정말 속상하게도, 이번 작업은 제대로 이루어지지 않았다.
그 이유에 대해서는 뒤에서 설명을 하도록 하겠다.
이번 게시글은 프로젝트 학습 내용보다는 무엇이 문제였는지 회고하는 식의 게시글이 될 거 같다.
1. 원래 Phase 5-2 계획
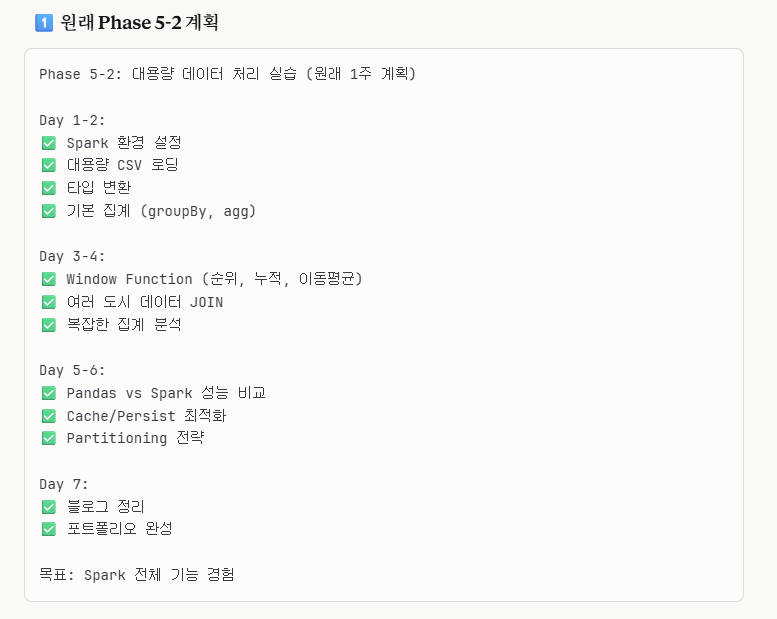
원래의 우리 계획은 이렇게 할 예정이었다.
하지만, 이번 작업은 완전히 망쳤다.
2. 실제로 한 작업들
위 깃허브에 업로드한 .ipynb 파일을 보면 직접 확인이 가능하다.
간단하게 요약하자면,
1.Cell 1: Google Drive 마운트
2.Cell 2: 파일 확인
3.Cell 3: PySpark 설치 & SparkSession 생성
4.Cell 4: 첫 CSV 로딩 시도
5.Cell 5: 파싱 문제 확인
6.Cell 6: 파싱 옵션 추가하여 재로딩
7.Cell 7: price 타입 변환
8.Cell 8: 나머지 컬럼 타입 변환
9.Cell 9: 검증
9번까지 작업을 하던 도중에, 문득 이런 생각이 들었다.
'아니 근데 지금 이 작업이 Spark만의 작업이 맞는 건가?'
곧바로 Claude에게 질문을 했는데, 역시나 답변은 좋지 않은 쪽으로 흘러갔다.
충분히 Pandas로도 할 수 있는 작업을 나는 중복해서 하고 있는 것이었다.
그럼 도대체 우리가 한 Spark만의 작업은 무엇이고, 왜 Spark만의 작업을 할 수 없었던 것일까?
1. 우리가 한 Spark 작업들
- SparkSession 초기화

- Spark DataFrame 생성
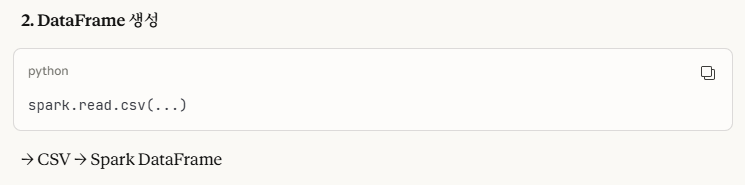
- CSV 파싱 옵션
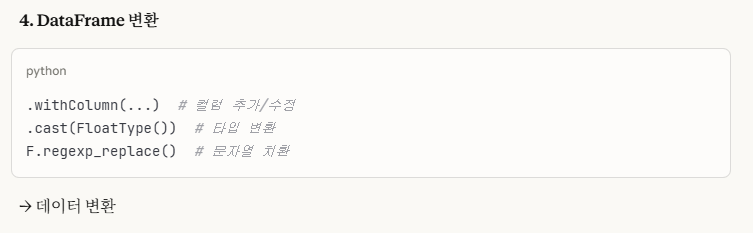
- Spark DataFrame 변환
- Spark DataFrame 조회
- Lazy Evaluation(지연 실행)

->요약하자면, pandas는 각 줄을 바로 실행하여 메모리에 올리지만, Spark는 df.show()가 나오기 전까지 실행을 안 하고, 계획에만 올려놓고 한 번에 최적화하여 실행을 한다는 것이다.
정말 별 거 없는 작업들이다.
그렇다면 우리는 왜 Spark만의 작업을 하지 못한 것일까?
2. 우리가 Spark만의 작업을 하지 못한 이유
- 로컬 환경 -> colab 무료 버전 -> 1대의 머신만 사용
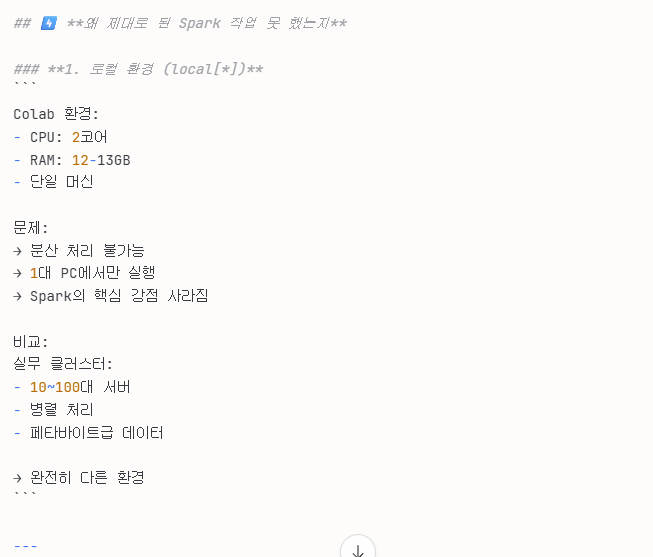
- 작은 데이터 크기

- 분산 처리 체험 불가 -> 1번이랑 이어지는 내용

3. 우리가 하지 못한 다른 Spark 작업들

하지만, 이 작업들이 별로 의미있다고 생각이 안 드는 이유는,
일단 현 상황 자체가 이를 하기에 적합하지 않기 때문이다.
조건 필터링, 집계, 테이블 조인,window function 등의 기능들은 이미 phase 1이나 앞에서 해봤던 것들이고, 지금 상황에서는 앞에서 했던 phase들의 학습을 중복해서 하는 꼴 밖에 안 된다.
메모리 최적화,파티셔닝,join 최적화,spark sql 또한 현 소규모 데이터와 로컬 1대의 컴퓨터 환경에서는 그리 의미있는 작업은 아니라고 판단된다.
4. 마무리 및 결론
정말 아쉬운 학습이었다.
여태 phase 학습 중에서 유일한 미완성 학습으로 기록되는 것 같다.
다음 게시글이나 아니면 후에라도 위와 같은 작업들을 진정으로 경험할 수 있는 날이 오기를 바란다.
내 데이터 엔지니어링의 마지막 phase 학습인데,
좋게 마무리되지 못한 거 같아 아쉬움만 남는다.
다음에는,
'실무 심화 3개 정도의 exercise'를 가져와서 이에 대해 글을 작성해보고자 한다.
오늘도 제 글을 읽어주셔서 감사합니다 :)
