안녕하세요!
이번에는 문제 풀이가 아닌 실습으로 돌아왔습니다!
sql에는 인덱스라는 개념이 있는데요.
간단하게 말하자면, 이 '인덱스'는 '조회를 빠르게 하기 위함'이라고 말할 수가 있습니다.
인덱스에 대한 개념 정리를 자세하게는 하기 힘들 거 같긴 한데요...
그래도 개념 설명을 안 하고 바로 실습으로 진행한다면, 좀 찝찝하긴 하겠죠...?
간단하게 인덱스에 대해 개념 설명을 먼저 해보도록 하겠습니다.
1. 인덱스(index)란?
인덱스의 단어 자체의 의미는 '색인'이란 뜻입니다.
색인이란 무엇일까요?
우리가 흔히 영어사전을 보면, 맨 뒷 페이지에 색인 부분이 같이 있음을 알 수 있을 것입니다.

이렇게 해당 단어의 위치를 빠르게 찾아갈 수 있도록 도와주는 것을 '색인'이라고 합니다.
SQL의 인덱스 역시 이 '색인'의 단어적 의미에서 유래되었습니다.
1-1. SQL에서의 index는 무엇일까?
저는 처음에 sql의 index를 1,2,3,4 같은 auto_increment 형식의 숫자인 줄 알았어요.
마치 대리키 개념으로 말이죠.
아예 틀린 말은 아니지만,
좀 더 정확하게 개념을 알아둘 필요가 있어요!
SQL의 인덱스 역시 정의 자체는,
'키워드 -> 위치' 매핑 구조에요.
즉, 앞에서 말한 사전 구조와 동일하다고 보면 돼요.


일반적인 인덱스 형태는 'non clustered index'에요.
위 사진을 보면,
원본 데이터 파일이 있고,
여기에 추가로 index 파일을 생성해요.
이 때 인덱스 파일은, 우리가 인덱스로 생성할 열을 선택해서 이 열을 기준으로 먼저 정렬을 진행해요.
그리고 이 정렬된 열에 있는 데이터를 활용해서,
b-tree, hash, b+ tree 같은 자료구조를 활용해서
검색 알고리즘을 만들어줘요.
->말이 알고리즘이지 사실상 위의 자료구조 특성을 그냥 활용해서 만들어요.
※cf.) 정렬 알고리즘 후 -> b-tree 구조로 저장.

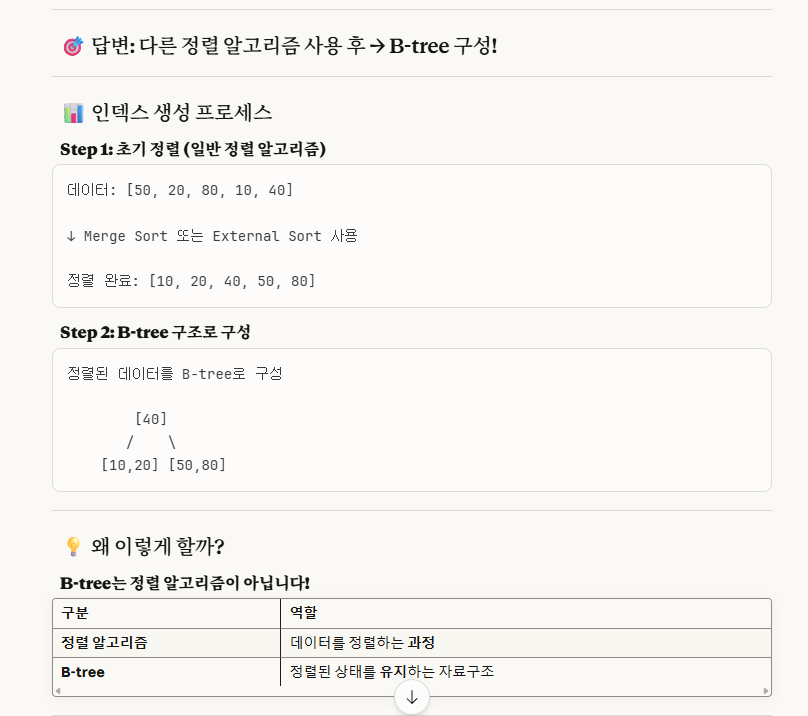


여기서 1% 틀린 부분은 인덱스의 개념을 바로 잡기 위함인데,

이렇게 인덱스는 단순히 배열의 인덱스와 같이 0,1,2,.. 와 같은 연속적으로 증가하는 숫자 개념이 아닌,

위의 사진처럼, (키,값) 형태인 key-value 형태로 저장됩니다. 이 전체 자체가 인덱스입니다.
여기서 key는 우리가 정렬을 시도한 열에 있는 데이터들을, value가 pointer(실제 데이터가 원본 테이블에 있는 행의 위치를 가리킴)를 나타냅니다.
<실제 인덱스 만드는 sql 질의문>

이렇게 create index를 통해서 인덱스를 생성합니다.
위의 사진을 참고하면 inx_created는 인덱스 명을
on users(created_at)은 users 테이블의 'created_at'이라는 열을 이용해서 인덱스를 만드는 것을 의미합니다.
1-1-1. 인덱스를 사용하는 본질적 이유
우리가 100만개의 행의 데이터를 가지고 있다고 가정해봅시다.
그리고 우리가 where절을 이용하여 어떤 특정 조건을 만족하는 행을 구하고 싶다고 가정해봅시다.
만약에 우리가 인덱스가 없다면, 우리는 처음부터 끝까지 모든 행을 다 돌아야할 것입니다.
마치 brute-force와 같은, O(n)의 시간이지만 실질적으로는 O(100만)의 엄청난 시간이 걸리죠.
하지만, 우리가 인덱스의 개념을 이용한다면,
인덱스의 자료구조적 특징(b-tree,hash)으로 인하여 검색 시간을 압도적으로 단축시킬 수 있습니다.
->O(100만) -> O(몇십번)
※이런 이유로 우리는 '인덱스'를 사용합니다.
더 길게 개념 설명을 하고 싶으나,
그러면 너무 길어질 거 같아서 이 정도만 설명하고 실습으로 넘어가겠습니다.
2. 실습
2-1. 데이터베이스 환경 구축하기
먼저 저는 이전 '데이터베이스 학과 프로젝트' 때와 마찬가지로 phpmyadmin을 활용해서 웹 데이터베이스(MySQL)로 진행하였습니다.
2-1-1. DB 생성하기
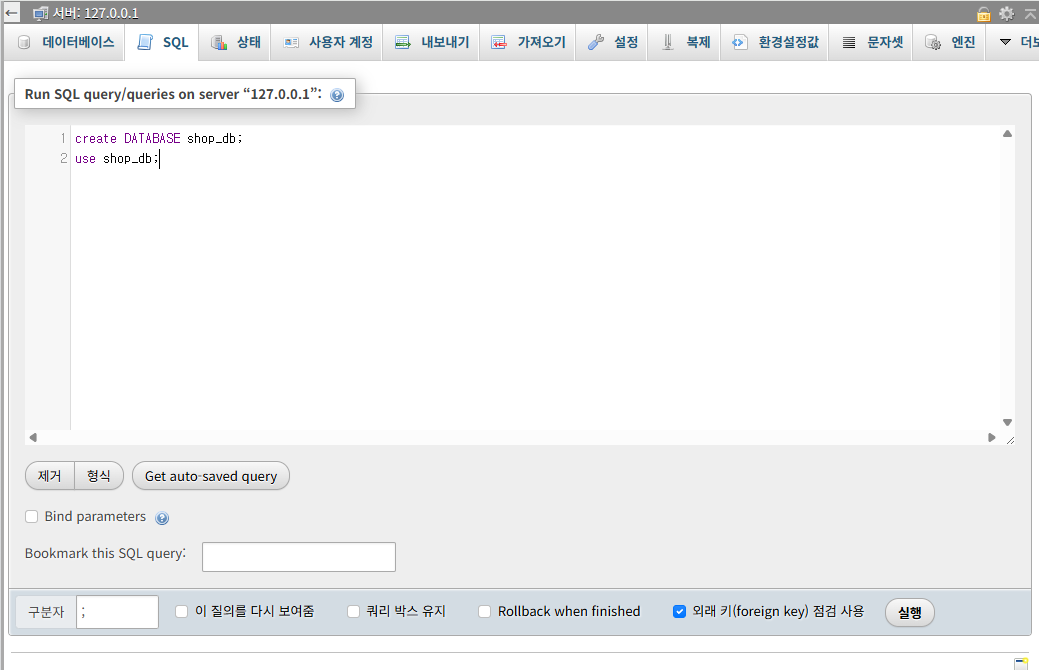
위 질의문으로 DB를 생성하고, 이 DB를 사용합니다.
->DB는 'shop_db'로 쇼핑과 관련한 데이터베이스입니다.
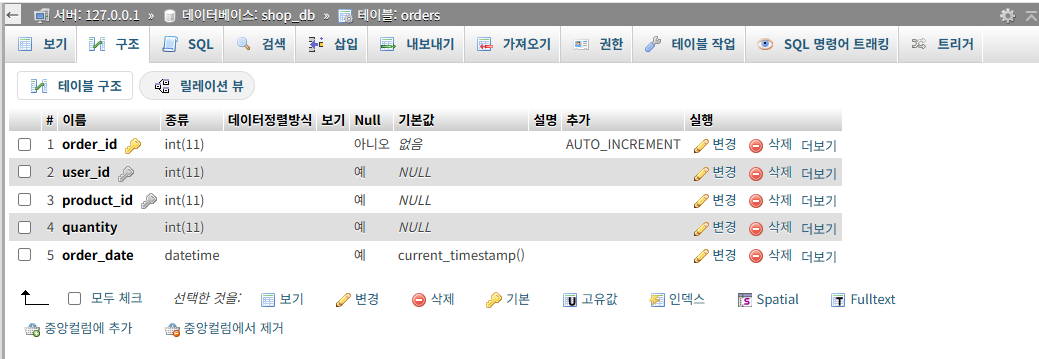
2-1-2. 테이블 생성하기
저는 총 3개의 테이블을 생성할 것입니다.
3개의 테이블은 각각 '샤용자(users)', '상품(products)', '주문(orders)' 테이블입니다.
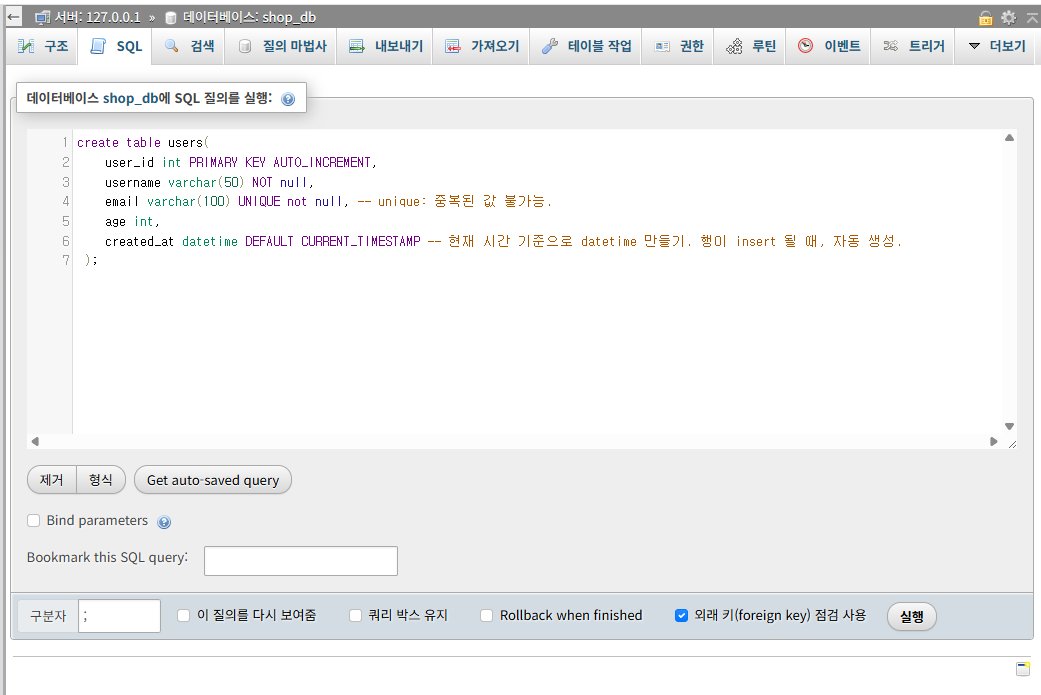
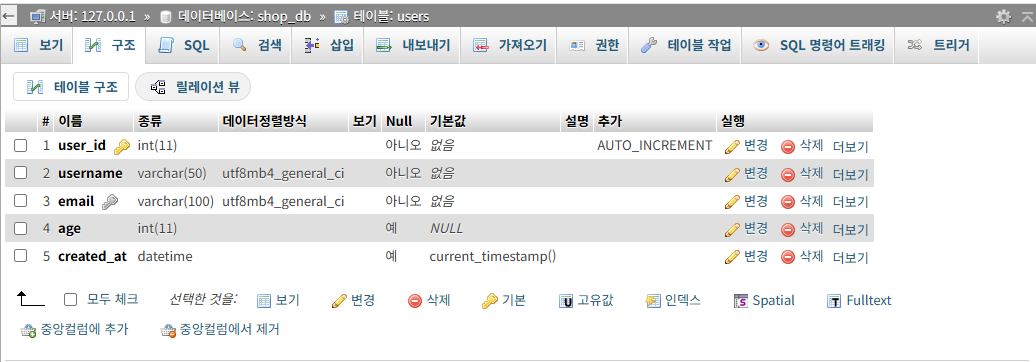
<샤용자(users) 테이블>
CREATE TABLE users (
user_id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
age INT,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
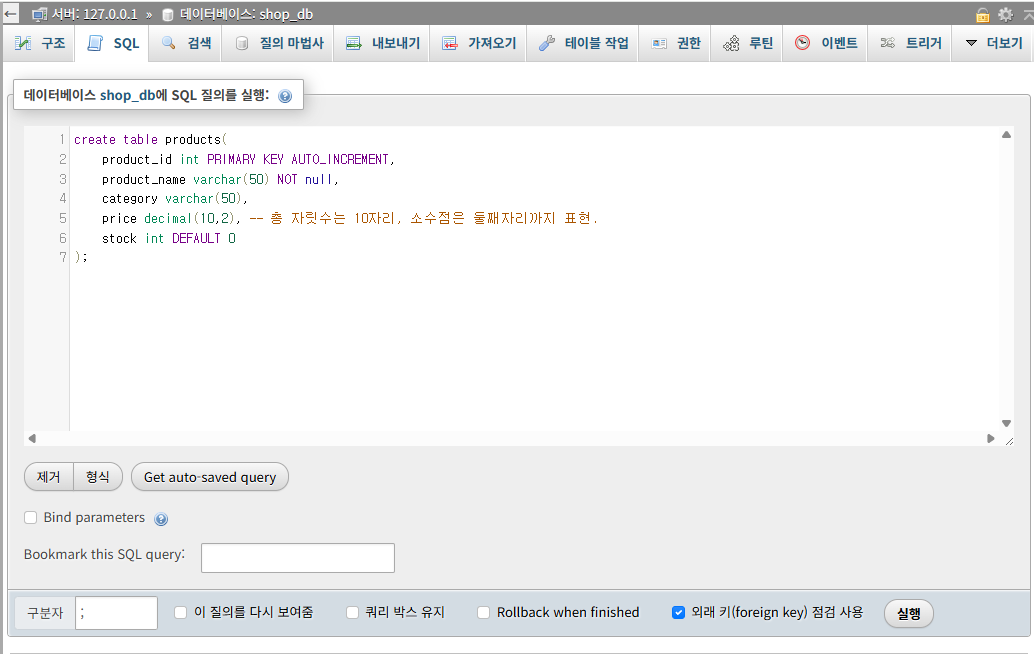
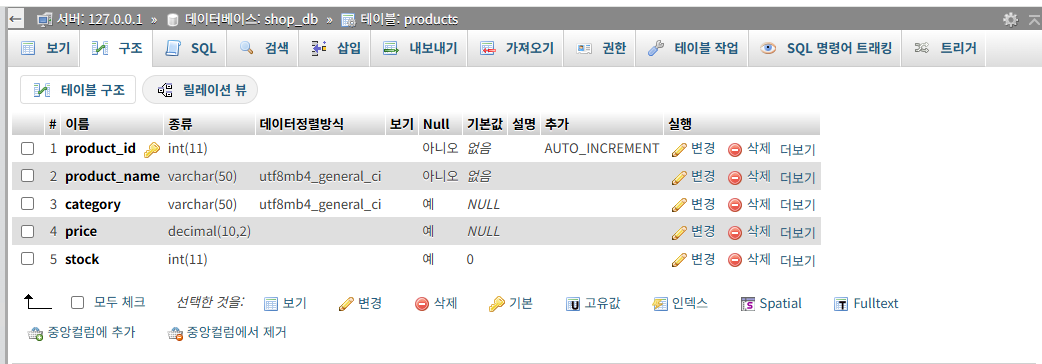
<상품(products) 테이블>
CREATE TABLE products (
product_id INT PRIMARY KEY AUTO_INCREMENT,
product_name VARCHAR(100) NOT NULL,
category VARCHAR(50),
price DECIMAL(10,2),
stock INT DEFAULT 0
);
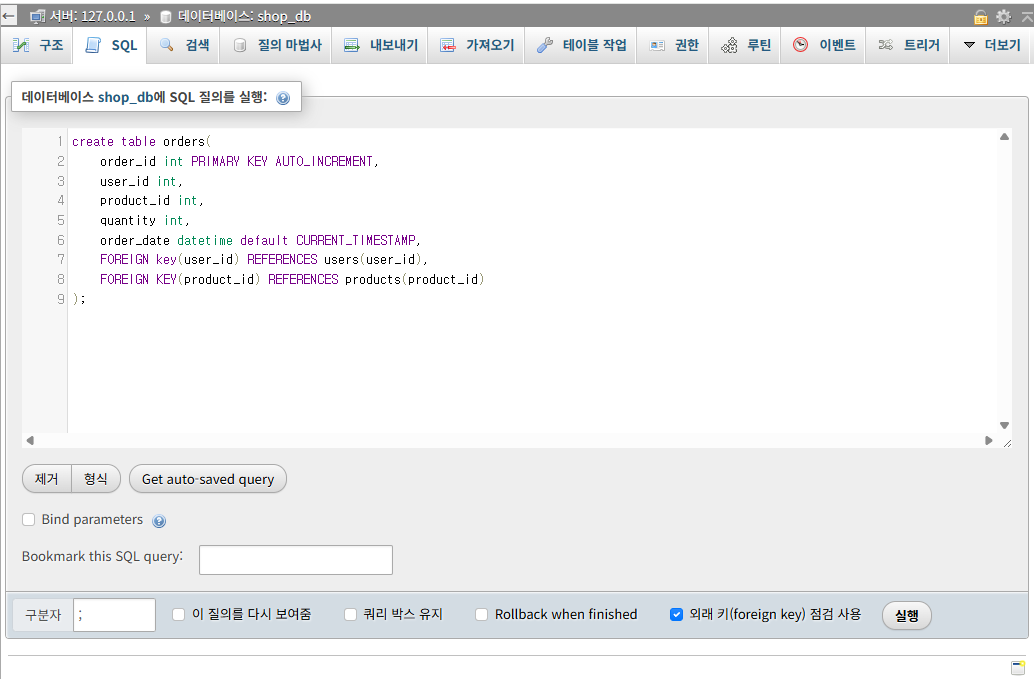
<주문(orders) 테이블>
CREATE TABLE orders (
order_id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT,
product_id INT,
quantity INT,
order_date DATETIME DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(user_id),
FOREIGN KEY (product_id) REFERENCES products(product_id)
);
2-1-2-1. erd로 테이블 관계 표현하기
저는 단순 테이블 생성 코드만 작성하는 게 아닌,
erd를 통해서 테이블 간의 관계 또한 표현하고 싶었습니다.
저는 'dbdiagram.io'라는 웹 기반 erd 사이트를 통해서 erd를 만들었습니다.
->이 웹사이트는 sql 코드를 기반으로 테이블을 자동 생성해주고, ref(reference)를 통해 관계 또한 표현해줍니다.
다만, 'dbdiagram'과 'mysql' 코드는 서로 약간 문법이 달라서, 이 부분은 claude의 도움을 받아 진행하였습니다.
<dbdiagram 코드>
Table users {
user_id int [pk, increment]
username varchar(50) [not null]
email varchar(100) [unique, not null]
age int
created_at datetime [default: `CURRENT_TIMESTAMP`]
}
Table products {
product_id int [pk, increment]
product_name varchar(100) [not null]
category varchar(50)
price decimal(10,2)
stock int [default: 0]
}
Table orders {
order_id int [pk, increment]
user_id int
product_id int
quantity int
order_date datetime [default: `CURRENT_TIMESTAMP`]
}
// 관계 정의 (Foreign Key)
Ref: orders.user_id > users.user_id // 1:m 관계
Ref: orders.product_id > products.product_id // 1:m 관계
// >을 크기 비교 연산자로 이해하면 쉬움. 큰 쪽이 m, 작은 쪽이 1로.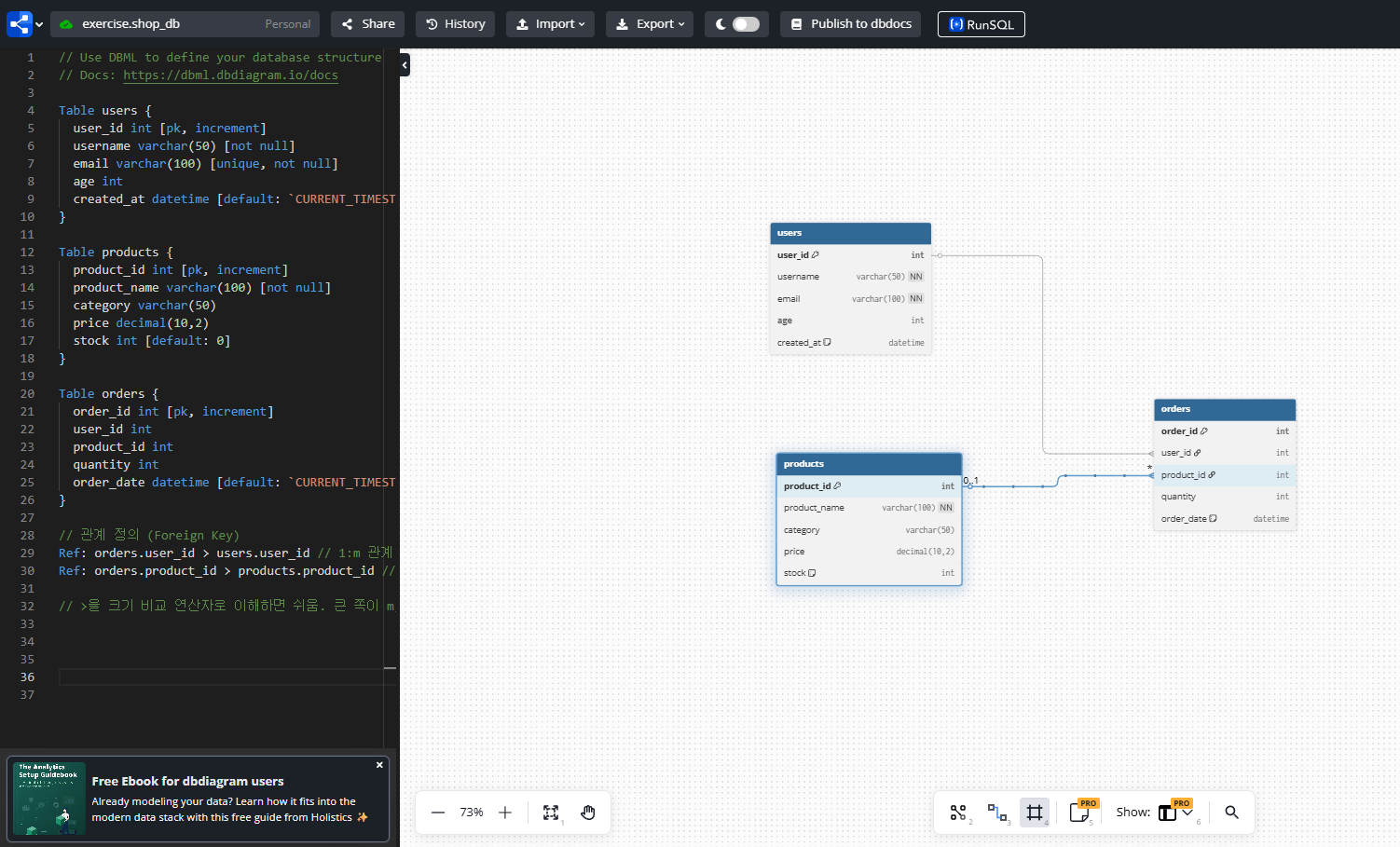
⭐※개념_1. ERD(개념/논리 설계)에서는 관계(1:1,1:n,n:m)을 표현하고, 실제 테이블(물리 설계)에서는 그 관계를 fk를 통해서 구현한다.
이렇게,
ERD에서 1:1,1:n,n:m으로 표현한 것을,
실제 sql문으로 테이블을 생성할 때에는 fk(1:n), fk+unique(1:1), 중간 테이블 생성(n:m)을 통해서 구현을 합니다.즉, 위 'dbdiagram.io'에서 ref로 언급한 코드는 erd에서의 관계를 표현(1:n)을 한 것이고, 실제 테이블(phpmyadmin 테이블 생성)에서는 fk로 우리가 구현을 한 것임을 알아둬야합니다.






※cf.)
'dbdiagram.io'에서 관계 화살표를 통해서 관계를 나타내는데, 특히 1:n에서 '>' 이 부분을 '크기 비교 연산자'로 이해하면 쉽습니다.
큰 쪽이 n이고, 작은 쪽이 1로 하여 이해하면 쉽습니다.

2-2. 더미데이터 만들기
일단은, 본격적인 실습을 진행하기에 앞서, 공지를 먼저 하고자 합니다.
앞의 2-1에서 했던 DB 및 테이블 설계에서 이어서 진행하나, 'user_logs'라는 새로운 테이블을 생성하여, 여기서 더미데이터를 만들어서 '인덱스 유무에 따른 성능 차이'를 비교할 예정입니다.
그 이유는, 실무에서도 user log 데이터를 많이 활용한다고 하니, 최대한 실무에 가깝게 느낌을 내기 위해서 이렇게 시도한 점 양해부탁드립니다.
즉, 앞 부분은 'erd 설계 및 그것을 실 테이블로 표현'에 중점을 맞췄다고 생각하면 되고, 여기서는 실제 user logs 더미데이터를 활용하여 인덱스 성능 비교 차이를 했음을 알립니다.
또한, 'generate.py' 및 'test_index.py' 2개의 파이썬 파일로 진행함을 알립니다.
위 두 파일의 전체 코드는 제 github에서 확인해주세요!
https://github.com/pilmalion114/data_engineer_portfolio/tree/main/phase%201-2
2-2-1. python venv 가상환경 설정하기
이 부분은 환경설정 세팅하는 부분입니다.
아실 분은 다 아시겠지만,
'가상환경'이라고 함은, 운영체제 전역적으로 패키지를 설치하고 관리하는 것이 아닌(가상환경을 안 만들고 파이썬 패키지를 설치하면 운영체제 전역에 설치가 됩니다.) '나만의 공간'을 만들어서 여기서 독립적으로 패키지 설치 및 관리를 하는 것이라고 생각하면 되겠습니다.
이렇게 가상환경을 사용하는 이유는 대표적으로 '호환성 및 충돌'에 있는데요.
아무래도 파이썬이라 이와 호환하는 여러 패키지들은 각각 업데이트를 진행하는데 이 과정에서 기존에 있던 코드들을 빼고 더 업그레이드를 하거나 등의 이유로 업데이트 버전에 따라서 호환성이 안 맞을 때가 있습니다.
이를 전역적으로 설치해서 관리하다 보면, 일일이 매 프로젝트를 할 때마다 설정해야하고, 그러면 다른 프로젝트는 또 호환이 되지 않고... 등등 이런 골치아픈 경우들이 많이 나타납니다.
이를 위해서, 아주 간편한 도구인, '가상환경'을 사용하는 것입니다. 이 가상환경은 각 프로젝트마다 개개인적으로 독립적으로 사용하기에 맞춤형 호환 버전이라고 보시면 됩니다.
이렇게 간단하게 가상환경에 대한 개념을 설명드렸고,
이제 파이썬 기반으로 대표적인 pyvenv를 통해 가상환경을 설치하도록 하겠습니다.(pyvenv -> venv가 더 정확한 용어 설명이라고 하네요.)
(가상환경 관련 패키지 및 소프트웨어는 많습니다. 패키지로는 pyvenv외에 anaconda도 있습니다. anaconda로 설치하셔도 됩니다. 다만, 터미널이 bash(리눅스)기반에서 설치하셔야 합니다.(window/mac/linux 다 된다고 하네요. ㅎㅎ..;;;)
<python venv 설치 코드>
저는 Vscode(Visual Studio Code)에서 진행하는데요.
보통의 경우에는 폴더를 새로 생성해서,
그 폴더를 open하여 그 안에 코드 파일을 생성하는 것이 가장 좋습니다.
그럼 위의 과정을 거쳤다고 가정 하에,
python -m venv myvenv'myvenv'는 가상환경 이름입니다.
보통 이렇게 하지만, 이름이니 다른 걸로 바꿔도 됩니다.
그리고, 이 가상환경을 활성화(activate)하는 코드를 추가 작성하면 됩니다.
저는 'bash(linux 기반 터미널)'에서 진행하므로,
source myvenv/Scripts/activate이 명령어로 실행하면 활성화 완료입니다.
윈도우 용은,
myvenv/Scripts/activate입니다.
※cf.)
참고로, 위 'source~' 명령어에서,
myvenv에서 my(일부분만 타이핑하고) + 'tab'키를 누르면 자동완성이 되는데, 이렇게 활용하면 더 빠르고 간편하게 명령어 작성이 가능합니다.

그럼 위 사진과 같이 '(myvenv)' 이렇게 표시가 됩니다.
2-2-2. generate_data.py
이제 본격적으로 실습 코드로 들어가겠습니다.
그리고, 웬만하면 코드에 주석으로 설명이 잘 들어가있으니,
제가 설명하지 않은 코드 중에 모르는 부분이 있다면,
위 github에 들어가서 주석을 확인해주시기 바랍니다.
이 글에서는 로직 상 대표적인 부분들만 웬만하면 설명할 예정입니다.
2-2-2-1. 필요한 라이브러리 설치 및 DB 연결
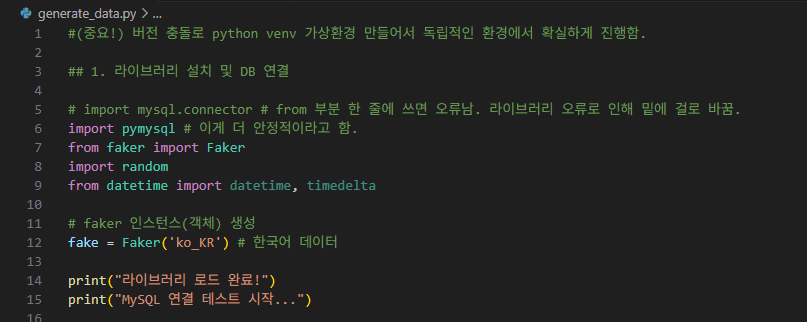

일단, 우리가 필요한 라이브러리는 다음과 같습니다.
1.pymysql -> python에서 실행할 수 있는 안정적인 sql
2.faker -> 가짜데이터(더미데이터)를 만들기 위해 필요한 라이브러리
3.datetime -> 날짜 관련 라이브러리
fake 변수에는 Faker() 인스턴스(객체) 생성을 하고, 한국어 데이터의 객체를 생성합니다.
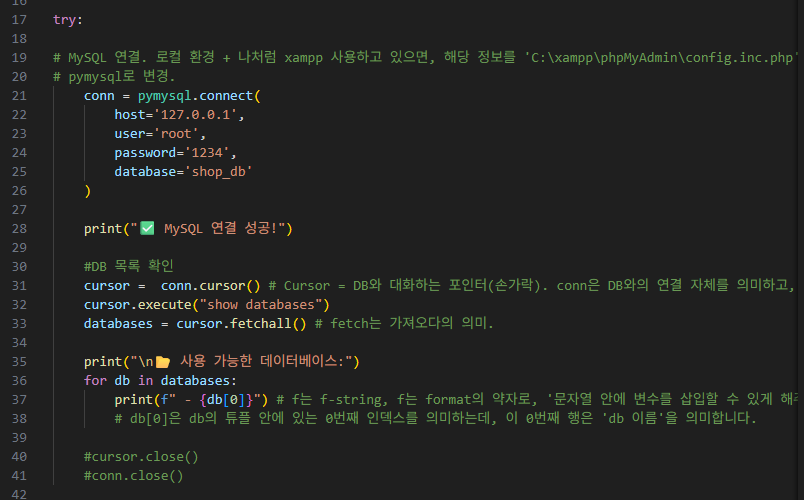
try, except문으로 오류 처리 구문을 구현했는데,
try문에는 DB 연결을 시도합니다.
conn이라는 변수에, connect할 DB 관련 정보를 넣고,
cursor를 이용하여 실제 SQL 실행 작업을 합니다.
※conn vs cursor
conn은 DB와의 연결 그 자체를 의미하고,
cursor는 실제 작업 수행(SQL 실행) 역할을 하는 주체입니다.
마우스 커서의 포인터(손가락)으로 이해하시면 됩니다.
cursor.execute() 부분에는 sql문을 넣어서 sql 질의문을 실행시켜주면 됩니다.
즉, 요약하자면,
DB 연결 부분인데, 연결을 하고 연결된 DB 정보들을 가져오는 부분입니다.

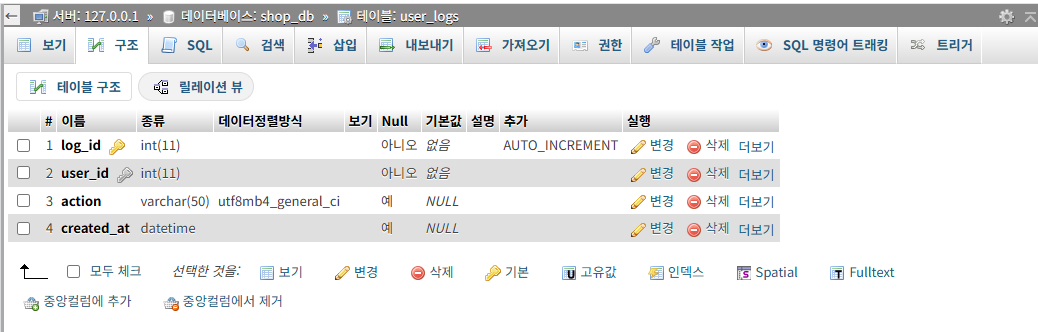
2-2-2-2. user_logs 테이블 만들기

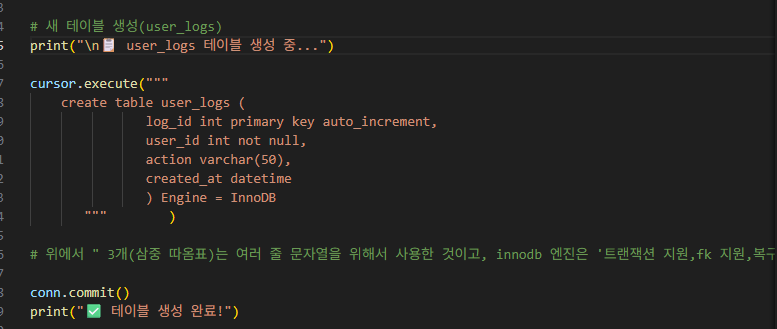
말 그대로 새로운 'user_logs' 테이블을 만드는 코드 부분입니다.
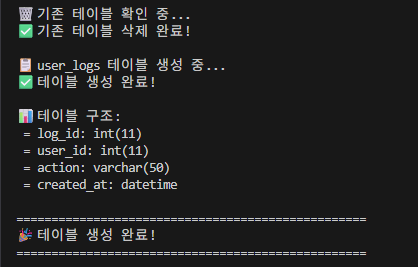
기존에 'user_logs' 테이블이 있으면 지워주는 코드로부터 시작합니다.
(이는, 추후 코드를 실행할 때 누적으로 데이터가 쌓이지 않고 초기화하여 시작함을 위함입니다.)
마찬가지로, cursor.execute()를 통해서 여러 줄 sql 질의문을 실행시킵니다. 이 여러 줄 코드가 'user_logs' 테이블을 만드는 코드입니다.
conn.commit()은 commit의 의미가,
우리가 깃허브를 하면, commit()을 통해 수정사항을 반영시키지 않습니까?
똑같은 의미입니다.
sql commit() 또한 위의 수정사항(테이블 만들기)을 반영하겠다라는 의미입니다.
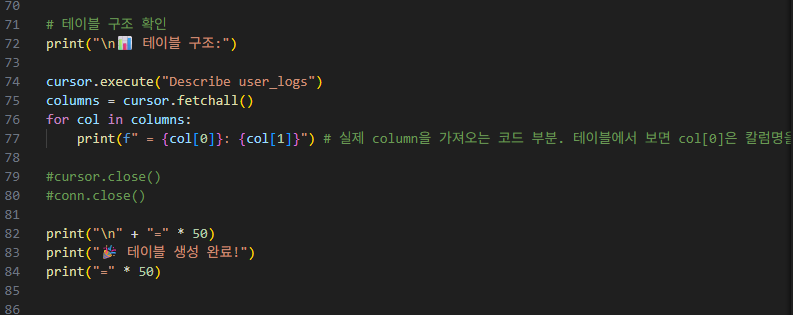
그리고 테이블 구조를 확인하기 위해.
cursor.fetchall()을 통해 fetch+all(모두 가져오기)
print문으로 나열해줍니다.
2-2-2-3. user_logs 테이블 안에 더미데이터 100만개 만들기
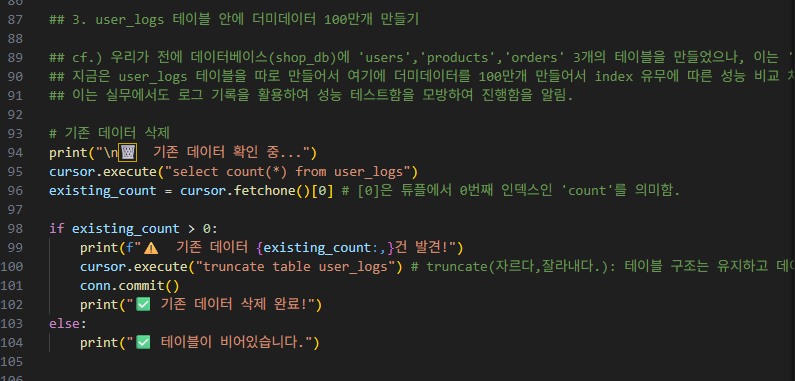
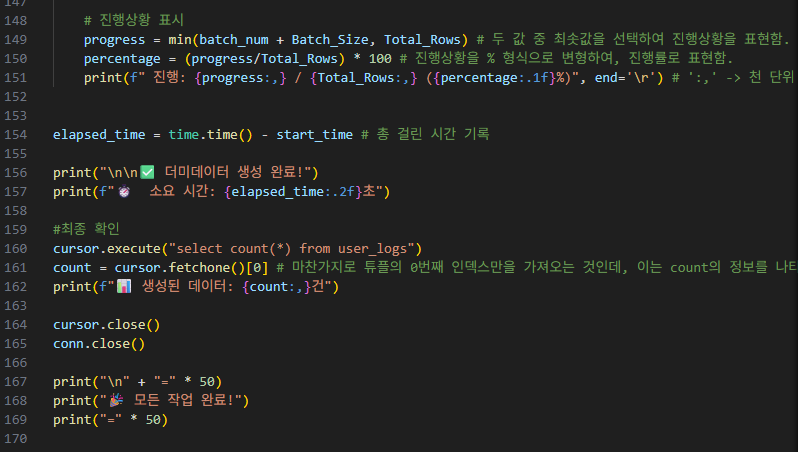
먼저 저는 테이블에 있는 데이터들을 truncate로 행은 유지하되 데이터만 전부 삭제하는 코드를 작성했는데, 작성하고 나고 보니 이미 앞에서 'drop table'을 실행하므로, 굳이 이 부분은 작성을 안 해도 됐음을 깨달았습니다.
(따라서 이 부분은 주석 처리해도 상관없습니다.)
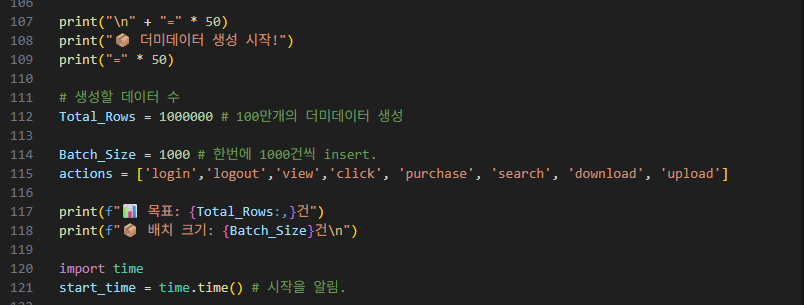
Total_Rows = 1000000,
Batch_Size = 1000(Batch란 해당 크기만큼 cut하여 이 cut한 단위로 연산을 하겠다는 의미이다. 주로 머신러닝 및 딥러닝에서 나오는 용어이다. 전 게시글에서 이동 평균(MA)때 설명한 윈도우와 같은 개념이라고 이해하면 편함(겉으로).)
actions = [~~], action과 관련한 리스트를 만들어줍니다.
start_time은 기록을 위한 첫 스타트 시간입니다.
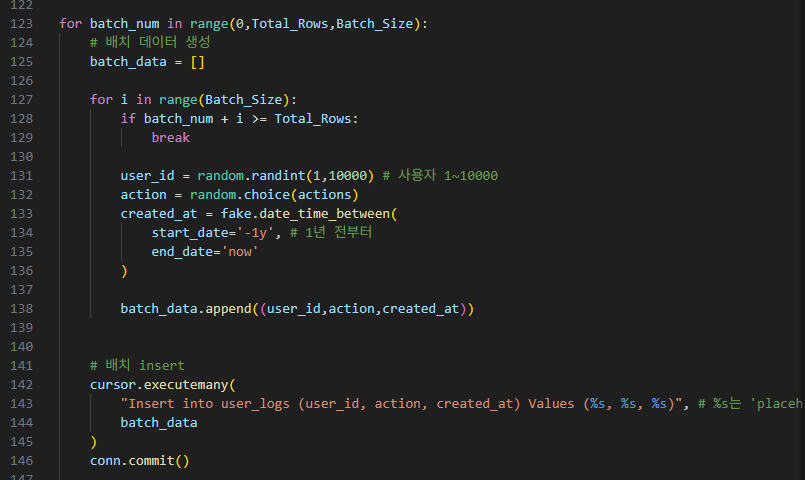
이중 for문을 통해,
안쪽 for문에는 배치사이즈 안에 있는 개별 데이터를,
바깥 for문은 배치사이즈로 반복문을 돌립니다.
안쪽 for문의 각 개별 데이터에는,
user_id(랜덤 int 번호(1~10000)), action(랜덤 액션 리스트. 액션 리스트 안에 있는 것을 랜덤으로 선택함.), created_at(여기서 fake 날짜 데이터를 사용)
이 3개 열에 대한 데이터 정보를 생성합니다.(한번에 1000개씩(배치사이즈), 1000개(배치사이즈) 단위로 수행.(여기서는 1000개씩 barch_date 리스트에 append(뒤에서부터 추가)를 합니다.)
그리고, 'cursor.executemany()'를 통해 배치를 sql 테이블에 insert합니다. executemany()는 말 그대로 execute()보다 많은 양의 데이터를 처리할 때 효과적이라고 합니다.
progress(진행 상황), percentage(진행 상황을 백분율로 표현)를 통해 수치로 나타냅니다.
elapsed_time은 총 걸린 시간을 표현한 것으로, 아까 시작 지점인 start_time과 마지막 지점인 time.time()의 차로 구합니다.
마지막은, print문으로 최종 확인합니다.

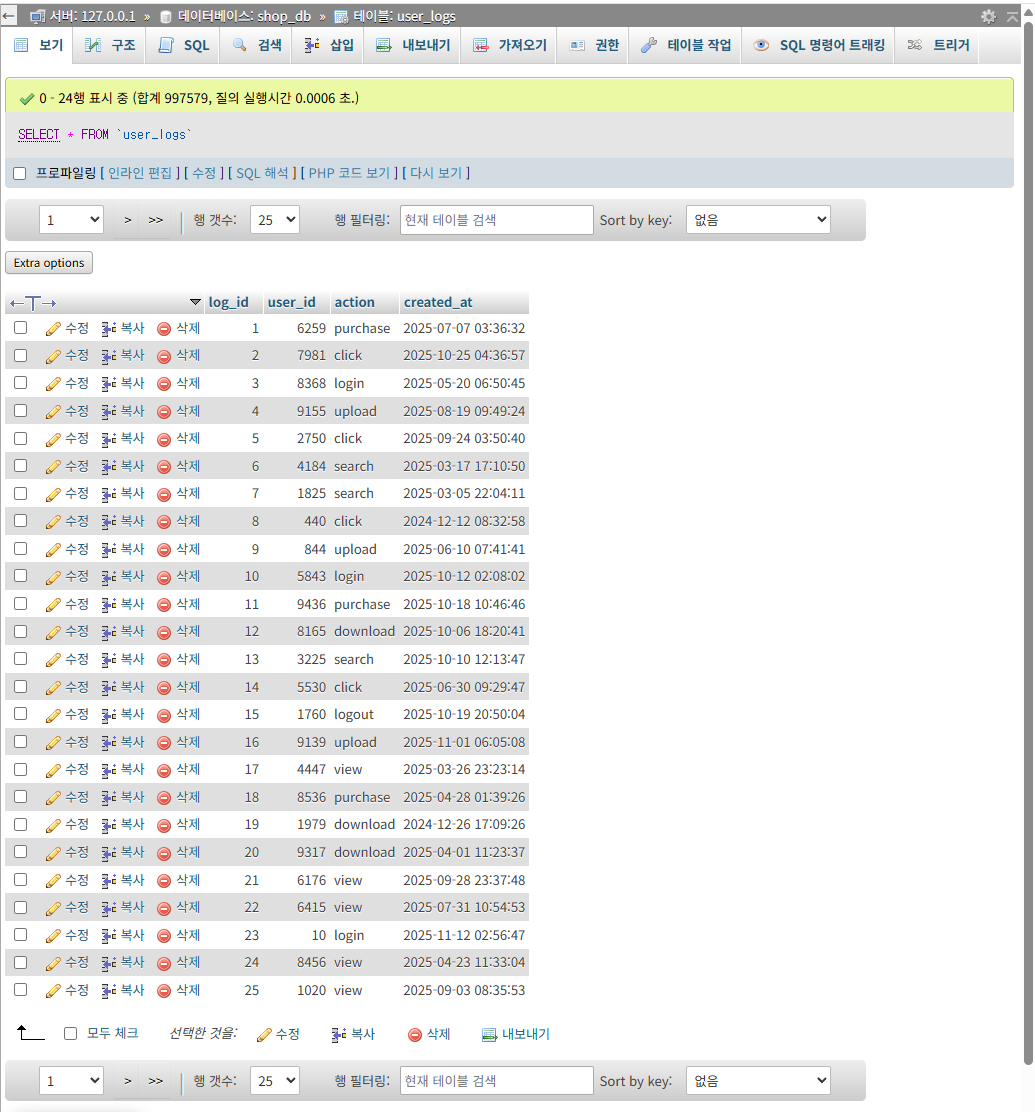
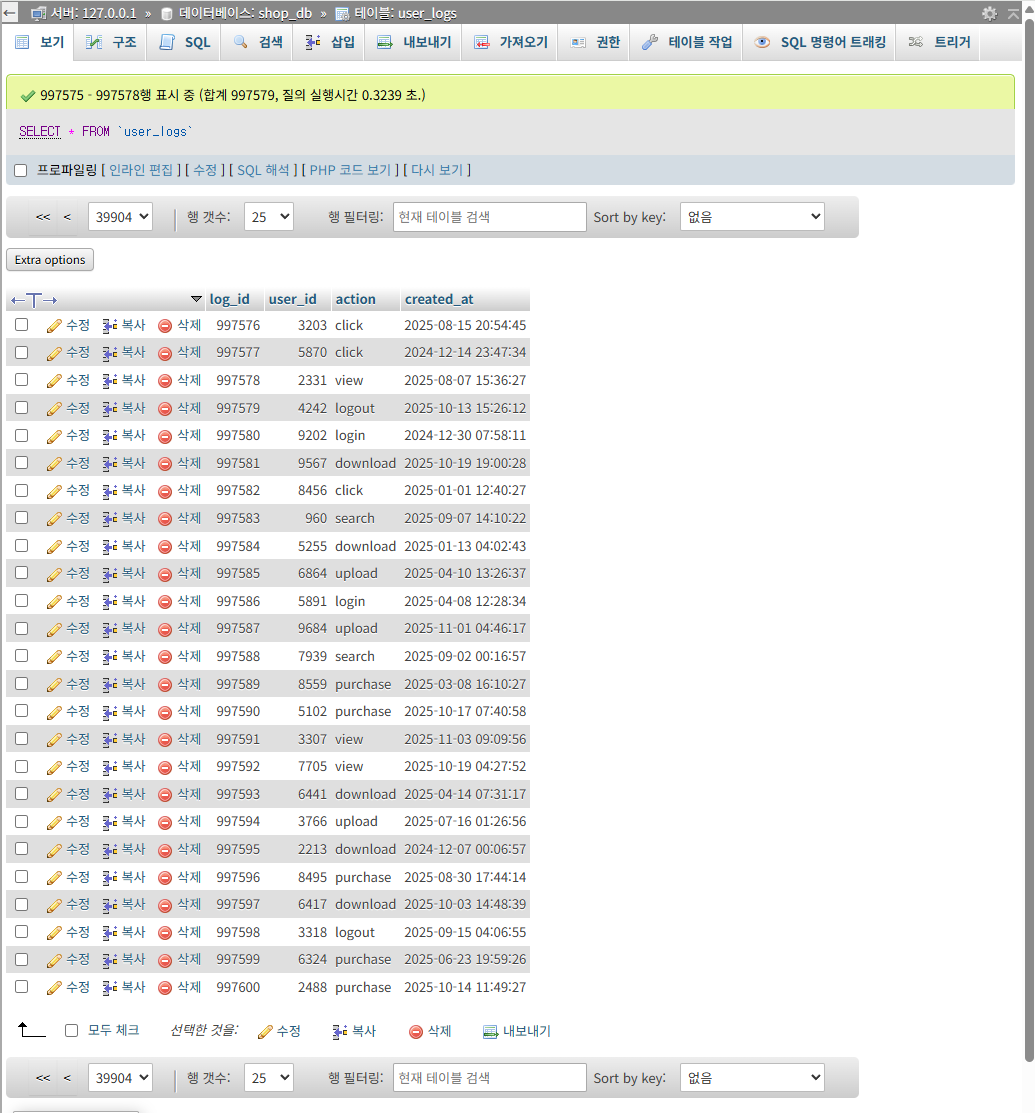
100만개를 넣기를 바랐는데,
997600개가 max인가봅니다.
큰 차이는 없으니 이 부분은 넘어가도록 하겠습니다.
2-2-3. test_index.py
또 다른 python 코드 파일입니다.
여기에서 'index 유무에 따른 성능 차이 비교'를 본격적으로 진행합니다.
앞 파이썬 파일은 세팅에 중점을 맞춘 파일이라고 생각하면 되겠습니다.
2-2-3-1. DB 연결

그냥 한번 더 가볍게 DB 연결을 해줍니다.
2-2-3-2. 테스트 쿼리 생성(3개) 및 인덱스 없는 상태(without index)에서 시간 측정하기
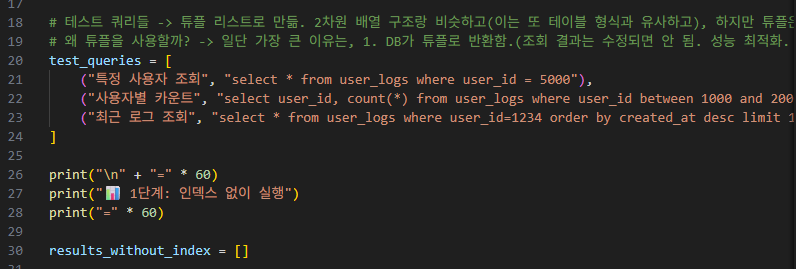
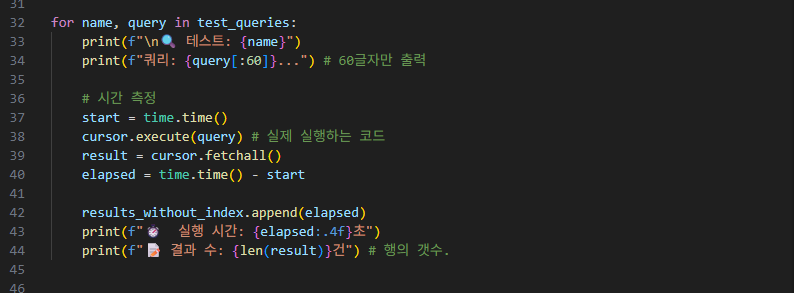
3개의 테스트 쿼리들을 생성합니다.
각각은,
'특정 사용자 조회', '사용자별 카운트(group by+ 집계)', '최근 로그 조회' 이렇게 3개로 만들었습니다.
그리고, 'results_without_index'라는 빈 리스트를 만들고,
for문을 통해 테스트 및 시간 측정을 진행합니다.
2-2-3-3. 인덱스 있는 상태(with index)에서 시간 측정하기
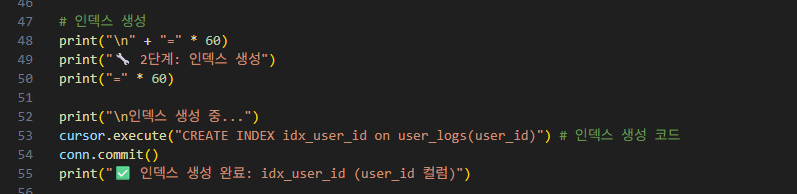
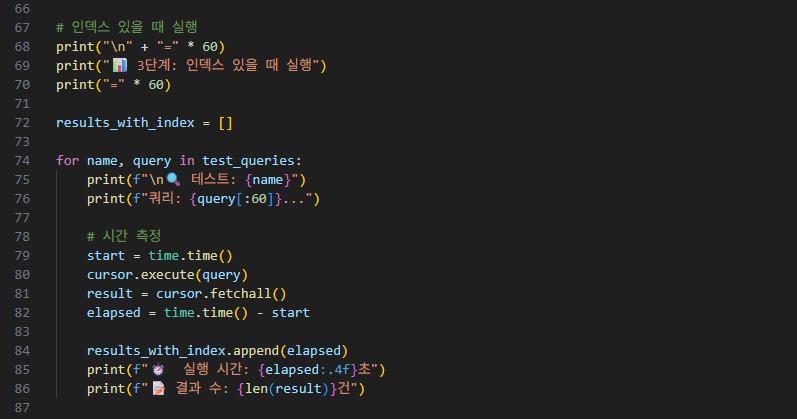
cursor.execute()로 인덱스 생성 sql문을 작성합니다.
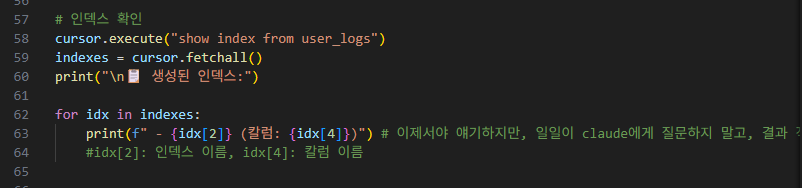
그 다음, cursor.execute() + print문으로 인덱스 생성된 것을 확인하고,
without_index 코드 때와 마찬가지로 for문을 통해 테스트 및 시간 측정을 합니다.
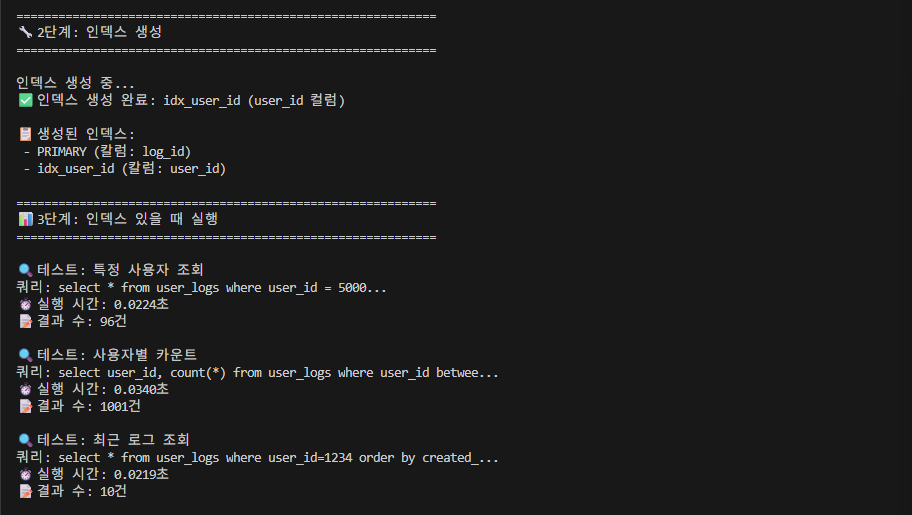
->여기서 생성된 인덱스를 살펴보면, 우리가 생성하고자 하는 'idx_user_id' 외에도 primary key가 인덱스로 생성됨을 알 수 있는데, 이 pk가 바로 '대리키+pk'이면 자동으로 인덱스를 생성하는 'Clustered Index'입니다.
즉, 우리는 'Non-Clusterd Index'와 'Clustered Index' 2개를 생성한 것입니다.
2-2-3-4. 성능 비교
'results_without_index' 와 'results_with_index' 두 리스트에는 시간 측정한 값이 append 되어있습니다.
3개의 쿼리를 for문으로 돌렸으니, 총 3개의 값이 들어가있죠.
이를 활용하여,
improvement = without/with_idx 수식을 통해,
몇 배 더 성능이 향상 되었는지를 수치로 표현합니다.
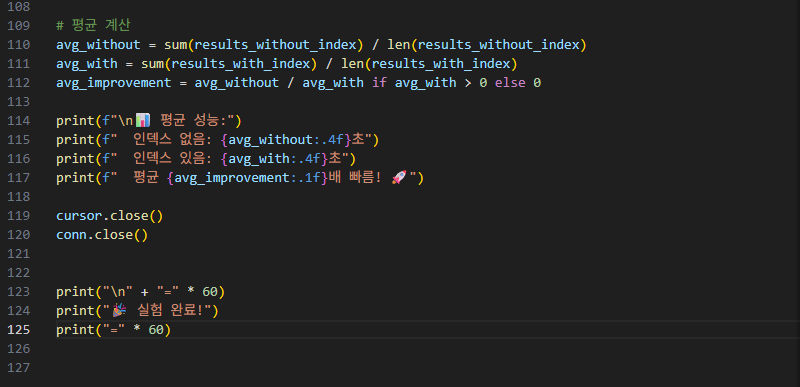
그 다음은, sum()과 len()을 활용하여, avg(평균)을 구합니다.
sum()은 말 그대로 총 합이고, len()은 갯수이니, 평균 공식과 부합합니다.
이렇게 해서 평균 성능도 보여줍니다.
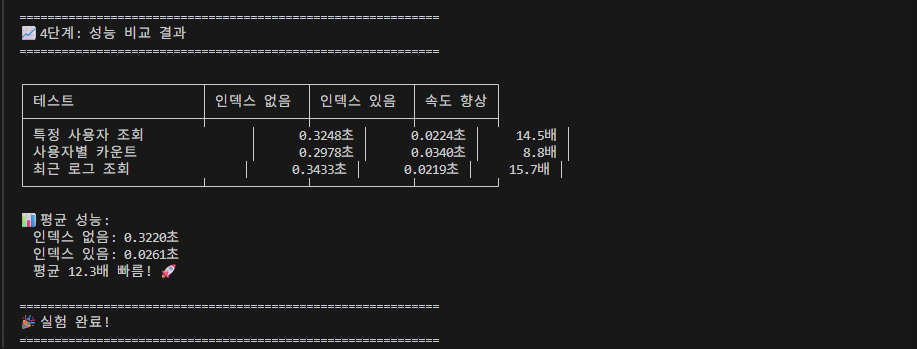
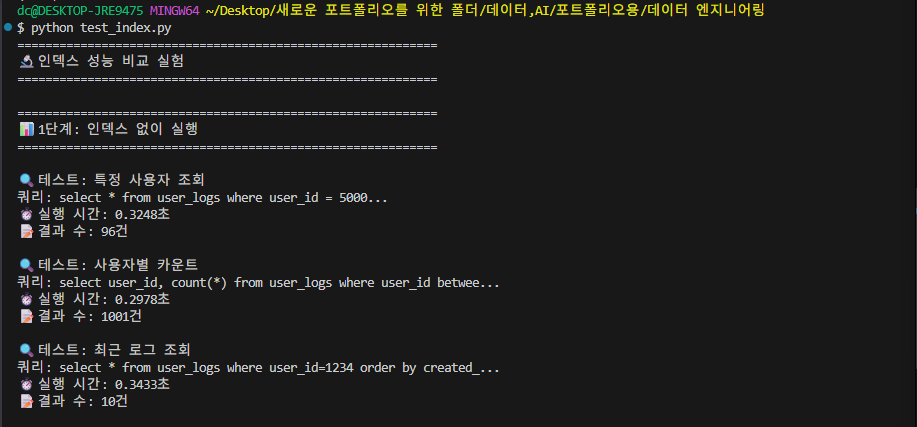
-> 위 결과 사진을 보면, 평균 12.3배 빠름을 알 수 있습니다.
(제가 이번 말고 저번에도 실행을 했었는데, 그 때도 약 10배 정도 빨랐었습니다.)
즉, 우리는 index를 사용해서 조회하는 것이 없을 때 조회하는 것보다 평균 10배 정도는 빠르다는 것을 눈으로 확인할 수 있었습니다.
3. 마무리 및 결론
이렇게 해서 우리는
- 인덱스 개념
2.실습
을 통해 '인덱스란 무엇인지?' 그리고 '인덱스 유뮤에 따른 성능 차이 비교'를 눈으로 확인해보았습니다.
코드가 복잡하지 않으면서,
시각적으로 한번에 성능 비교를 확인할 수 있는 점이 좋았던 거 같습니다.
이번에도 제 긴 글을 읽어주셔서 감사합니다! :) bb
다음에도 재밌는 컨텐츠로 돌아오도록 하겠습니다~~
