오늘 역시 leetcode window function medium 난이도의 문제 2개를 가져와봤습니다.
오늘은 어렵다기보다는 처음 접한 개념들이 나올 예정이어서 이 부분 유의해서 보시면 될 거 같아요 :)
#1321번
1. 문제 소개
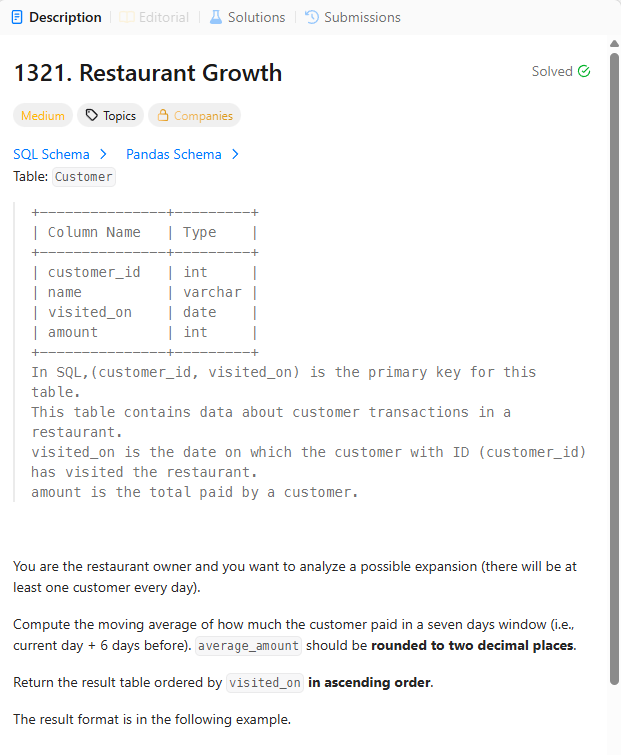
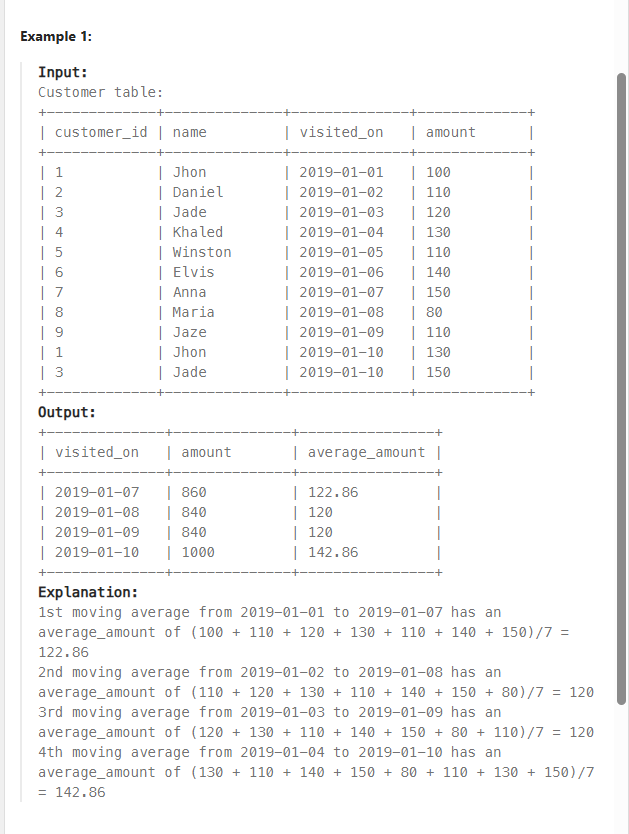
*테이블
CUSTOMER((CUSTOMERID,VISITED_ON)(PK),NAME,AMOUNT)
*문제
You are the restaurant owner and you want to analyze a possible expansion (there will be at least one customer every day).
Compute the moving average of how much the customer paid in a seven days window (i.e., current day + 6 days before). average_amount should be rounded to two decimal places.
Return the result table ordered by visited_on in ascending order.
-> 하루 최소 한 명 이상의 고객이 있음. 7일치의 '이동 평균' 값을 구하라. 평균 AMOUNT값은 소수점 셋째자리에서 반올림하여 둘째자리까지 나타냄.
VISITED_ON 기준으로 오름차순 정렬하라.
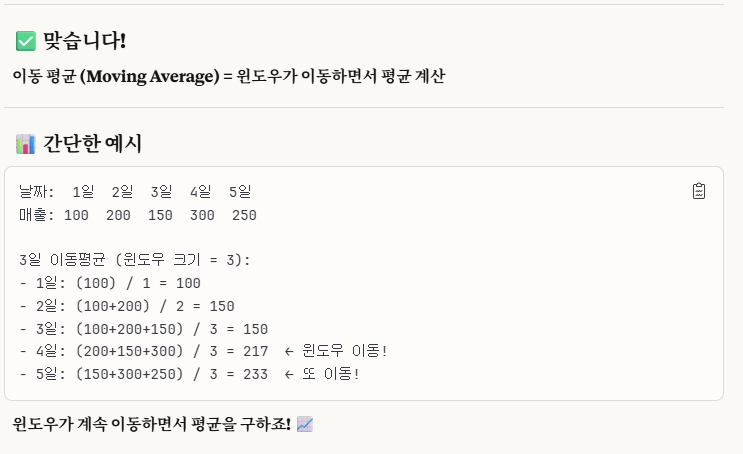
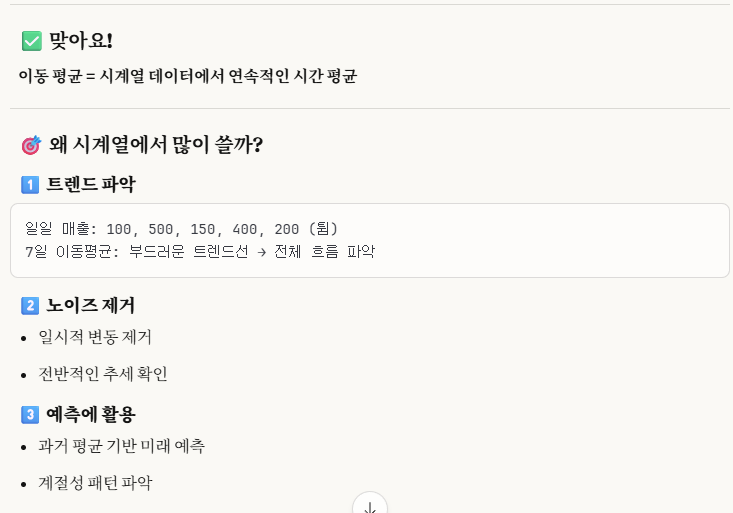
개념_1) ※이동 평균(Moving Average, MA)이란?
이동 평균이란, 평균값을 구하는 건데, WINDOW의 크기에 따라 이동하면서 평균을 구하는 것이다.
주로 시계열 같이 TIME SERIES에서 연속적인 시간 평균을 구할 때 쓴다.
2. 문제 풀이
문제가 잘 이해가 안 가서, 예시를 보고 이해하였다.
문제 자체는 단순해보이는데, sql에 이동 평균을 구하는 방법이 막상 떠오르지 않았다.

그러다가 위의 사진을 보고, 윈도우 함수 중에 '값 참조 함수'인 lag()와 lead()가 떠올랐다.
※개념_2. Lag() vs Lead()
한 마디로, lag()는 이전 값 참조, lead()는 이후 값 참조를 의미한다.


그러다가 전에 윈도우 함수 관련해서 따로 정리한 문서에서 'sum() over()' 누적 합계, 이동 평균 등 계산하는 집계 window function 및 이동 평균 예제가 있어서 참고해보았다.


위의 '이동 평균(3개월)' 예시를 보니,
우리가 풀어야 할 문제 양식과 거의 똑같음을 알 수 있었다.
(구조상 동일했다.)
따라서, 이 예시를 보고 sql문을 작성하였다.
SELECT
visited_on,
amount,
sum(amount) over(order by visited_on ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) as amount_1,
avg(amount) over(order by visited_on ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) as average_amount
from customer일단은 위 코드를 먼저 간략하게 설명하자면,
sum over, avg over 둘다 over를 사용하므로 윈도우 함수이고, 또한 윈도우 함수이므로 각각의 행을 유지한다.
over절 안에 있는 sql문을 해석하자면,
visited_on 열로 order by (asc)로 하고(생략이면 default 값은 asc이다.), 'ROWS BETWEEN 6 PRECEDING AND CURRENT ROW'의 의미는 문장 그대로 해석하면 되는데,
ROWS(연속으로) BETWEEN 6 PRECEDING(6개의 이전의 값들) AND CURRENT ROW(현재의 행)
즉, 6개의 이전 연속 값들과 현재의 행 1개를 합쳐서 총 SIZE가 7인 윈도우를 만들겠다. 이동 평균을 만들겠다라는 의미이다.
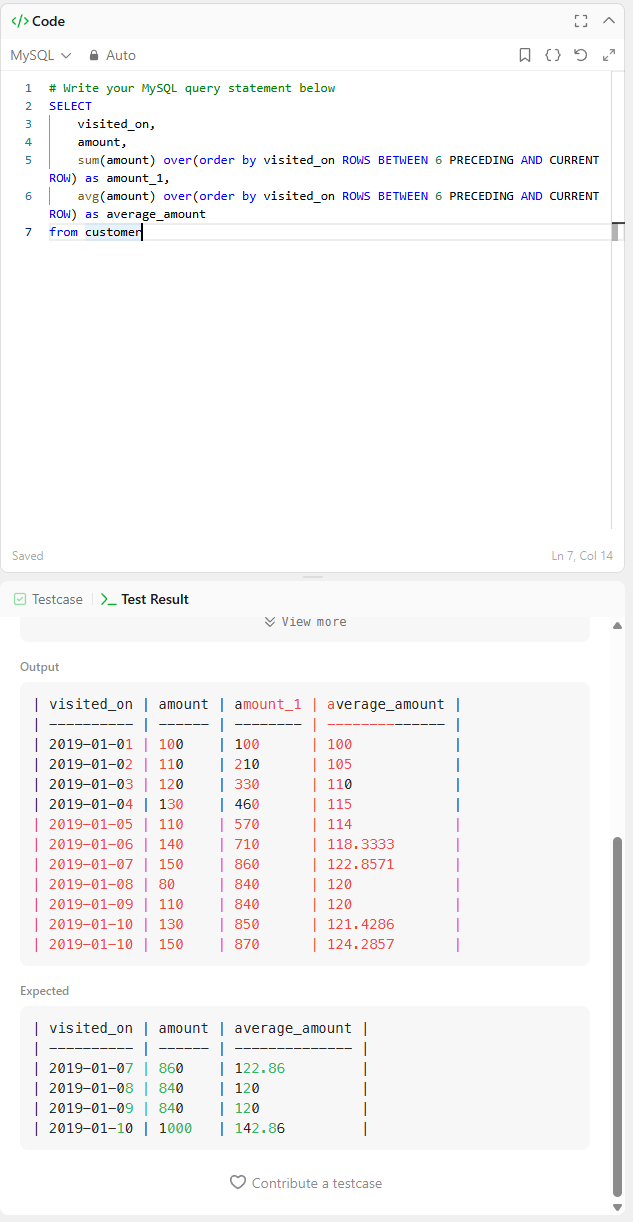
나는 위 결과 사진을 보고 FORMAT 형식만 정답 형식 꼴로 맞추면 되겠다고 생각했다.
SELECT
visited_on,
-- amount,
sum(amount) over(order by visited_on ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) as amount,
ROUND(avg(amount) over(order by visited_on ROWS BETWEEN 6 PRECEDING AND CURRENT ROW),2) as average_amount
from customer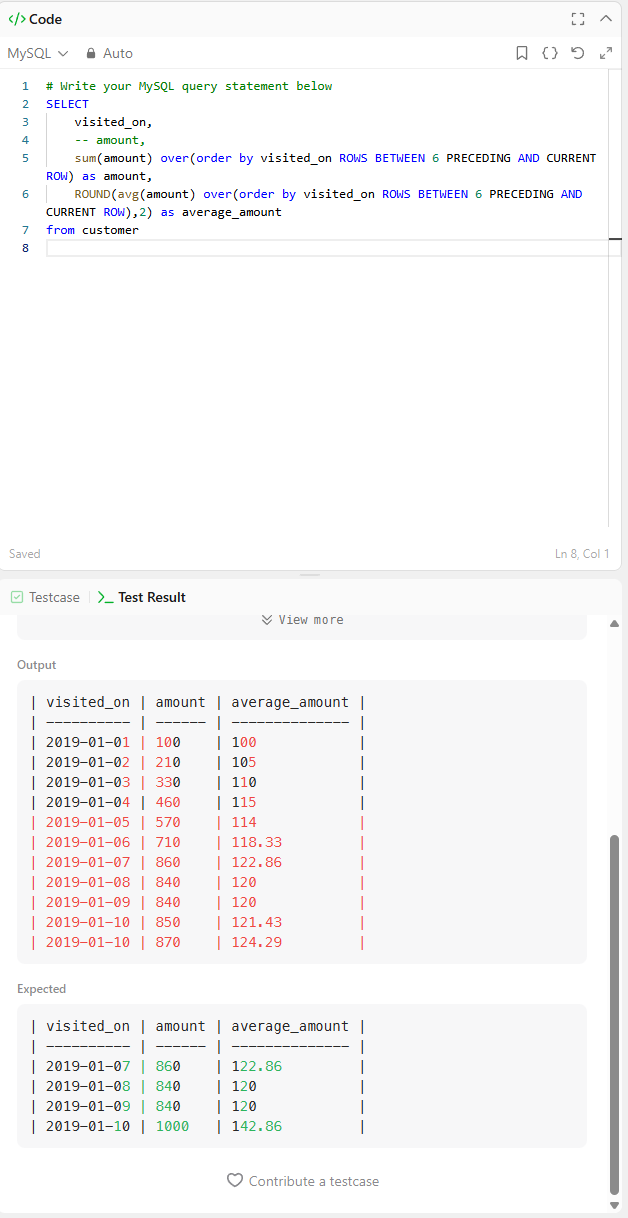
하지만 여기서 2가지의 문제가 생겼다.
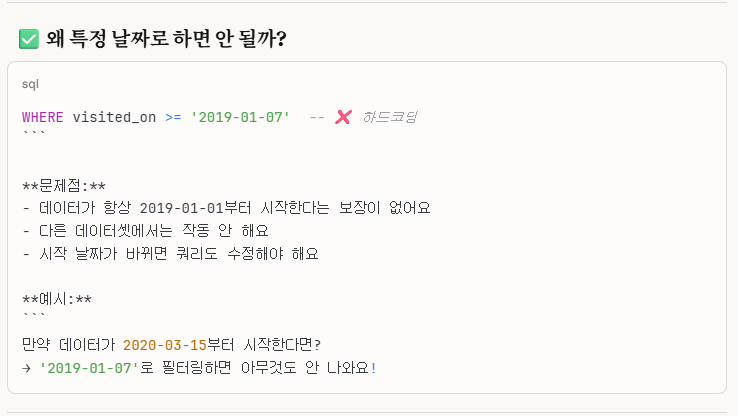
1.VISITED_ON에서 시작 날짜 설정을 어떻게 맞출 것인가?
2.1-10일 부분의 AMOUNT 부분이 틀린데?
CLAUDE로부터 힌트를 얻었다.
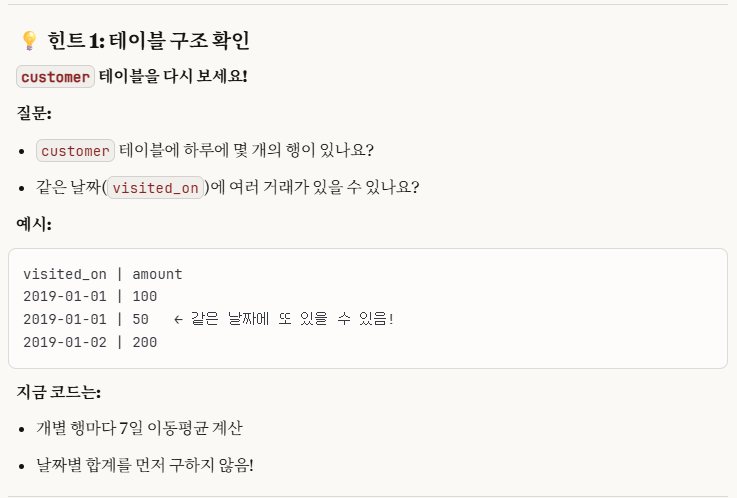
그렇다.
자세히 살펴보니, 1/10일에 2개의 데이터가 있었다.
이를 GROUP BY를 통해 하나로 합치고 집계를 진행했어야 했다.
그 다음에는, VISITED_ON 날짜 조건 설정을 하는 것인데,
이 또한 CLAUDE의 도움을 받았다.
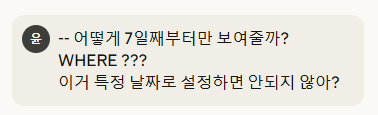
그렇다.
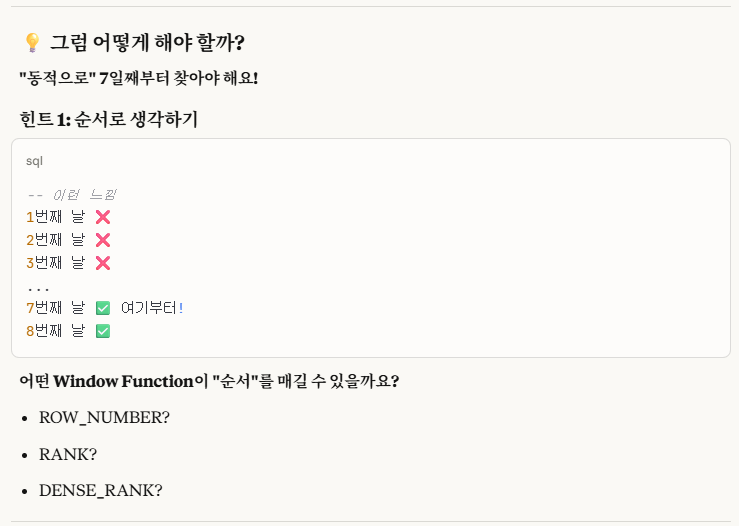
우리는 무조건 특정 날짜 기준(EX.2019-01-01부터 시작)으로 시작한다는 조건이 없으므로, 정적이 아닌 '동적'으로 구현을 해야한다.
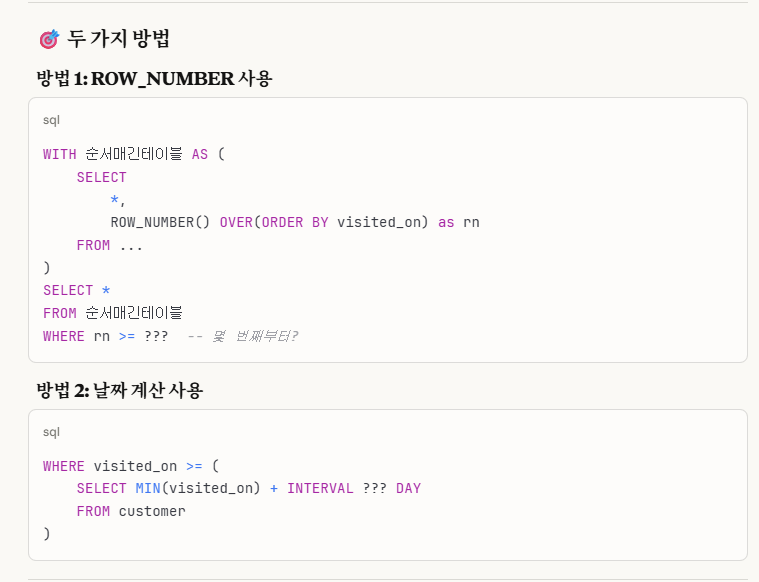
여기에는 2가지 방법이 있는데,
1.ROW_NUMBER 사용
2.날짜 계산 사용
ROW_NUMBER는 이전에도 다뤄봤고,
직관적으로 인덱스 개념처럼 접근하면 되므로
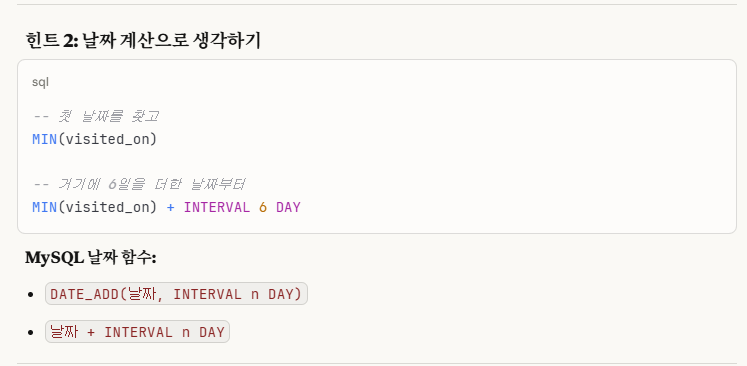
우리는 해보지 않았던 '날짜 계산 사용'으로 접근을 해보고자 한다.
SELECT
VISITED_ON,
SUM(DAILY_AMOUNT) OVER(order by visited_on ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) as amount,
round(AVG(DAILY_AMOUNT) OVER(order by visited_on ROWS BETWEEN 6 PRECEDING AND CURRENT ROW),2) as average_amount
FROM(
SELECT
VISITED_ON,
SUM(AMOUNT) AS DAILY_AMOUNT
FROM CUSTOMER
GROUP BY VISITED_ON
) as t_1
where visited_on >= (
select min(visited_on) + interval 6 day
from customer
)위 2가지 SOLUTION을 적용한 전체 코드이다.
위 전체 코드에는 서브쿼리를 사용하였는데,
서브쿼리를 통해 먼저 GROUP BY + 집계를 완료하고,
그 결과를 메인 SELECT문에서 윈도우 함수를 통해 구현을 하였다.
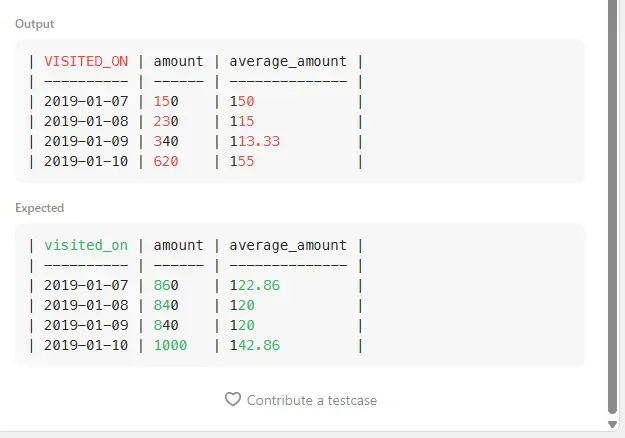
그런데, 값이 다르게 나온다.
뭐가 문제일까?
아무리 고민을 해봐도 문제가 무엇인지 알 수 없었다.
CLAUDE에게 물어봐도 로직이 꼬였는지 오답만 답변하였다.
CLAUDE가 서브쿼리 부분 먼저 검토를 해보라고 했다.
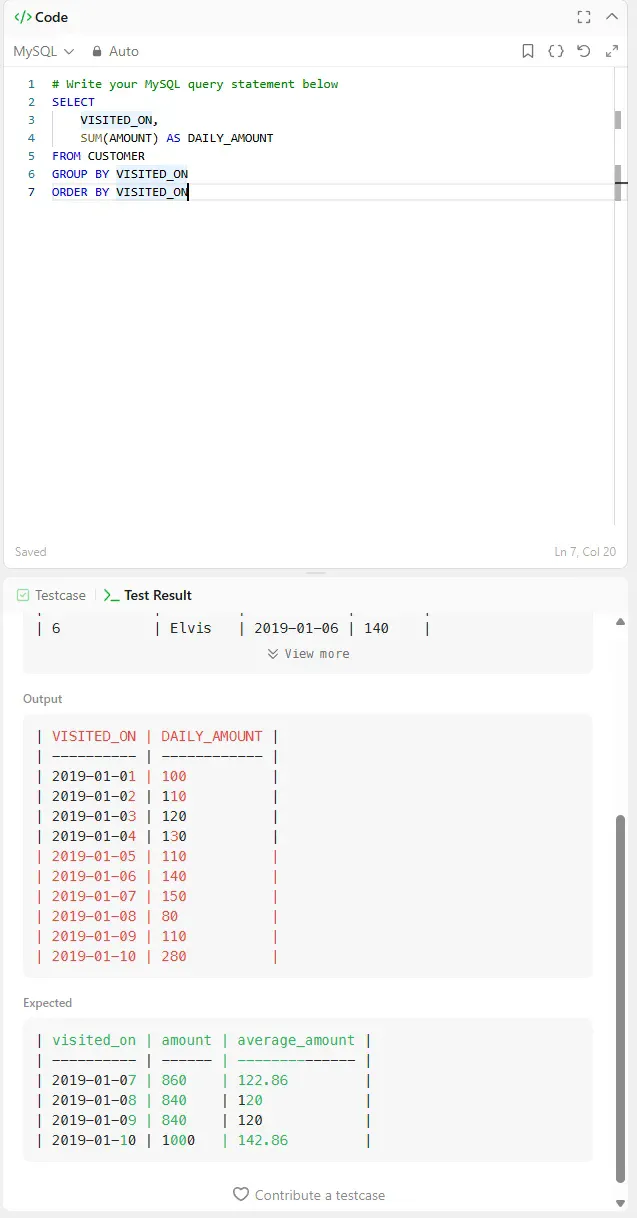
서브쿼리 부분은 정상적으로 잘 나왔음을 확인할 수 있다.
그러다가 CLAUDE가 WHERE절의 위치가 문제라고 해답을 주었다.
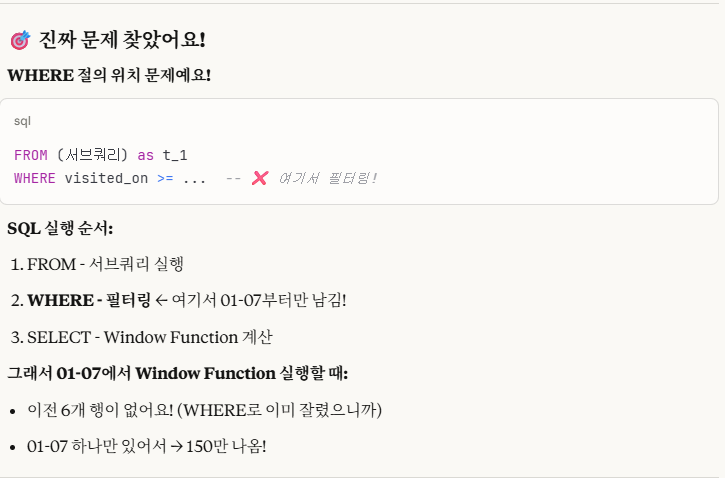
그렇다.
결과를 보니, CLAUDE의 말처럼 SQL의 작동 순서에 의해서 FROM 다음에 SELECT절보다 WHERE절이 작동을 하므로,
WHERE절의 조건식에 의해서 1/1~1/6일치의 데이터는 버린 후, 1/7일 데이터부터 시작한다.
그래서 값에서 오류가 나왔던 것이다.
이를 해결하는 방법은 다음과 같다.
<최종 정답 코드>
SELECT *
FROM(
SELECT
VISITED_ON,
SUM(DAILY_AMOUNT) OVER(order by visited_on ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) as amount,
round(AVG(DAILY_AMOUNT) OVER(order by visited_on ROWS BETWEEN 6 PRECEDING AND CURRENT ROW),2) as average_amount
FROM(
SELECT
VISITED_ON,
SUM(AMOUNT) AS DAILY_AMOUNT
FROM CUSTOMER
GROUP BY VISITED_ON
) as t_1
) AS t_2
where visited_on >= (
select min(visited_on) + interval 6 day
from customer
)기존의 코드를 한번 더 감싸서 그 자체를 서브쿼리로 만들고,
WHERE절을 그 밖에다가 작성하는 것이다.
이렇게 하면,
윈도우 function 계산이 아예 끝난 후에 where절 실행하는데,
어차피 하나로 크게 묶었으므로,
전체 계산된 결과에서 조건식으로 추출하는 꼴이 되는 것이다.
#1164번
1. 문제 소개
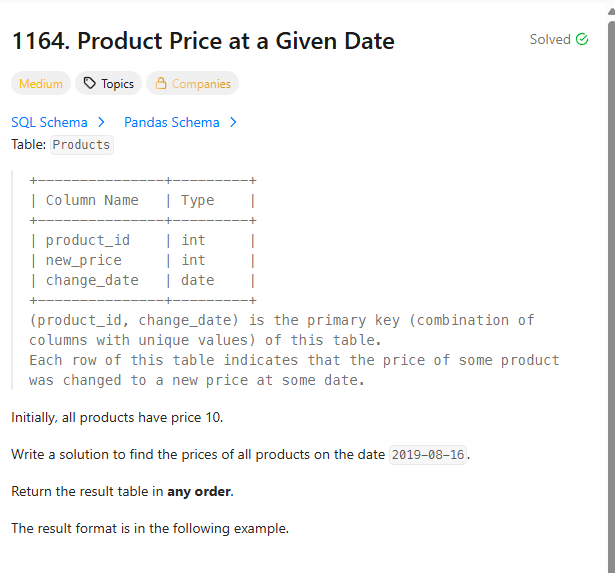
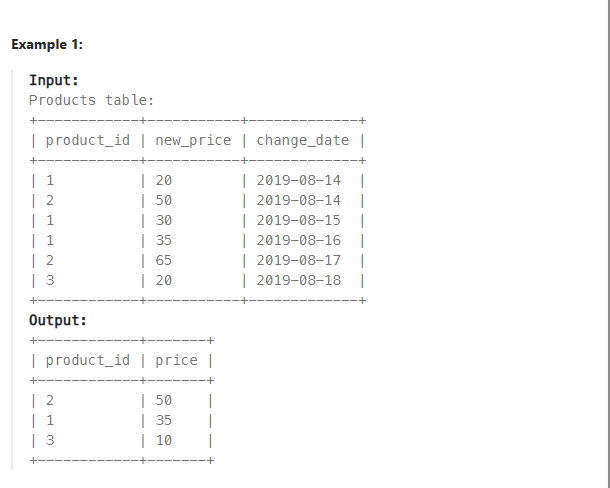
*테이블
PRODUCTS((PRODUCT_ID,CHANGE_DATE)(PK), NEW_PRICE)
*문제
Initially, all products have price 10.Write a solution to find the prices of all products on the date 2019-08-16.
Return the result table in any order.
초기 설정은, 모든 제품 가격은 10임.
2019-08-16 날짜의 모든 제품들의 가격을 보여라.
결과 테이블 순서는 어떻게든 상관 없음.
2. 문제 풀이
이 역시 예제를 보고 나서야 이해하기가 쉬웠습니다.
요구하는 문제를 다시 한번 요약하자면,
'2019-08-16'일을 기준으로 각 제품의 가격을 출력하면 되는 것이었습니다.
어떻게 접근하면 좋을까? 고민을 해보았습니다.
1.LAG(),LEAD() 개념을 사용하는 것인가?
2.WHERE CHANGE_DATE <= 2019-08-16 , WHERE CHANGE_DATE > 2019-08-16
3.좀 어려운데..? PARTITION BY로 더 세분화해야되나..?
4.아... 이거 이동 평균때 문제 푼 거처럼.. 아 아닌가..?
위와 같이 고민을 하다가 이렇게 해답을 내놓았습니다.
※아 그럼,
2019-08-16 날짜 이후는 버리고,
이전 날짜들 중에서, PRODUCT_ID 기준으로 PARTITION BY하고,
각 파티션(분할)한 거 중에, CHANGE_DATE가 가장 높은 거 선택하면 되는 구나.
->없으면 IFNULL로 처리
전체적인 풀이 과정은 맞지만, 세부적인 부분에서는 오류가 있으니, 이는 추후 진행하면서 설명드리도록 하겠습니다.
2-1. '2019-08-16' 이후 날짜는 버리기
이는 아주 간단하게 sql 쿼리문을 작성할 수 있습니다.
<정답 코드>
SELECT
PRODUCT_ID,
NEW_PRICE,
CHANGE_DATE
FROM PRODUCTS
WHERE CHANGE_DATE <= '2019-08-16'설명은 생략하겠습니다.
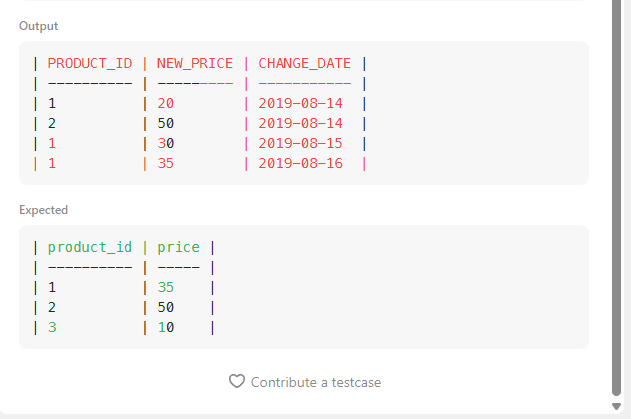
2-2. 1번 결과에서(서브 쿼리) PRODUCT_ID 기준으로 PARTITION BY하기 & CHANGE_DATE 기준 가장 높은 거 선택하기
<정답 코드>
SELECT *,
RANK() OVER(PARTITION BY PRODUCT_ID ORDER BY CHANGE_DATE DESC) AS TEMP -- RANK()는 인자가 불필요하다.
FROM
(SELECT
PRODUCT_ID,
NEW_PRICE,
CHANGE_DATE
FROM PRODUCTS
WHERE CHANGE_DATE <= '2019-08-16') AS T_1코드 설명을 간단하게 하자면,
위 1번 결과 코드를 서브쿼리로 두고, rank() 윈도우 함수를 통해 product_id 기준으로 partition by를 하고, change_date 기준으로 order by를 하여 이를 'temp'라고 별칭을 지어주었습니다.
※개념_1. rank() 함수는 인자가 불필요하다.
순위는 이미 order by절로 구현하기에, 인자가 따로 필요하지는 않다.

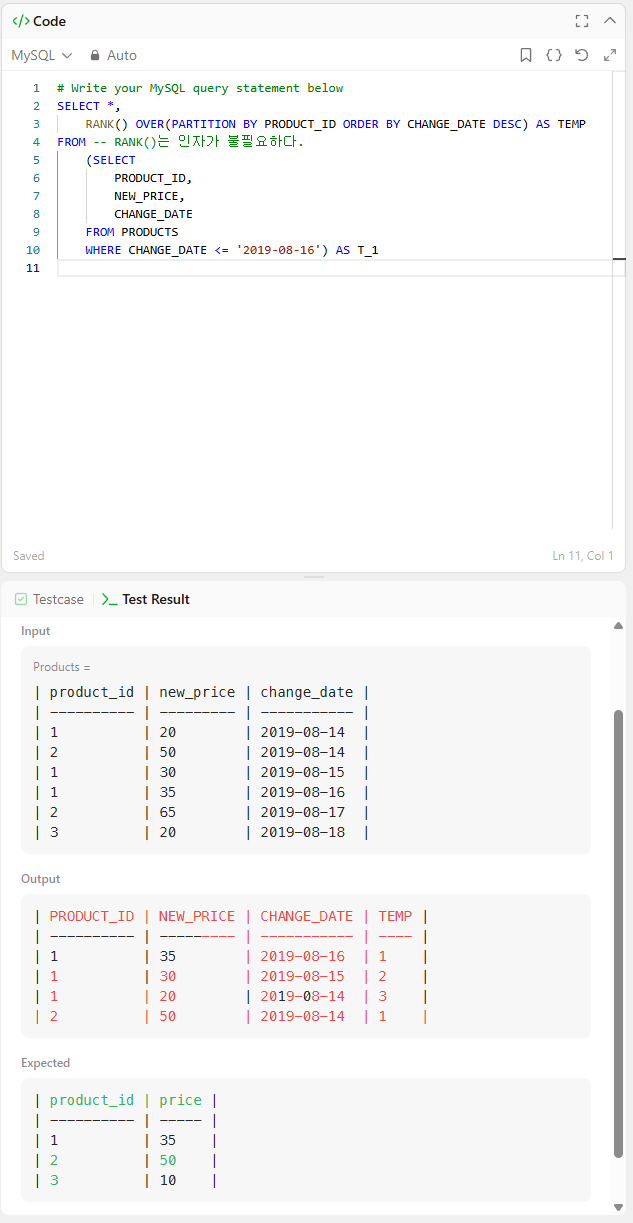
여기까지 내가 원하는 결과가 나왔다.
2-3. ifnull 넣기?
?를 붙인 이유를 알아야 한다.
결론을 먼저 말하자면, 틀린 접근법이다.
왜 틀린 것일까?
cf.) TMI: 맨 처음엔 limit 1 & ifnull로 하면 끝인 줄 알았다.
그렇게 해서 나타낸 코드는 다음과 같다.
SELECT *, RANK() OVER(PARTITION BY PRODUCT_ID ORDER BY CHANGE_DATE DESC) AS TEMP, IFNULL(PRODUCT_ID,10) FROM -- RANK()는 인자가 불필요하다. (SELECT PRODUCT_ID, NEW_PRICE, CHANGE_DATE FROM PRODUCTS WHERE CHANGE_DATE <= '2019-08-16') AS T_1
뭔가 고칠 부분이 많아보인다.
그래서 claude에게 질문을 하였다.
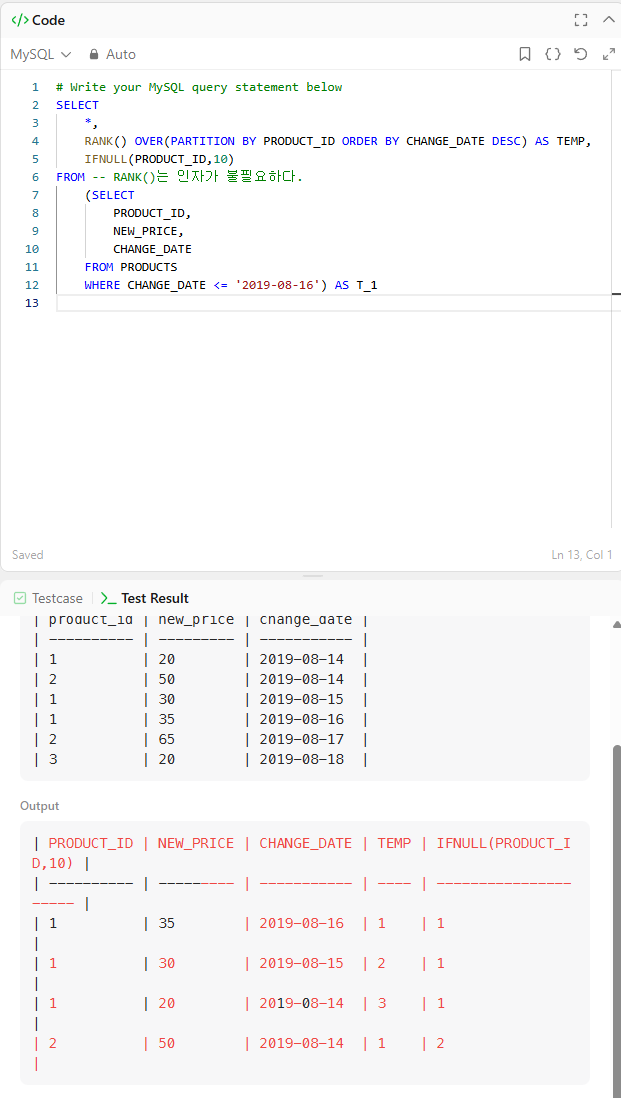
claude에게 물어보니, 다음과 같은 답변을 받았다.
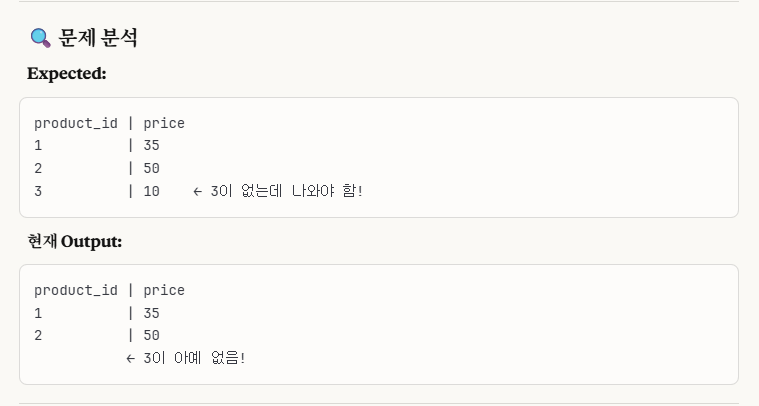
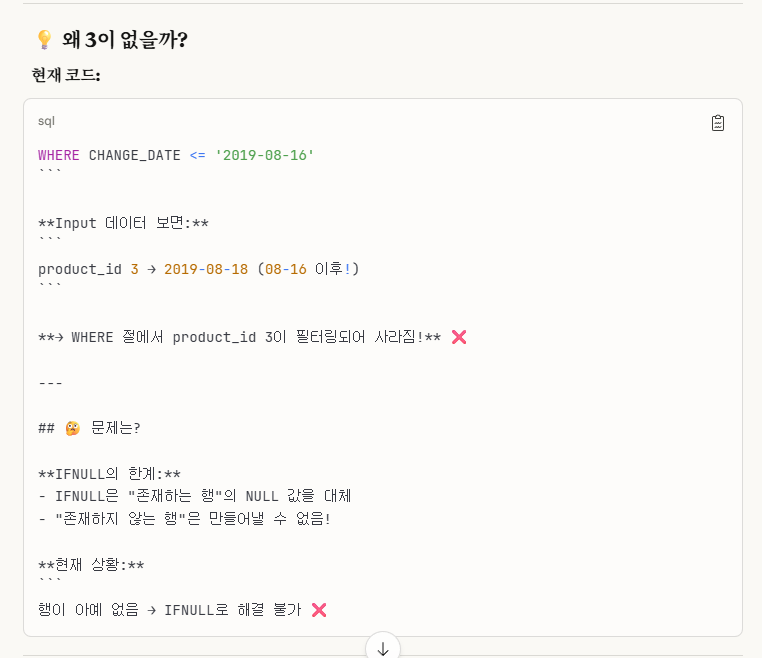
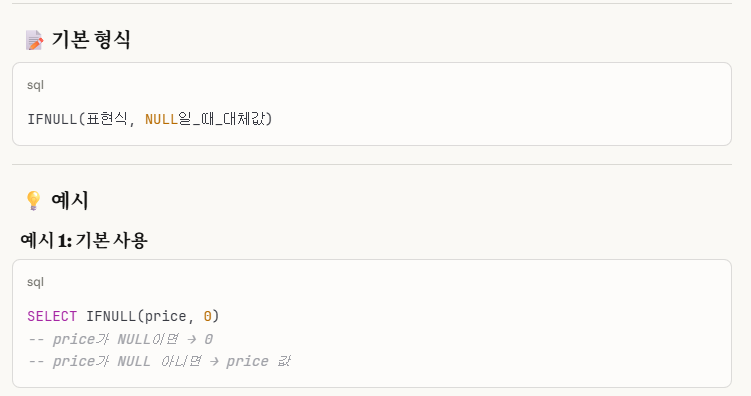
그렇다.
ifnull은 '존재하는 행'에 대해서, null이면 대체값을 아니면 표현식 값을 나타내는 문법인 것이다.
즉, '존재하지 않는 행'에 대해서는 오류가 난다는 의미이다.
그러면 어떻게 구현하면 될까?
2가지의 방법을 제안받았다.
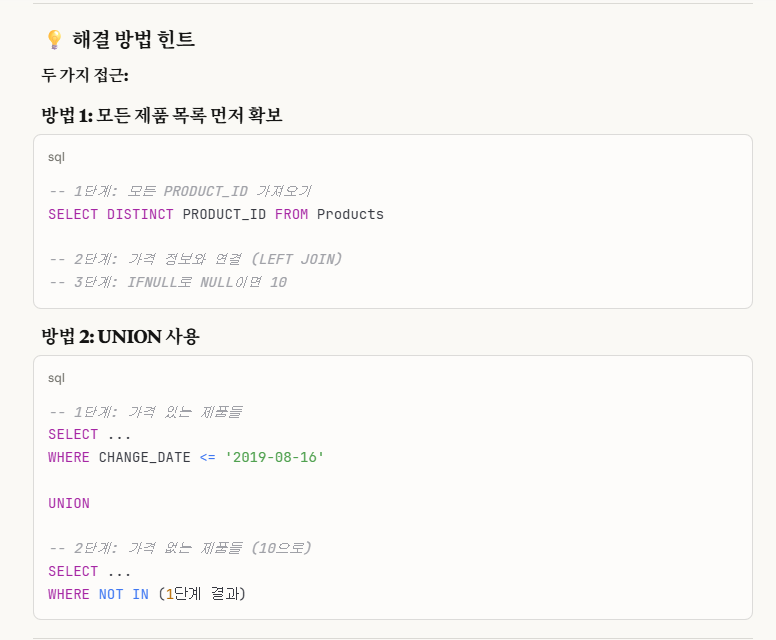
하지만 나는 위 '방법 1'의 경우에는,
만에 하나 모든 제품 목록을 확인해봤는데, 해당 product가 없을 수도 있다는 가정 하에서(예시에는 있지만, 없을 수도 있다는 가정 하에서), 이 방법은 배제시켰다.
->뭔가 하드코딩적인 느낌이 나서...
그래서 나는 위 '방법 2'인 'union(합집합)'으로 문제를 접근하였다.
※개념_2. union(합집합)
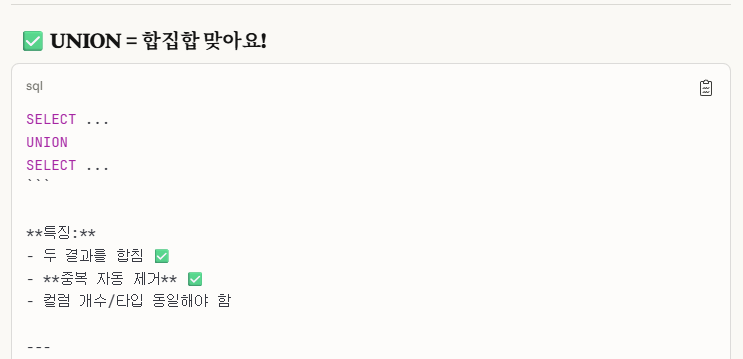
합집합으로 문제를 푸는 방법은 이런 식으로 풀면 된다.
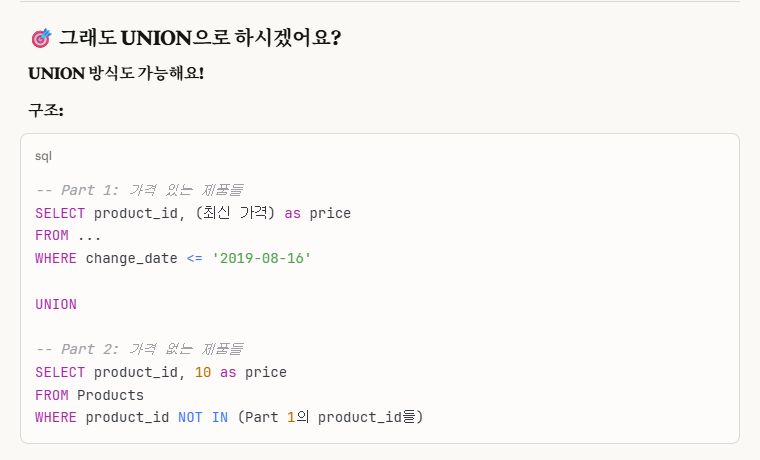
이렇게 메인 select문을 2개로 나눠서
1개는 '2019-08-16' 기준으로 최신 가격이 있는 제품들을,
다른 1개는 가격이 없는 제품들로 나눠서,
칼럼 갯수/타입을 동일시해서 나타내면 된다.
2-3-1. 1번 메인 select문
먼저, '가격이 있는' 제품들을 select하는 코드를 짜도록 하겠다.
<내 정답 코드>
SELECT *
FROM(
SELECT
*,
RANK() OVER(PARTITION BY PRODUCT_ID ORDER BY CHANGE_DATE DESC) AS TEMP
-- IFNULL(PRODUCT_ID,10)
FROM -- RANK()는 인자가 불필요하다.
(SELECT
PRODUCT_ID,
NEW_PRICE,
CHANGE_DATE
FROM PRODUCTS
WHERE CHANGE_DATE <= '2019-08-16') AS T_1) AS T_2
-- LIMIT 1 -- 결과값 중에서 상위 결과 1개만 나옴.
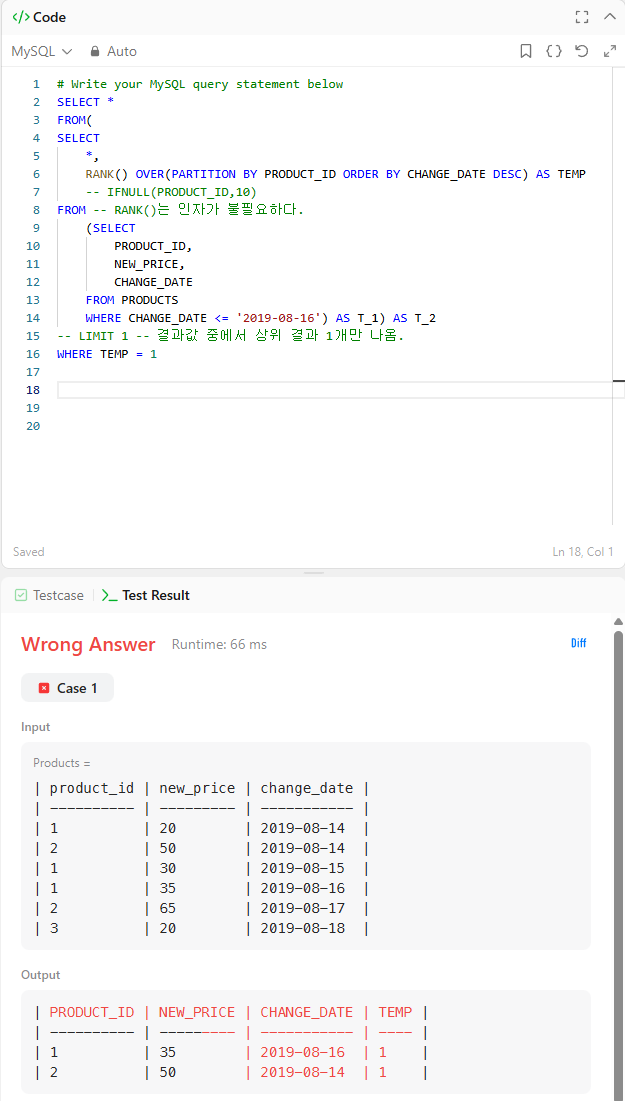
WHERE TEMP = 1코드를 설명하자면, 서브쿼리를 3개 썼다.
제일 안쪽의 서브쿼리는 '2019-08-16' 이전의 제품들을 선정하는 부분을, 그 다음 안쪽 서브쿼리는 제일 안쪽 서브쿼리의 모든 열(*)과 rank() 윈도우 함수를, 그 다음 메인 select문에서는 모든 열(*)을 다 가져오는데 temp=1인 조건을 만족하는 식으로 썼다.
3개의 서브쿼리로 감싼 이유는,
#1321번 위 문제와 같이, 'sql 실행 순서'에 있는데,
where이 select보다 먼저 실행되므로, 전체를 한번 더 감싸야 temp를 찾을 수 있고, where절을 실행할 수 있다.
<claude 정답 코드>
SELECT
PRODUCT_ID,
NEW_PRICE
FROM (
SELECT
*,
RANK() OVER(PARTITION BY PRODUCT_ID ORDER BY CHANGE_DATE DESC) AS rn
FROM PRODUCTS
WHERE CHANGE_DATE <= '2019-08-16'
) AS T_1
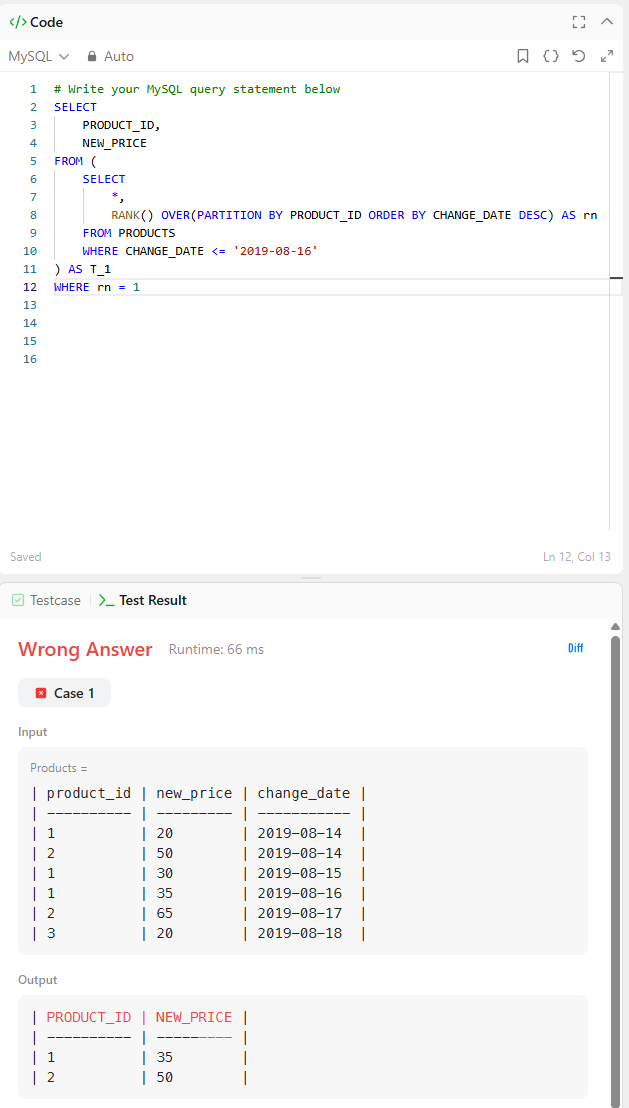
WHERE rn = 1claude는 같은 결과인데,
서브쿼리를 1개 더 줄여서 가독성 좋게 만들었다.
내 코드와 차이점은,
서브쿼리 안에 넣은 것들의 순서(?)를 바꿔서
훨씬 더 가독성 좋게 만든 것이다.



2-3-2. 2번 메인 select문
여기에서는 not in, not exists를 사용해서 구현해보았다.
not in, not exists 개념 설명을 한번 더 자세하게 정리할 예정이다.
(이전 게시글에서 이미 한번 정리를 했었다.)
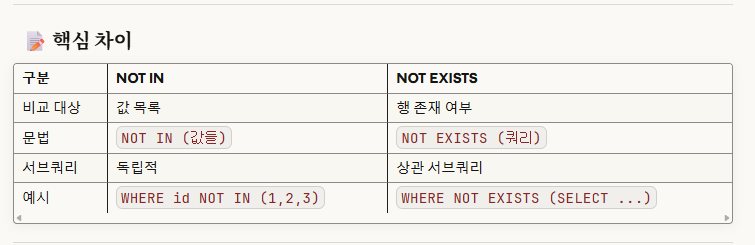
※개념_3. 'not in' vs 'not exists'
위 사진들에 있는 개념들을 잘 알아두면 좋다.
그러면 명확하게 구분이 될 것이다.
요약하자면,
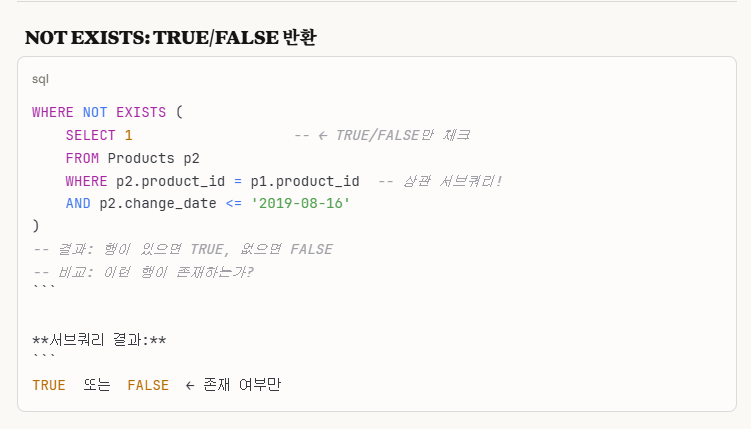
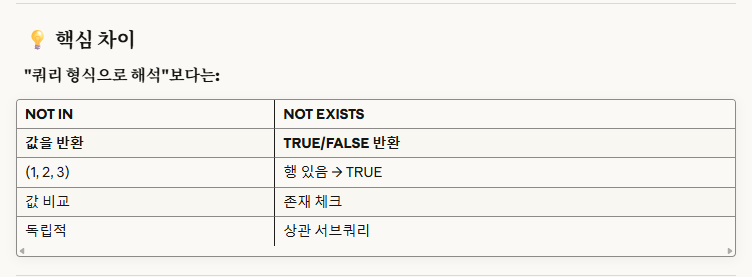
'not in'은 '값 목록'에 '해당 값이 있는지/없는지'를 판단하는 것이고,
'not exists'는 '행 존재 여부'만을 판단하는 것으로, 결과가 'true/false'를 반환한다.구현 자체도, not in은 서브쿼리가 독립적이고, not exists는 상관 서브쿼리로 작성해야한다.
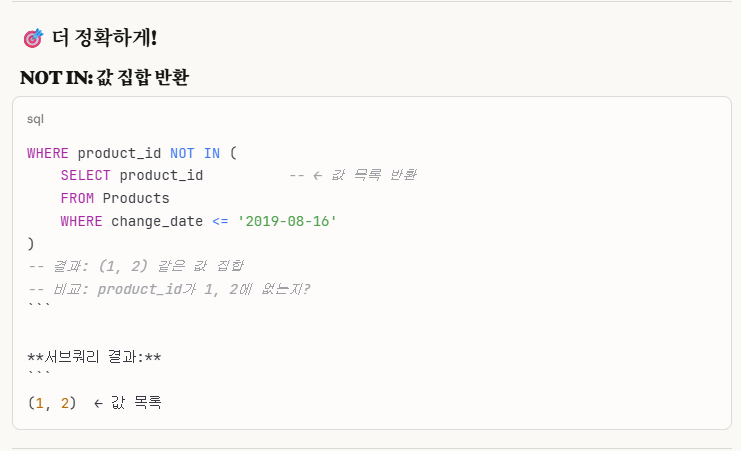
(그냥 참고만. 따로 안 보셔도 됩니다.)맨 위 사진에서,
'not in(값들)', 'not exists(쿼리)' 이렇게 되어있는데,
2,3번째 사진을 보면, 얼핏 겉만 보면 둘 다 쿼리 형식으로 되어있어서 헷갈릴 수가 있다.그래서 본인은 쿼리 형식이지만 결과가 값이면 not in을, 서브쿼리 자체가 쿼리(질문) 형식으로 해석되면 not exists를 쓰면 되냐고 claude에게 질문을 했으나, claude는 이렇게 답하였다.
즉, not exists는 true/false 결과로 이해하면 확실하다는 것을 다시 한번 강조하고 싶었다.

<not in 정답 코드>
SELECT
PRODUCT_ID,
10 AS price
FROM PRODUCTS
where product_id not in (
select distinct product_id
from products
where change_date <= '2019-08-16'
)<not exists 정답 코드>
SELECT distinct product_id, 10 as price
from products p1
where not exists (
select 1 -- 의미없는 select문
from products p2
where p1.product_id = p2.product_id
and p2.change_date <= '2019-08-16'
)'not in' 및 'not exists' 코드는 위 개념보면 이해하기 쉬울 것이므로, 따로 설명은 안하도록 하겠다.
2-3-3 2개의 select문 union하기
나는 1번 select문은 claude것을, 2번 select문은 not in으로 골라서 union을 시켜보았다.
<최종 정답 코드>
-- Part 1: 2019-08-16 이전에 가격 변경 이력이 있는 제품
SELECT
product_id,
new_price as price
FROM (
SELECT *,
RANK() OVER(PARTITION BY product_id ORDER BY change_date DESC) as rn
FROM Products
WHERE change_date <= '2019-08-16'
) t
WHERE rn = 1
UNION
-- Part 2: 2019-08-16 이전에 가격 변경 이력이 없는 제품
SELECT
product_id,
10 as price
FROM Products
WHERE product_id NOT IN (
SELECT DISTINCT product_id
FROM Products
WHERE change_date <= '2019-08-16'
)
union은 칼럼 갯수/타입을 동일하게 해야하므로,
select하는 열의 갯수, 이름(대문자/소문자 구분까지), 타입을 다 맞춰줘야한다.
※cf.) 이름은 달라도 된다고 합니다.
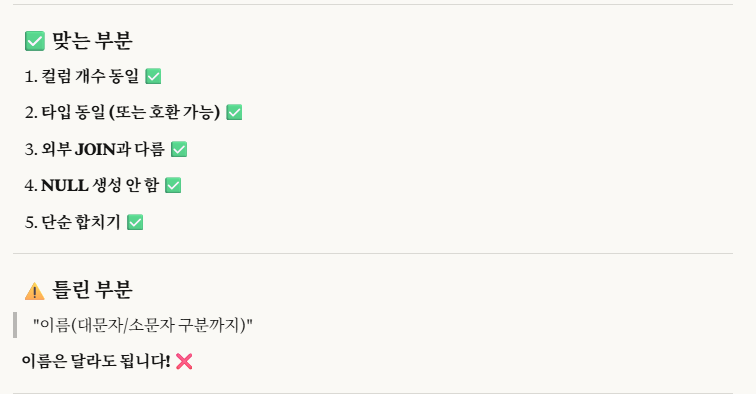
위 코드는 다 맞춰줬으므로,
안전하게 union을 할 수가 있다.
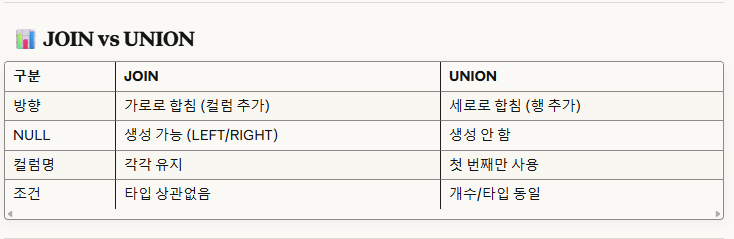
※외부 join과 다르다.
->union은 null을 생성하지 않고, 단순 합치기만 하기에 모든 양식들을 다 맞춰야한다.
3. 마무리
이렇게 해서 오늘도 2개의 문제를 풀어보았다.
난이도가 어렵다기보단 새로운 개념들을 배우고,
기존에 알았던 개념들도 다시 재정비할 수 있는 시간이었던 거 같다.
오늘도 제 긴 글을 봐주셔서 감사합니다 :) bb
