데이터 엔지니어링을 위한 포트폴리오
1.데이터베이스 학과 프로젝트 리뷰-1

학부생 때 했던 데이터베이스 프로젝트 소개학부생 때 했던 데이터베이스 프로젝트 최대한 원본 그대로 살려서 수정·보완 작업(현재 수준에 맞춰서)Claude에게 점수 평가 받기최종적으로, 웹 데이터베이스에서 데이터 조작어 실행해보기총 2번의 발표가 있었는데, '중간 발표'
2.데이터베이스 프로젝트 리뷰 2 - 릴레이션 스키마 제약조건 설정 및 웹 데이터베이스 테스트
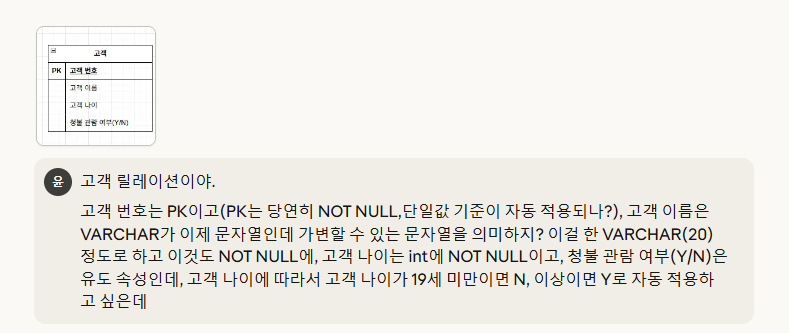
※cf.) 데이터베이스 프로젝트 1에 이어서 진행되는 게시글입니다!
3.[SQL 프로그래머스 문제풀이] (JOIN) 없어진 기록 찾기
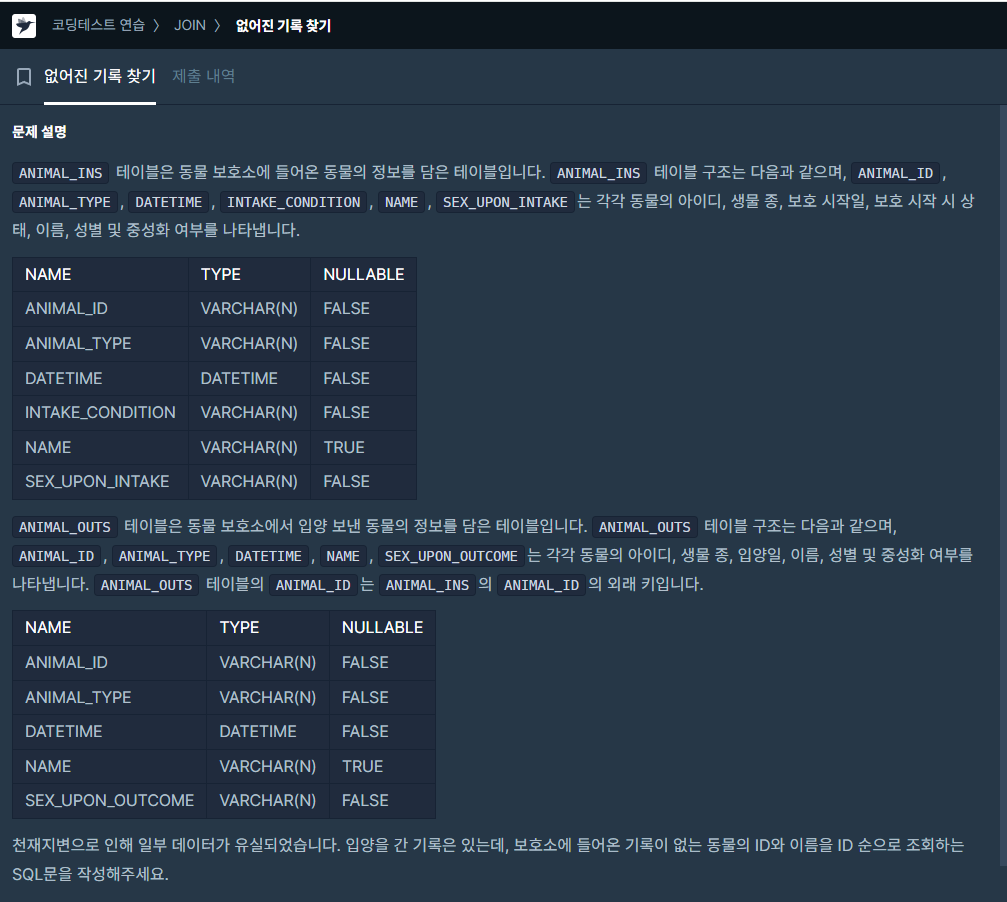
※TMI데이터 엔지니어링을 하기 위해서는, Claude가 먼저 window function이 중요하다고 하여, window function 개념 및 셀프 조인 개념 및 왼쪽,오른쪽,완전 외부 조인 개념을 한번 리뷰하고 문제풀이를 진행하였다.각각의 개념들은 내 '네이버
4.[SQL 프로그래머스 문제풀이] (JOIN) '있었는데요 없었습니다.'

문제는 전 게시글인 '없어진 기록 찾기'와 정보는 같습니다.다만, 요구하는 문제만 다릅니다.우리는 이 문제를 해결해야 합니다.우리는 '보호 시작일보다 입양일이 빠른 동물'을 찾아야 합니다.JOIN 문제이지만, 저는 JOIN 없이 풀 수 있는 방법이 없을까하며 약간 고민
5.[SQL 프로그래머스 문제풀이] (JOIN) '오랜 기간 보호한 동물(1)'

전 게시글들과 테이블 정보들은 동일합니다.이번 역시, 요구하는 문제만 다릅니다.우리는 문제를 이렇게 세분화할 수 있습니다.아직 입양을 못 간 동물가장 오래 보호소에 있었던 동물 3마리 -> ORDER BY DESC보호 시작일예시 테이블을 보는데, 뭔가 이상한 점이 있습
6.[SQL 프로그래머스 문제풀이] (JOIN) '주문량이 많은 아이스크림을 조회하기'
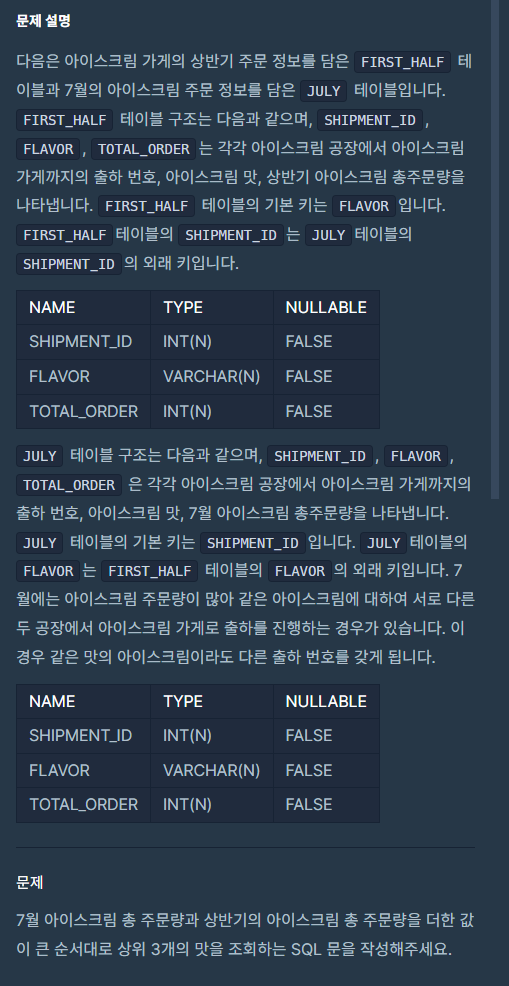
이번 문제는 LEVEL-4입니다.문제를 풀고 나니, 확실히 LEVEL-3보다는 조금 더 복잡하긴 하네요 ㅎㅎ..문제를 요약해보도록 합시다.*테이블 정보\-> FIRST_HALF 테이블(상반기 주문 정보), JULY 테이블(7월의 아이스크림 주문 정보)*각 테이블에서의
7.[SQL 프로그래머스 문제풀이] (JOIN) '특정 기간동안 대여 가능한 자동차들의 대여비용 구하기'
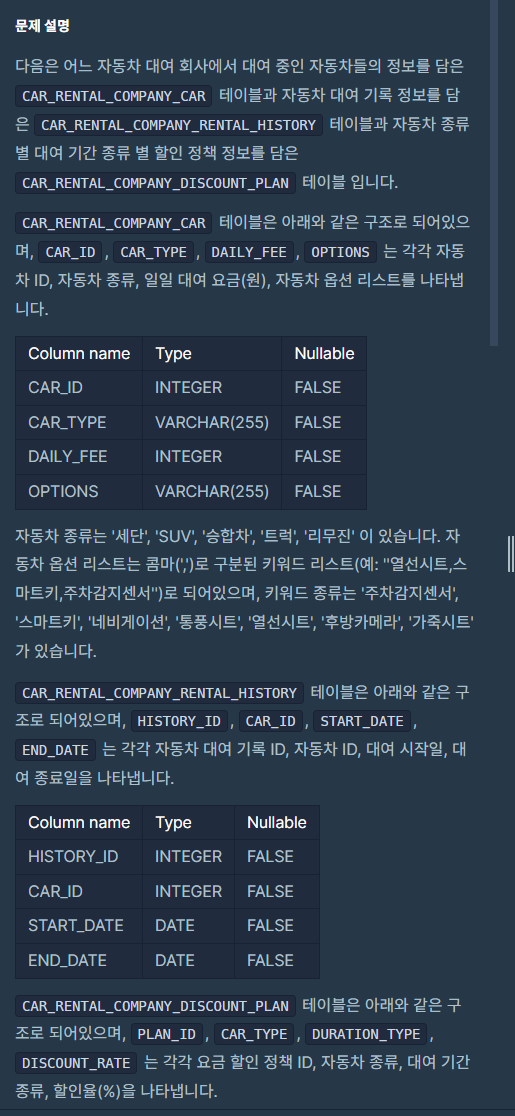
똑같이 프로그래머스 LEVEL-4 문제인데 상당히 어렵네요..ㅠㅠ 엄청나게 틀리고 수정하는 작업을 반복했습니다.제 기준으로, 중요한 개념 정리가 여러개 나오는데, 강조 표시 해둘게요..!!!총 3개의 테이블이 있습니다.1.회사에서 대여 중인 자동차 정보 담은 테이블(C
8.[SQL 프로그래머스 문제풀이] (JOIN) '5월 식품들의 총매출 조회하기'
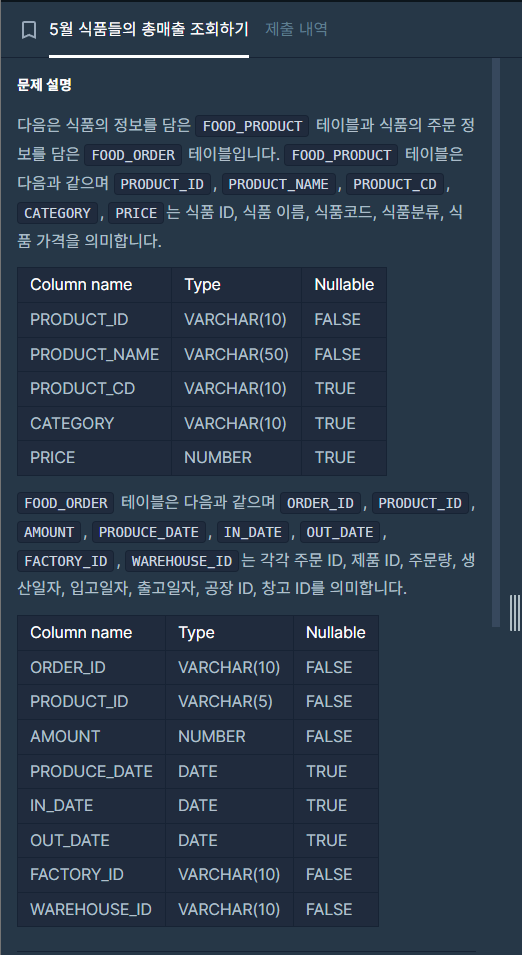
프로그래머스 LEVEL-4 문제입니다.직전 게시글 문제랑 같은 레벨이지만 다른 난이도인 거 같아요. 아무래도 직전 게시글이 LEVEL-4가 아니라 5인 거 같음...(다른 사람 해답 풀이과정 게시글 참고했는데, 거기서 'LEVEL-5'라고 적혀있는 거 보면..)이번엔
9.[SQL 프로그래머스 문제풀이] (JOIN) '그룹별 조건에 맞는 식당 목록 출력하기'
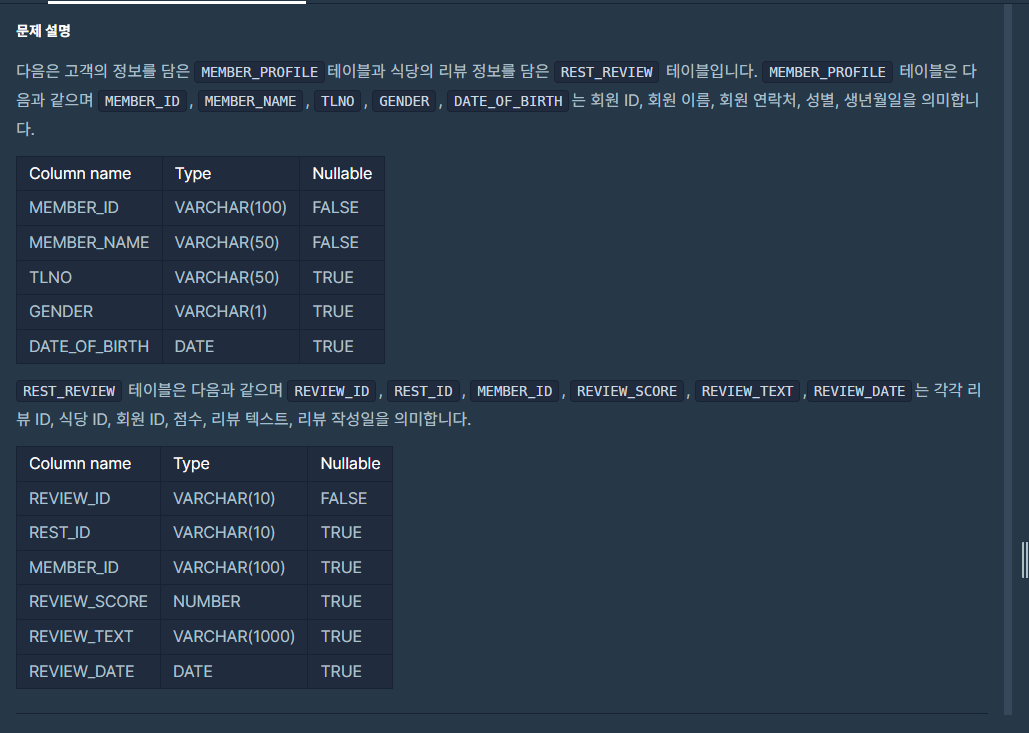
이번 게시글에서는 2가지 풀이법이 나옵니다.첫번째는 노가다(?)방식으로 여러 서브쿼리(총 3개)를 써서 푼 방식과두번째는 윈도우 함수를 이용하여 2개의 서브쿼리를 쓴 방식입니다.이번에도 풀이 과정이 다소 길기 때문에 가능한 정답 코드만을 보여주고, 제가 설명하고 싶은
10.[SQL 프로그래머스 문제풀이] (JOIN) '보호소에서 중성화한 동물'
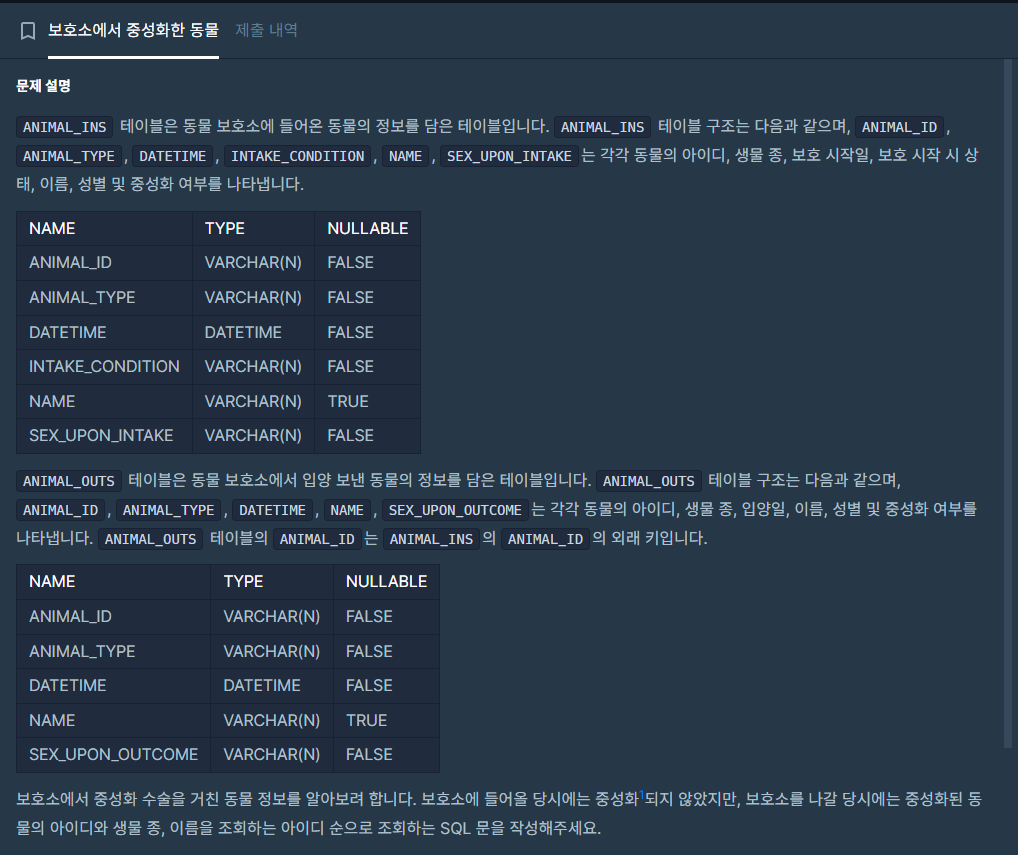
이번 게시글도 마찬가지로 개념 설명을 다소 적을 예정입니다.다만, 이전 게시글과는 다르게 오답 과정 부분은 별로 없으니 안심(?)하셔도 될 겁니다 ㅎㅎ..ANIMAL_INS 테이블과 ANIMAL_OUTS 테이블,이전 게시글에서 봤던 테이블들입니다.*테이블1.ANIMAL
11.[SQL 프로그래머스 문제풀이] (JOIN) 'FrontEnd 개발자 찾기'
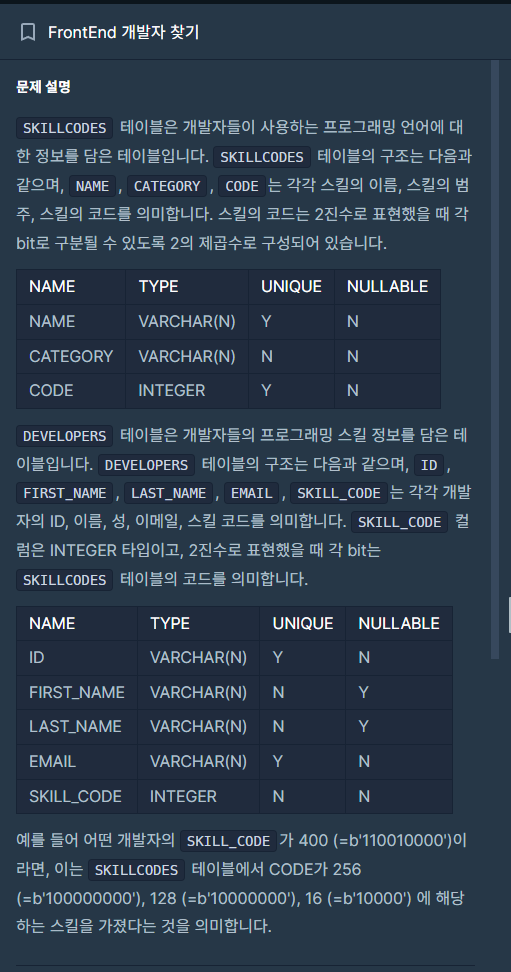
*테이블1.SKILLCODES(NAME,CATEGORY,CODE)\->코드는 2진수로 표현했을 때, 각 bit로 구분될 수 있도록 2의 제곱수로 구성됨.2.DEVELOPERS(ID,FIRST_NAME,LAST_NAME,EMAIL,SKILL_CODE)\->SKILL_CO
12.[SQL 프로그래머스 문제풀이] (JOIN) '상품을 구매한 회원 비율 구하기'
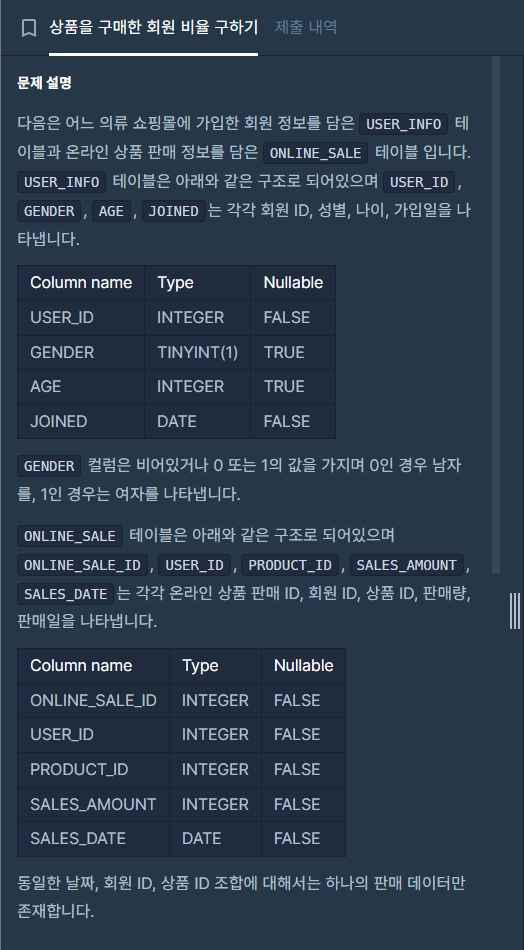
프로그래머스 유일한(?) LEVEL_5 문제입니다.LEVEL_5 문제이자 마지막 문제입니다.저는 이번 게시글에서1.먼저 정답 코드 관련 문제 풀이 과정 공개2.제가 처음에 접근한 풀이과정 방법(개념 설명 포함)이 순서로 글을 진행할 예정입니다.이번 문제는 SQL 해결
13.[LEETCODE 문제풀이] (WINDOW FUNCTION) #178 & #176번

지난 프로그래머스 JOIN 문제에 이어서, LEETCODE SQL WINDOW FUNCTION 문제를 풀기 시작하였습니다.오늘은, 나름 EASY(?) PART의 WINDOW FUNCTION 문제를 2개 풀었습니다.이전 게시글들과 같이 정답 코드 공유하고 설명하고, 제가
14.[LEETCODE 문제풀이] (WINDOW FUNCTION) #184 & #1204
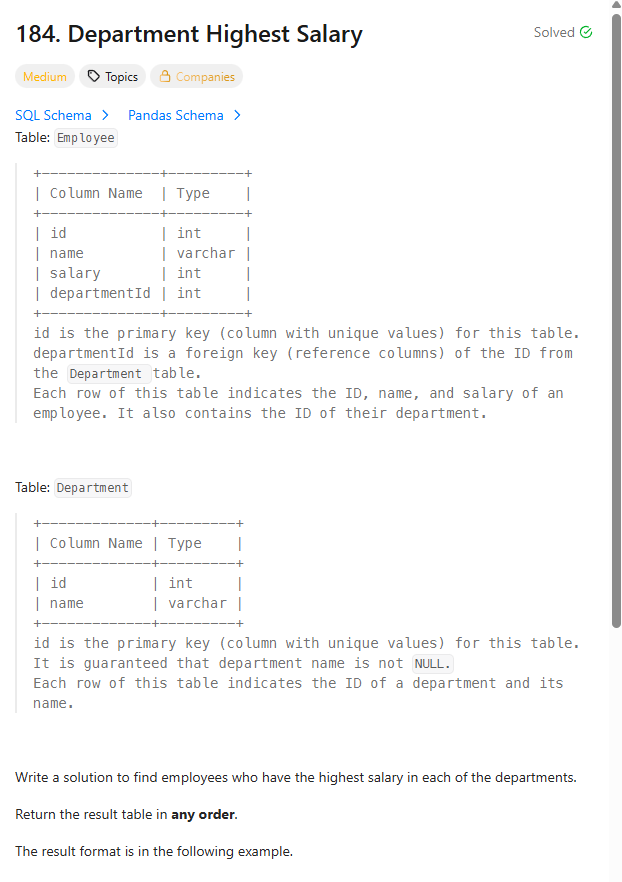
오늘도 윈도우 함수 관련 2문제를 가져왔습니다.난이도는 둘다 medium이라고 하네요.오늘도 역시 제가 설명하고 싶은 개념 설명을 추가로 할까 합니다.*테이블EMPLOYEE(ID(PK),NAME,SALARY,DEPARTMENTID(FK))DEPARTMENT(ID(PK)
15.[LEETCODE 문제풀이] (WINDOW FUNCTION) #1321 & #1164
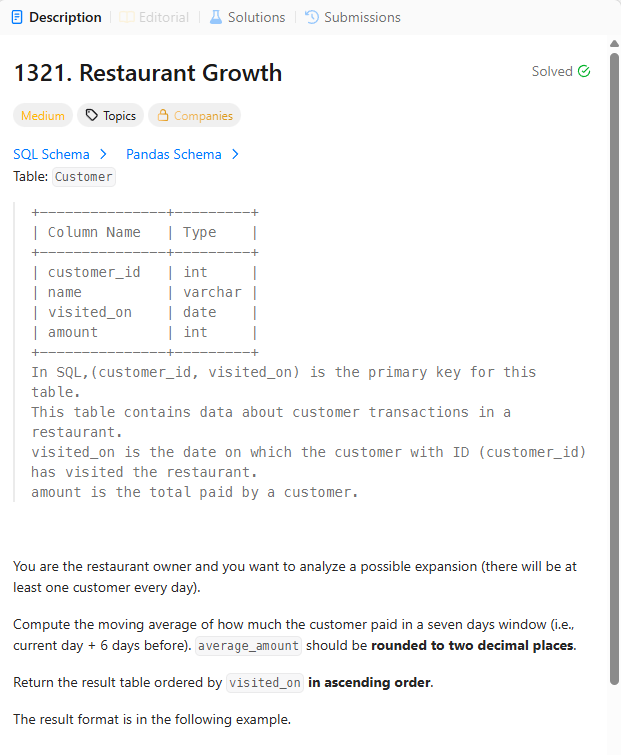
오늘 역시 leetcode window function medium 난이도의 문제 2개를 가져와봤습니다.오늘은 어렵다기보다는 처음 접한 개념들이 나올 예정이어서 이 부분 유의해서 보시면 될 거 같아요 :)*테이블CUSTOMER((CUSTOMERID,VISITED_ON)
16.[LEETCODE 문제풀이] (WINDOW FUNCTION) #601

오늘은 leetcode window function 마지막 문제 풀이입니다.마지막인만큼 hard 문제로 가져와봤고요.hard인데 정답률이 50%나 돼서 좀 의심스럽지만...나름 재밌게 푼 문제인 거 같습니다.이번 게시글도 마찬가지로 문제 풀이 과정 및 제가 소개하고 싶
17.[실습] MySQL 인덱스 성능 실험 - 100만건 데이터로 비교하기

안녕하세요!이번에는 문제 풀이가 아닌 실습으로 돌아왔습니다!sql에는 인덱스라는 개념이 있는데요.간단하게 말하자면, 이 '인덱스'는 '조회를 빠르게 하기 위함'이라고 말할 수가 있습니다.인덱스에 대한 개념 정리를 자세하게는 하기 힘들 거 같긴 한데요...그래도 개념 설
18.[실습] Pandas 데이터 실습 및 ETL Pipeline 체험하기
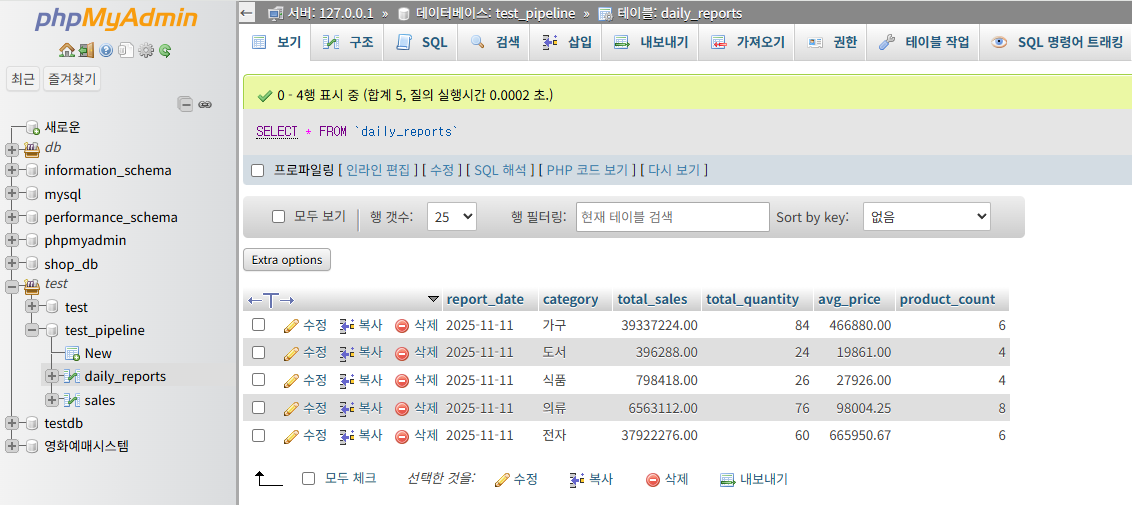
이번 게시글은 필요한 부분만 글을 쓰려고 합니다.제 github 링크를 올려드리오니, 여기서 참고하시면 될 거 같습니다.'sales_data.ipynb' Jupyter Notebook으로 진행하였습니다.아무래도 일반 파이썬 파일보다는 독립적인 셀 단위로 실행이 되어서,
19.[Phase 2] Phase 1을 끝내고, Phase 2에 들어가며..

안녕하세요. 이번 게시글에는 '데이터 엔지니어링'의 큰 단계 중 2번째 단계인 'Phase 2'의 입문에 대해서 글을 써보고자 합니다. > 제가 현재 작성하는 이번 게시글 앞에 작성한 게시글들은 전부 'phase 1' 단계였는데요. > 'Phase 1'에서는, '데이터
20.[Phase 2-2, 2-3,2-4] 삼성전자 주식 ETL 한번에 보기
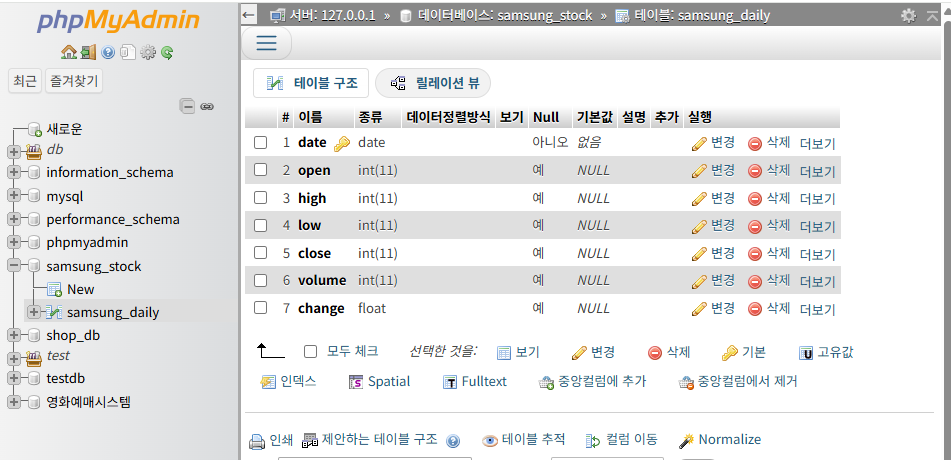
이번 게시글에는 'phase 1'에서 맛 봤던 ETL 파이프라인 프로세스를 '삼성전자 주식'을 활용해서 한번 더 만들어볼꺼 합니다.https://github.com/pilmalion114/data_engineer_portfolio/tree/main/phase%
21.[Phase 2-5] Docker 및 Airflow DAG로 자동화하기

이번 게시글은 저도 처음 경험하는 'Docker' 및 'Apache Airflow DAG'에 대해서 설명을 합니다. 꽤 긴 글이 될 수 있으니 참고 바랍니다.그리고, 이 게시글은 우리가 이전에 했던 'phase 2-2,2-3,2-4의 ETL 과정을 자동화하는 과정이라고
22.[phase 2-6] 로그(log) 남기기

오늘은 'phase 2'의 마지막 단계인 'phase 2-6: 로그 남기기'에 대해서 글을 작성하고자 합니다.이번 게시물은 따로 코드 관련한 내용은 없고, 이미 전 단계들에서 했던 것들을 다시 가져오는 수준의 작업이 진행되기 때문에(이미 전 단계에서 다 한 것들입니다.
23.[Phase 3-1] AWS 세팅하기

'Phase 3'는 '클라우드 & 대용량 데이터 처리'하는 파트입니다.\->이런 이유로 'AWS' 선택을 하게 되었습니다.다른 사이트에서 계정 생성하는 것처럼 계정을 새로 만들면 됩니다.\->현재 제 AWS Console 화면입니다.\->Region 변경\->Billi
24.[Phase 3-2] AWS S3 Bucket ~ Upload,Download.py ~ 기타
이번 'phase 3-2'는 S3 Bucket이라는 AWS의 저장소(repository) 개념을 접하게 되고, 단순 웹 UI에서 파일 업로드/다운로드 뿐만이 아닌,boto3라는 라이브러리를 활용하여 파이썬 코드로 파일 업로드/다운로드를 하는 과정을 담았습니다.(핵심)그
25.[Phase 3-3] AWS lambda

즉, lambda 또한 쉽게 말해 '자동화' 작업이라고 생각하면 된다.위 첨부한 사진들의 설명대로 이해하자면,lambda는 기존 방식의 하루 종일 서버를 켜서 관리하는 것이 아닌, 필요할 때만 사용하는 것을 말한다.좀 더 이해하기 쉽게 밑에 비유 예시를 달아두었다.\-
26.[Phase 3-4] AWS RDS(Database)

\-> Lambda 자동화 함수를 이용해서 내 기존의 웹 phpmyadmin mysql 대신에 AWS 데이터베이스(RDS)에 저장하는 것이다.우리는 phase 3-3에서 JSON 파일 형식으로 데이터를 저장한 경험이 있다.그렇다면, 왜 굳이 귀찮게 RDS를 설계해야할까
27.[Phase 3-5] AWS Glue & Athena

어느 덧 'Phase 3'의 마지막 단계인 'Phase 3-5'에 들어왔습니다.본격적으로 설명 들어가기에 앞서 간단하게 'phase 3-5'에서 뭘 하는지 알아보도록 하겠습니다.즉, 간단하게 말하자면,'S3 버킷에 저장되어 있는 파일을 AWS Glue와 Athena를
28.[Phase 4-1] Dimensional Modeling & Star Schema

이번 게시글부터는 메모 스타일을 변경할까 합니다.기존의 '모든 것을 적는 디테일함' -> '핵심 요약으로 간단하게'로 변경할까 합니다.각각의 스타일에 장·단점이 있다고 생각합니다.이번에 이렇게 바꾸게 된 이유는, '간편하고 핵심적인 것만 요약해서 보는 것이 제 뇌에 효
29.[phase 4-2] dbt(data build tool)

이번에도 마찬가지로 핵심 요약만 작성하도록 하겠습니다.※이번 게시글에는 제 깃허브 링크가 몇 개 밖에 없을 수 있습니다.따라서, 다음 제 phase 4-2 전체 깃허브 링크를 공유드리고자 합니다.확인하고 싶은 부분들은 해당 깃허브 링크로 따라가서 확인해주시면 감사하겠습
30.[Phase 5-1] Spark 기초

이번 'Phase 5'는 본격적으로 빅데이터를 다루는 단계입니다. 이번 게시글의 순서는 다음과 같습니다.1.Spark vs Pandas 개념 핵심 요약2.Google Colab 실습 \->Pandas vs Spark 비교표\-> Lazy Evaluation(게으른 실행
31.[Phase 5-2] Spark 본격 실습
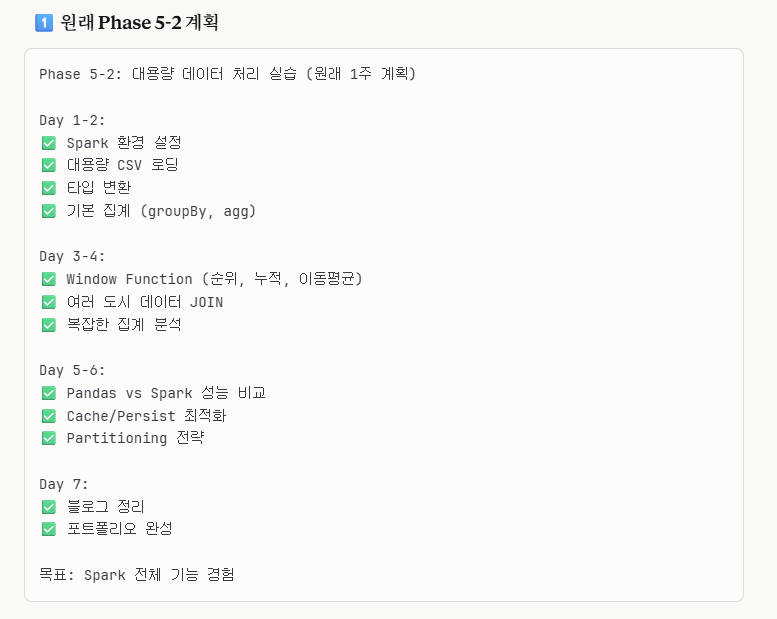
정말 속상하게도, 이번 작업은 제대로 이루어지지 않았다.그 이유에 대해서는 뒤에서 설명을 하도록 하겠다.이번 게시글은 프로젝트 학습 내용보다는 무엇이 문제였는지 회고하는 식의 게시글이 될 거 같다.원래의 우리 계획은 이렇게 할 예정이었다.하지만, 이번 작업은 완전히 망
32.[데이터 엔지니어링 3가지 실무 과제] - 1. Extreme Scalability
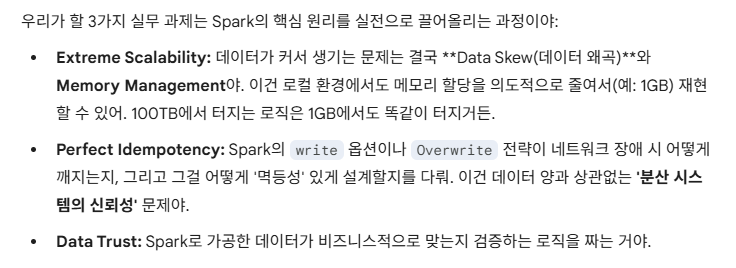
이번 게시글부터 이후의 게시글들까지 총 약 3개의 게시글에서는 실제 실무와 관련한 내용들이 나올 예정이다.대략적인 3가지 실무 과제의 내용들은 다음과 같다.1.Extreme Scalability: 극단적 확장성2.Perfect Idempotency: 완벽한 멱등성※멱등
33.[데이터 엔지니어링 3가지 실무 과제] - 2. Perfect_Idempotency

이번 2번째 exercise에서는 'Perfect Idempotency(완벽한 멱등성)'에 대해서 실험 실습을 진행해보았습니다.이번에도 마찬가지로, 멱등성과 관련한 자세한 과정은 제 깃허브에 올린 .ipynb에 자세하게 설명되어 있으니,이번 글에서는 간단하게 핵심 과정
34.[데이터 엔지니어링 3가지 실무 과제] - 3. Data_Trust
이번 게시글은 제 3가지 실무 과제들 중 마지막 단계인 '3.Data Trust(데이터 신뢰성)'에 대해서 실습을 하는 시간을 가져봅니다.어느 덧 마지막 단계까지 왔네요...데이터 엔지니어링 독학 학습 과정, 약 2.5개월 정도를 지나오면서, 때로는 천천히 때로는 급하
35.[데이터베이스] ⭐SQL 실행 순서
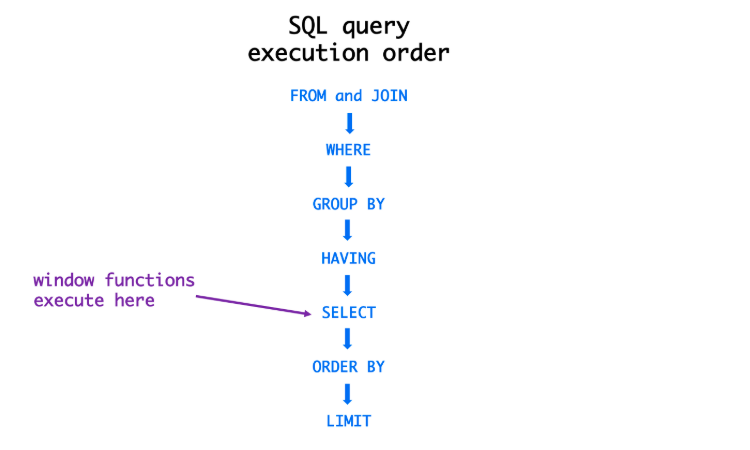
가장 근본이자 기본이자 꼭 알아야 되는 SQL 쿼리 실행 순서!!※출처:https://jaehoney.tistory.com/191 (JaeHoney님 글 참조)