오늘도 윈도우 함수 관련 2문제를 가져왔습니다.
난이도는 둘다 medium이라고 하네요.
오늘도 역시 제가 설명하고 싶은 개념 설명을 추가로 할까 합니다.
#184번
1. 문제 소개
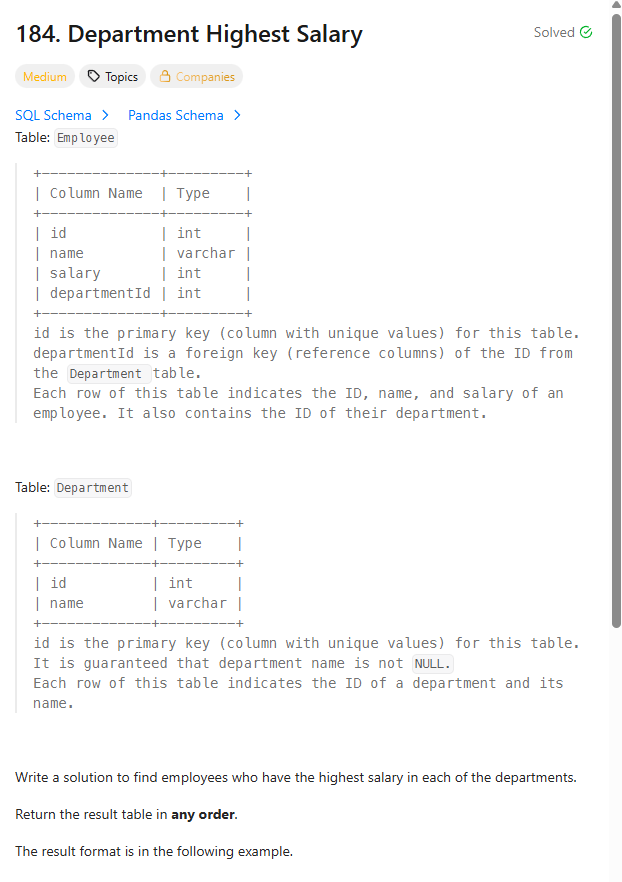

*테이블
EMPLOYEE(ID(PK),NAME,SALARY,DEPARTMENTID(FK))
DEPARTMENT(ID(PK),NAME)
*문제
Write a solution to find employees who have the highest salary in each of the departments.
Return the result table in any order.
->각 부서에서 가장 연봉이 높은 직원 찾아라. 순서(정렬)은 아무렇게나 해도 됨.
예시를 보니깐, 공동 1등은 둘 다 나타냄.
2. 문제 풀이
저는 문제를 읽고 예시를 살펴보며 딱 들었던 생각이
- WINDOW FUNCTION의 RANK OR DENSE_RANK 둘 다 가능
->어차피 1등만 고르면 되니깐. 그 다음 순서는 어떻게 매기든 상관 없음.2.그리고 FK로 이어져있기 때문에, 따로 JOIN도 안해도 됨.
그냥 EMPLOYEE TABLE에서 진행해도 됨.
->다만, DEPARTMENTID를 나누는 작업을 어떻게 해야할지 고민해야 됨.
->PARTITION BY?
이렇게 2가지가 생각이 났습니다.
일단은 partition by 구현을 이렇게 해보았습니다.
SELECT
ID,
NAME,
SALARY,
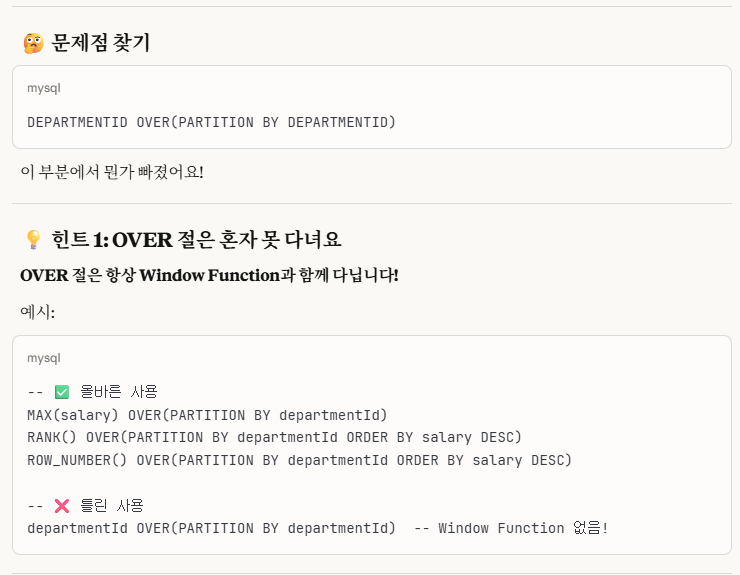
DEPARTMENTID OVER(PARTITION BY DEPARTMENTID) AS DEPARTMENTID
FROM EMPLOYEE하지만 문법 오류가 뜨더군요.
※개념_1. partition by의 올바른 사용법
이렇 듯, partition by가 속하는 over()절은 항상 윈도우 함수가 동반되야함을 알 수 있었습니다.



그래서 위의 오류를 고치고, 한번 이렇게 작성해보았습니다.
SELECT
ID,
NAME,
SALARY,
DEPARTMENTID,
RANK() OVER(PARTITION BY DEPARTMENTID ORDER BY SALARY DESC) AS 'RANK'
FROM EMPLOYEE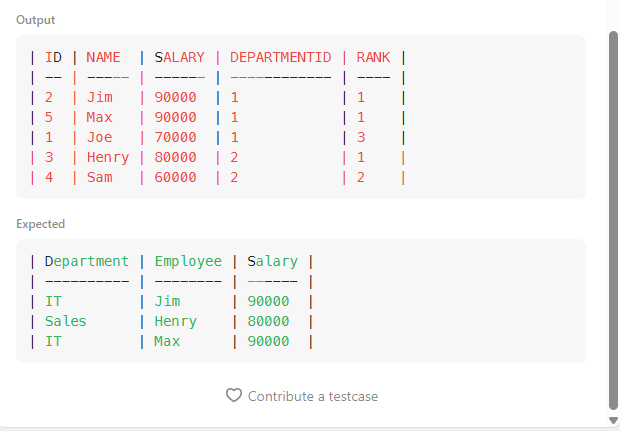
하지만 위의 결과를 볼 때, 우리는 departmentid가 아닌 department_name을 알아야합니다.
제가 위 2번에서 '그리고 FK로 이어져있기 때문에, 따로 JOIN도 안해도 됨. 그냥 EMPLOYEE TABLE에서 진행해도 됨.' 이라고 했는데, 과연 join 없이 department table의 name을 가져올 수 있는지 claude에게 물어보았습니다.
※개념_2. Q. join 없이 fk한 자식 테이블의 다른 정보를 알아올 수 있나?

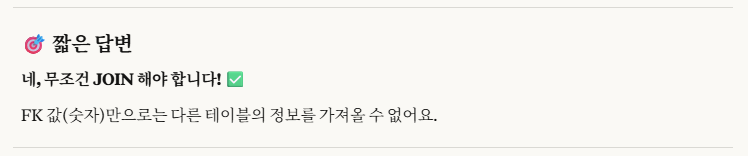

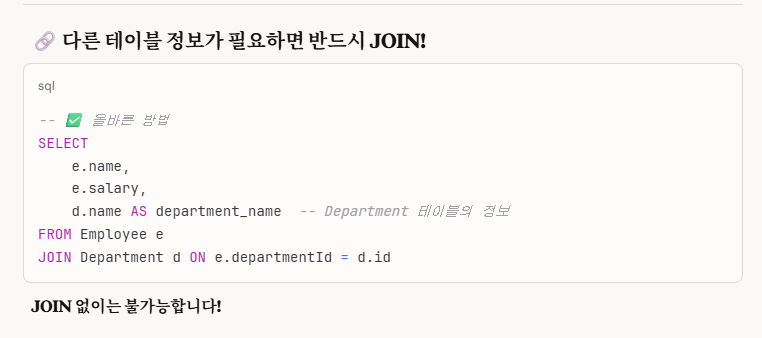
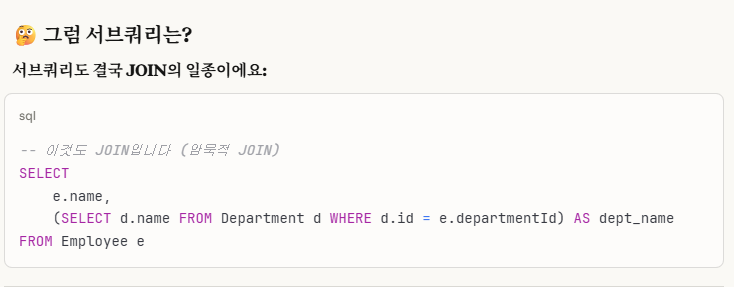
이렇게 해서, 우리는 department_name이 필요함으로 join이 반드시 필요함을 알게 되었습니다.
*조인 종류: inner join(교집합)
*공통된 속성(열): departmentid
내부 조인인 이유는 우리는 양 테이블의 공통된 부분만 추출하면 되고, 공통 열이 departmentid인 이유는 양쪽 겹치는 열이기 때문입니다.
SELECT
E.ID,
E.NAME,
E.SALARY,
E.DEPARTMENTID,
D.NAME,
RANK() OVER(PARTITION BY DEPARTMENTID ORDER BY SALARY DESC) AS 'RANK'
FROM EMPLOYEE E INNER JOIN DEPARTMENT D
ON E.DEPARTMENTID = D.ID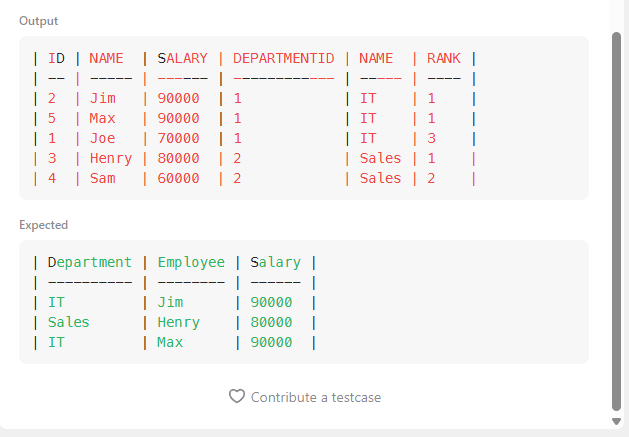
이제 우리는 이 결과를 보고, 요구하는 정답대로 format을 맞추면 끝입니다.
format을 맞추다가, 이렇게 한번 맞추어보았습니다.
SELECT
-- E.ID,
D.NAME as Department,
E.NAME as Employee,
E.SALARY as Salary,
-- E.DEPARTMENTID,
-- RANK() OVER(PARTITION BY DEPARTMENTID ORDER BY SALARY DESC) AS 'RANK'
FROM EMPLOYEE E INNER JOIN DEPARTMENT D
ON E.DEPARTMENTID = D.ID
-- WHERE 'RANK' = 1
WHERE RANK() OVER(PARTITION BY DEPARTMENTID ORDER BY SALARY DESC) = 1오류의 원인은 where절에 윈도우 함수를 사용해서였습니다.
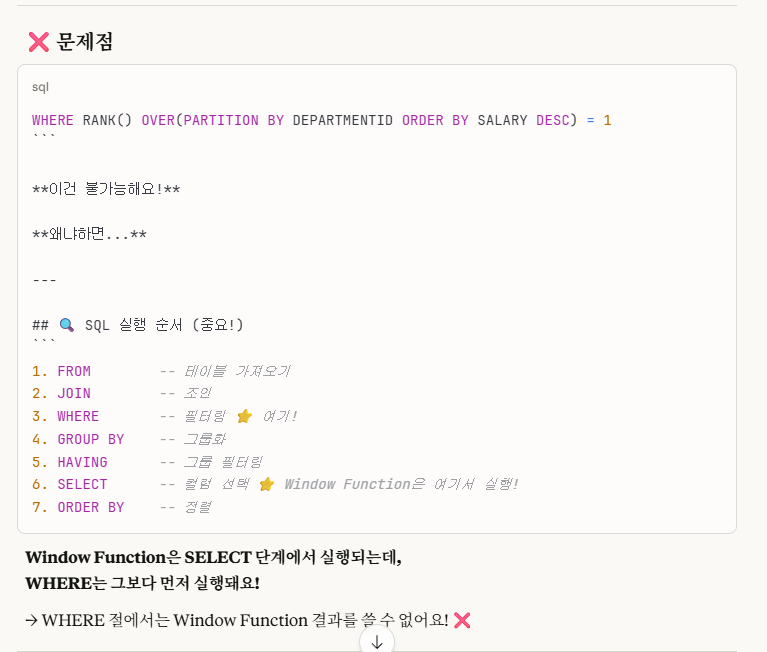
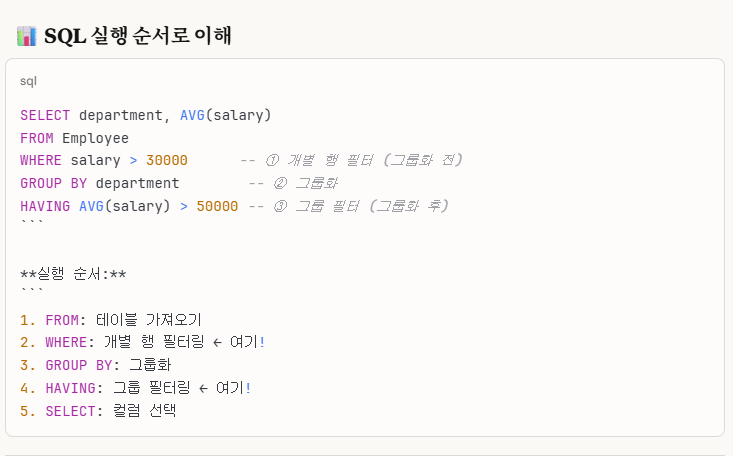
->위 'SQL 실행 순서'를 꼭 참고해주세요. 중요합니다 ⭐
위 사진에서 말한 것처럼,
window function은 select 단계에서 실행되는데,
where는 select보다 먼저 실행하므로 실행 순서에서 오류가 납니다.
※cf.)개념_3. sql문에서 window function 사용 위치
이렇게 이해하면 쉬울 거 같습니다.
'sql 실행 순서'를 보면 5.select문 6. order by절 입니다. 보통 윈도우 함수는 select문에서 사용되고, 실행 순서상 order by는 select문에 뒤에 있으므로, order by절에도 윈도우 함수를 사용할 수 있는 것입니다.반면, where,group by, having 절에서는 윈도우 함수가 사용 불가능한 이유는, select보다 실행 순서가 앞서기 때문에 사용이 불가능합니다.

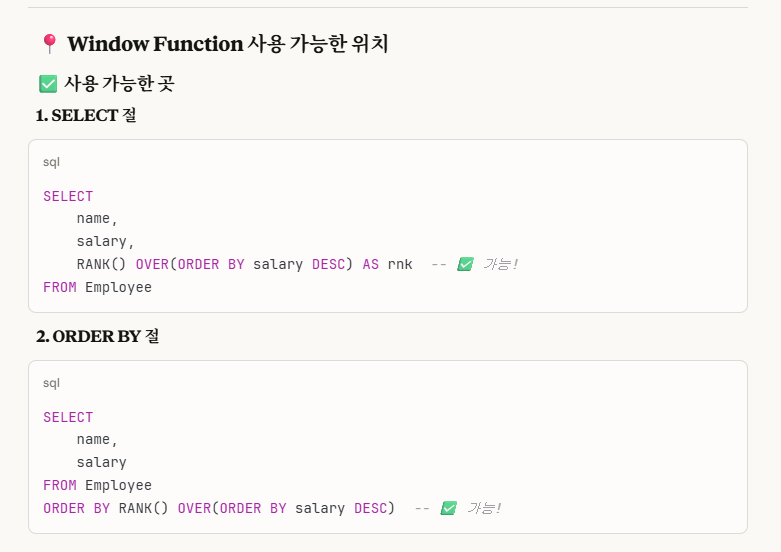
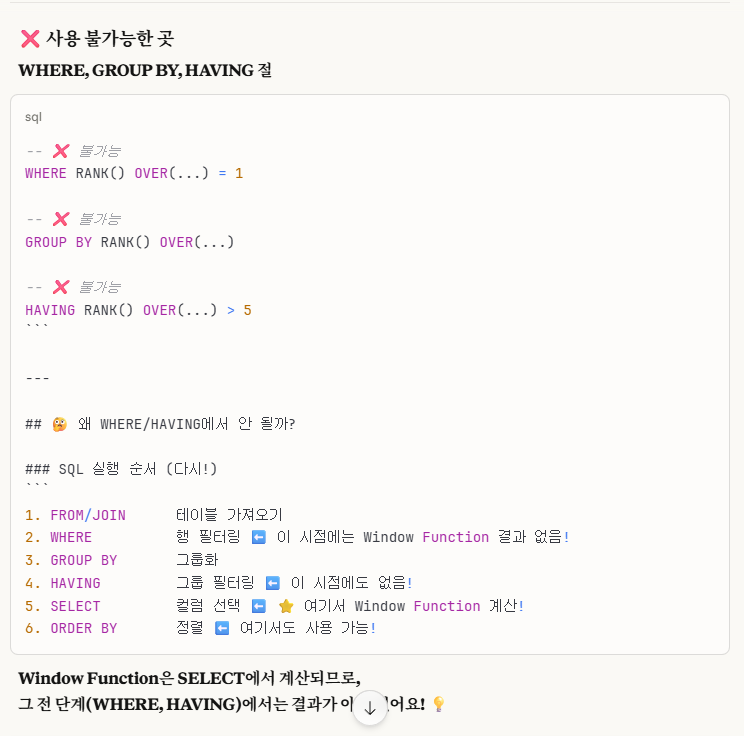
따라서 우리는 밑의 2가지 방식으로 문제풀이를 진행하면 됩니다.
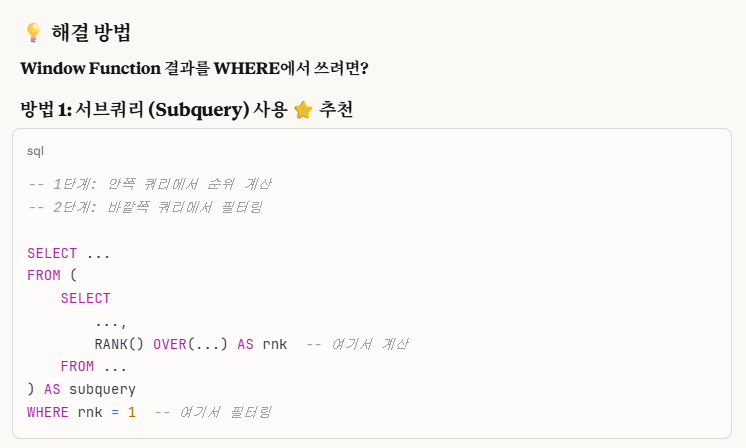

우리는 이전에 서브쿼리로 문제 푸는 것을 많이 해봤으므로, 이번에는 CTE- with절을 사용하여, 임시테이블을 생성해서 문제를 풀어보도록 하겠습니다.
※개념_4. with절 개념 설명

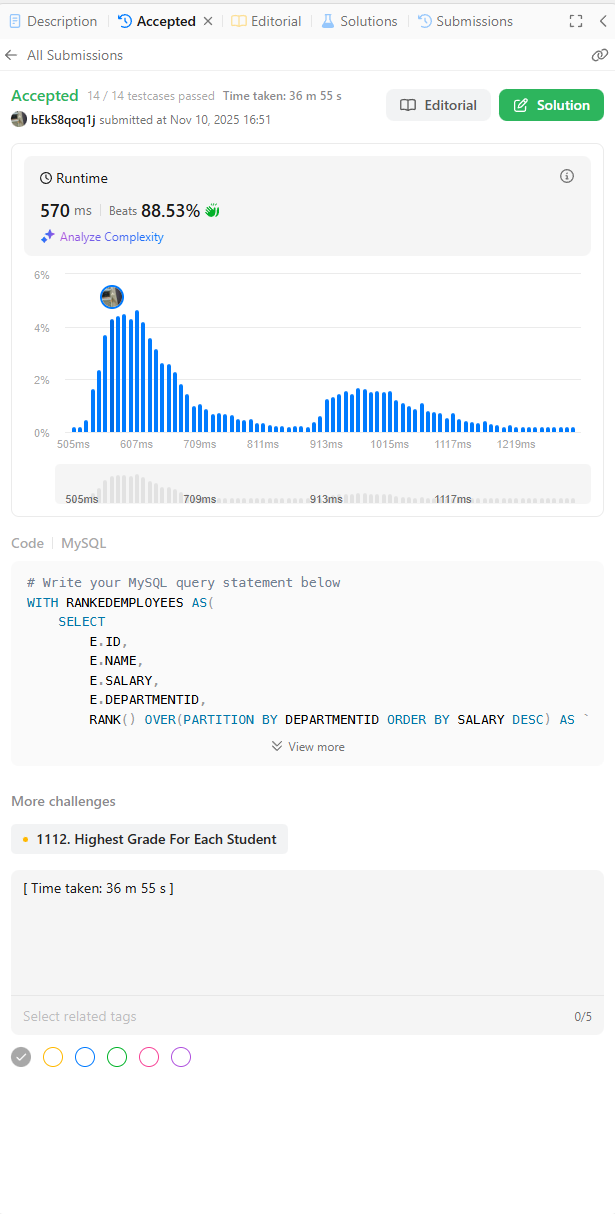
<최종 정답 코드>
WITH RANKEDEMPLOYEES AS(
SELECT
E.ID,
E.NAME,
E.SALARY,
E.DEPARTMENTID,
RANK() OVER(PARTITION BY DEPARTMENTID ORDER BY SALARY DESC) AS `RANK`
FROM EMPLOYEE E
)
SELECT
D.NAME as Department,
RE.NAME as Employee,
RE.SALARY as Salary
FROM RANKEDEMPLOYEES RE INNER JOIN DEPARTMENT D
ON RE.DEPARTMENTID = D.ID
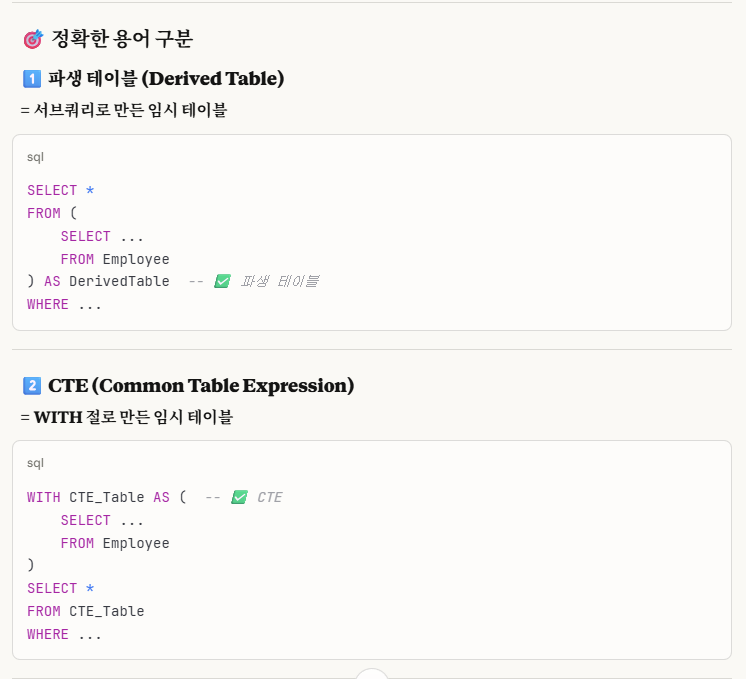
WHERE RE.`RANK` = 1with절로 만든 테이블은 '임시 테이블'입니다.
'RANKEDEMPLOYEES' 부분은 임시 테이블의 이름입니다.
with절 임시테이블에서는 조인을 하지 않고, 임시테이블과 department 테이블을 inner join 합니다.
임시 테이블에서 RANK() OVER(PARTITION BY, ORDER BY)의 윈도우 함수를 진행하고 이를 'RANK'(백틱으로 표현해야 합니다.)라고 지칭합니다.
그리고 이 'RANK'를 WHERE절 조건절로 활용하여 요구하는 정답 형식으로 나타냅니다.
#1204번
1. 문제 소개
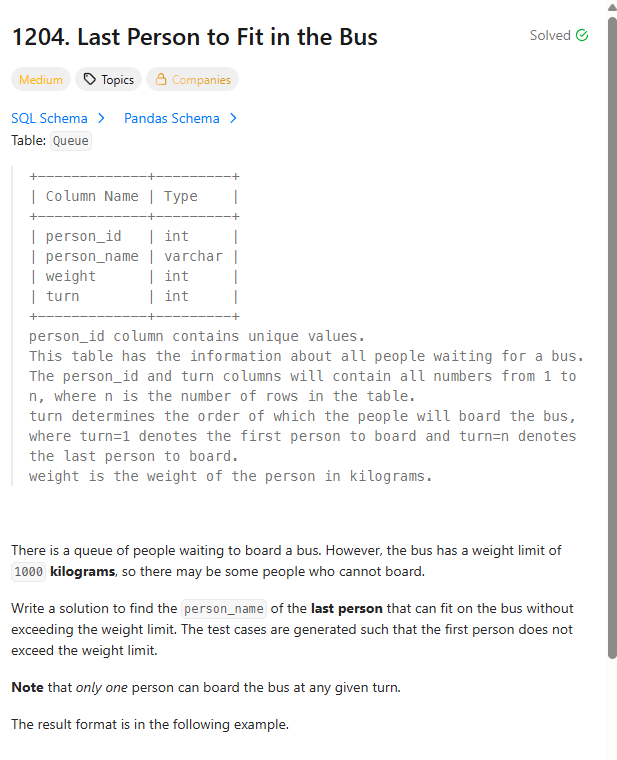

*테이블
QUEUE(PERSON_ID(PK),PERSON_NAME, WEIGHT, TURN)
->'PERSION_ID & TURN' CONTAIN ALL NUMBER 1 TO N, N IS THE NUMBER OF ROWS IN THE TABLE. -> ROW_NUMBER()를 사용하라는 의미인가?
TURN의 의미는 버스에 탑승하는 순서를 의미한다고 함.
->1이 제일 빠르고 N이 제일 나중임.버스 무게 제한: 1000KG
->사람이 못탈 수 있음.
*문제
Write a solution to find the person_name of the last person that can fit on the bus without exceeding the weight limit. The test cases are generated such that the first person does not exceed the weight limit.
->버스 무게 제한(1000KG) 초과않는 선에서, LAST PERSON을 찾아라. 첫번째 사람은 버스 무게 제한을 안 넘음.
※마치 알고리즘 정렬 문제 같아 보이나 거기까지는 안 간듯 함.
2. 문제 풀이
일단 문제와 조건들을 보고 제 머릿 속에 처음에 딱 드는 생각은 다음과 같았습니다.
ORDER BY + HAVING + 집계 함수
2-1. 일단 TURN을 ORDER BY ASC로 만들자.
<정답 코드>
SELECT
TURN,
PERSON_ID,
PERSON_NAME,
WEIGHT
FROM QUEUE
ORDER BY TURN이 부분은 쉬우니 설명은 생략하겠습니다.
2-2. SUM(WEIGHT)과 HAVING절이 필요하다.
SUM(WEIGHT)이라는 집계함수와 그에 대한 조건식을 작성해야하므로, WHERE절이 아닌 HAVING절을 생각했습니다.
그러다 문득 HAVING절의 정확한 사용법이 생각이 나지 않아
CLAUDE에게 물어보았습니다.

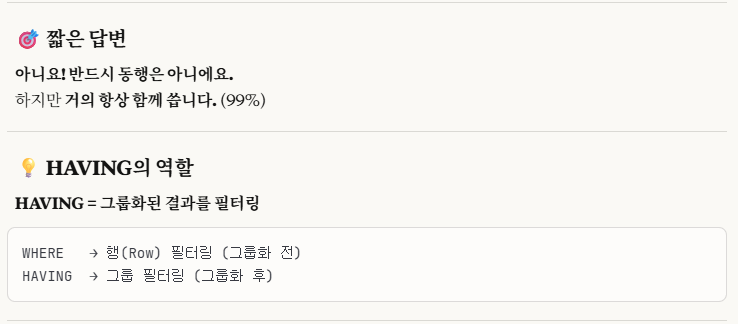
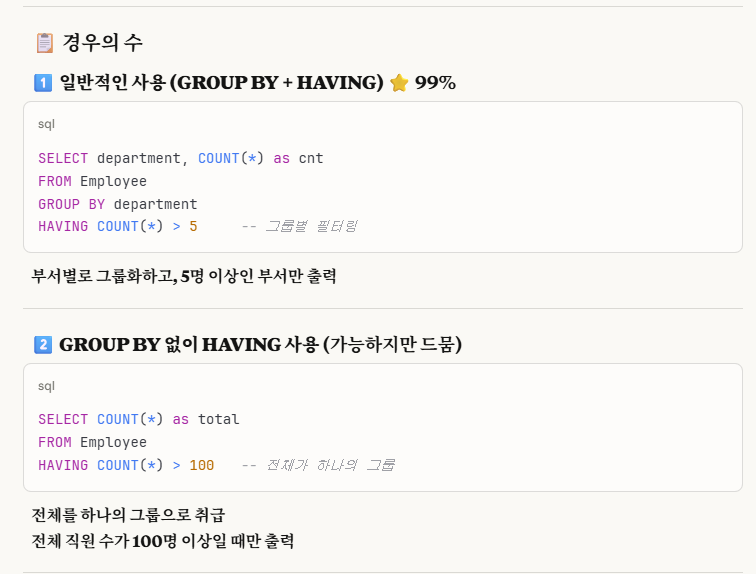
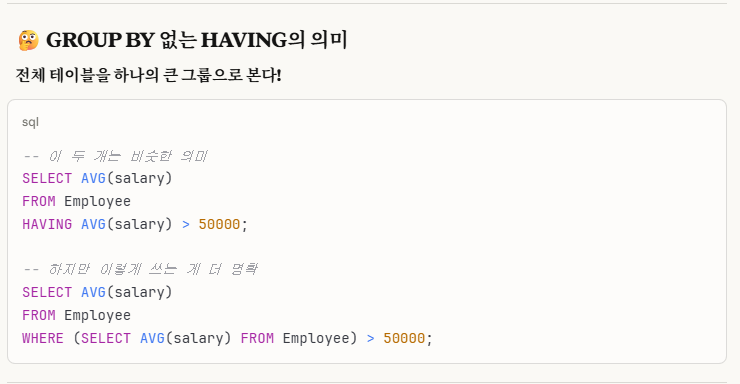
나는 전체 테이블을 하나의 큰 그룹으로 바라보고 작성하므로
GROUP BY 없이 HAVING으로만 조건식을 작성해보았다.
SELECT
TURN,
PERSON_ID,
PERSON_NAME,
WEIGHT,
SUM(WEIGHT) OVER(ORDER BY TURN) AS `TOTAL_WEIGHT`
FROM QUEUE
-- HAVING `TOTAL_WEIGHT` <= 1000
-- ORDER BY TURN위에는 주석처리했지만,
주석 처리를 보면 알 듯이, HAVING절을 사용할 수 없었다.
일단은 위의 이유보다 먼저 살펴볼 점은,
SUM(WEIGHT)에 OVER()절을 사용하여 윈도우 함수로 나타냈다는 점이다.
근데, 왜 윈도우 함수로 나타내야 할까?

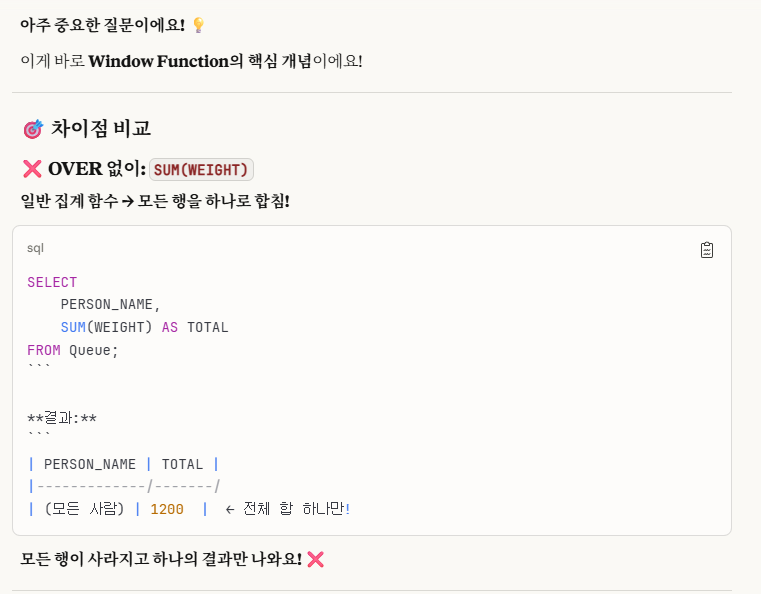
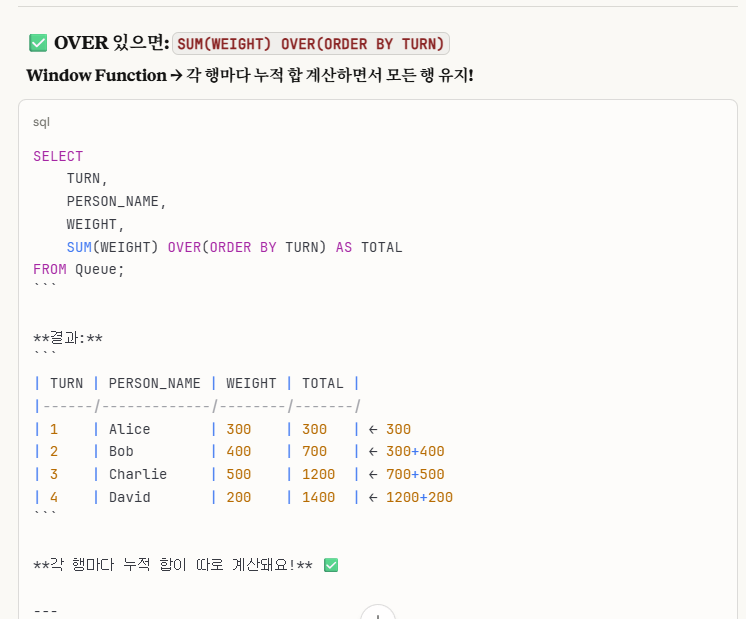

그렇다. 위 사진들을 참고해보면 알 수 있듯이,
OVER()의 유무 차이는 '행을 하나로 합치거나(GROUP BY처럼)(OVER()가 없을 때)' VS '행을 전부 유지하면서 집계 함수 실행(PARTITION BY처럼)(OVER()가 있을 때)' 이렇게 나뉜다.
우리가 이전 게시글에서 윈도우 함수를 다룰 때,
'GROUP BY VS PARTITION BY'로 개념을 나눴는데,
사실상 여기에서의 개념은 OVER()의 유무 차이에서의 이유와 같다고 본다.
즉, OVER()가 있으면 모든 행을 유지함, OVER()가 없으면 모든 행을 하나로만 합침. 이 개념을 알면 된다.
그리고 우리는 위에서 OVER()를 사용해서 윈도우 함수로 나타냈으므로, HAVING절을 사용할 수가 없다.
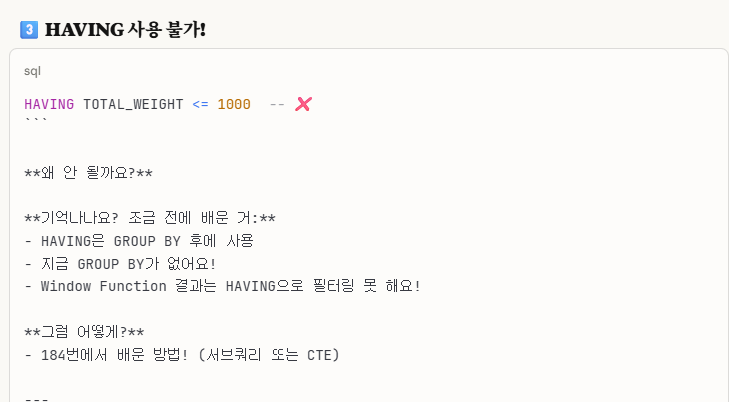
위 사진에서 GROUP BY가 없어서 안된다는 이유보다는 그냥 WINDOW FUNCTION은 HAVING절을 사용못한다고 알아두면 더 좋다.
※왜 having절을 사용할 수 없는가?(디테일한 설명)
위 사진을 보면 알 수 있듯이,
having절은 거의 대부분의 경우에서 group by와 함께 사용되므로, 집계의 '결과'를 having 조건식으로 필터링한다.하지만, 우리는 집계의 '결과'가 아닌 각 행을 살려서 마지막 인물을 조회해야하므로,
'각 행을 살린다는 의미' = 윈도우 함수 over()를 활용하고,
이 윈도우 함수는 집계의 '결과'가 아닌 집계의 '각 행'을 중요시 여기기에,having과 윈도우 함수는 논리적으로 모순 및 충돌이 일어난다.

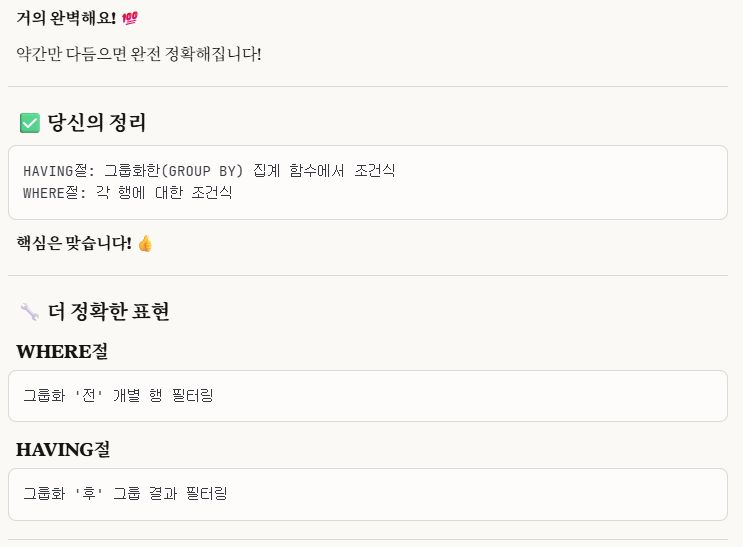
※cf.) where절 vs having절 개념 설명
내가 말한 개념대로 이해해도 좋고(직관적임),
claude가 말한 '더 정확한 표현'(where절: 그룹화 전 '개별 행' 필터링)(having절: 그룹화 후 '그룹 결과' 필터링) 이런 식으로, 그룹화 전 vs 후로 기억해도 좋다.
(본인은 본인이 말한 개념대로 좀 더 이해할 계획임.)

그러면 HAVING 부분을 어떻게 해결하면 될까?
앞에서 했던 것과 마찬가지로
1.서브쿼리 활용
2.CTE 임시 테이블 WITH절 활용
이렇게 할 수 있다.
둘 다 임시테이블 개념이므로, 임시테이블로 문제를 해결할 수 있다는 점이다.
마찬가지로 WITH절로 해결해보았다.
<최종 정답 코드>
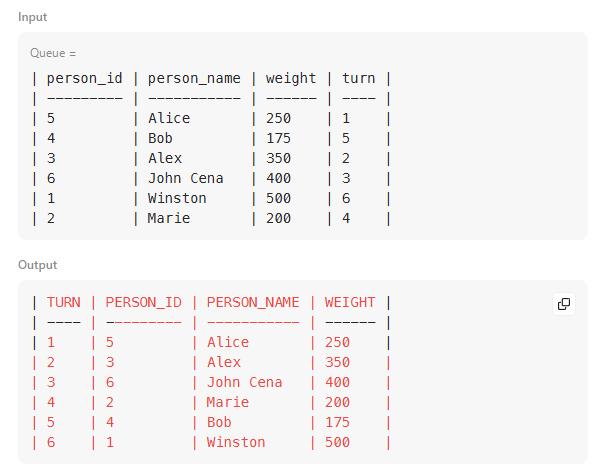
WITH TABLE_1 AS(
SELECT
TURN,
PERSON_ID,
PERSON_NAME,
WEIGHT,
SUM(WEIGHT) OVER(ORDER BY TURN) AS TOTAL_WEIGHT
FROM QUEUE
)
SELECT
PERSON_NAME AS person_name
FROM TABLE_1
WHERE TOTAL_WEIGHT <= 1000
ORDER BY TURN DESC
LIMIT 1
-- HAVING `TOTAL_WEIGHT` <= 1000
-- ORDER BY TURN앞서서 푼 문제와 마찬가지로,
WITH절로 임시 테이블을 만들어서, 여기에 윈도우 함수를 구현하고, 그 다음 메인 SELECT문에서 WHERE절을 활용하여 조건식을 작성하면 된다.
TURN은 임시 테이블 'TABLE_1'에 SELECT를 미리 해두었으므로, 이는 이미 있는 열(속성)이므로 메인 SELECT에서도 사용할 수 있고, 이를 이용해서 ORDER BY DESC을 진행한다.
또한 우리는 맨 마지막 사람 한명만 PICK하면 되므로 LIMIT 1로 제한을 둔다.
※왜 HAVING절이 아닌 WHERE절일까?
이미 임시 테이블에서 윈도우 함수를 통해 집계 함수를 구현하였다.
따라서, 메인 SELECT문에서는 이 집계된(=집계가 완료된) 결과를 토대로 조건을 적용하면 되므로, HAVING절이 아닌 WHERE절을 사용하면 된다.
-> where절은 각 행(개별 행)에 대한 조건식 필터링임을 앞에서 언급하였다. 이미 임시테이블에서 집계 함수를 활용해 sum() 결과를 각 행 별로 냈으므로, 우리는 각 행의 관점으로 조건식을 접근하면 된다.
3. 마무리
이렇게 해서 오늘도 LEETCODE 윈도우 함수 MEDIUM 난이도의 문제를 2개 풀어보았다.
오늘은 윈도우 함수, 특히 OVER()절에 대해서 더더욱 세심하게 개념 공부를 한 시간이 되어서 좋았다.
오늘도 제 긴 글을 봐주셔서 감사합니다. :) bb
