오늘은 leetcode window function 마지막 문제 풀이입니다.
마지막인만큼 hard 문제로 가져와봤고요.
hard인데 정답률이 50%나 돼서 좀 의심스럽지만...
나름 재밌게 푼 문제인 거 같습니다.
이번 게시글도 마찬가지로 문제 풀이 과정 및 제가 소개하고 싶은 개념들을 설명하고자 합니다.
1. 문제 소개

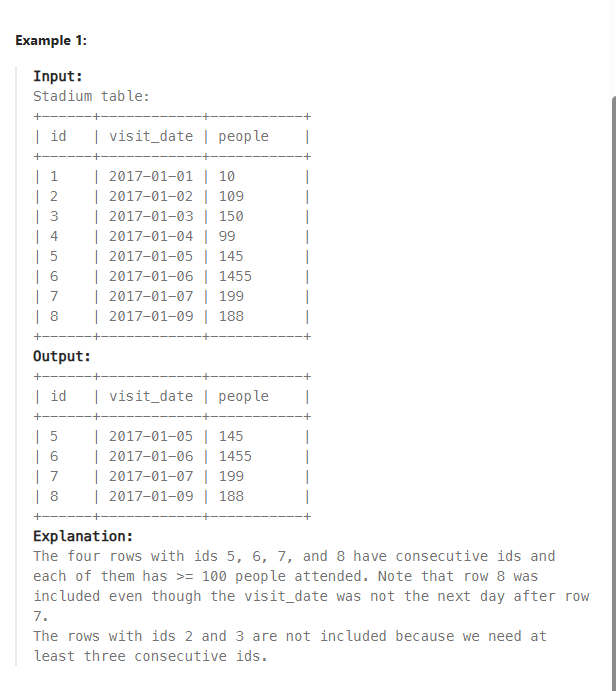
*테이블
STADIUM(ID,VISIT_DATE(PK),PEOPLE)
-> ID가 증가하면, VISIT_DATE도 증가하는 방식
*문제
Write a solution to display the records with three or more rows with consecutive id's, and the number of people is greater than or equal to 100 for each.
Return the result table ordered by visit_date in ascending order.
-> 방문자 수가 100명 이상이고 그 기록이 연속으로 3개 이상(3일 이상) 나오는 기록을 보여줘라.
-> VISIT_DATE를 ASC하게 정렬
2. 문제 풀이
제가 문제를 읽고 조금 곰곰이 생각해봤을 때, 중요하다고 생각한 건 이렇게 였습니다.
- 방문자 수 100명 이상
- 3일 연속 이상
->이게 제일 중요하고, 이거를 조건식으로 세워야 함.
sql문에서 3일 연속 이상을 어떻게 구현해야할까 생각하는데 뭐를 사용하면 좋을까 고민을 먼저 했습니다.
LAG(),LEAD(),이동 평균...
->LAG()로 이전 값 가져오는데, ROWS BETWEEN 2 PRECEDING AND CURRENT ROW(3개 연속.3일 연속)를 활용하여 이거 이상이게 조건식을 세우면..?
그렇게 해서 위의 말처럼 sql문을 한번 짜봤습니다.
LAG(PEOPLE) OVER(ORDER BY ID ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS CONSECUTIVE_ROW
WHERE PEOPLE >= 100※cf.) 근데 이게 문법에 맞다면,
- ORDER BY ID 뿐만 아니라 ORDER BY VISIT_DATE도 되고
- ORDER BY는 PARTITION BY와 함께 선택인데, 굳이 안 써도 될 듯..?
(이 부분에 대해서는 뒤에서 풀이과정으로 언급됩니다.)
SELECT
ID,
VISIT_DATE,
PEOPLE,
LAG(PEOPLE) OVER(ORDER BY ID ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS CONSECUTIVE_ROW
FROM STADIUM
WHERE PEOPLE >= 100SQL 실행 순서에 의해 코드 해석을 해보자면,
- FROM -> STADIUM 테이블을 가져온다.
- WHERE -> PEOPLE >= 100인 행만 추출한다.(개별 행 추출 문법)
- SELECT -> SELECT에 포함된 열을 추출한다. LAG의 경우는 추출이 아닌 새로 생성되는 열.
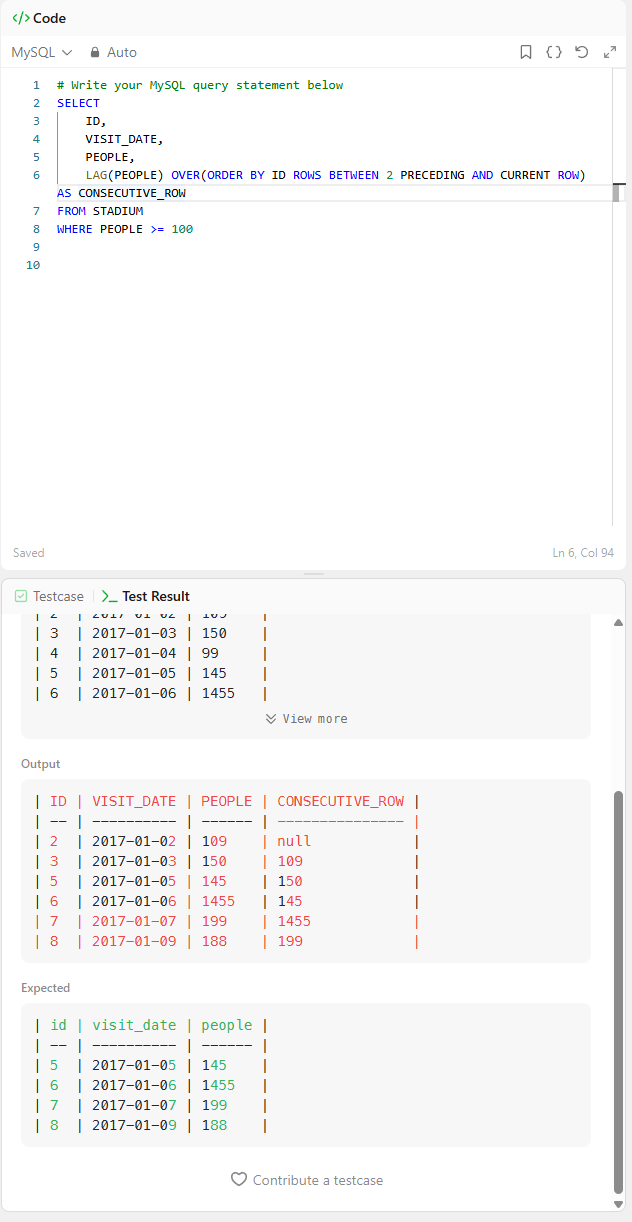
결과를 보면 알 수 있듯이,
'consecutive_row'에서는 이전 값인 lag(people)만을 참조하고 연속 3일의 값은 존재하지 않는다는 것을 발견할 수 있었습니다.
어떻게 보면 당연한 것이,
LAG()는 이전 값을 가져오는 함수이고, ROWS BETWEEN 2 PRECEDING AND CURRENT ROW는 3개 연속으로 가져오는 함수인데, 논리상 모순이 생깁니다.

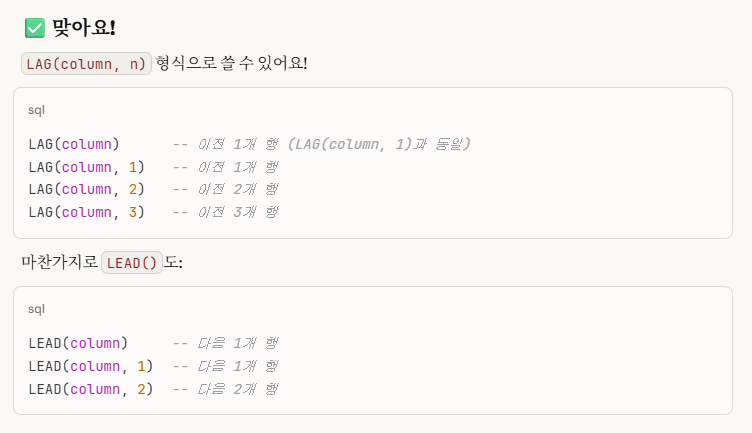
※개념_1. lag(), lead() 함수 추가 개념 설명
쉽게 요약하자면, lag와 lead는 바로 직전 값뿐만 아니라 그 이전들의 값들도 참조할 수 있다.
lead는 반대로 바로 직후 값뿐만 아니라 그 이후들의 값들도 참조할 수 있다.


방법을 고민하다가,
claude에게 여러분 질문을 하기도 했고,
그렇지만 뭔가 lag()와 lead()를 사용하여 '3일 이상'이라는 조건식을 만족시키기에는 다소 복잡하고 하드코딩적이라는 느낌을 받았습니다.
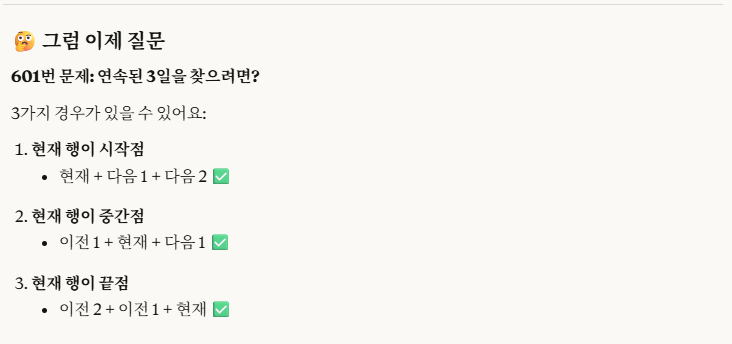


그렇게 claude와 대화를 이어가던 중에,
엄청난 힌트를 하나 제공받았습니다.
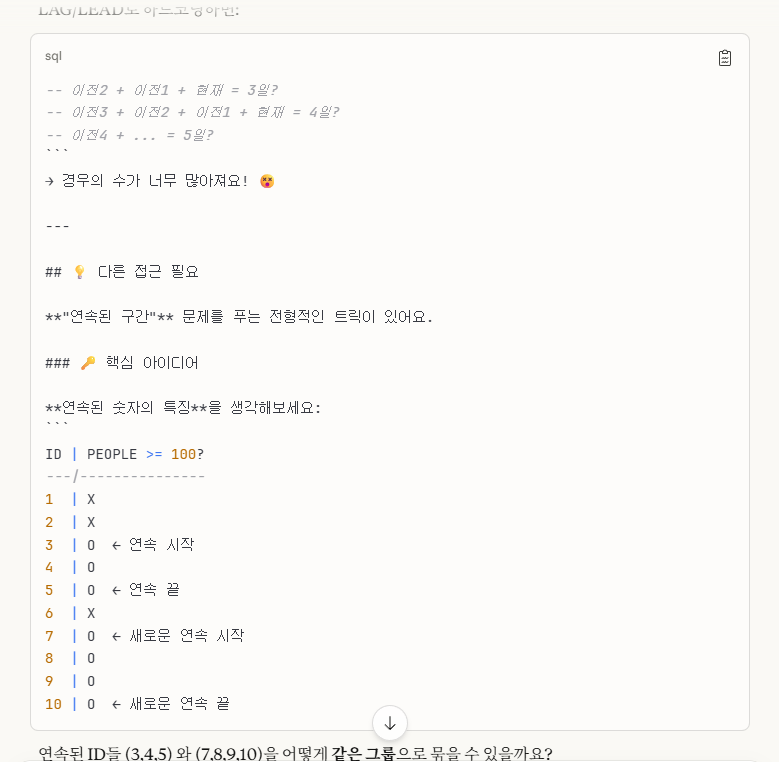
그렇습니다.
위 사진을 보면 알 수 있듯이, '수학적인 개념'을 활용하는 것인데요.
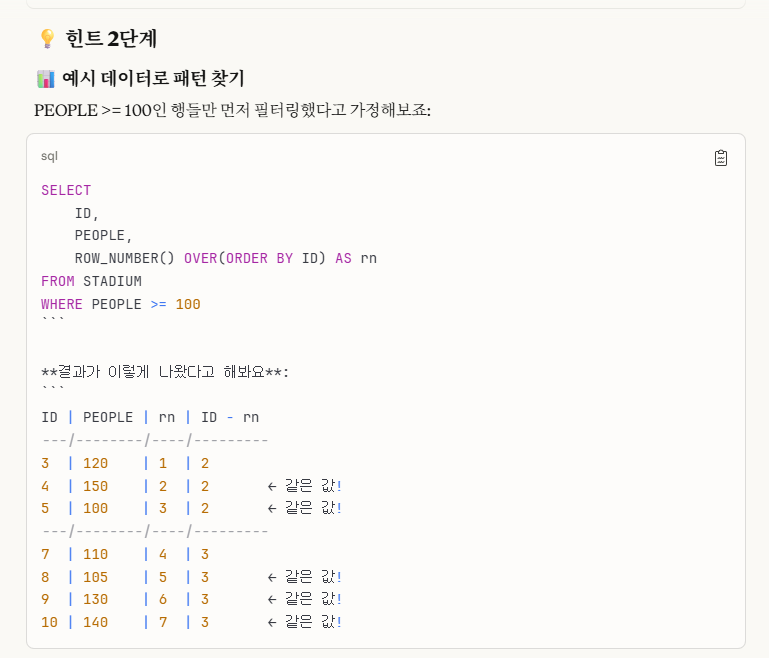
row_number()를 추가해서,
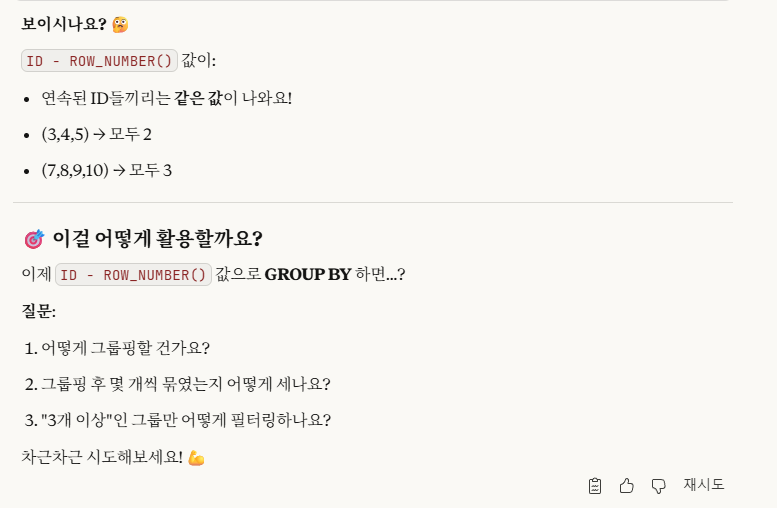
'row_number - ID' 값이 같은 수를 연속 3개 이상 찾으면 되는 것이었습니다.
이게 가능한 이유는,
문제에서 ID 값은 마치 인덱스 개념처럼 연속적으로 ascending하는 숫자이고, row_number()는 저희가 임의로 추가한 연속적으로 ascending 하는 숫자인데,
우리가 처음에 where절로 people >= 100 이상인 개별 행들만 추출했고, 거기에 포함된 ID값과 row_number()의 차를 통해 연속적인 갯수를 구할 수 있는 수학적 개념이 완성되는 것입니다.
설명보다는 직접 실행해서 직관적으로 보면 이해가 바로 되실 겁니다.
이런 수학적인 개념은 코딩의 조건식에 넣을 때 매우 유용하므로, 다른 코딩 부분에서도 이런 수학적 개념 로직을 탑재하는 것이 중요합니다!
(코딩 또한 수학에서 심화된 분야이다보니깐요.)
SELECT
ID,
VISIT_DATE,
PEOPLE,
ROW_NUMBER() OVER(ORDER BY ID) AS RN,
ID - ROW_NUMBER() OVER(ORDER BY ID) AS 'ID-RN'
FROM STADIUM
WHERE PEOPLE >= 100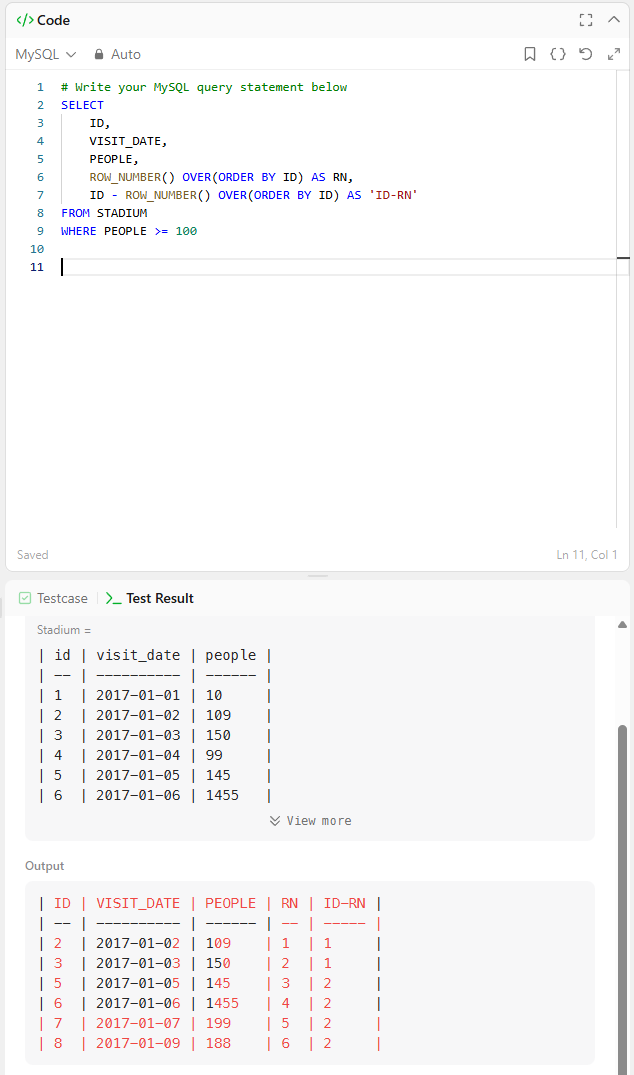
그럼 이제 여기서,
'ID-RN'이 같은 것이 3개 이상이게 하는 조건식을 어떻게 만들 수 있을까요?
바로 '그룹화' 개념을 사용하는 것입니다.
2가지의 방법이 있는데,
1.group by
2.partition by
가 있습니다.
먼저, 'partition by'부터 진행해보도록 하겠습니다.
일단 partition by는 group by와 다르게 모든 행을 하나로 합치지 않고, 개별 행으로 유지하는 특징이 있죠.
이를 이용해서 group by보다 간편하게 코드가 나올 거 같아서 구현해보았습니다.
저는 맨 처음에는 이렇게 진행했습니다.
SELECT
id,
visit_date,
people
FROM(
SELECT
ID,
VISIT_DATE,
PEOPLE,
ROW_NUMBER() OVER(ORDER BY ID) AS RN,
ID - ROW_NUMBER() OVER(ORDER BY ID) AS 'ID-RN',
COUNT(*) OVER(PARTITION BY ID - ROW_NUMBER() OVER(ORDER BY ID)) AS CNT
FROM STADIUM
WHERE PEOPLE >= 100) AS T_1
WHERE CNT >= 3그런데, 처음 보는 오류가 뜨더군요.
해석을 해보니 윈도우 함수가 다른 윈도우 함수를 감쌌다는 오류인 거 같았습니다.
그래서, 서브쿼리 부분을 따로 돌렸더니,
똑같은 오류가 나오더군요.
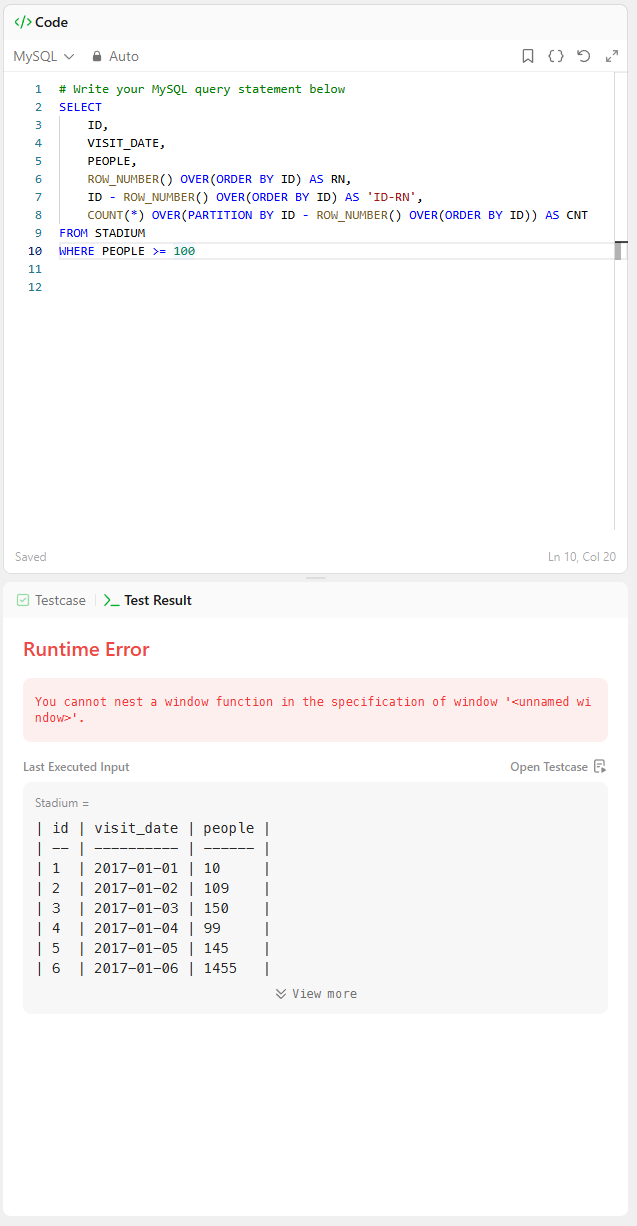
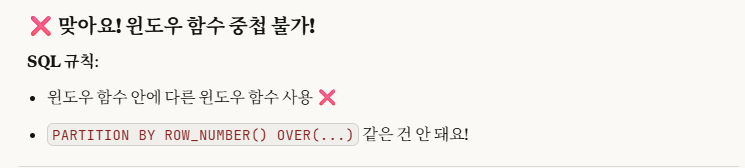
그래서 어쩔 수 없이,
윈도우 함수들을 각각 분리시켜서 진행해야하므로,
2번의 서브쿼리를 활용해서 구현을 해보았습니다.
<partition by 최종 코드>
SELECT
ID,
VISIT_DATE,
PEOPLE
FROM (
SELECT
ID,
VISIT_DATE,
PEOPLE,
COUNT(*) OVER(PARTITION BY grp) AS cnt
FROM (
SELECT
ID,
VISIT_DATE,
PEOPLE,
ID - ROW_NUMBER() OVER(ORDER BY ID) AS grp
FROM STADIUM
WHERE PEOPLE >= 100
) sub1
) sub2
WHERE cnt >= 3
order by visit_date asc -- 이거 빼먹어서 처음에 오답 나옴.코드를 보면 익숙한 형태인데,
제일 안쪽 서브쿼리는 people >= 100인 조건과 'id-row_number' 부분을 먼저 처리하였고,
그 다음 서브쿼리에서는 안쪽 서브쿼리의 열들을 가져오고,
여기에 'count(*) + partition by'를 통해 각 개별 행들은 합치지 않고 유지를 하면서 조건을 만족하는 행의 갯수를 count하였습니다.
그 다음 마지막 메인 select문에서는 조건을 만족하는 행의 갯수(cnt)가 3 이상인 것들을 만족하는 id,visit_date,people 열을 추출하면서 마무리가 됩니다.
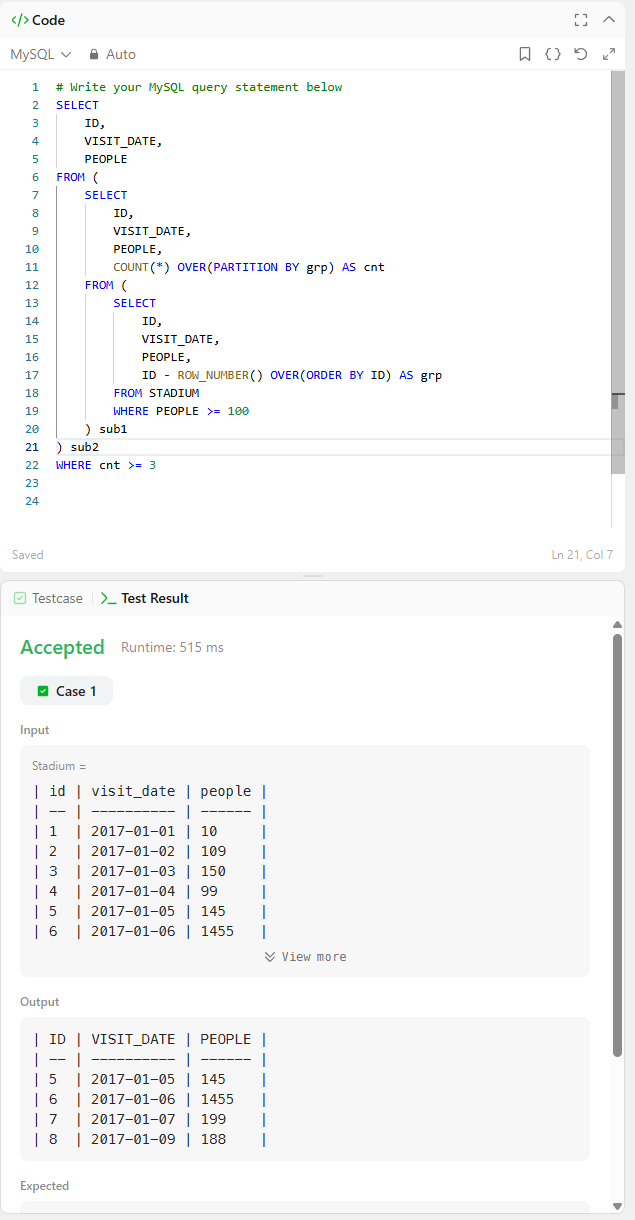
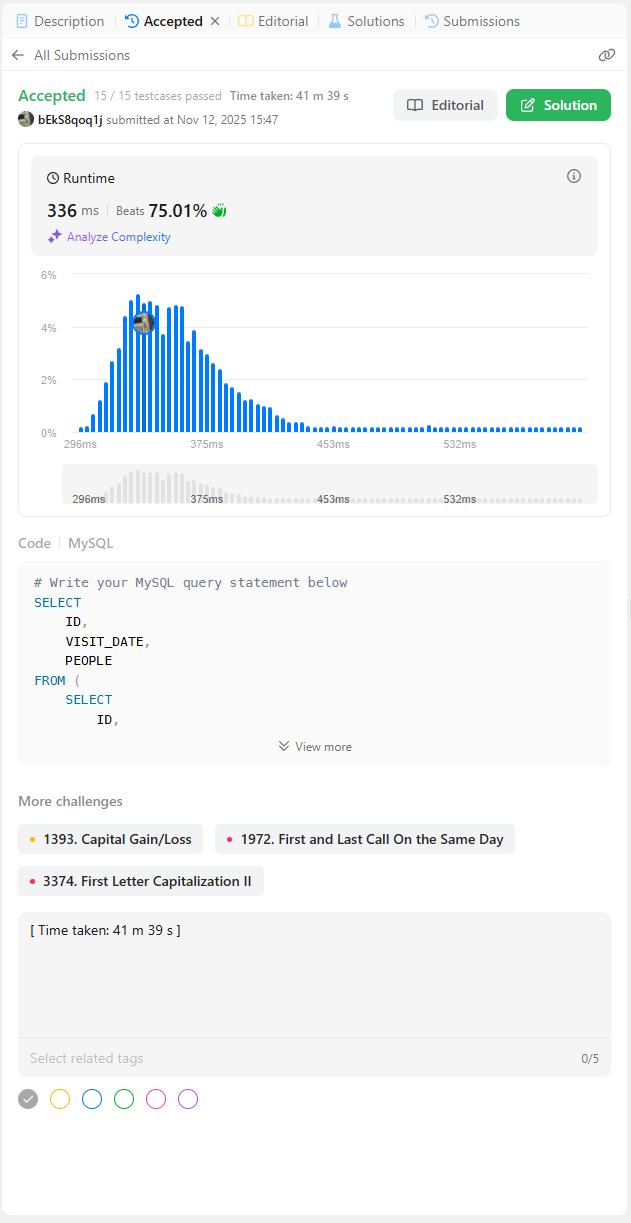
그 다음은, 'group by'로 구현을 해보았습니다.
<group by 최종 코드>
with grouped as (
select
id,
visit_date,
people,
id - row_number() over(order by id) as grp
from stadium
where people >= 100
)
select
id,
visit_date,
people
from grouped
where grp in (
select grp
from grouped
group by grp
having count(*) >= 3
)
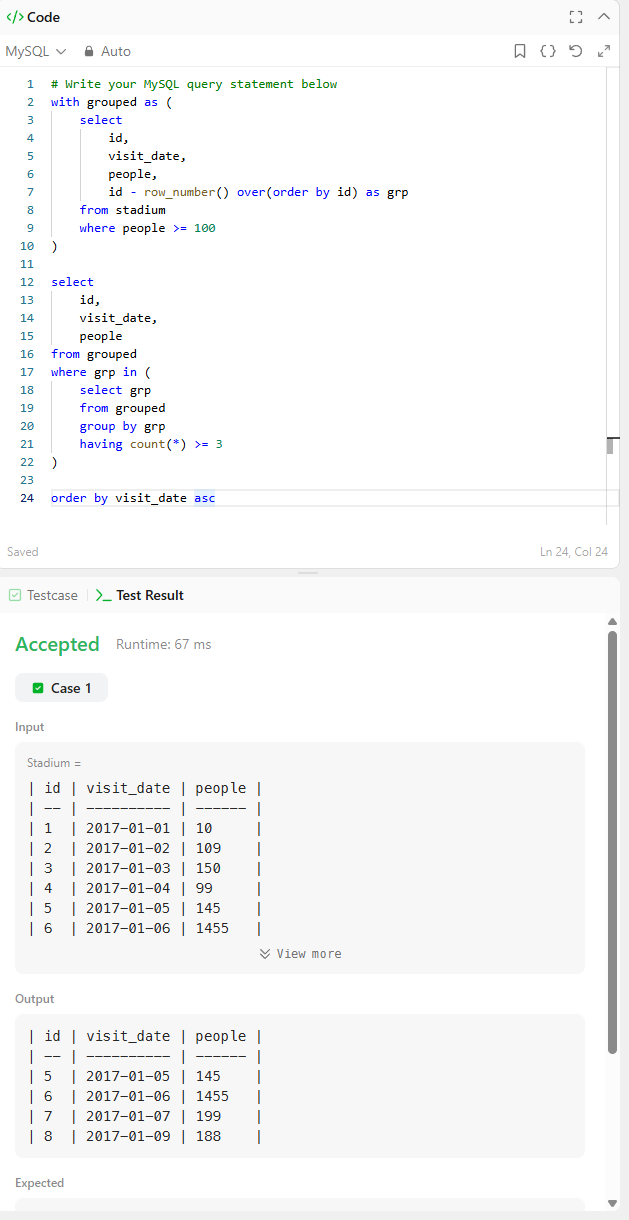
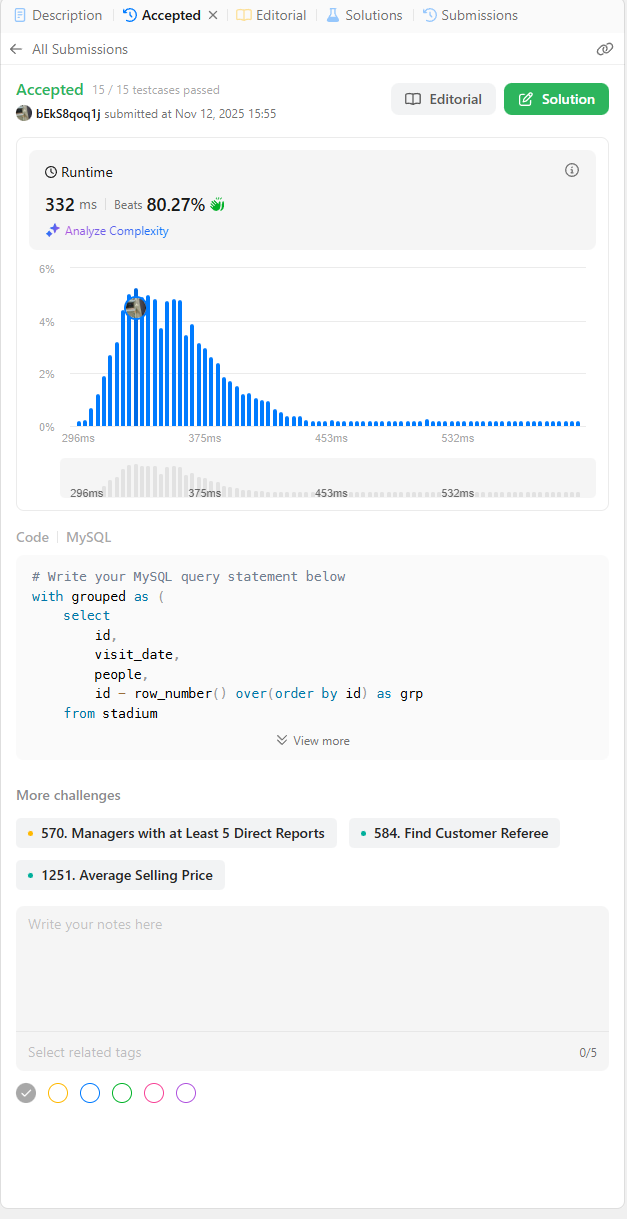
order by visit_date asc'grouped'라는 임시 테이블을 만들고,
이 임시테이블을 활용하는 방법입니다.
메인 select문에서의 where 조건식 절을 보면,
in을 활용하여 값들이 '값 목록' 안에 있음을 판단합니다.
그 값 목록을 추출하는 조건은 'group by + having 집계 조건절'을 활용하여, grp가 3개 이상인 애들인 grp 값을 추출하는데, 거기에 있는 grp만을 where절로 가져옵니다.
그럼 이제 마지막 궁금증입니다.
앞에서 언급을 미리 했었는데요.
Q.
'partition by', 'group by'에서 둘 다 id-row_number() over()에서 order by를 썼는데,
이를 생략해도 같은 값인가?
테스트를 진행해보았습니다.
진행하기에 앞서 제가 미리 예상을 했었는데요.
저는 결과가 같다고 봤습니다.
그 이유는,
over절 안에 있는 order by,partition by는 필수가 아닌 선택이고,
어차피 id도 인덱스 번호대로 순서대로, row_number()도 연속 숫자 순서대로일테니, 굳이 order by를 안 넣어도 자동정렬된다고 봤기 때문입니다.
->문제에서도 'As the id increases, the date increases as well.' 정렬 보장을 해줌.
먼저 'group by'입니다.
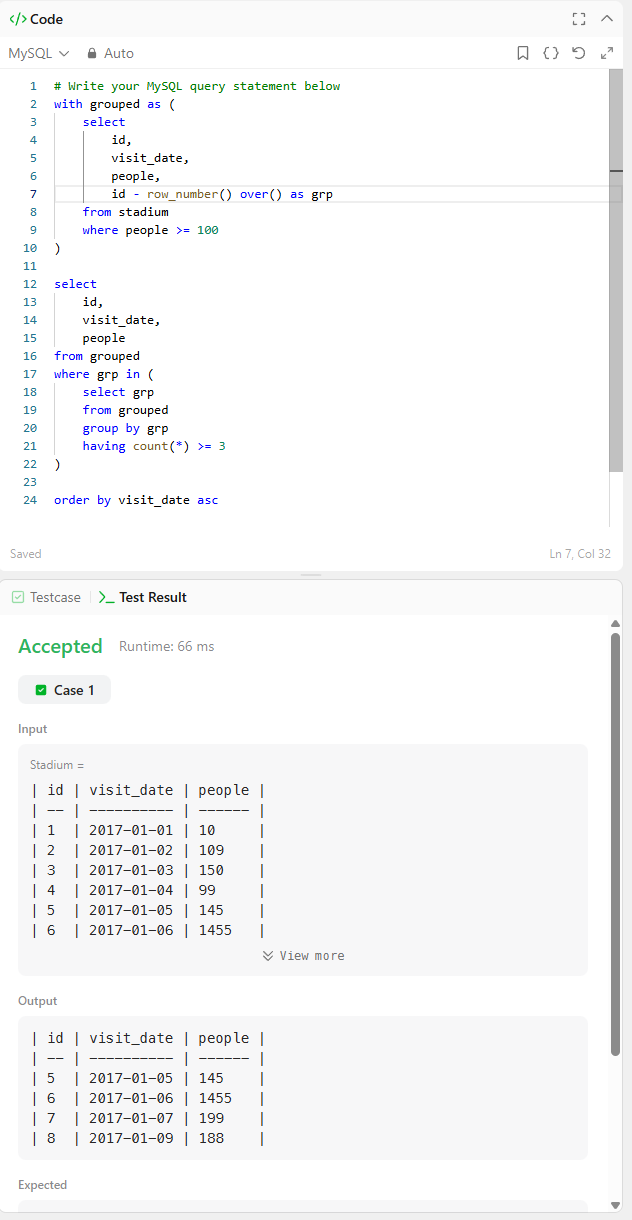
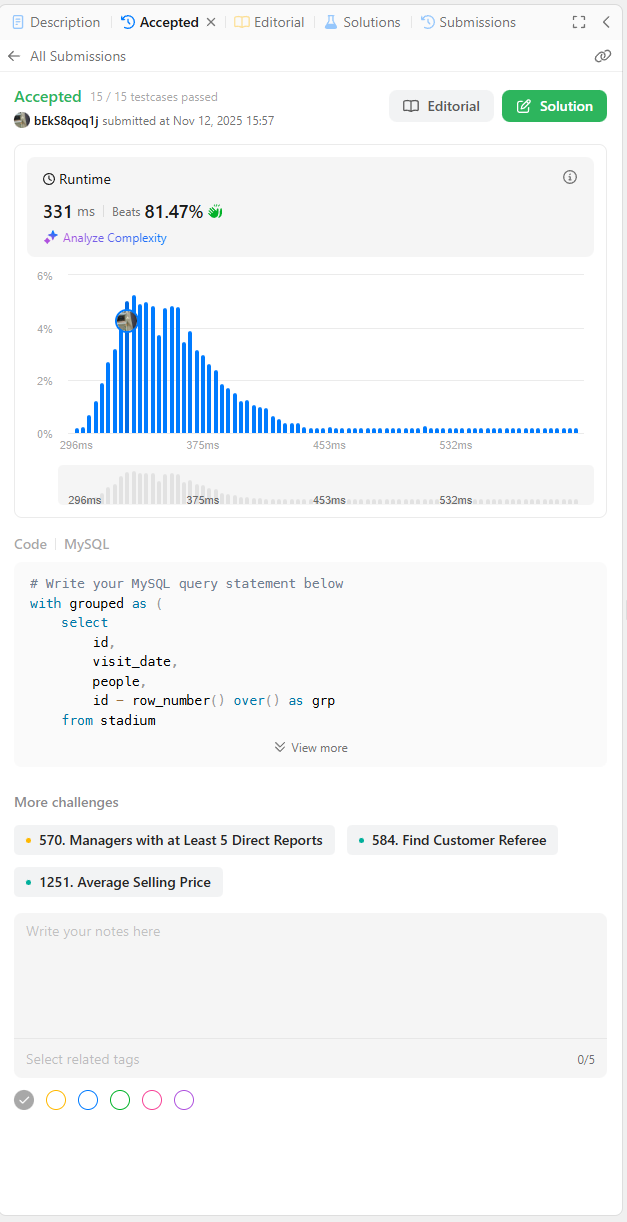
통과됨을 볼 수 있습니다.
그 다음은 'partition by'입니다.
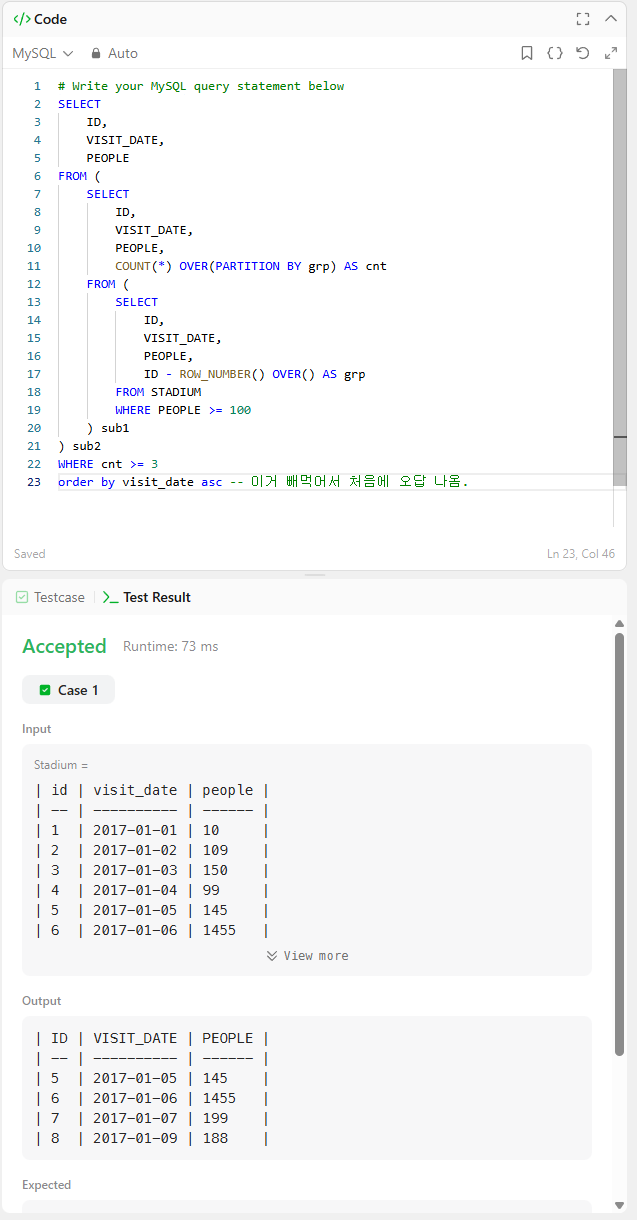
이 역시 통과됨을 볼 수 있습니다.
3. 마무리
이렇게 해서 leetcode window function의 마지막 문제인 hard 난이도 문제를 1개 풀어보았습니다.
뭔가 코드적으로 복잡하고 어렵다기 보다는,
'수학적인 개념 로직'을 탑재해야 풀린다는 점에서 재밌었던 문제였던 거 같습니다.
이런 수학적인 개념 로직은 실무에서도 많이 쓰인다고 하니,
숙지를 잘 해야겠네요 ㅎㅎ
오늘도 제 긴 글을 읽어주셔서 감사합니다 :) bb
다음에는 문제 풀이 외에 다른 데이터 엔지니어링 실무 코스로 돌아오도록 하겠습니다~~
