를 이용하면 값의 type을 강제로 지정할 수 있습니다.

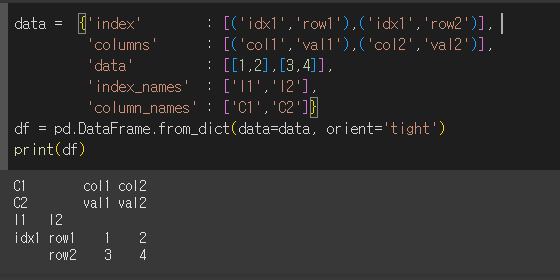
orient='tight'인 경우 'index' / 'columns' / 'data' / 'index_names' / 'column_names'를 키 값으로 지정하여 세부내용을 설정 할 수 있습니다.