이번 'Phase 5'는 본격적으로 빅데이터를 다루는 단계입니다.
이번 게시글의 순서는 다음과 같습니다.
1.Spark vs Pandas 개념 핵심 요약
2.Google Colab 실습
1. Spark vs Pandas 개념 핵심 요약

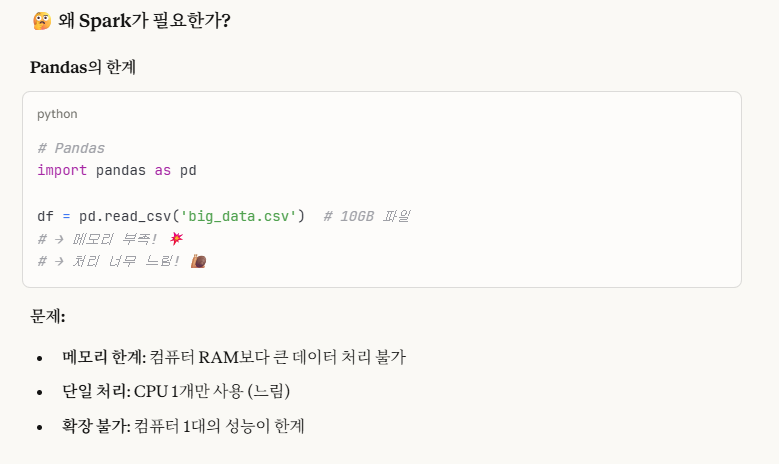
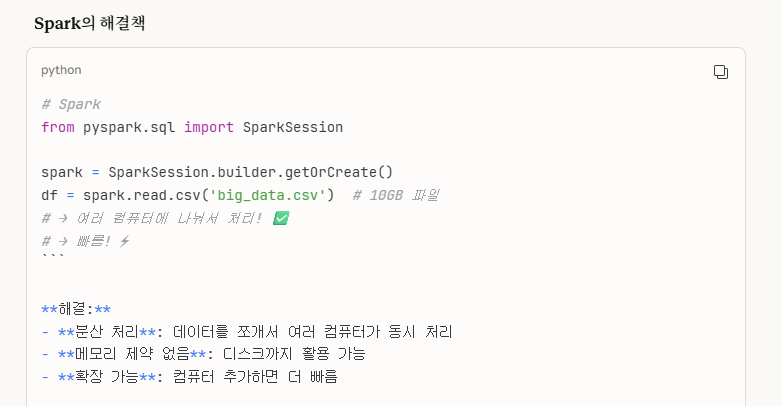

->Pandas vs Spark 비교표


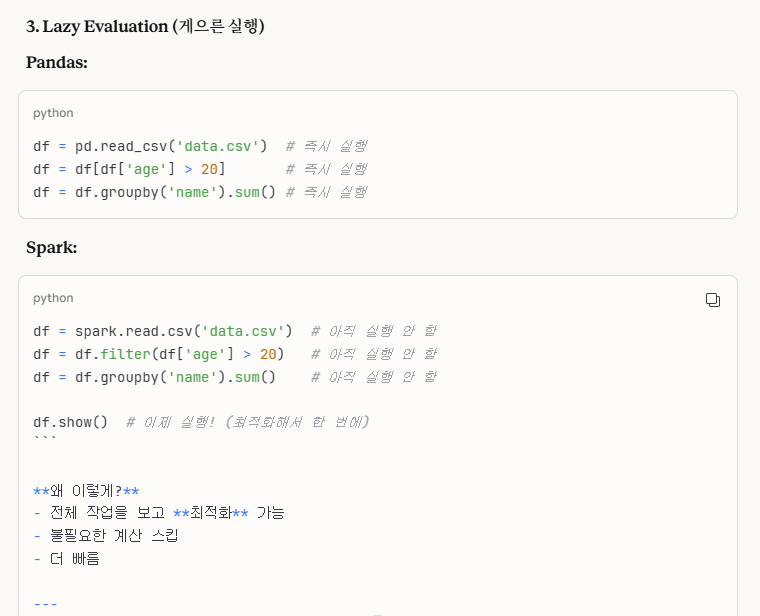
-> Lazy Evaluation(게으른 실행)

즉, 한 마디로 요약하면, pandas는 컴퓨터 1대에 cpu 1개 사용에, 사용자 RAM 크기만큼의 데이터만 가능한, 소규모의 데이터 활용에만 쓰이는 거고.(컴퓨터 1개로만 운영)
Spark는 컴퓨터 여러 대를 활용해서 빅데이터를 분산해서 사용하며, RAM 뿐만 아니라 Disk 저장공간도 활용해서 메모리 제약이 없는 편이고, 컴퓨터가 많으면 많을 수록 처리 속도가 빠르다. 그래서 빅데이터에 사용된다.(컴퓨터 여러 개로 운영)
2. Google Colab 실습
Google Colab 실습한 .ipynb를 깃허브에 업로드하였다.
역시 설명이 자세하게 잘 되어 있으므로, 여기에 따로 설명은 생략하겠다.
3. 마무리 및 결론
이렇게 해서 오늘은 Spark(빅데이터 처리 방법)에 대해서 간략하게 알아보았다.
다음에는 Phase 5-2(대용량 데이터 처리 - 본격 실습)으로 돌아오도록 하겠다.
->phase 5-2가 우리의 데이터 엔지니어링 학습 프로젝트의 마지막 부분이다.
오늘도 제 긴 글을 봐주셔서 감사합니다 :) bb

통합형 개발자. 기획부터 개발, 자동화까지. 문제를 구조적으로 이해하고, AI를 능동적으로 활용해 본질적인 해결책을 제시하는 사람입니다.