
Properties of Normal Distribution
-
-
CDF
-
-
-
- (odd fn)
- "3rd moment"
-
(symmetry)
-
Let , (mean, location), (SD, scale)
-
Then we say
-
-
-
; if and only if for some
-
-
-
-
in general, not linear
[equal if , are indep.] -
-
-
Standardization(표준화) :
-
Simple and Useful transformation!
-
단위를 제거할 수 있으므로 무차원 변환하여 해석 가능
-
-
-
Find PDF of
-
CDF :
-
Derivative of CDF : PDF!
- 합성함수 미분 :
-
- Later we'll show : if indep.
-
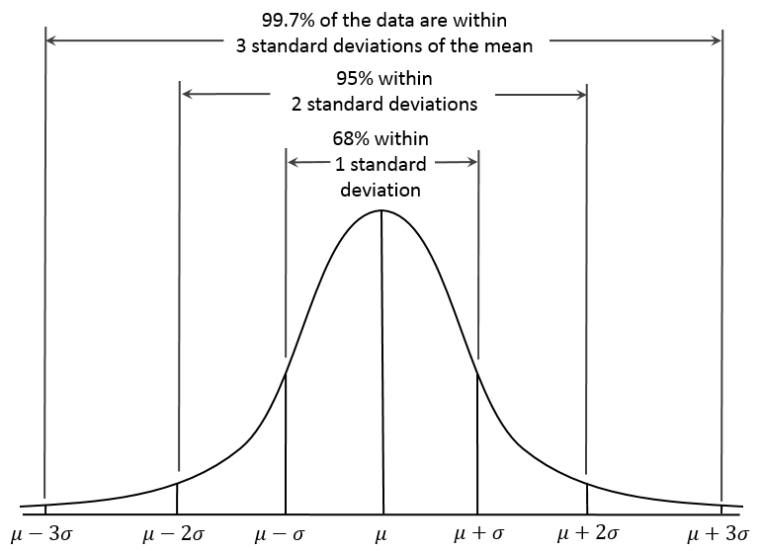
68-95-99.7% Rule,
Calculations of Poission Distribution
| Prob. | ... | ||||
|---|---|---|---|---|---|
| ... | |||||
| ... |
-
-
-
-
-
-
-
(Derivative)
-
-
(Derivative again)
-
-
-
- 평균과 분산이 같다!
-
Find ,
-
,
-
-
[indicator of succession both trials 1, 2]
,
-
Prove LOTUS for discrete sample space
-
Show
-
[grouped] [ungrouped] (Pebble World)
-
[Definitely]
[Sum of the pebbles mass]
-
- 출처 : Statistics 110, boostcourse

물리학 전공자의 프로그래밍 도전기