1. Lambda란 무엇일까?

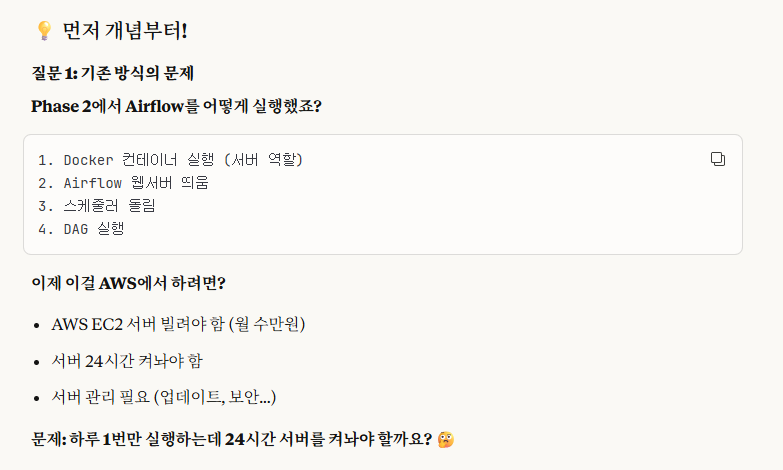
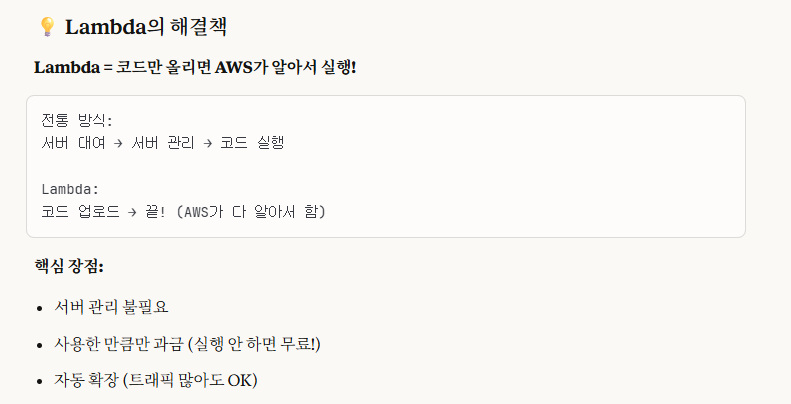
즉, lambda 또한 쉽게 말해 '자동화' 작업이라고 생각하면 된다.
위 첨부한 사진들의 설명대로 이해하자면,
lambda는 기존 방식의 하루 종일 서버를 켜서 관리하는 것이 아닌, 필요할 때만 사용하는 것을 말한다.
좀 더 이해하기 쉽게 밑에 비유 예시를 달아두었다.
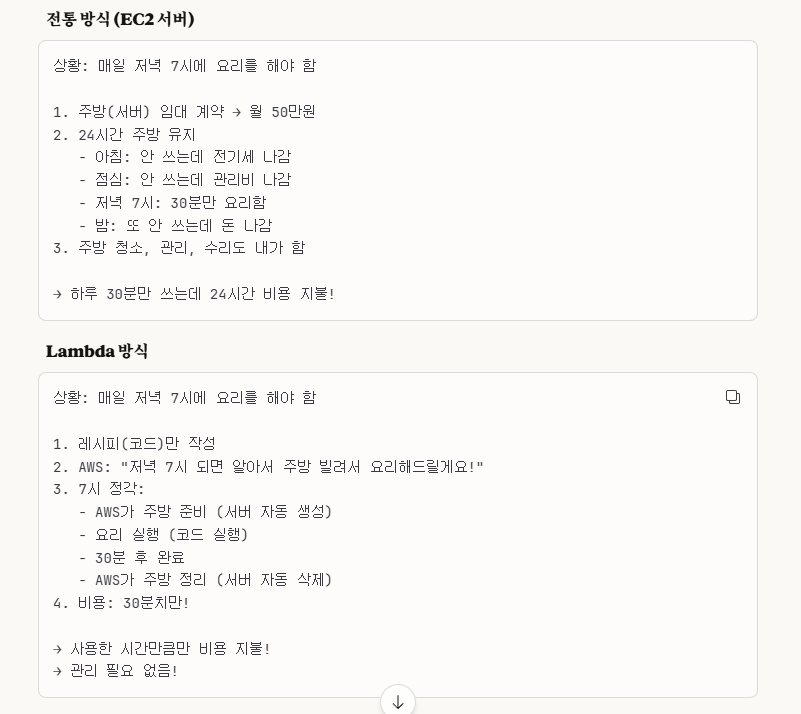

->이것만 알아두어도 좋다.
1-1. Python Lambda와 관련이 있는 것일까?

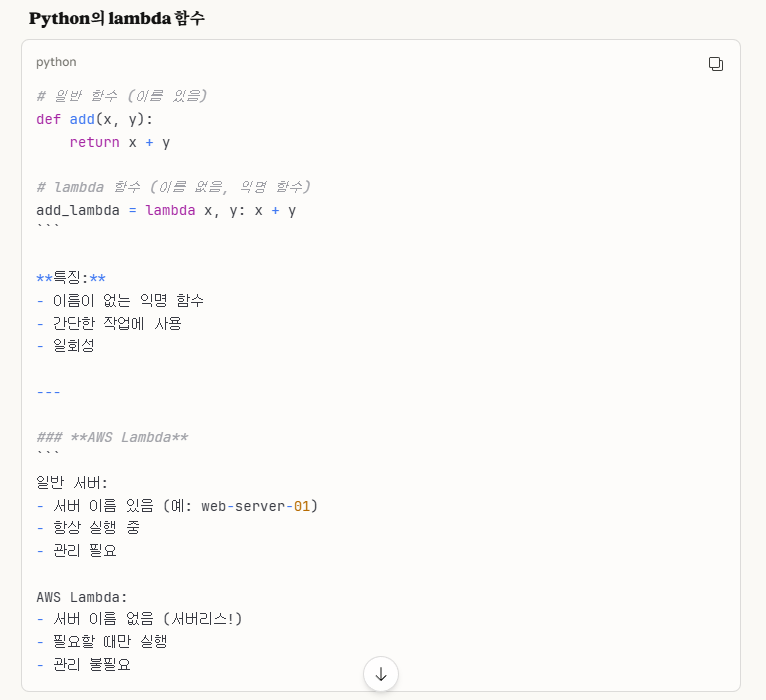
우리가 흔히 lambda라고 하면, lambda 함수에 대해서 많이들 떠올릴 것이다.
lambda 함수라 함은, 일반적인 함수와는 다르게 '이름을 붙이지 않고, 즉시 사용하는 함수'를 의미한다.
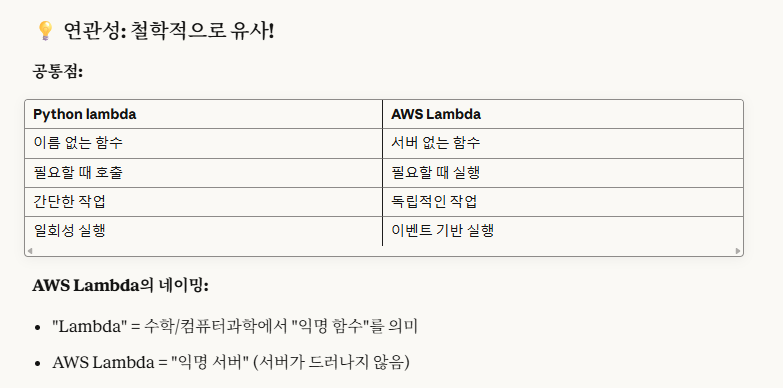
위의 첨부된 사진을 보면,
lambda 함수와 AWS lambda는 철학적으로 거의 유사하다고 볼 수 있다.
즉, '익명 함수'의 의미처럼 '익명 서버'로 해석하지만,
좀 더 정확하게는 '서버가 필요없는 함수'라고 이해하면 된다.
※ AWS lambda를 바로 위에서 함수라고 표현한 이유
뒤에 보면 알겠지만,
lambda를 설정할 때, .py 코드로 작성하는데,
이 때, def로 함수로 표현합니다.
2. Lamnda 생성하기

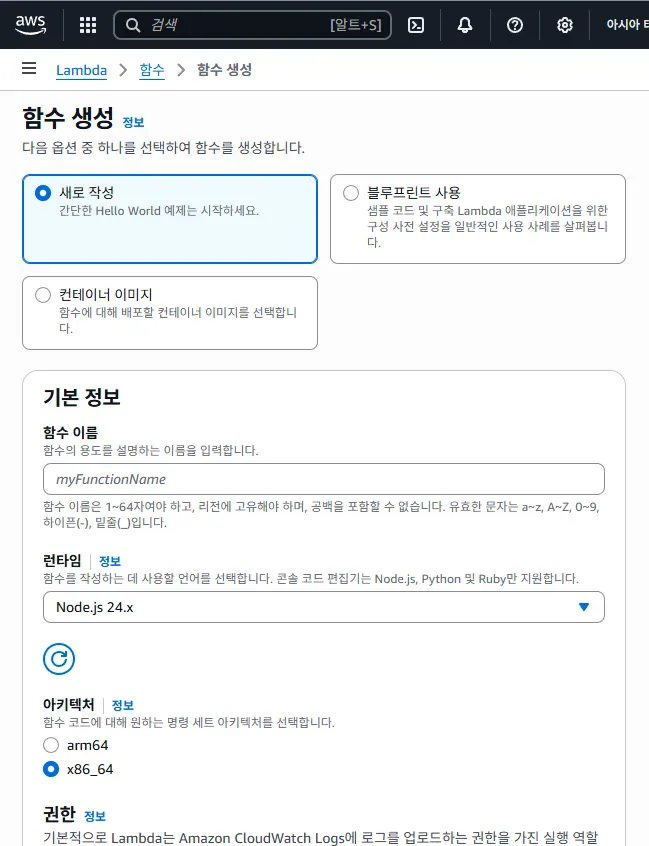
-> 여기서, 함수 이름은 's3-file-processor'로, 런타임은 'python 3.12'로 설정하였다.
나머지는 그대로 기본 설정으로 두었다.
->잘 생성되면 위와 같은 화면이 나온다.
3. Lambda 테스트하기
위 첨부한 사진을 보면,
'코드 소스'라는 탭이 보일 것이다.
해당 코드 소스에
import json
def lambda_handler(event, context):
# Hello World 출력!
print("Hello from Lambda!")
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}이렇게 print("Hello from Lambda!")라는 구문을 추가해보자.
그 다음 테스트 탭에 들어가면
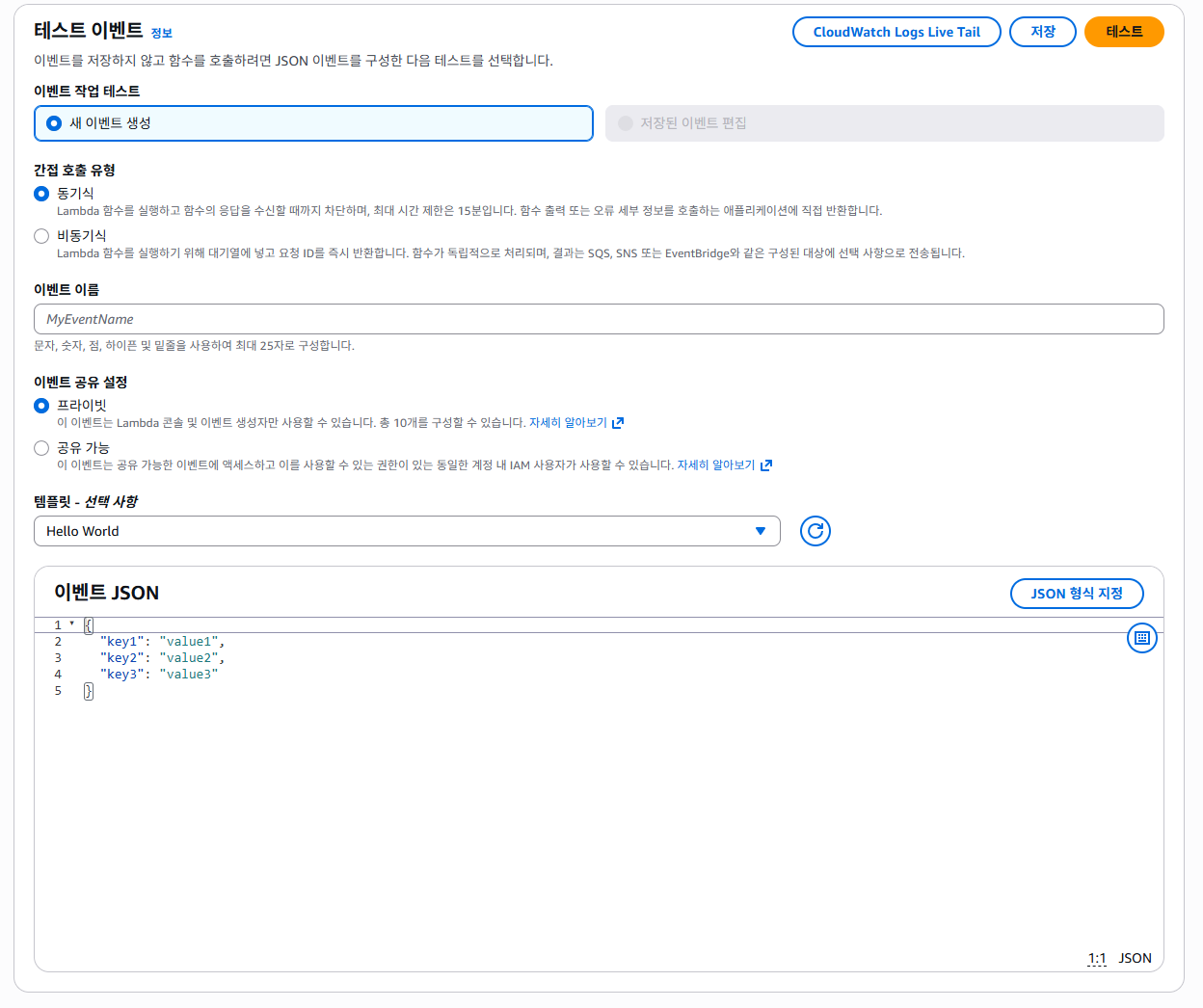
이렇게 나오는데,
이벤트 이름을 'test-event-1'으로 설정하고, 나머지는 기본 설정대로 두고 저장한다.
그리고 실행하면,
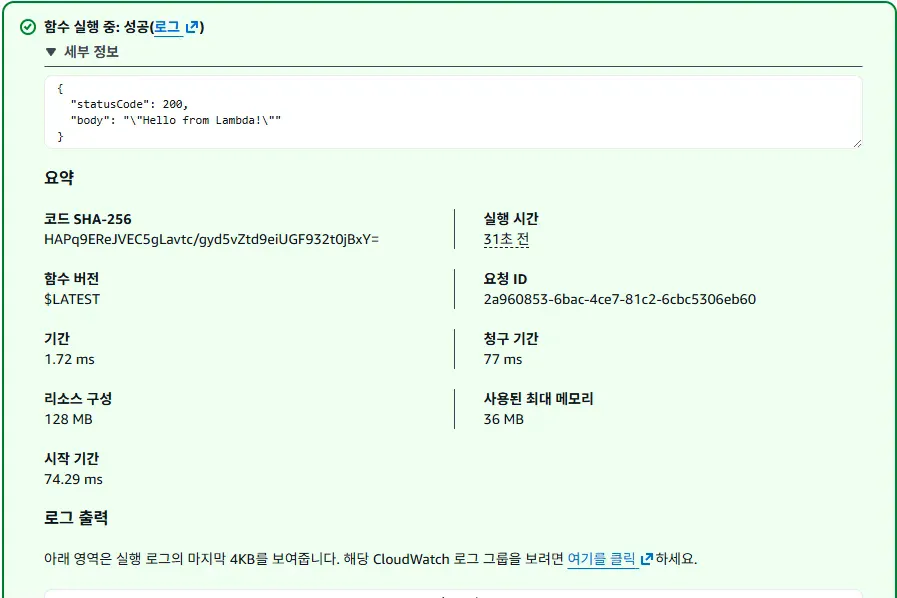
이렇게 나오는데,
위 사진에서는 잘렸지만 로그 출력에 print문이 출력된다.
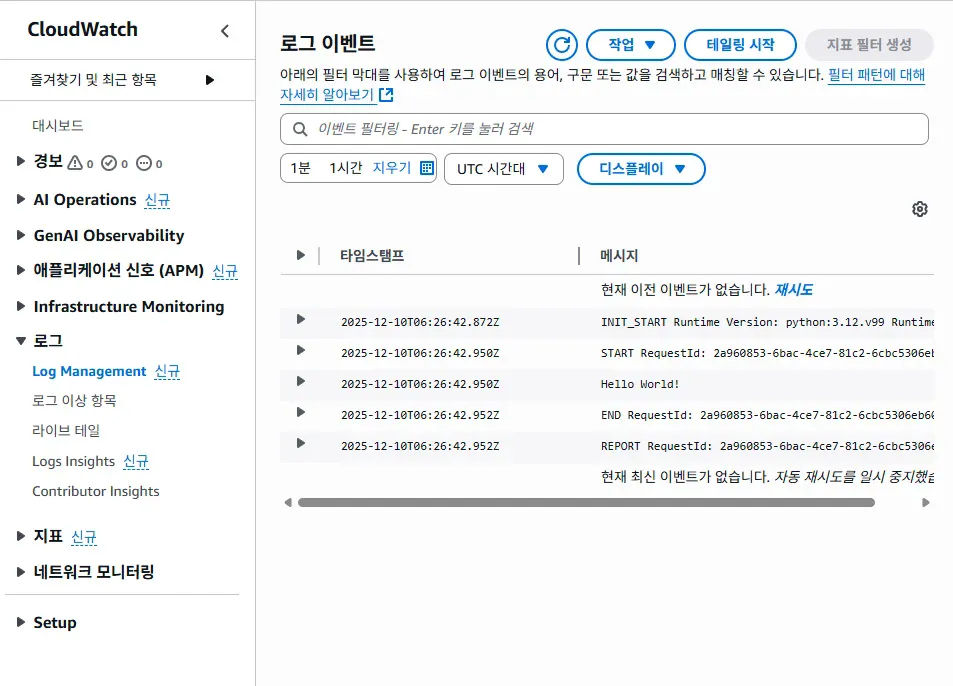
또한 'CloudWatch'를 통해서도 로그를 확인할 수 있다.
※ CloudWatch란?
AWS의 로깅 시스템이다.
4. Lambda에 트리거 추가하기
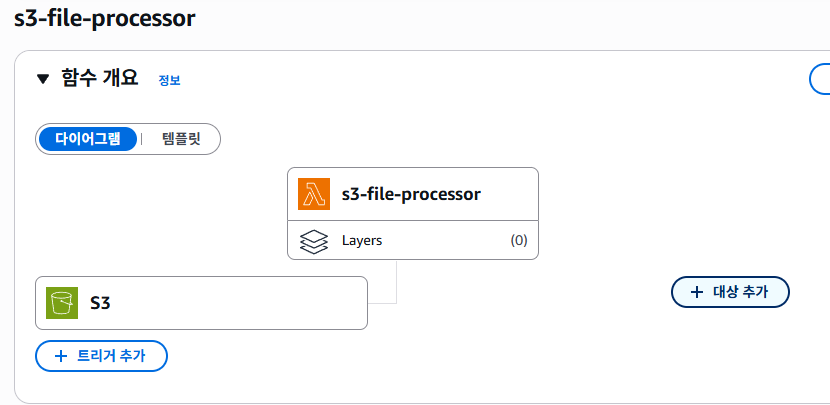
이렇게 lambda 메인 화면에 '트리거 추가'라는 버튼이 있는데, 이를 클릭하면
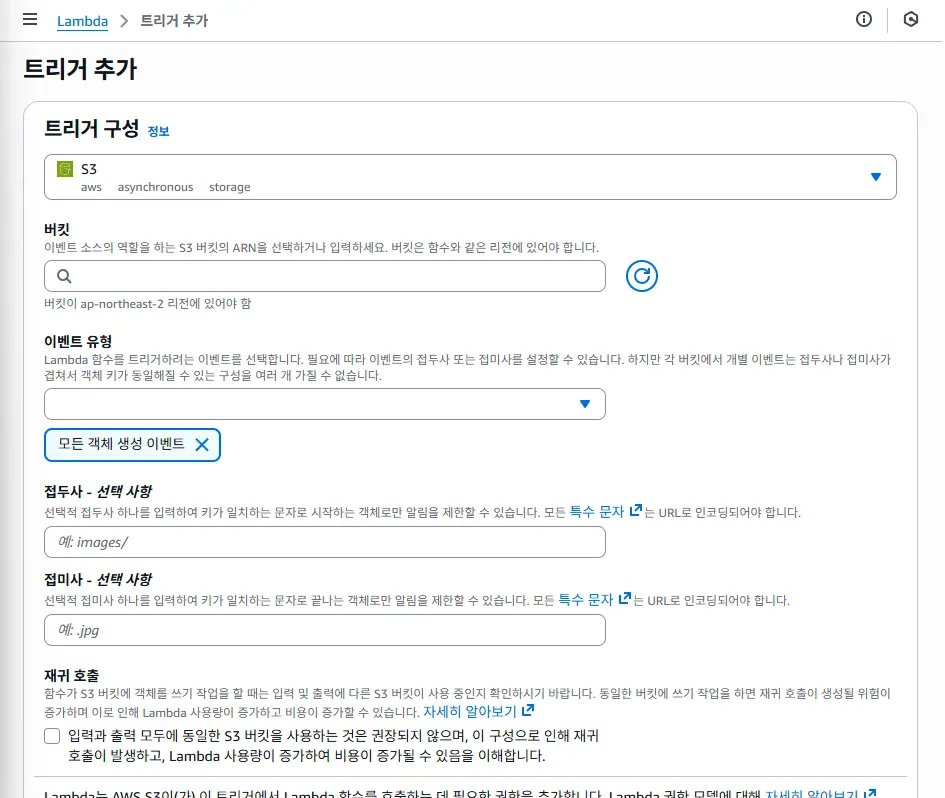
이런 창이 나온다.
트리거에서 'S3'를 선택하고,
버킷은 내 S3에 있는 버킷을 선택한다.
이벤트 유형은

위 첨부된 사진처럼 '파일 업로드하는 모든 방식에 반응'해야하므로, '모든 객체 생성 이벤트'를 선택한다.(기본으로 설정되어 있다.)
접두사엔 '/raw'를(raw 폴더에 있는 파일들만 트리거한다.), 접미사엔 '.csv'를(.csv 파일만 트리거한다.) 설정한다.
마지막으로는, '재귀 호출 경고'가 있는데,
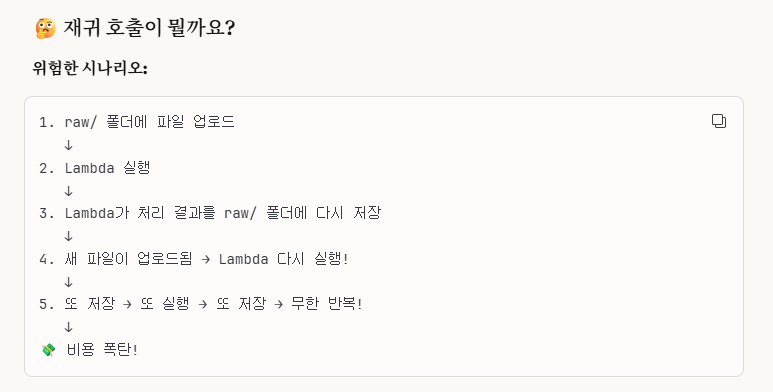
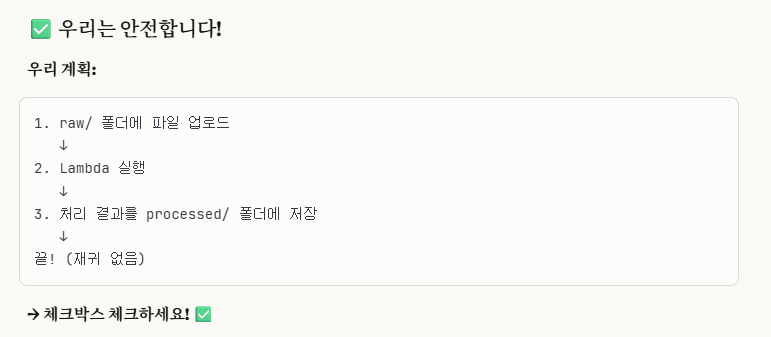
말 그대로, 재귀적(자기 자신을 이용해 다시 돌아오는 것을 의미함.)으로 진행됨을 언급하는 것이다.
하지만, 뒤에 보면 알겠지만,
우리는 처리 결과를 raw/ 폴더에 그대로 넣는 것이 아닌,
processed/라는 폴더를 새로 생성해서 넣을 것이기 때문에,
재귀에 대해서는 걱정을 하지 않아도 된다.
※cf.) 재귀함수
대표적인 예시로 '피보나치 수열'로 알아보자.
이걸 보면 확실하게 이해가 될 것이다.def fibonacci(n): # 기저 조건 (탈출 조건) if n <= 1: return n # 재귀 호출 else: return fibonacci(n-1) + fibonacci(n-2) # 사용 예시 print(fibonacci(4)) # 출력: 3 (0, 1, 1, 2, 3) print(fibonacci(7)) # 출력: 13 (0, 1, 1, 2, 3, 5, 8, 13)else 부분을 보면,
자기 자신 함수를 return으로 받아서 결과를 내는 것을 확인할 수 있다.이렇게 '자기 자신을 이용' + '다시 되돌아옴(자기 자신으로)' 이 2가지 개념이 혼합된 것이 '재귀'의 의미이다.
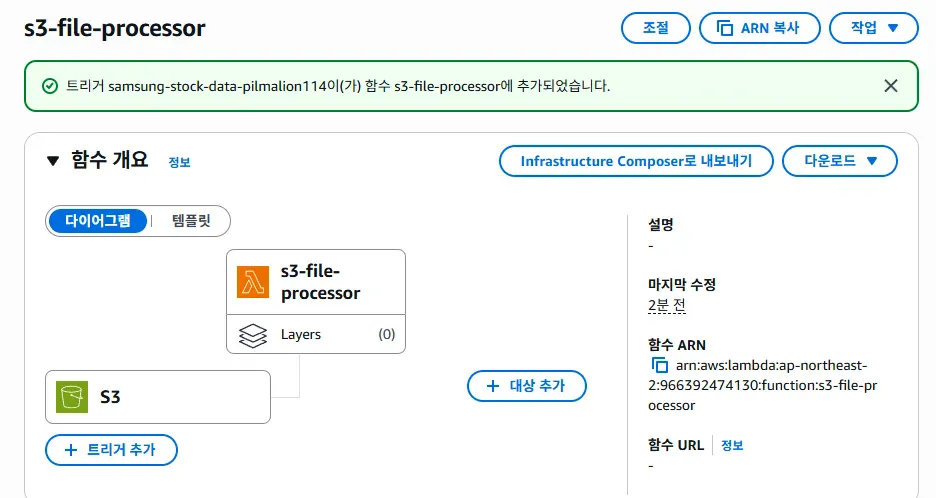
이렇게 결과가 나오면 잘 된 것이다.
5. ⭐Lambda 코드 작성하기
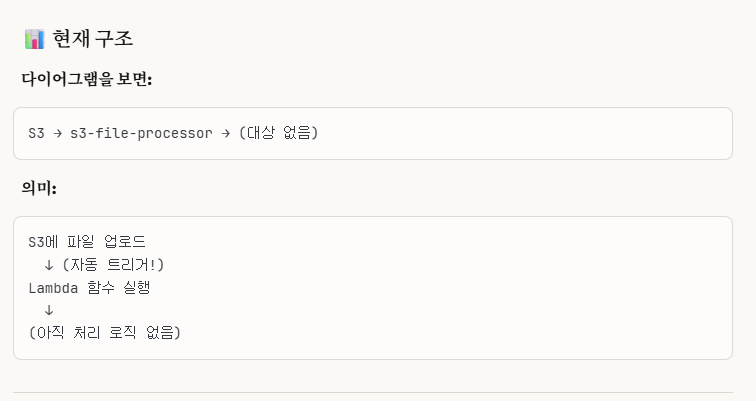
현재 위 4번의 결과 사진을 확인해보면,
아직 처리 로직이 없음을 확인할 수 있다.
이에 우리는 본격적으로 테스트 코드를 작성한 코드 탭에서
본격적인 처리 로직 코드를 작성해야한다.
->이 역시 깃허브에 올려서 공유하도록 하겠다.
자세한 코드 설명은 주석에 설명이 되어있으므로, 참고하면 된다.
코드의 구성 단계를 간략하게 설명하도록 하겠다.
1.S3 클라이언트 생성
2.함수 생성(lambda_handler)
2-1. S3 이벤트에서 버킷, 파일 정보 추출
2-2. S3에서 파일 읽기
2-3. CSV 분석
2-4. 처리 결과를 processed/ 폴더에 저장.
2-5. 결과 파일명 생성
2-6. 결과 저장
즉, 자연스럽게 과정을 이해하면 된다.
우리가 로직을 처리하려면,
먼저 S3 에서 버킷,파일 정보를 추출해야한다.
그래야 연동을 할 수 있으니 말이다.
그 다음 S3에서 처리하고 싶은 파일을 읽어오고,
그 파일에 대해 분석을 하고,
처리 결과를 해당 폴더에 저장을 한다.
그 다음은 결과물에 대한 세부적인 세팅을 하면 끝이다.
6. lambda 실전 코드 테스트하기
우리가 전에 VScode에서 만든
's3_upload.py'를 실행시키면,
lambda의 자동화 과정이 실행된다.
하지만, 이를 하기 전에 뭔저 lambda에 대한 IAM 권한 설정을 진행해야한다.
이유는,

이렇게 현재 lambda는 읽고,쓰는 권한이 없기 때문이다.

이렇게 빨간색 표시한 링크를 들어가면
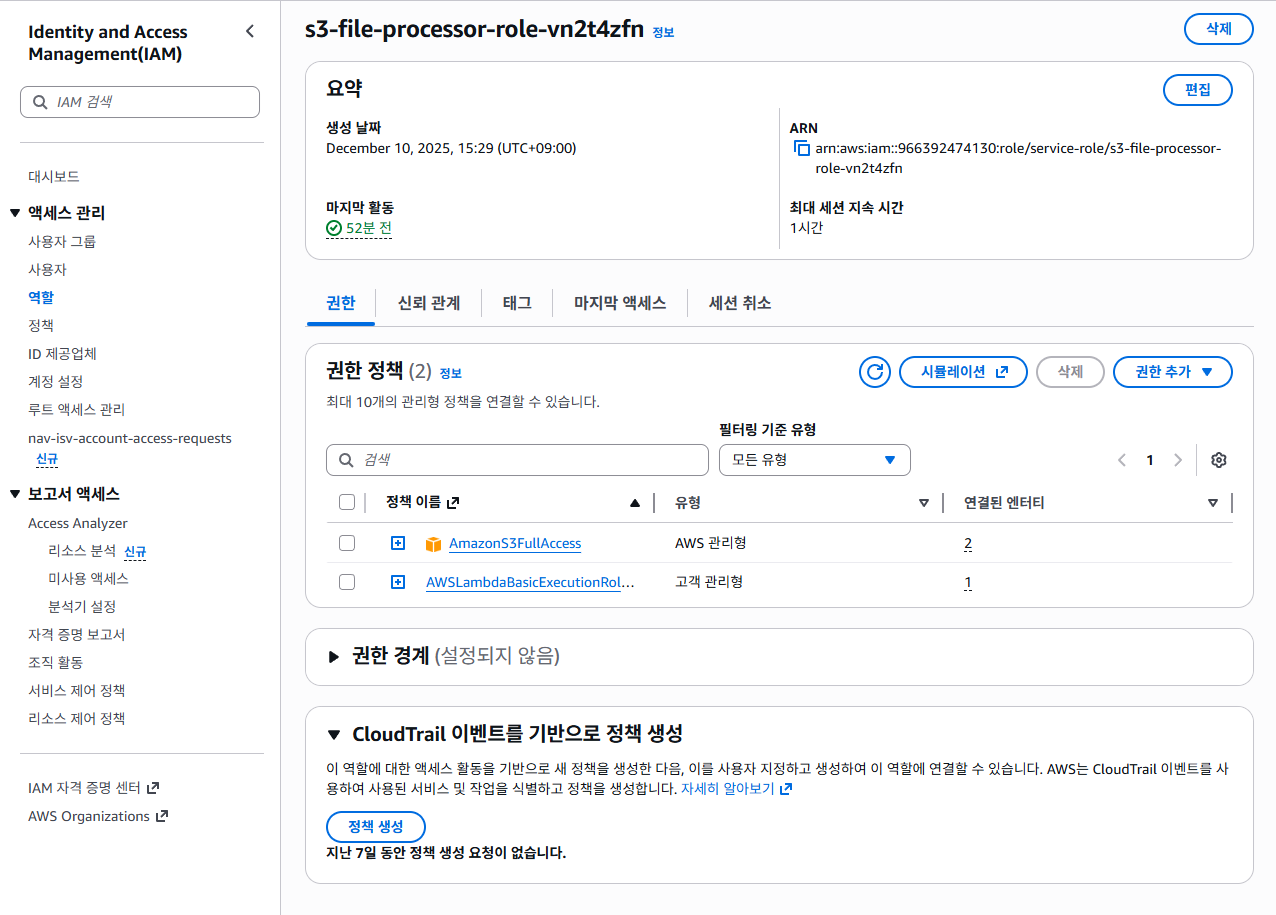
이렇게 창이 뜬다.
나는 미리 만들었으므로, 'AmazonS3FullAccess'가 있지만,
기본 상태는 'AWSLambdaBasicExecution....' 이것만 있다.
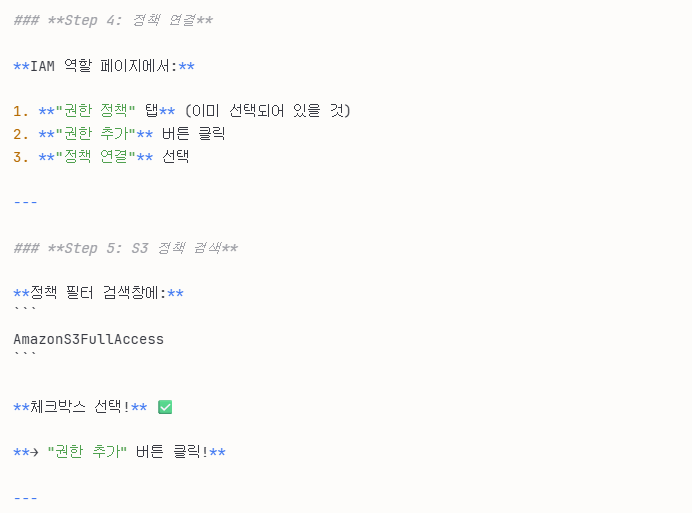
'권한 추가' 버튼을 누르고, 위 사진처럼 진행하면 된다.
그 다음, 위에서 말한 것처럼
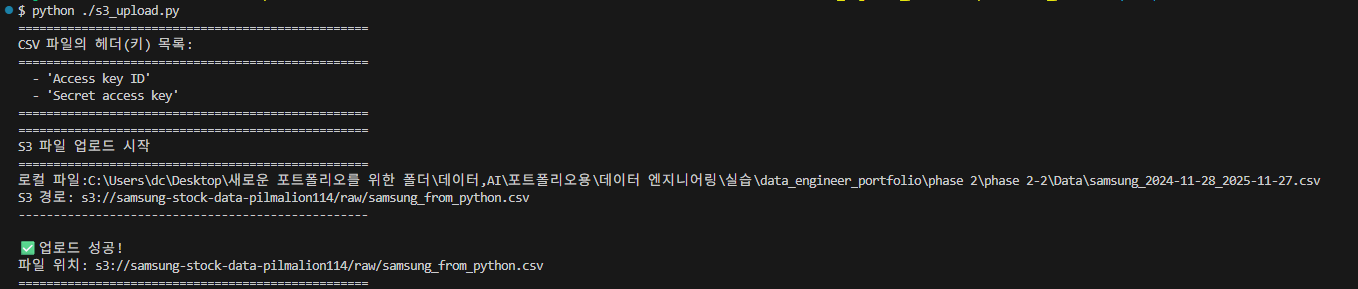
VScode에서 's3_upload.py'를 실행시키면,
lambda의 자동화 과정이 실행된다.
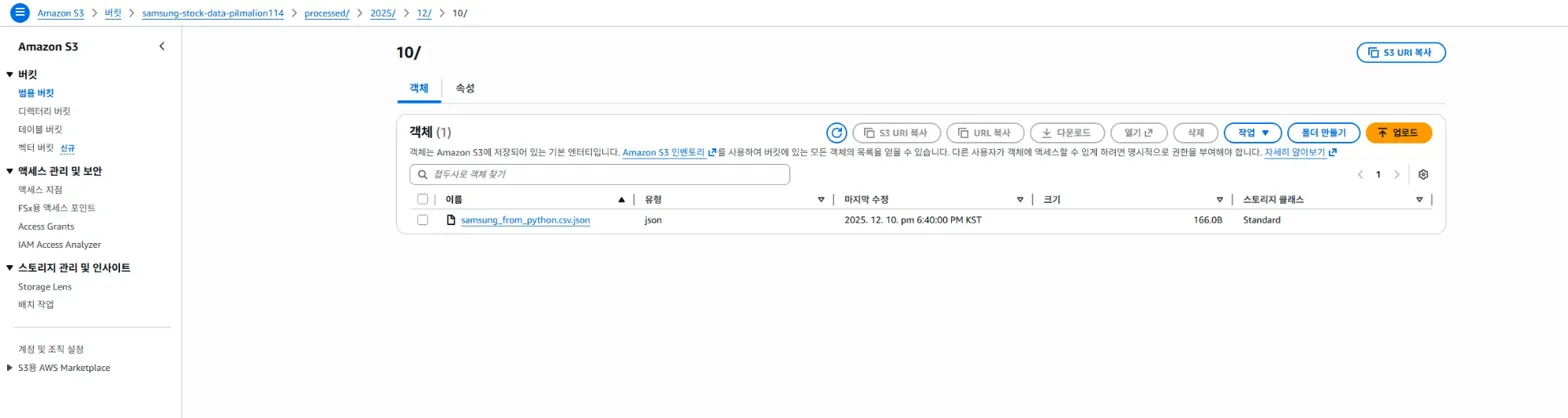
잘 작동되었는지 마지막으로 확인 작업이 필요한데,
가장 확실한 방법은
S3에서 processed/ 폴더가 생성되었고,
json 파일이 있는지 확인하는 것이다.
해당 json 파일을 누르면
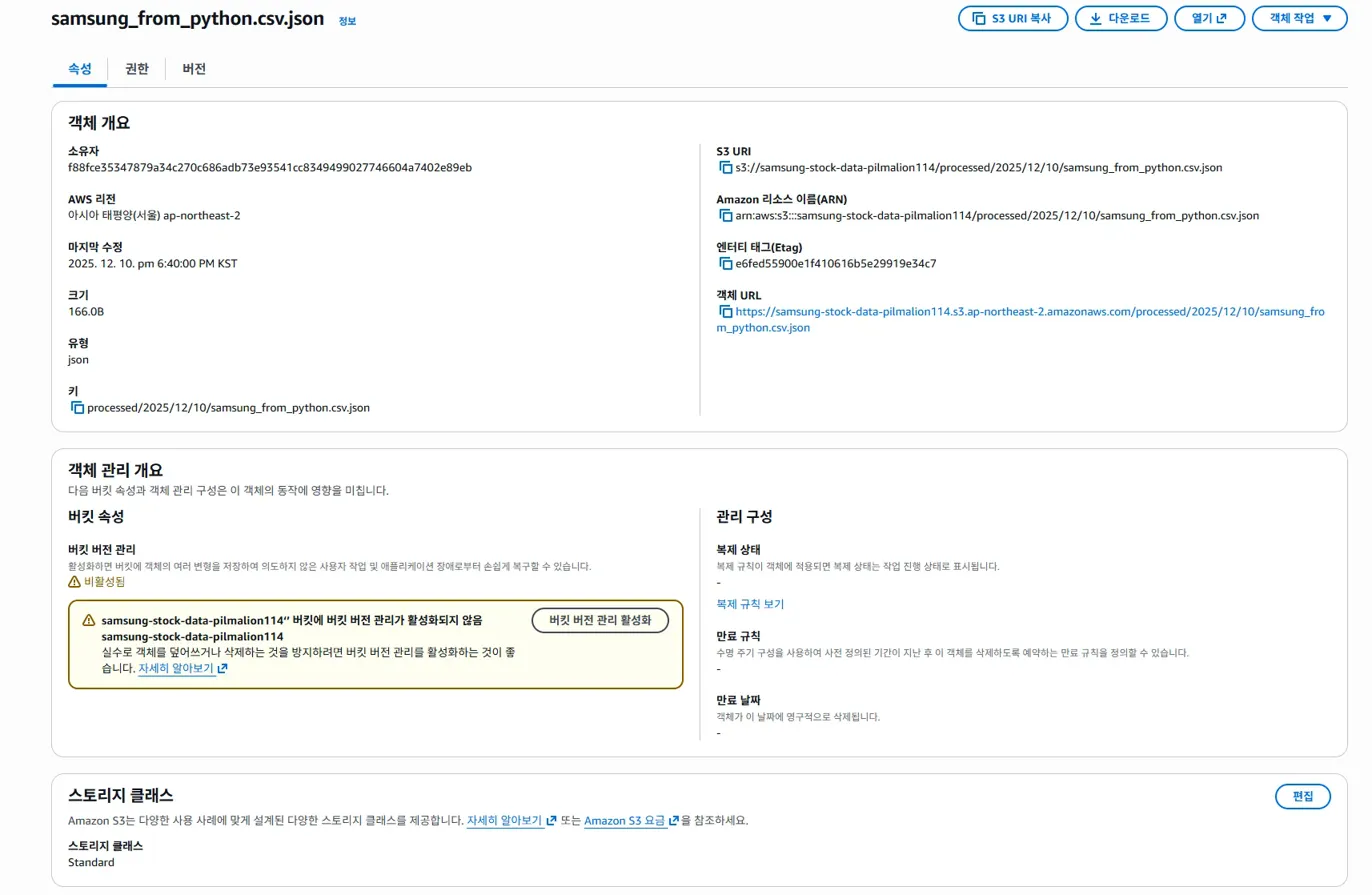
이렇게 json 개요만 나오는데
위 다운로드를 하면, json 파일이 다운로드 된다.
->json 파일은 위 깃허브 링크에서 확인할 수 있다.
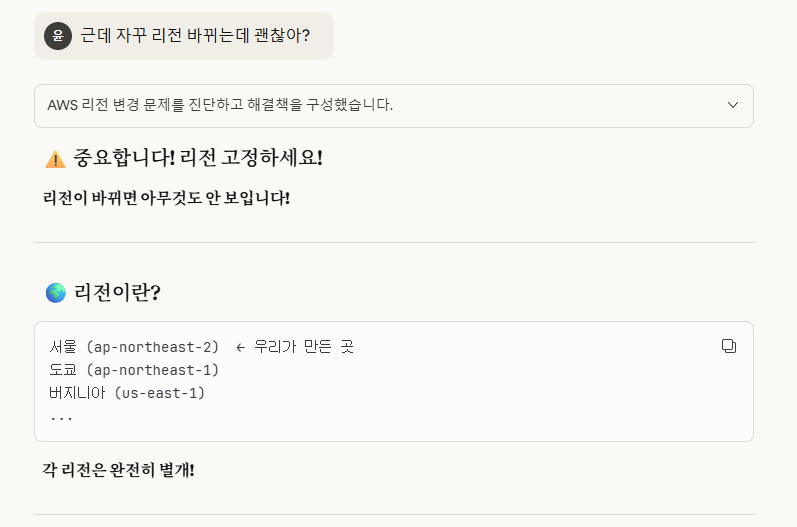
※(중요!) 리전이 변경되지 않도록 자주 확인하자!
7. 결론 및 마무리
이렇게 해서 또 다른 자동화 과정인 'lambda'에 대해서 알아보았다.
우리가 lambda를 접하기 전에는
예를 들어 Docker Container 같은 경우에는
일일이 서버를 켜야지 웹 UI에 접속할 수 있었는데,
lambda는 서버를 키지 않고도 자동화 과정으로 작업이 이루어질 수 있음에 간편하고 신선했다.
전에 회사에서 Make 자동화 툴을 이용하여 몇 개 작업물을 만들어본 적이 있어서 자동화 과정은 사실 낯설지는 않은 거 같다.
덕분에 lambda 자동화 과정 또한 어렵지 않게 학습할 수 있었다.
(느낌상으로는 Google SpreadSheet의 apps script 같은 느낌이었다. 이 역시 로직 처리를 함수로 선언하여 자동화하는 작업이다.)
다음은 우리가 여태까지 한 phase 3단계와 남은 phase 3단계를 소개하고자 한다.

위 첨부한 사진을 보면,
3-5에서 준-빅데이터를 다루는 과정을 볼 수 있다.

또한 진짜 빅데이터 처리는 마지막 phase 5에서 다루는 것을 알 수 있다.
본격적으로 빅데이터를 다룰 줄 알아야 실무에서도 유용하게 도움이 될 수 있다고 생각한다. 그리고 이게 진짜 실력이라고 생각한다.
오늘도 제 긴 글을 봐주셔서 감사합니다.
다음 phase 3-4로 다시 돌아오도록 하겠습니다 bb :)
