Image Classification : A core task in Computer Vision
The Problem : Semantic Gap
Challenges
-
Viewpoint variation
- 보는 시각에 따라 다르게 보일 수 있음
-
Illumination
- 명암에 따라 다르게 보일 수 있음
-
Deformation
- 자세에 따라 다르게 보일 수 있음
-
Occulusion
- 고양이 꼬리만 보고도 사람은 라벨링 할 수 있지만 컴퓨터가 할 수 있는 방법은?
-
Intraclass variation
- shape, color ...
An image classifier
def classify_image(image):
...
return label s-
Attemps have been made
- edge를 기준으로 corner하게
-
Data-Driven Approach
- 매우 많은 데이터셋 필요
-
데이터와 라벨을 기억
def train(images, labels):
...
return model- 트레이닝 이미지와 매우 비슷한 테스트 이미지로 라벨 추론
def predict(model):
...
return test_labelsExample Dataset : CIFAR10
- 10 classes
- 50,000 training images
- 10,000 testing images
Distance Metric to compare images
- L1 (Manhattan) distance :
- 가끔은 stupid, 가끔은 크게 도움 됨
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
def train(self, X, y):
self.Xtr = X
self.ytr = y
def predict(self, X):
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
for i in range(num_test):
distances = np.sum(np.abs(self.Xtr - X[i, :]), axis = 1)
min_index = np.argmax(distances)
Ypred[i] = self.ytr[min_index]
return Ypred- train : O(1)
- predict : O(N)
- quite slow
K-Nearest Neighbors
- K개씩 투표 진행
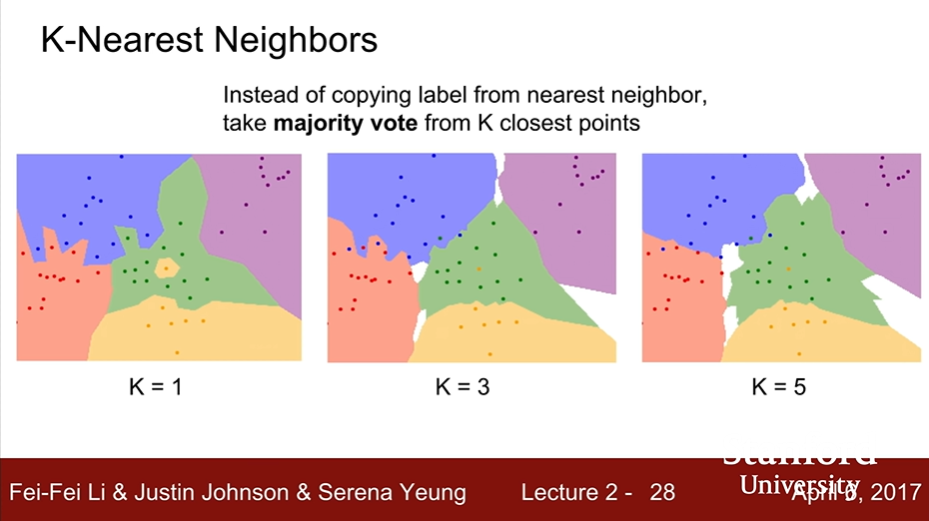
- L2 (Euclidean) distance :
- L1은 좌표계에 따라 point가 달라진다.
- L2는 동일하다.

-
만약 벡터가 어떤 식으로 생겨 먹었는지 모를 경우엔 좌표계에 따라 달라지는 L1보단 L2를 사용하는 게 좋을 것이다.
-
K-Nearest Neighbors : Decision Metric
- L2에 비해 L1의 decision boundary가 좌표계와 평행한 것을 알 수 있다.
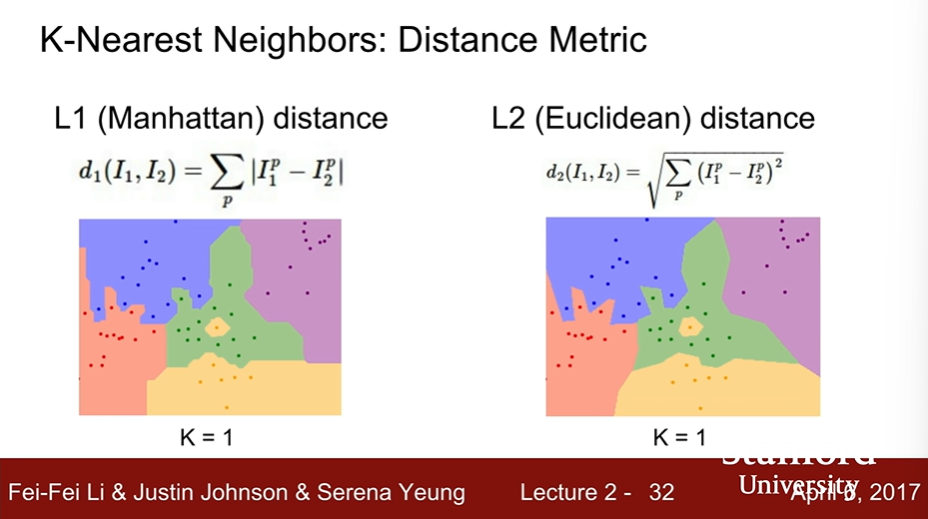
- L1이 좀 더 좌표 의존성이 있으므로 feature의 개별 요소가 어떠한 의미를 가질 때 L1을 사용하는 것이 좋을 수 있다.
- ex. 월급이나 일한 햇수와 같은 features로 직원들을 구분할 때
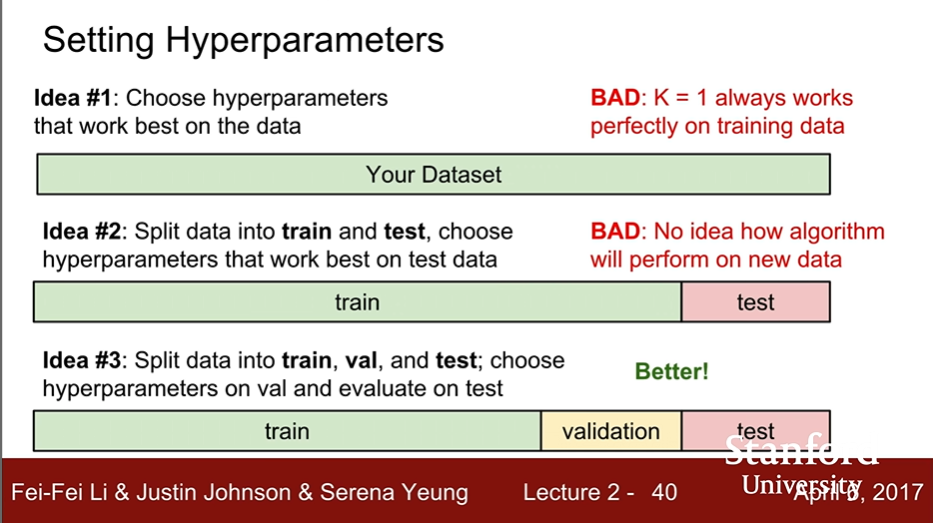
Hyperparameters
- The best way of Setting : Split data into train and val, and test; choose hyperparameters of val and evaluate on test!
- Cross-Validataion : Split data into folds, try each fold as validation and average the results.
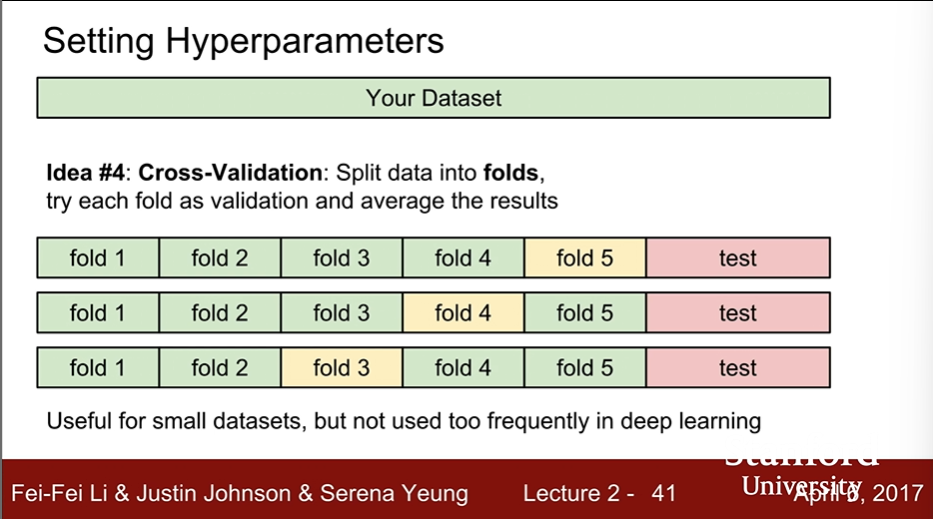
- But k-Nearest Neighbor on images never used.
- Very slow at test time
- Distance metrics(L1, L2) on pixels are not informative
- Curse of dimensionality

Linear Classification
- KNN has no parameter, but the linear Classification has.
- Example with an image

-
feature를 나타내는 가중치 행과 이미지 픽셀을 나타내는 열을 inner product하여 각 클래스에 대한 유사성을 판단한다.
-
선형 결정 경계를 그린다.
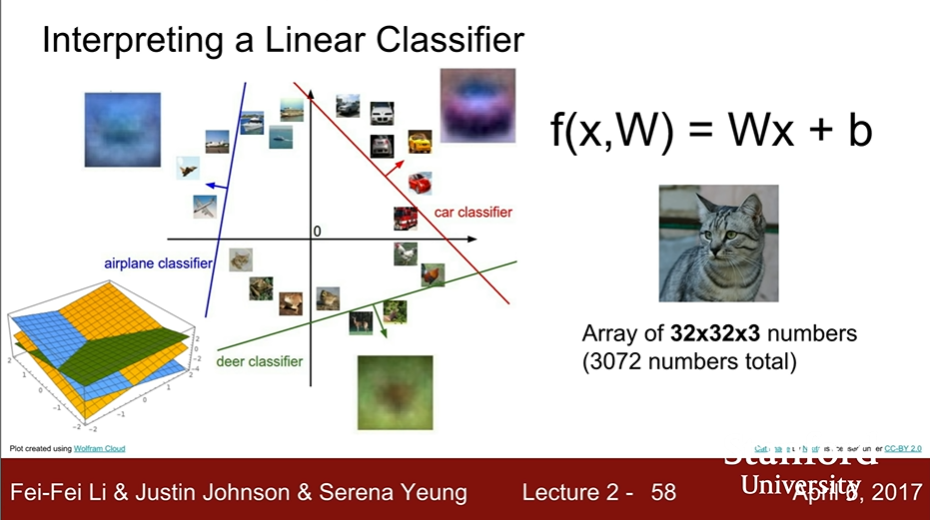
- Linear Classification이 갖는 한계
- ex. Parity problem

[출처] CS 231n | Stanford University school of Engineering

물리학 전공자의 프로그래밍 도전기