1. 학습 목표

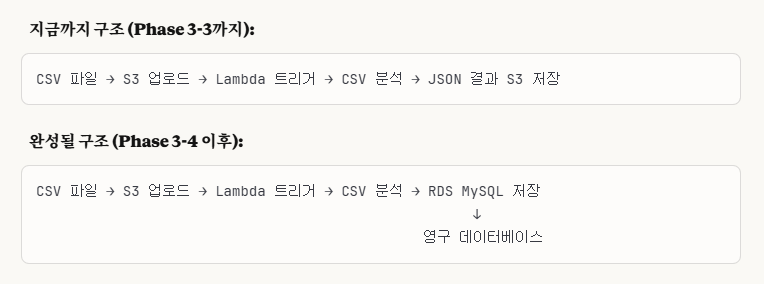
-> Lambda 자동화 함수를 이용해서 내 기존의 웹 phpmyadmin mysql 대신에 AWS 데이터베이스(RDS)에 저장하는 것이다.
2. RDS를 쓰는 이유
우리는 phase 3-3에서 JSON 파일 형식으로 데이터를 저장한 경험이 있다.
그렇다면, 왜 굳이 귀찮게 RDS를 설계해야할까?

위 질문에 이렇게 답변을 해보았다.


완전 정확하다고 한다.
하지만, 좀 더 깊게 들어가서 정말로 정확한지 파악하고 싶었다.
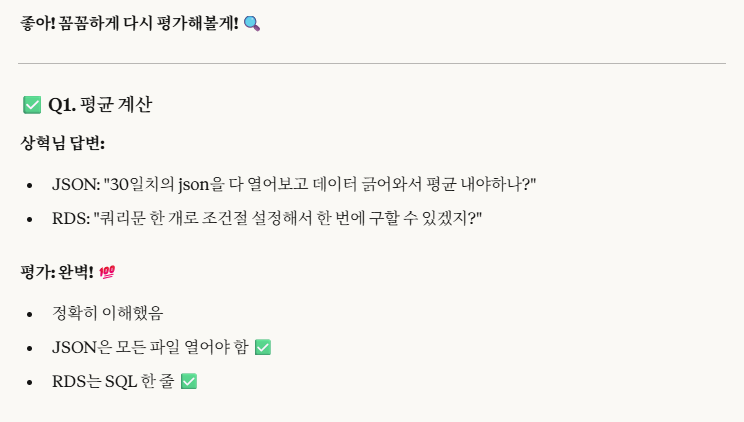
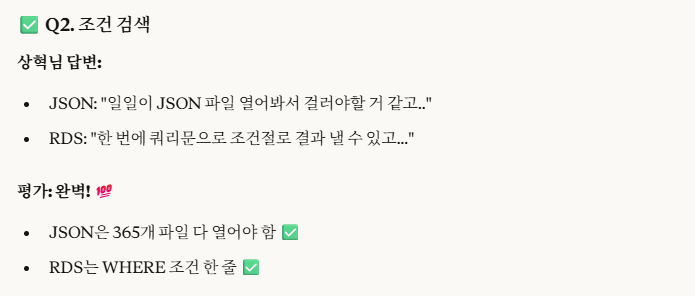
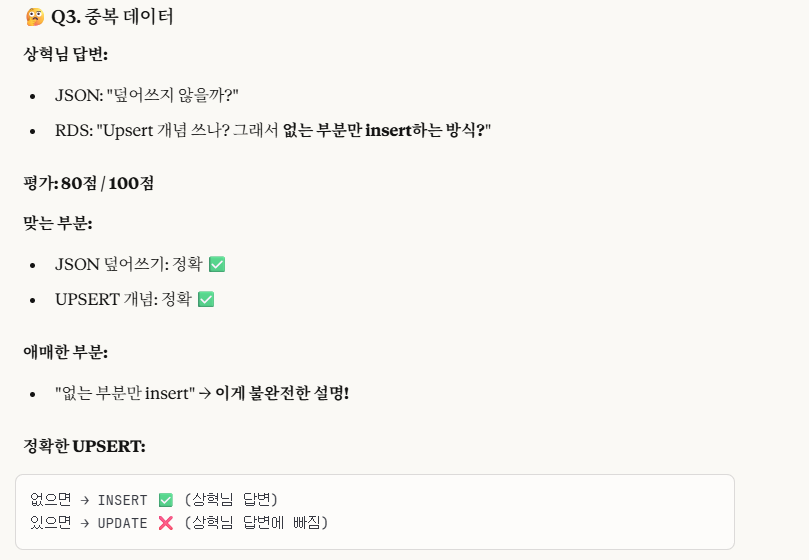
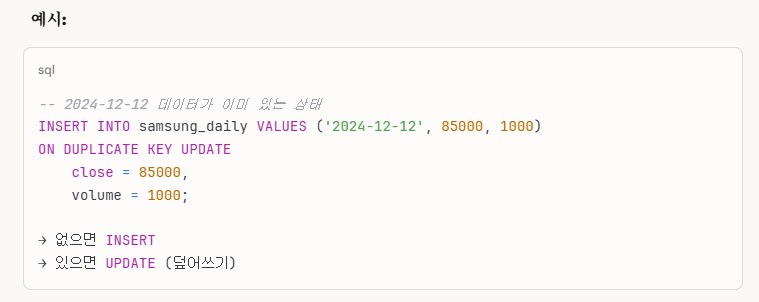

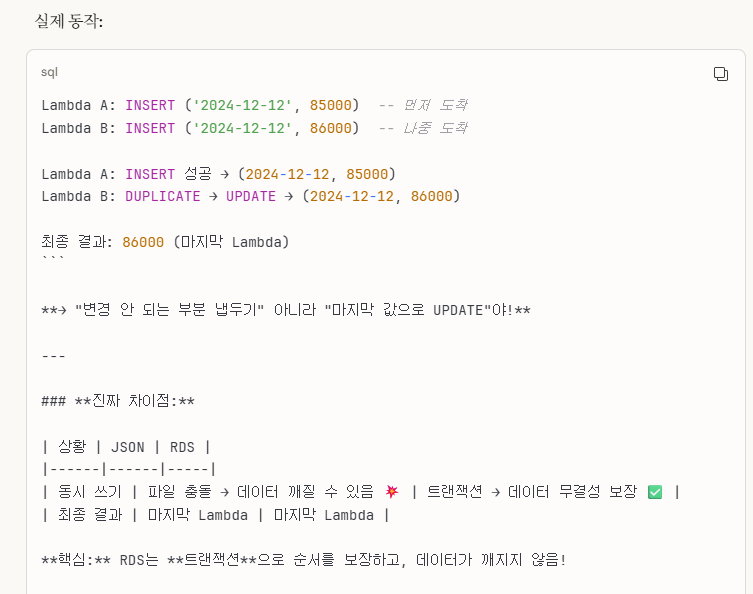
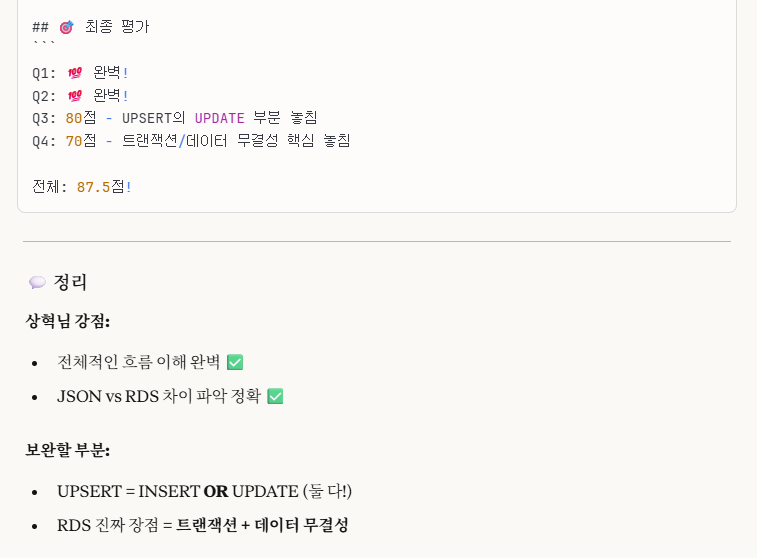
-> 잘 읽어보면, 내가 설명을 생략한 것이지 틀린 말을 한 것은 아니므로 100%는 맞다.
하지만, 좀 더 구체적인 설명을 원해서 위 답변들을 첨부했음을 알린다.
즉, 요약하자면,
RDS는 한 줄로 한 번에 처리할 수 있는 편리한 반면에,
JSON은 파일 하나하나를 열어서 처리해야하므로 불편하다.
그래서 우리가 RDS를 따로 설계하는 이유이다.
3. AWS RDS 생성하기
검색창에 RDS를 입력하고 누르면 이런 창이 뜬다.
여기서 '데이터베이스 생성'을 누르고,
너무 자세하게는 설명을 안 할 예정이고,
내가 기본값에서 바꾼 것들만 설명할 예정이다.
나는 free tier이므로 사용하는 데에 제약이 있다.
일단 데이터베이스 엔진은 MySQL로 진행하고(Phase 4부터는 PostgreSQL을 사용 할 예정이다.)
버전은 8.0.40을 사용했다.
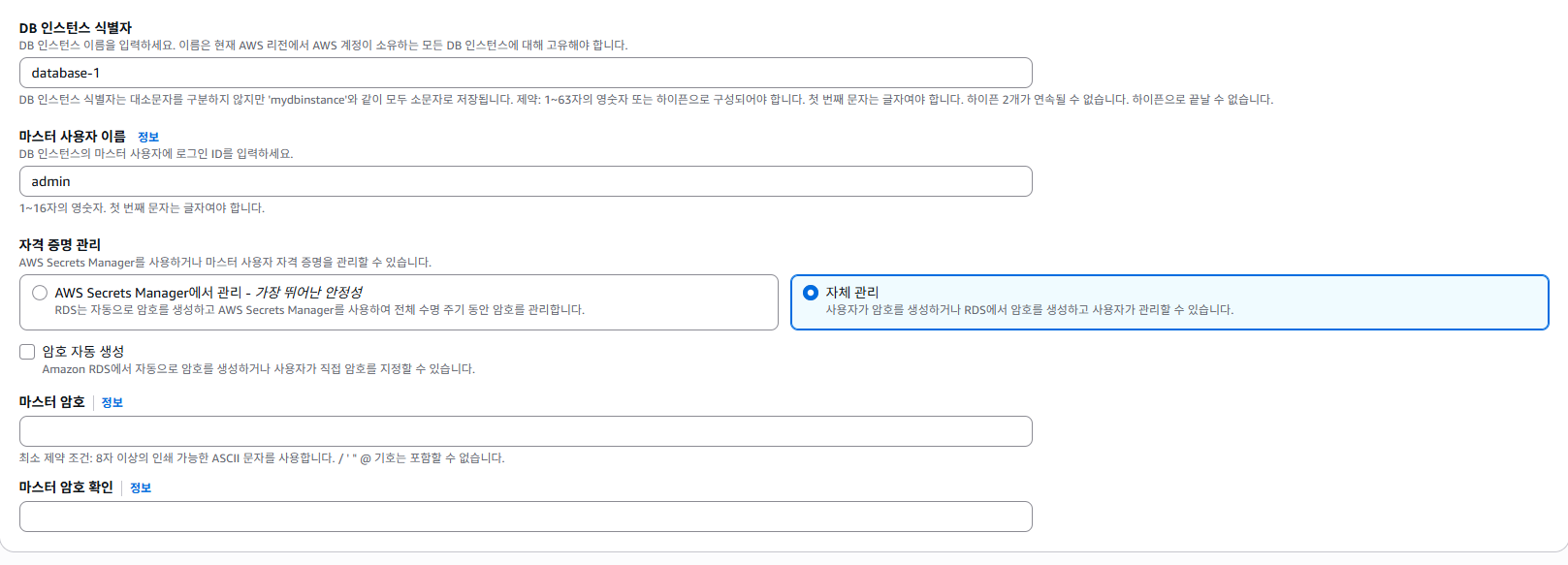
DB 인스턴스 식별자 이름은 'samsung-stock-db'로 하였고,
마스터 사용자 이름은 'admin'으로
자체 관리를 통해 내 pw를 입력하였다.
그 다음 public access를 허용으로 변경하였다.
(원래 실무에서는 No가 맞지만, 보안 문제로 외부 접근을 막는 게 맞지만, No로 설정하면 AWS 내부 리소스만 접근이 가능하고 그것도 같은 네트워크(리전)에서만 접근이 가능하다.)

->학습의 목적에 의해 Yes로 변경하였다.

-> No로 설정하면, 데이터 확인하려면 lambda 코드를 짜서 확인해야한다고 하고, Yes로 설정하면 내 로컬 IP만 허용으로 하면 외부 차단을 막을 수 있다.(하지만 뒤에 나오겠지만, 결국에는 All Access 가능하도록 0.0.0.0/0으로 설정하였다.)

->VPC security group 또한 새로 선택해서, 그룹 이름을 'samsung-stock-db-sg'으로 하였다.

-> 맨 밑에 추가 구성을 보면, 초기 데이터베이스 이름 설정칸이 나오는데, 'samsung_stock'으로 하였다.
-> 이걸 설정 안 해놓으면, 나중에 'Create Database' SQL문으로 만들어야한다고 한다.
이로써 세팅은 끝이고, 나머지는 기본 설정대로 하였다.
데이터베이스 생성까지는 약 5분 정도 걸리는 거 같다.
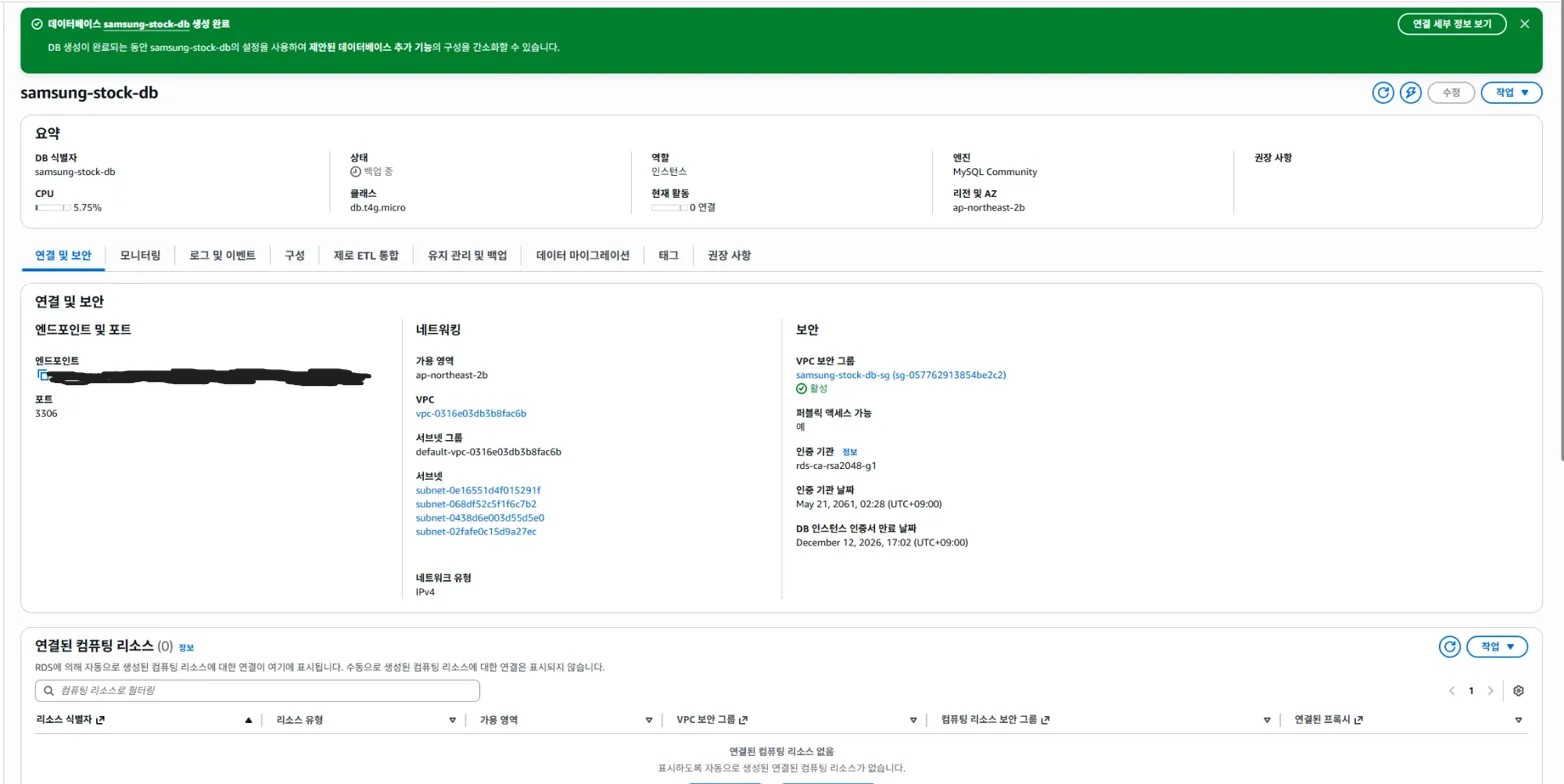
->완성되면 이렇게 보인다.
※주의할 점!
RDS든, lambda 든 기타 등등... 서비스를 이용할 때 꼭 '리전(Region)'을 확인하세요!!
다른 리전에 생성하면 그 리전에 서비스가 등록되는 겁니다. 리전을 변경한다고 해서 그 서비스가 자동으로 따라오는 것이 아닙니다. 새로 만들어야 합니다!
또한, 무료 티어인 경우에는, 다른 리전에 서비스를 만들 때, 리전 간의 통신 요금이 발생할 수 있으니, 꼭 같은 리전으로 설정해서 통신 요금이 부과되지 않도록 주의하세요!(같은 리전끼리는 요금이 부과되지 않는다고 합니다.)
꼭 확인하세요!!

3-1. VPC 보안 그룹에서 내 IP만 허용하도록 세팅하기
뒤에 보면 알겠지만, 여기서는 내 IP만 허용하도록 세팅하였지만, 나중에는 All Access로 바꾸었다.
아까 완성된 사진에서 'VPC 보안 그룹'에 있는 파란색 링크를 누르면,
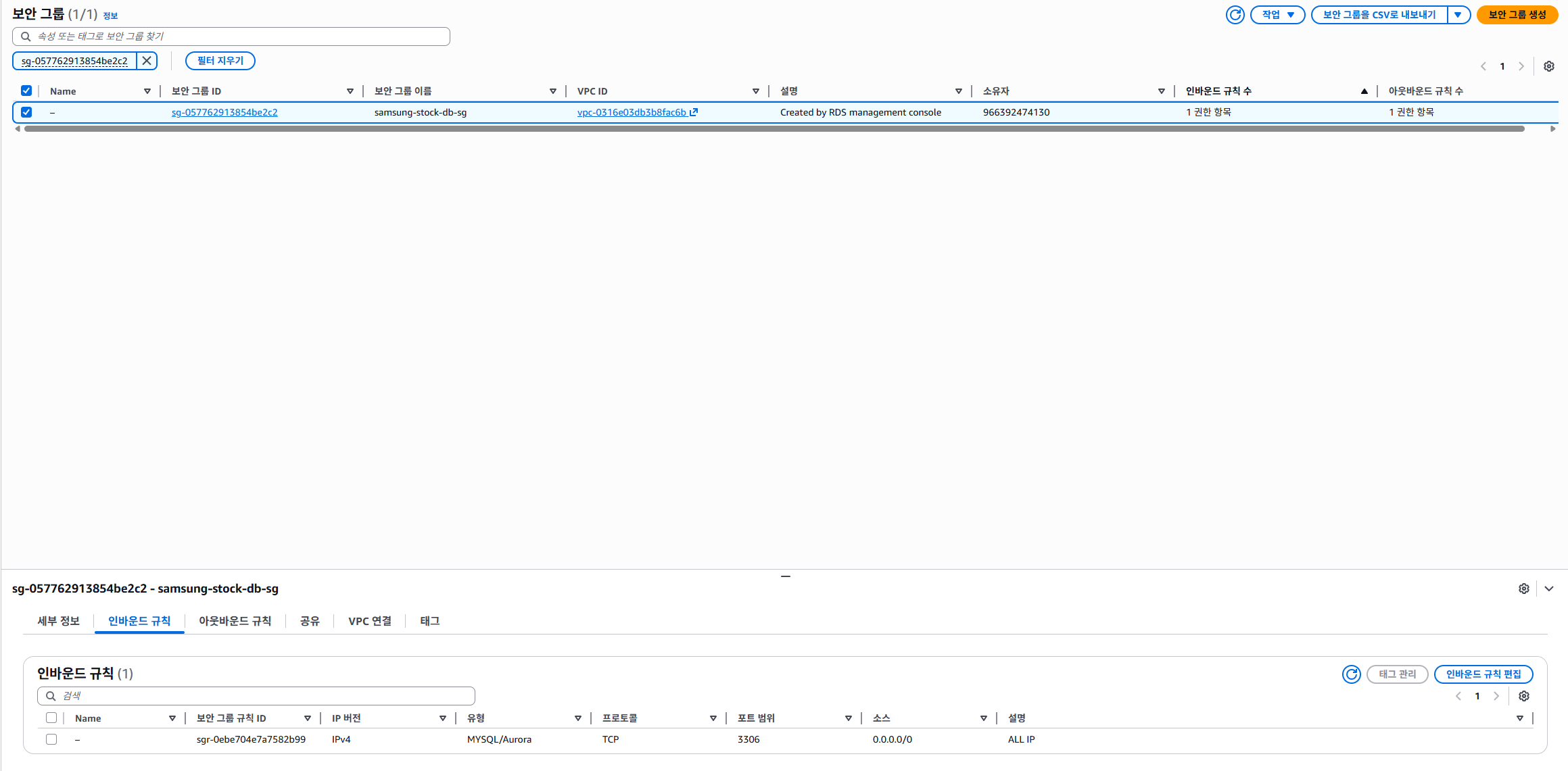
이렇게 나오고, 해당 보안 그룹 ID를 클릭한 후, 인바운드 규칙을 누르면 '인바운드 규칙 편집' 버튼이 보인다.
이를 클릭하고,
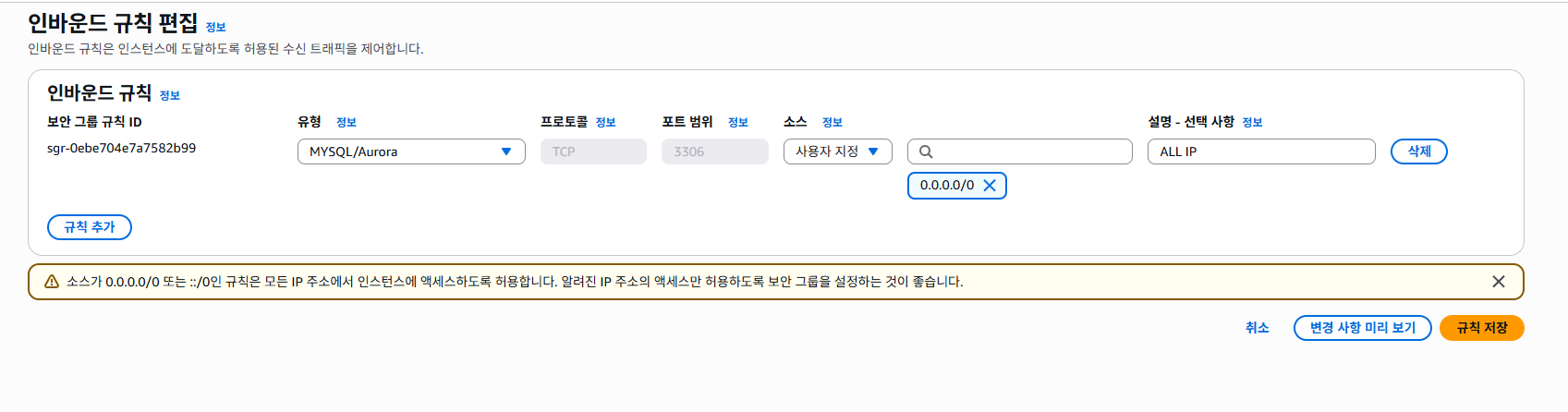
지금은 0.0.0.0/0이지만, 소스를 내 로컬 IP로 변경하면 된다.
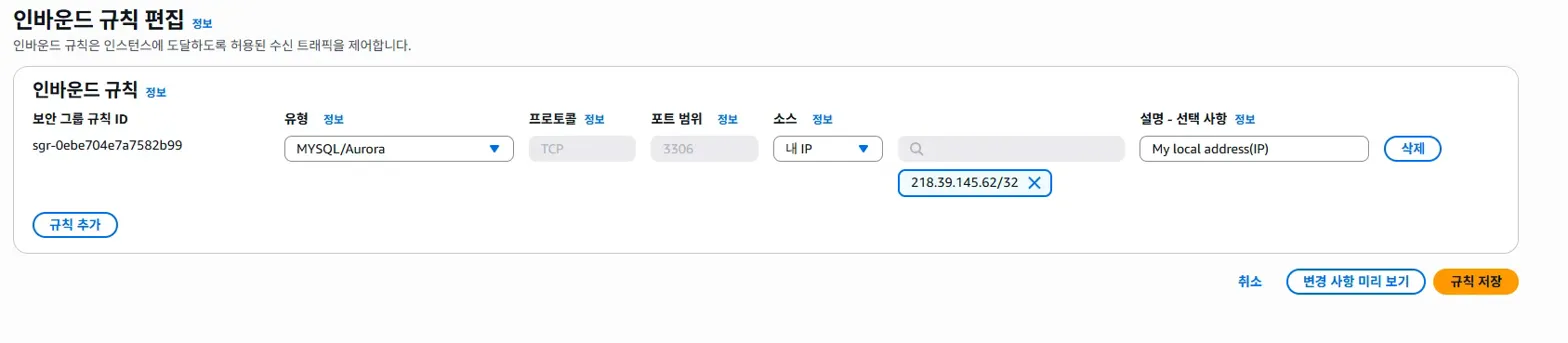
->이렇게 하면 된다.
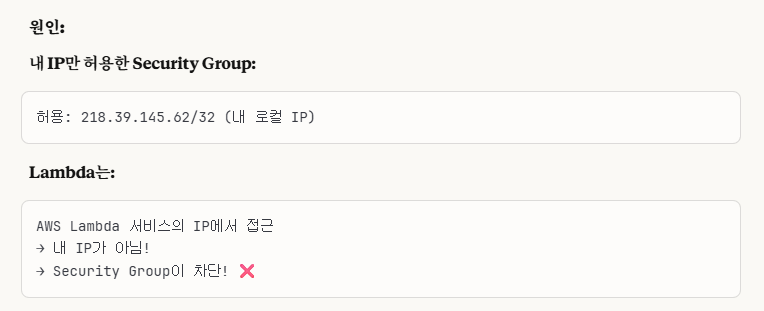
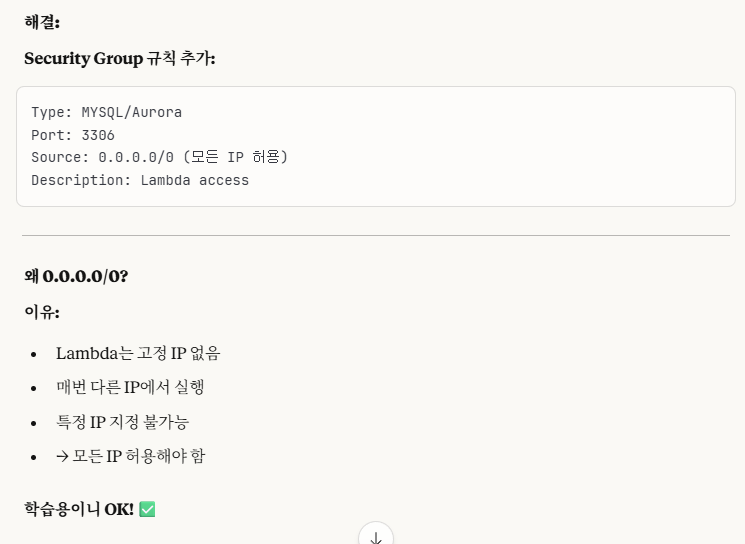
※뒤에다가 깜빡하고 안 적어서, '내 로컬 IP'가 아닌 'All access'로 설정한 이유를 말해드림.
이런 이유로, AWS Lambda는 내 IP가 아닌 외부 IP인데 접근이 필수적으로 필요하므로, 학습용이니깐 그냥 간편하게 All access로 하였다.
실무에서는 절대 All access로 하지말고 상황에 맞게 특정 IP를 추가하는 방식으로 진행해야 한다!

4. MySQL Workbench와 연결하기
일단 먼저, MySQL Workbench를 설치해야한다.
설치했다고 가정하에,
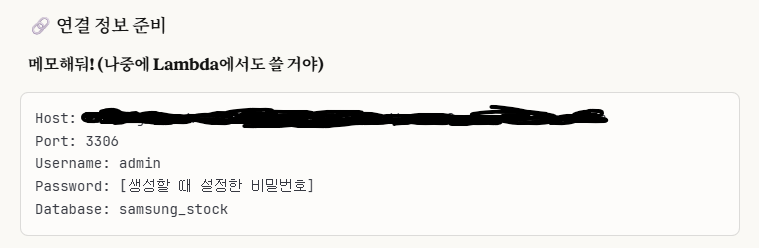
이 연결 정보를 Workbench에 New Connection을 만들어서 연결하면 된다.
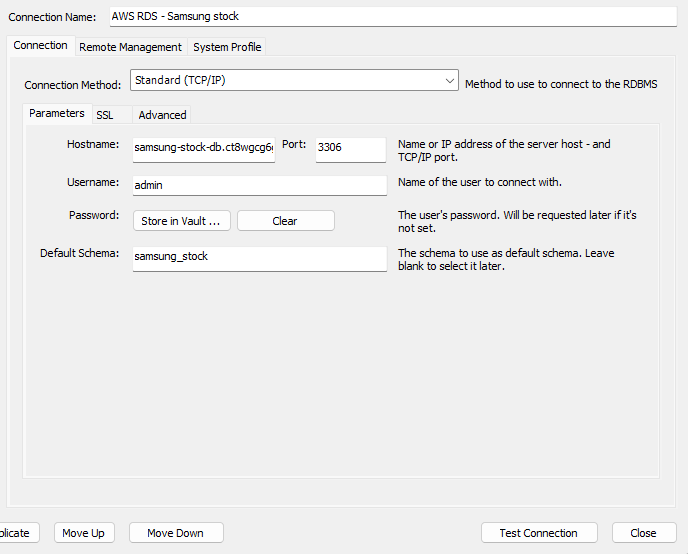
이런 식으로 작성하면 되고, test_connection을 해준다.
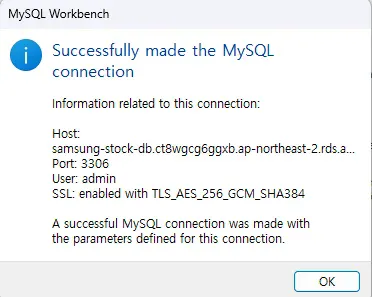
->이렇게 나오면 잘 된 것이다.
가끔 test connection이 잘 안 될 때가 있는데, 이 때, Host name이 틀리지 않았나 검토해보자.
(본인도 Host name 잘못 써서 연결이 몇번 안 됐었음.)
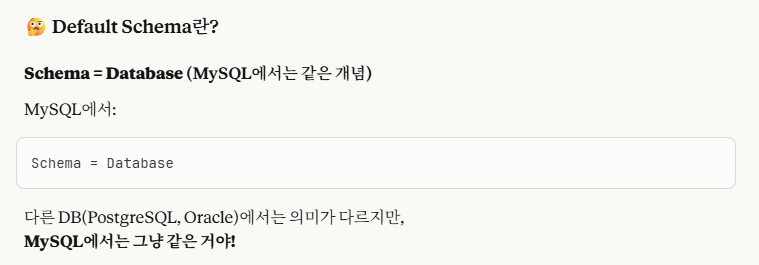
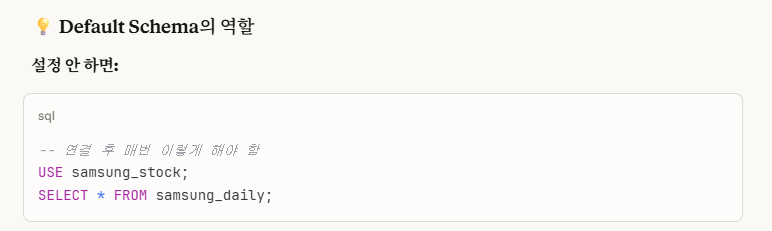
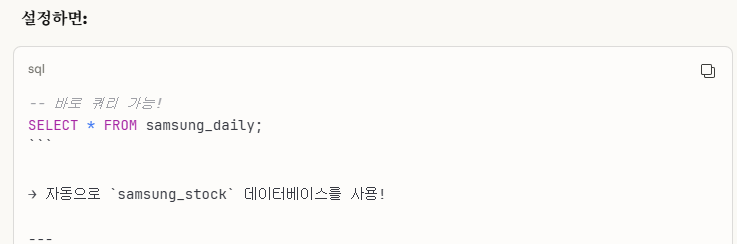
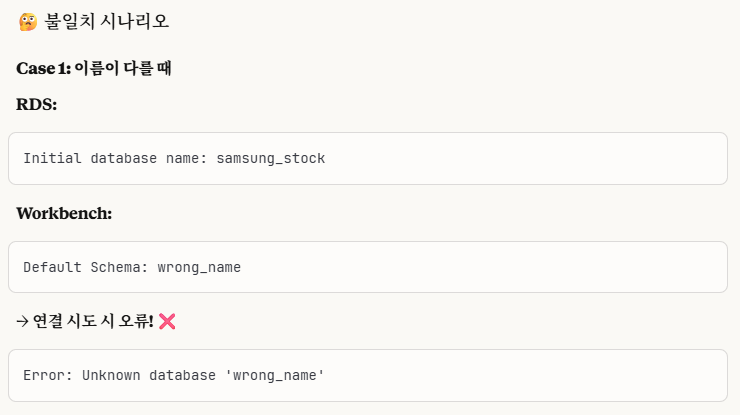
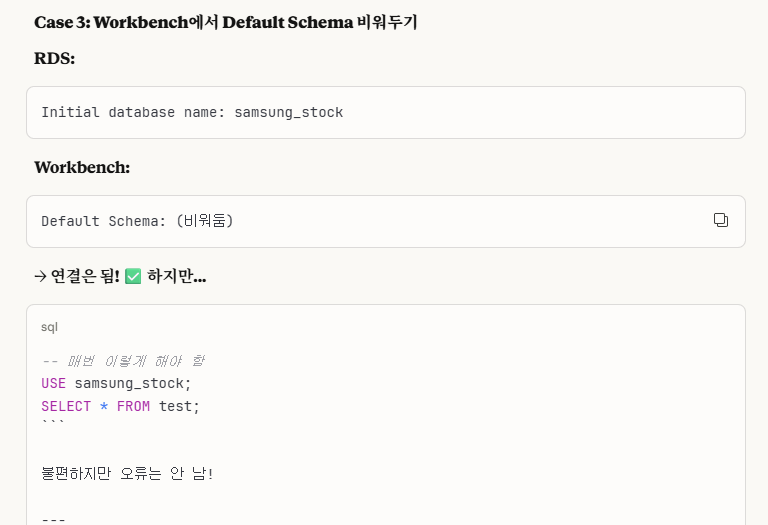
※Workbench에서 Default Schema에 대한 설명
느낌 상으로도 당연하게 일치하게 맞춰야한다는 감이 온다.
즉, 그냥 확실하게 둘 다 동일한 이름으로 설정하는 게 제일 best이다.
굳이 내가 스스로 오류를 만들어낼 필요는 없다.


4-1. 연결 테스트: 간단한 쿼리 날려보기
-- 현재 데이터베이스 확인
SELECT DATABASE();
-- 테이블 목록 확인 (아직 비어있음)
SHOW TABLES;
-- 테스트 테이블 생성
CREATE TABLE test (
id INT PRIMARY KEY,
message VARCHAR(100)
);
-- 데이터 삽입
INSERT INTO test VALUES (1, 'AWS RDS 연결 성공!');
-- 조회
SELECT * FROM test;이 SQL문으로 테스트해보자.
실행은 번개 아이콘(⚡)을 클릭하면 된다.
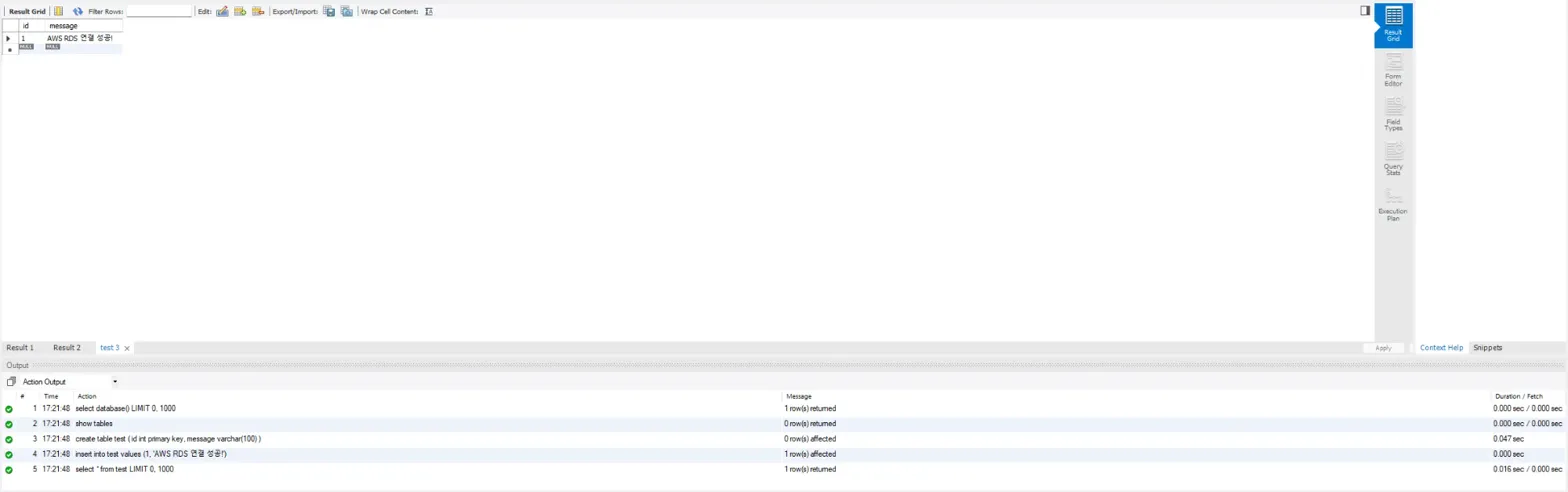
이렇게 나오면 잘 나오는 것이다.
※테이블에 아직도 아무 것도 없다면?
해당 데이터베이스를 우클릭 후, 'refresh all(모두 새로고침)'하면 최신으로 반영이 된다.
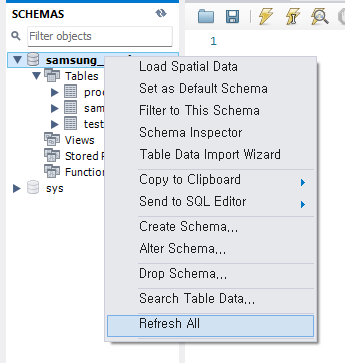
5. Lambda 함수 -> RDS 연결하기
우리가 기존에 만들었던, 'phase 3-3'에서 만들었던 lambda 함수를 일부 변형해서 RDS 연결 코드로 만들어야 한다.
코드가 어렵지는 않다. 익숙할 것이다.
우리가 전에 배웠던 코드들을 짬뽕해서 사용한다.
일단, 다음 질문들에 대해 고민을 먼저 해보자.
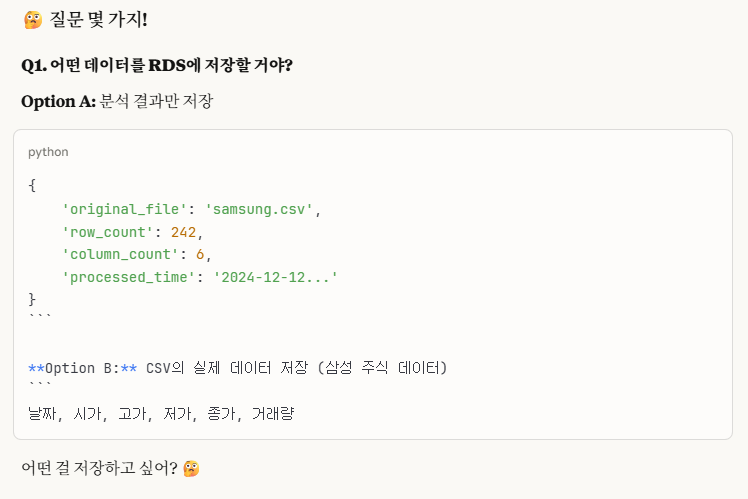
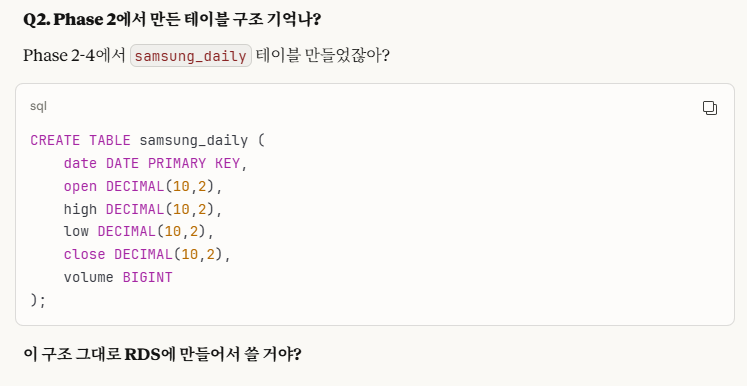

->나는 1번은 2개 다, 2번은 구조 통일로 답을 했다.
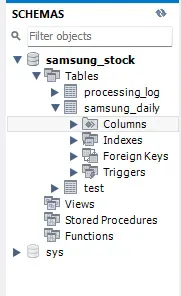
5-1. MySQL Workbench에 RDS 테이블 2개 생성하기
- samsung_daily(원본 주식 데이터 테이블)
CREATE TABLE samsung_daily (
date DATE PRIMARY KEY,
open DECIMAL(10,2),
high DECIMAL(10,2),
low DECIMAL(10,2),
close DECIMAL(10,2),
volume BIGINT
);- processing_log (처리 이력 테이블)
CREATE TABLE processing_log (
id INT AUTO_INCREMENT PRIMARY KEY,
original_file VARCHAR(255),
processed_time DATETIME,
row_count INT,
column_count INT,
status VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
이렇게 나오면 잘 나오는 것이다.
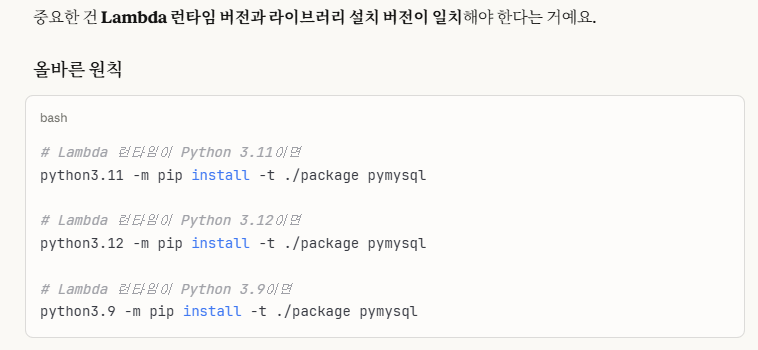
5-2. Lambda에 pymysql 추가하기


AWS Lambda는 기본적으로 boto3 외에는 외부 라이브러리를 잘 제공하지 않으므로,
누군가가 깃허브에 제공하는 공개 Lambda Layer를 사용하거나, 내가 직접 Layer를 만들어서 .zip으로 업로드하는 방법 2개가 있다.
5-2-1. 공개 Lambda Layer 사용하기
https://github.com/keithrozario/Klayers
->해당 깃허브 링크는 AWS ARN Layer를 사용할 수 있게 누군가가 공개한 깃허브 주소이다.
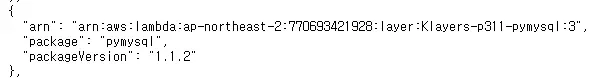
->하지만, python 3.11 버전에는 pymysql이 있지만, 3.12 버전에는 없었다.
나는 python 3.12 버전을 사용하므로, 공개 버전은 사용할 수 없었다.
⭐5-2-2. 내가 직접 layer 만들기
내 기존 폴더 트리에다가 'phase 3-4'라는 폴더를 새로 만들고,
여기에다가 'lambda-layer-pymysql-for-python-3.12' 폴더를 만들고,
VScode에서 이 해당 폴더('lambda-layer-pymysql-for-python-3.12')로 cd(change directory, 경로 변경) 한 후,
mkdir python # 'python'이라는 폴더 만들기명령어를 입력하였다.

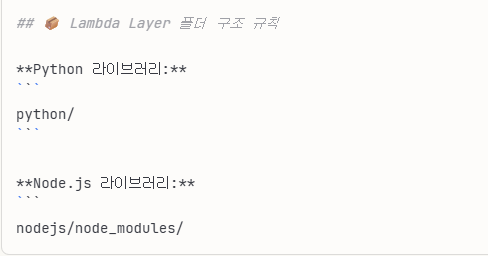

->이렇게 AWS Lambda가 해당 라이브러리를 인식하려면, 폴더명을 'python'으로 꼭 설정해야한다!
그 다음, 해당 폴더('lambda-layer-pymysql-for-python-3.12') 그대로에서 다음과 같은 명령어를 실행한다.
pip install pymysql -t python/ # 'pymysql' 라이브러리를 '-t(target, 설치 위치 지정)' 'python' 폴더로 지정해서, 여기에다가 라이브러리를 설치할 것이다.
이렇게 설치되면 잘 된 것이다.
혹시나 해서, python 설치 버전을 첨부하였다.
->해당 파이썬 설치 버전에 맞게 pymysql도 설치되므로, 꼭 python 버전을 3.12로 해야된다!
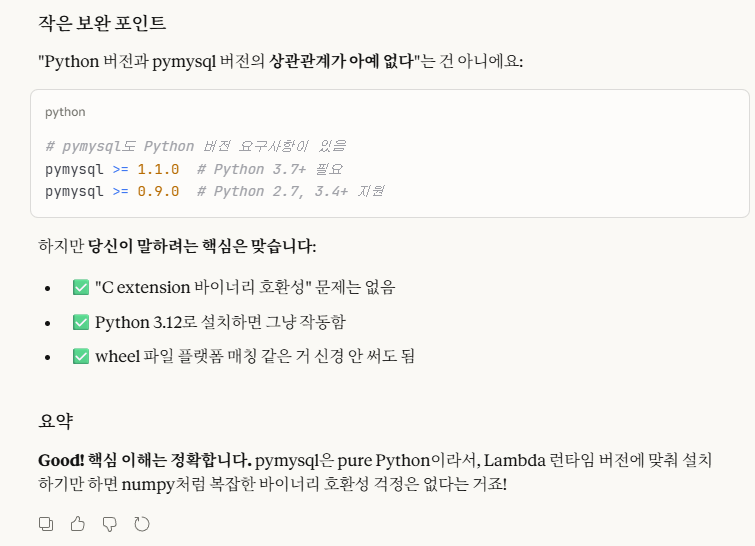
※정확한 설명(위 밑줄에 대한)
그렇다.
내가 lambda 런타임 버전을 python 3.12로 했기 때문에, 이 버전에 맞게 python 버전을 설치하는 것이지,
python 버전과 pymysql의 버전 상관관계는 이루어지지 않는다.(상관관계가 아예 없다는 말이 아니라, 복잡한 바이너리 호환성까지 안 가도 된다는 의미임.)
그 다음은, Powershell 또는 CMD에서 zip 파일을 만들면 된다.
Compress-Archive -Path python -DestinationPath pymysql-layer.zip # Powershell 명령어이 명령어의 의미는 다음과 같다.
※명령어 입력에 앞서서, cd를 먼저 해줘야한다.
VScode 새로운 Powershell 터미널 열어서 cd(경로 변경)을 한 사진이다.



->맞는 뜻이다.
이 명령어를 실행하면,

이렇게 생성된다.
※cf.)
즉, lambda가 바로 python폴더를 찾을 수 있게, python 폴더만을 압축하는 것이다.

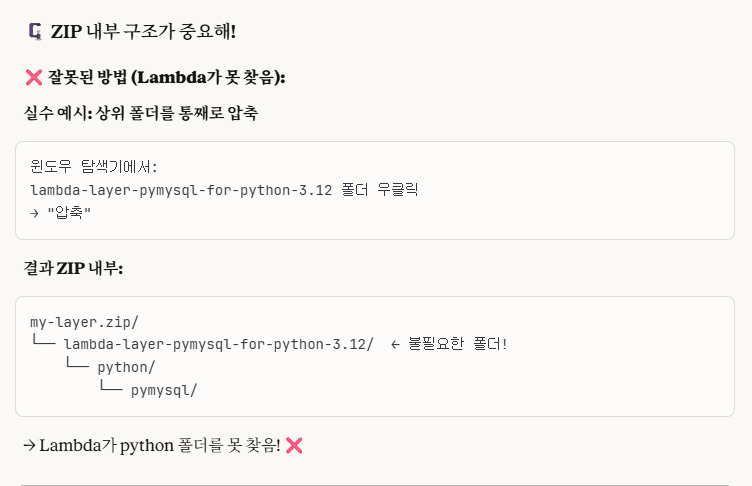
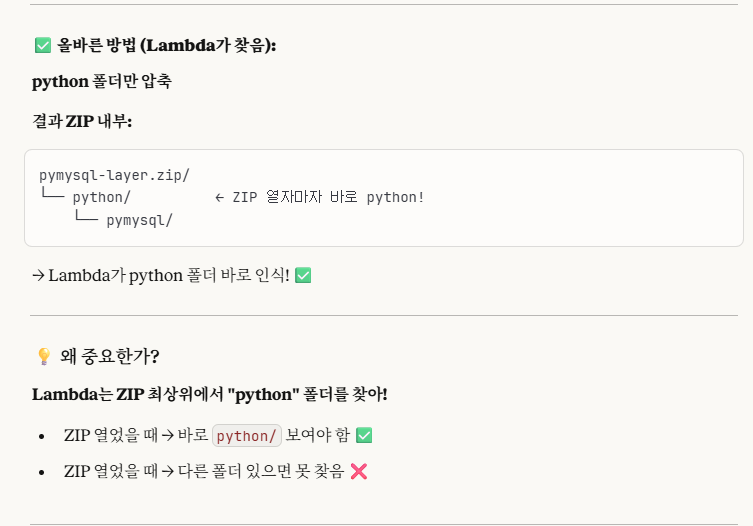

다음은 cmd로 하는 방법이다.
단순 zip 파일을 생성하는 것이므로, '관리자 권한'은 굳이 필수가 아니다.
cd "C:\Users\dc\Documents\윤상혁_데이터엔지니어\데이터 엔지니어링\Phase 3-4\lambda-layer-pymysql-for-python-3.12"->마찬가지로 해당 로컬 폴더로 cd를 해주고,
tar -a -c -f pymysql-layer.zip python이 명령어를 실행해주면 된다.
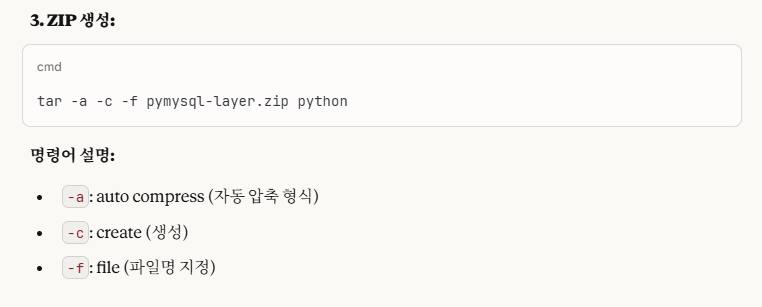
즉 해석하자면, 자동으로 압축을 해주고 파일을 생성해주는데, 파일명은 'pymysql-layer.zip'이고, 'python/' 폴더만을 압축해서 파일로 준다는 의미이다.
위와 같이 하면 결과는 이렇게 나온다.
5-2-3. Lambda Console에서 Layer 추가하기

여기서 '계층'을 클릭해서

'계층 생성' 버튼을 클릭하고
(난 이미 만들었어서 목록에 뜬다.)
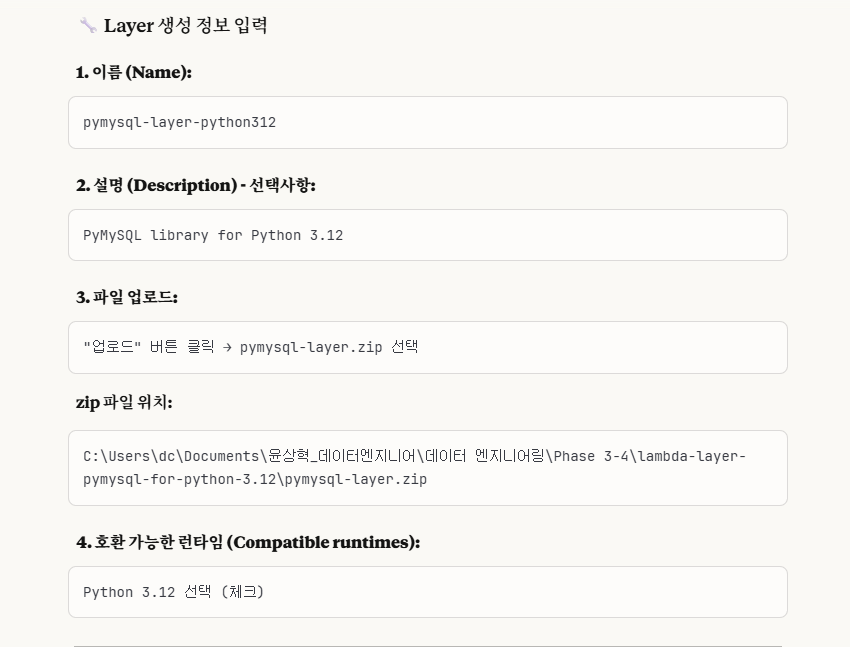
이렇게 설정을 한 다음에, 저장하면 된다.
해당 내가 만든 layer의 기본 설정은 private이다.
즉, 나만(본인 계정만) 사용할 수 있는데,
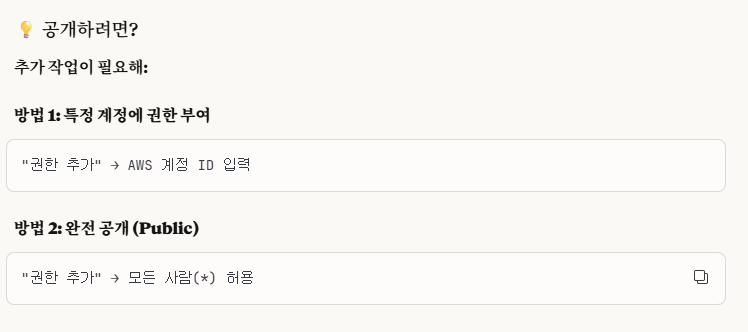
나중에 '권한 추가' -> '모두 공개'로 필요하면 바꾸도록 하겠다.
(아니면 직접 내가 한 방법처럼 만들면 된다.)
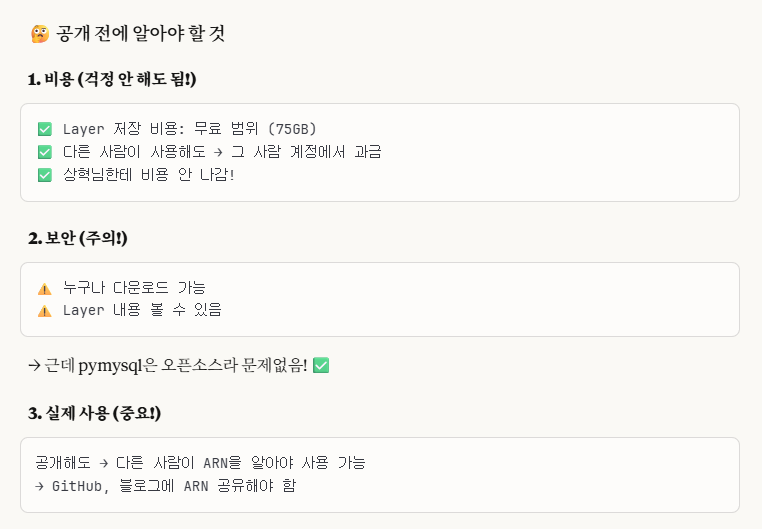
5-2-4. Lambda Console에서 추가한 Layer 등록하기
콘솔 맨 밑으로 가서 '계층'으로 가서
'add a layer' 버튼을 누르고
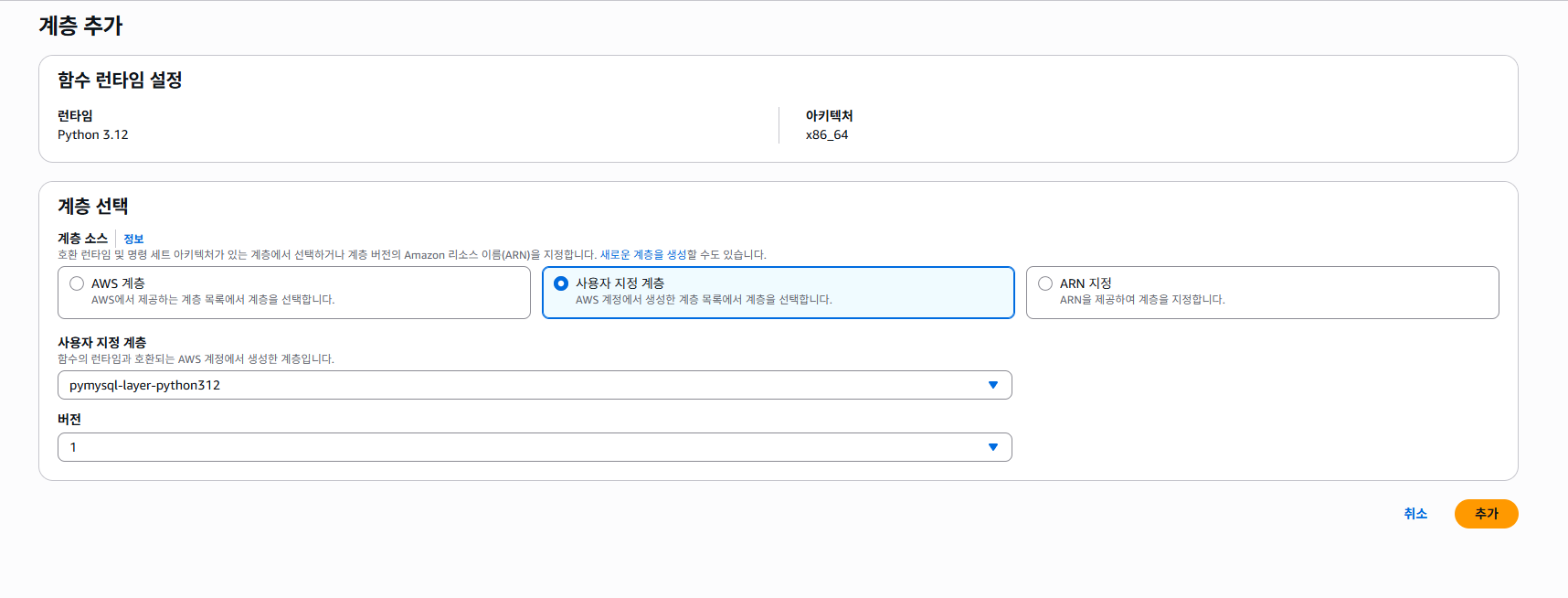
이렇게 설정하면 된다.

이렇게 나오면 잘 나오는 것이다.
5-3. Lambda 환경 변수 설정하기
※환경 변수란?
즉, 환경변수 == 미리 저장하는 설정값이라고 이해하면 된다.



Lambda Console에서 여러 탭들 있는 곳에서, '구성'탭 -> '환경 변수' 탭에 들어가서 설정값들을 등록하면 된다.
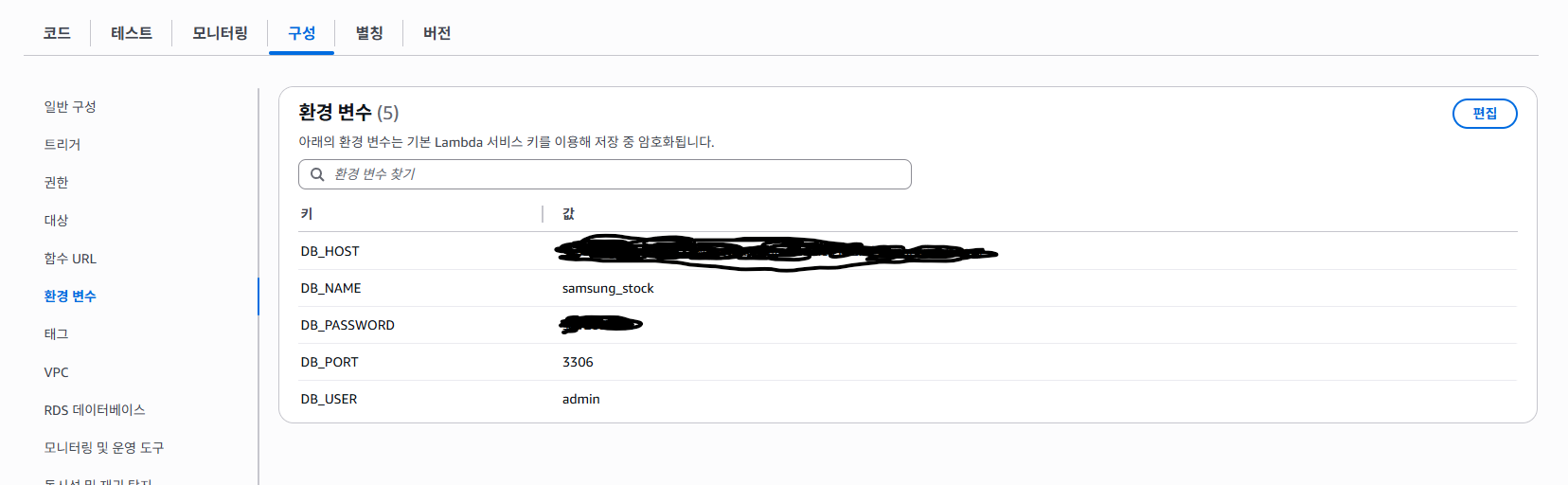
이렇게 나오면 잘 된 것이다.
⭐5-4. 기존 lambda_function.py 코드 RDS에 맞게 끔 수정하기
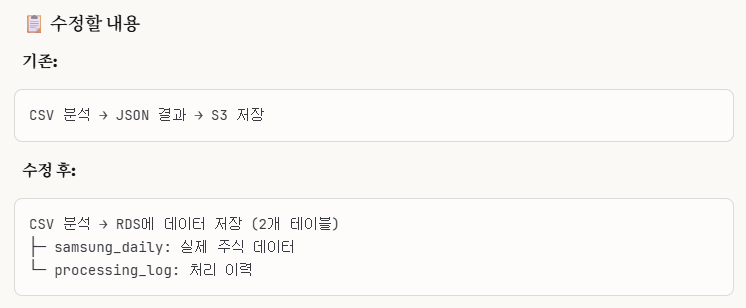
기존은 'phase 3-3' 부분을 수정 후는 지금 우리가 할 부분을 말한다.
해당 revised(수정된) lambda_function.py는 마찬가지로 내 깃허브에 공유하였다.
주석까지 상세하게 적혀있으므로 참고하면 된다.
※코드 간단한 설명
*기존 'phase 3-3'의 'lambda_function.py' 구조를 데이터베이스 연결로 바꿈. -> 기본 구조는 동일하나, 데이터베이스 부분만 추가된 거라고 이해하면 됨.
*변경된 부분: 3번의 DictReader(), 4번 ~ 끝까지(데이터베이스 설정에 맞게 새롭게 구성함.)
저렇게 작성하고 Deploy(저장)하면 된다.
5-5. 테스트
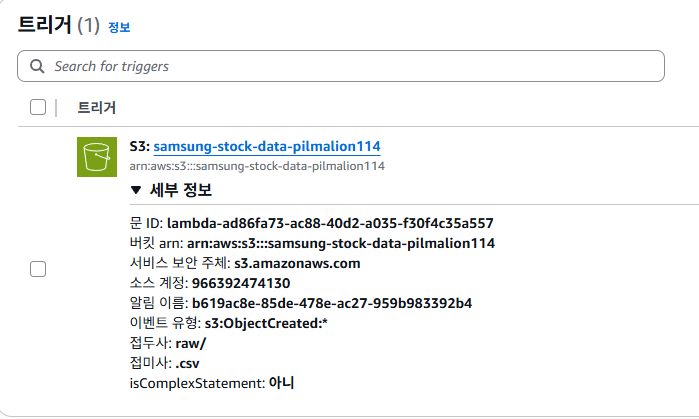
나의 S3 버킷 트리거 접두사는 raw/ 폴더로 설정되어 있다.
해당 raw/ 폴더에 들어가면,
'samsung_from_python.csv'라는 파일이 있는데,
이는 우리가 저번에 삼성주식 1년치 원본 데이터와 100% 같다.
따라서, 이 파일을 여기에다가 다시 덮어쓰기로 업로드하면 된다.
※cf.)파일이 raw/ 폴더 안에 있는데 굳이 왜 덮어쓰기로 업로드를 해야하나?
즉, S3 trigger는 '새 파일 업로드' 및 '덮어쓰기'에만 반응하므로, 다시 업로드를 해야한다.



5-5-1. CloudWatch에서 로그 확인하기
이렇게 파일 업로드를 하고 나서, CloudWatch에서 로그 기록을 확인하면 된다.
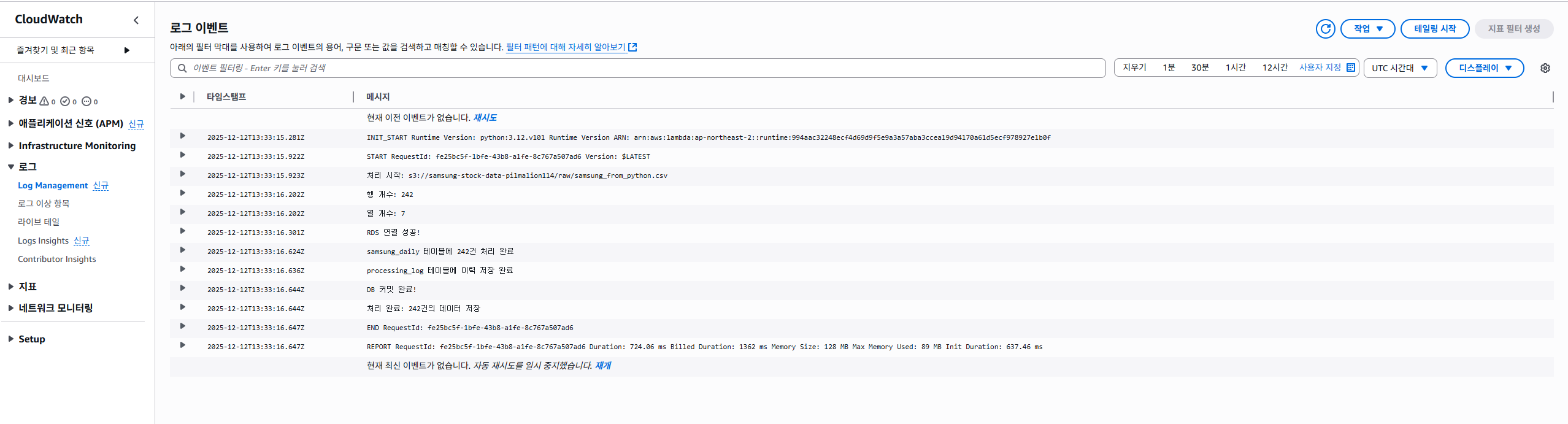
이렇게 나오면 잘 나오는 것이다.
※cf.) 주의 사항!!
1. lambda Configuration(구성) -> 제한 시간을 3초 -> 30초/1분으로 늘리기
제한 시간 때문에 timeout 문제 생길 수 있음.
2. 내 위의 깃허브 링크 들어가서 코드를 보면, 밑에 사진을 참고하면,
이 부분에서 상당히 에러가 많이 났다.
이는 '인코딩' 에서 문제가 발생한 건데,
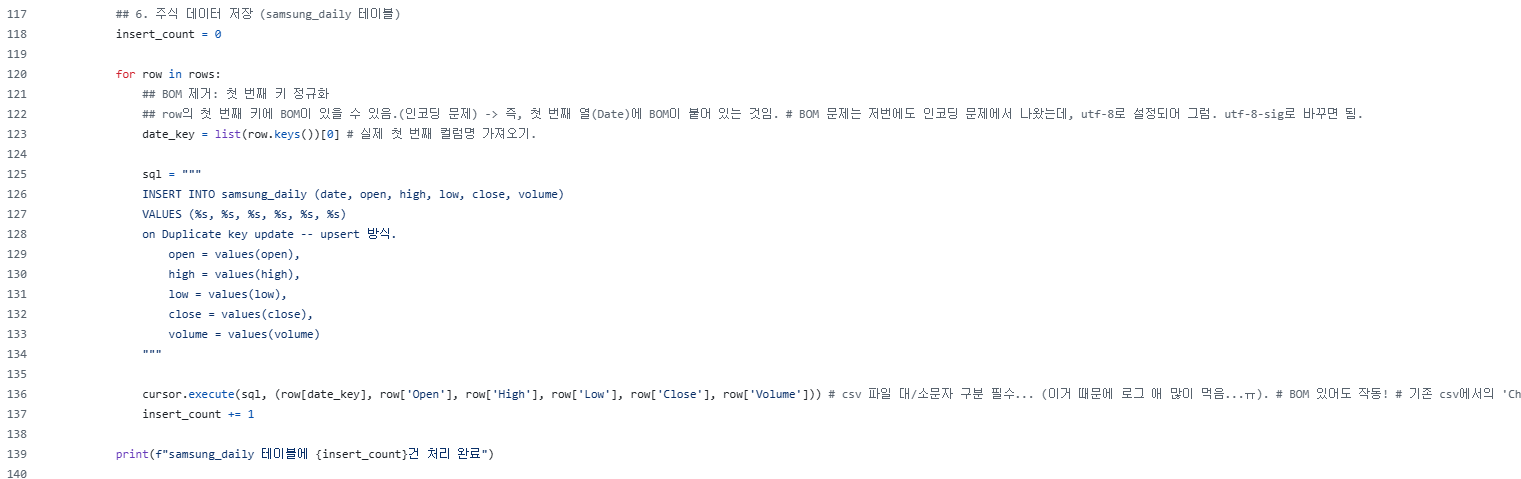
깃허브 주석에도 나와있지만, 'BOM'문제가 발생해서 그런 것이다.(BOM은 이상한 특수문자가 끼어있는 상태라고 이해하면 된다. 우리가 전에도 한 번 다뤘었다.)row의 첫 번째 키에 BOM이 있을 수 있음.(인코딩 문제)
그래서,
date_key = list(row.keys())[0] # 실제 첫 번째 컬럼명 가져오기. cursor.execute(sql, (row[date_key], row['Open'], row['High'], row['Low'], row['Close'], row['Volume'])) # date_key 변수로 그대로 불러오므로 BOM이 있어도 작동.이렇게 해결하면 된다.


Workbench에서도 데이터가 잘 들어옴을 확인할 수 있다.
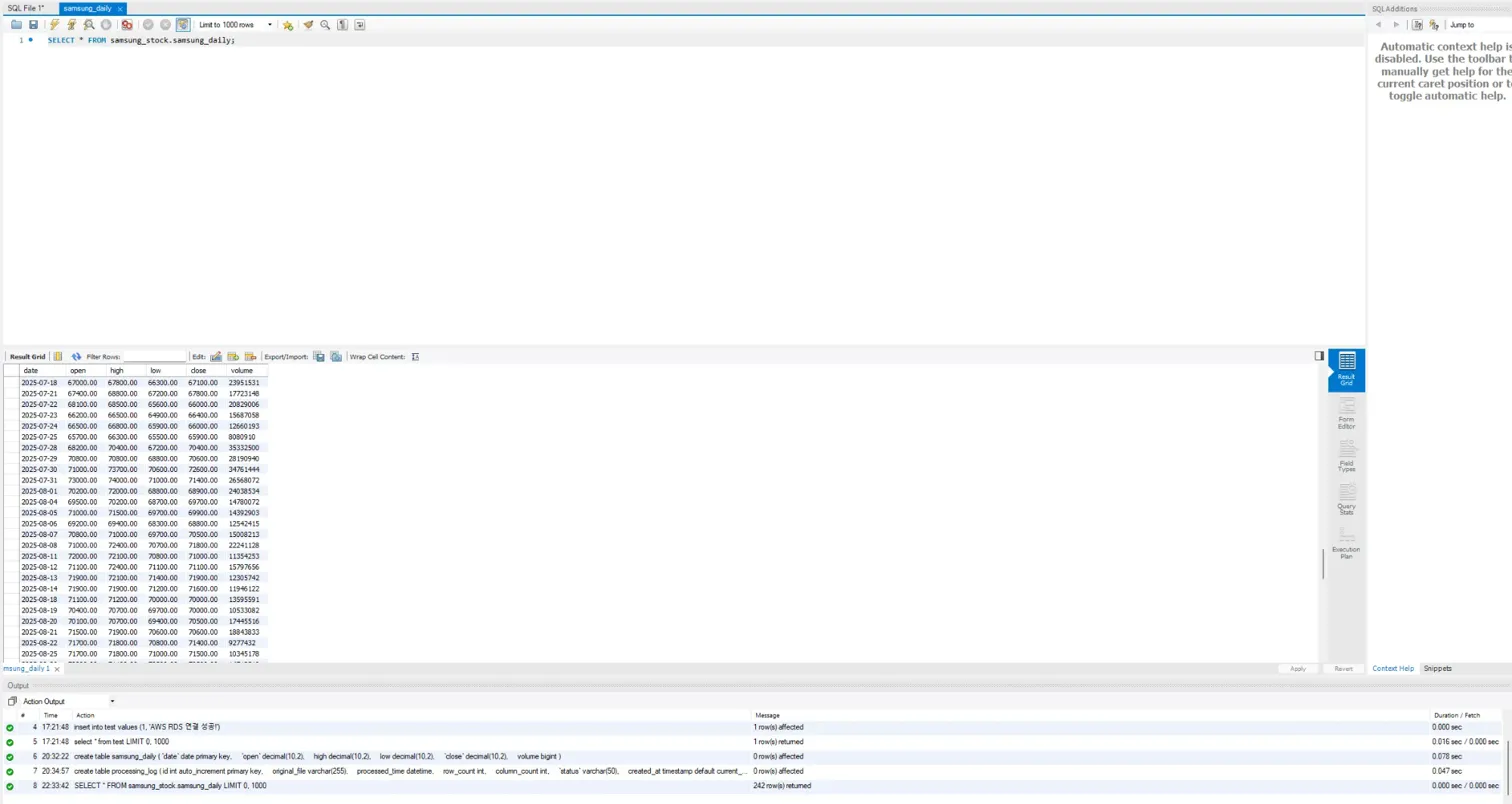
-> samsung_daily 테이블에 242개 잘 나옴.
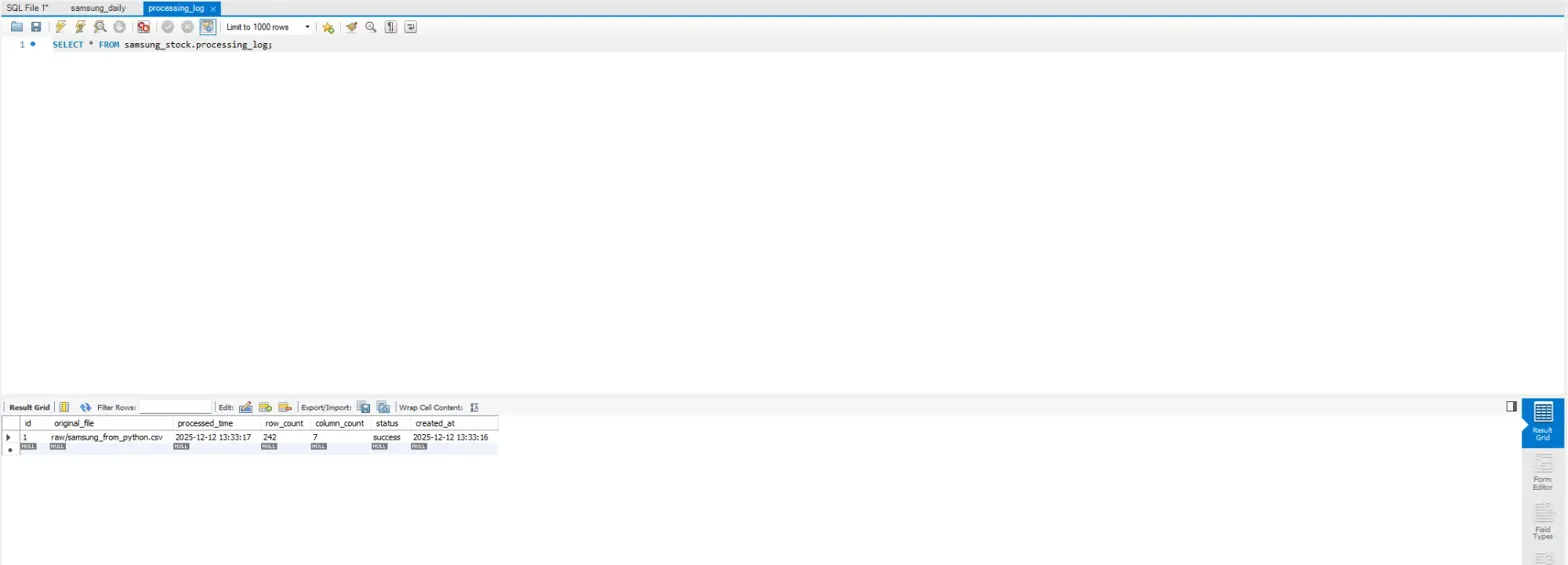
-> processing_log 테이블도 잘 나옴.
6. 마무리 및 결론
이번 게시글은 오랜만에 길게 쓸 게 많았다.
과정으로만 본다면 어렵지는 않았지만, 중간중간 실패 경험들이 많아서 쓸 게 좀 많아졌다.
그만큼 내 지식 소스들이 쌓인다고 긍정적으로 해석하면 될 거 같다.
오늘도 제 긴 글을 읽어주셔서 감사합니다! :) bb
다음은 'phase 3-5'로 찾아뵙도록 하겠습니다!
