[RL] Sample-based Learning Methods Week 3
Temporal Difference Learning Methods for Control
TD for Control
Sarsa: GPI with TD
- Generalized Policy Iteration을 TD로 improve하는 방법에 대해 알아보자.
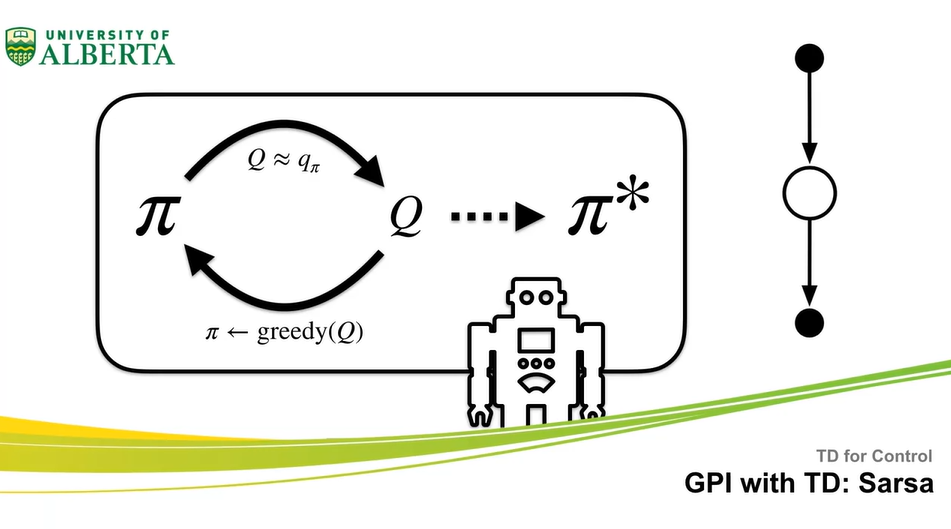
- 이번 강의에서는 GPI used with TD와 Sarsa control 알고리즘에 대해 다룬다.

- Policy Iteration은 Policy Evaluation과 Policy Improvement의 연속으로 전개되었다.

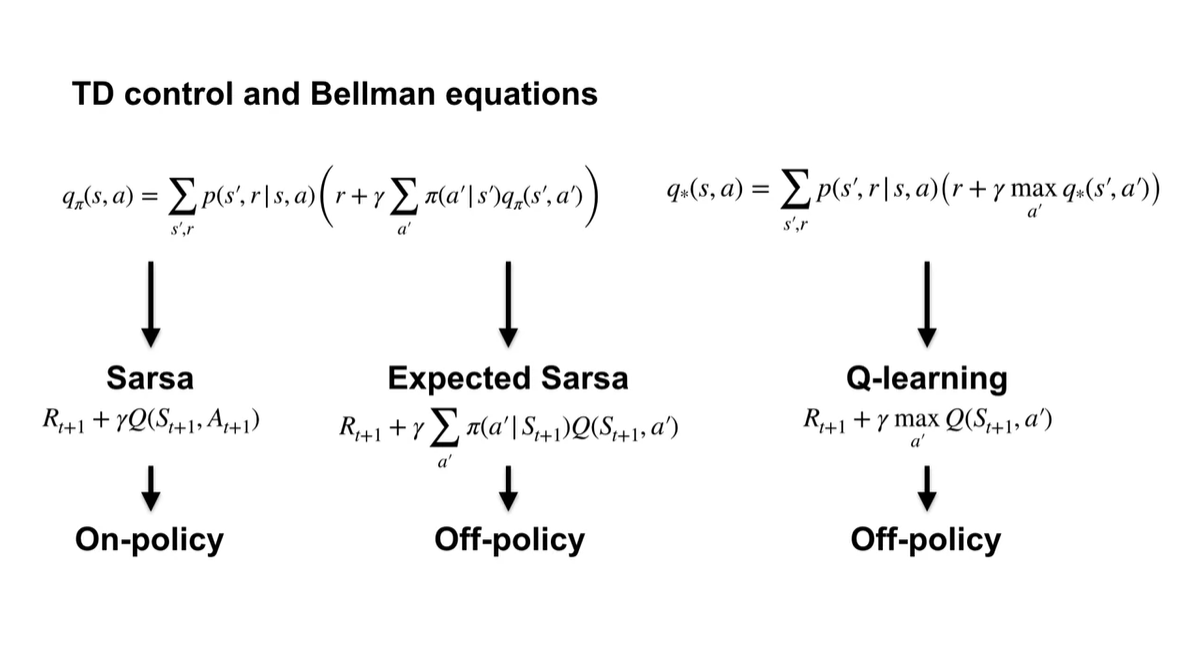
-
Policy Evaluation으로 가 estimate되고 나면, Policy Improvement로 를 업데이트 한다.
- 처음에는 Cheese로 향하는 직전의 길에서만 policy가 업데이트 되었다면, 이후 로 향해가면서 optimal policy가 모든 state에서 업데이트 된다.

-
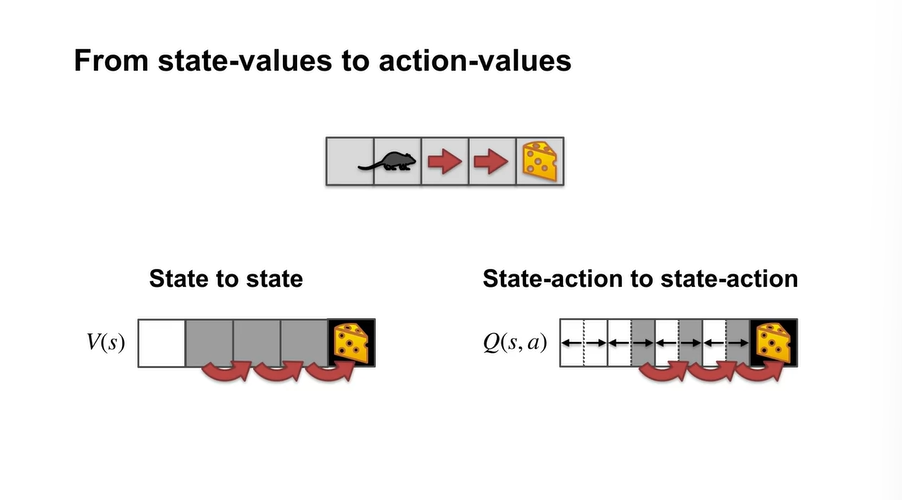
TD에서는 state-values에서 action-values로 관점을 바꿔야 한다.
-
State-action pair로 values를 estimate하며 policy를 선택하는 과정이 필요하다.
- 이와 같은 내용이 Sarsa 알고리즘이다.
-
-
Sarsa 알고리즘은 GPI with TD learning과 같다.
-
기존에는 state-values로만 policy evaluation & improvement 했다면, Sarsa는 state-action pair가 주어지기 때문에 action-values로 업데이트 하게 된다.
- 또한, -greedy method를 사용하여 every time step마다 control한다는 점에서 기존 GPI learning과 다르다고 볼 수 있다.
-

- Summary

Sarsa in the Windy Grid World
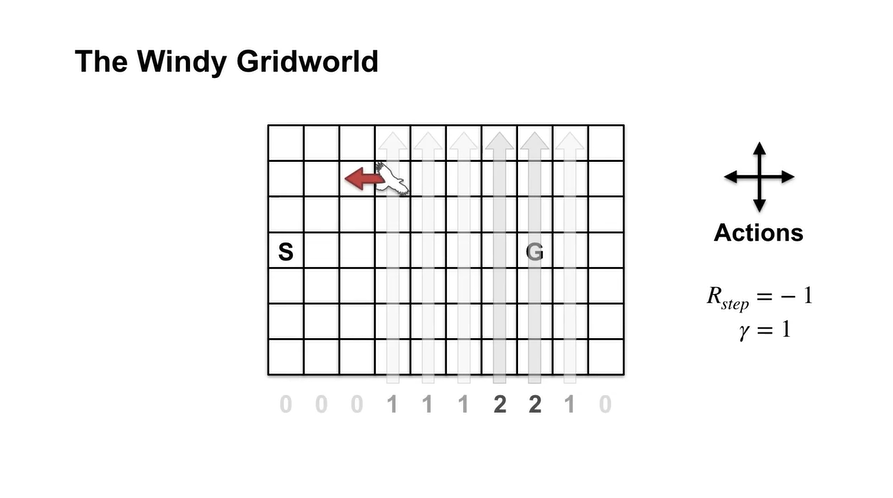
- Sarsa in the Windy Grid World 예제를 보자.

- 이번 강의에서는 MDP 예제에서의 Sarsa control 알고리즘을 이해해보도록 하자.

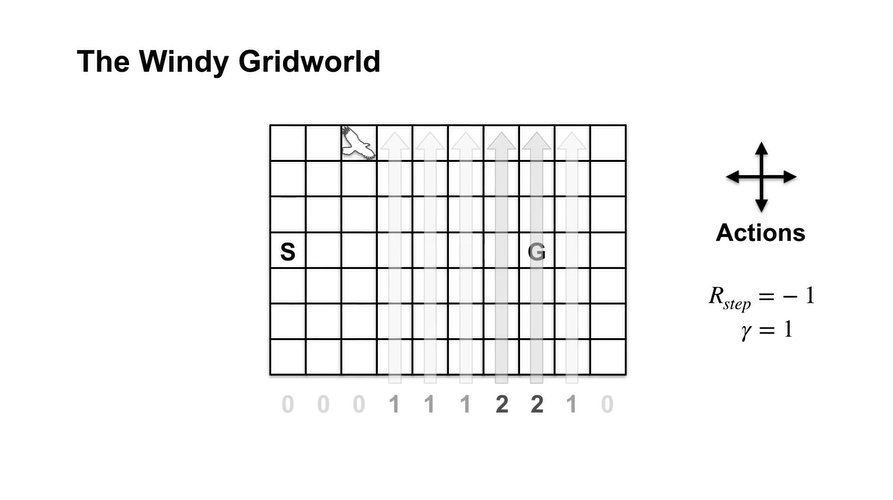
- 아래와 같은 Grid World가 놓여있고 action은 크게 상하좌우 4가지, reward는 -1이며 또한 1이다.

-
만약 아래에서 바람이 불어오고 있고 부는 정도가 아래 숫자와 같을 때, 왼쪽으로 가는 Agent가 있다고 하자.
-
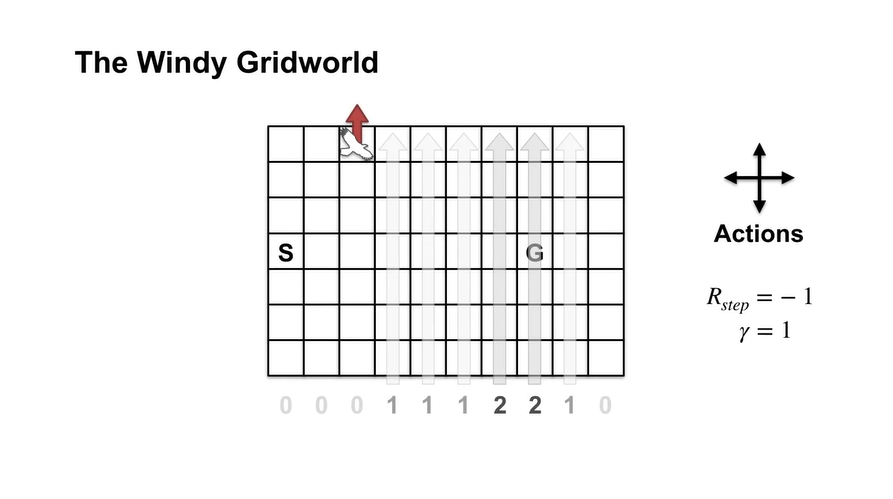
이 Agent는 바람의 영향과 본인이 선택한 action으로 북서쪽으로 한 칸 올라갈 것이다.
- 그리고 이러한 상황에서 위로 가는 다음 action을 취한다면 grid를 벗어나는 행위가 되므로 더 이상 움직이지 못하는 상황에 처한다.
-
-
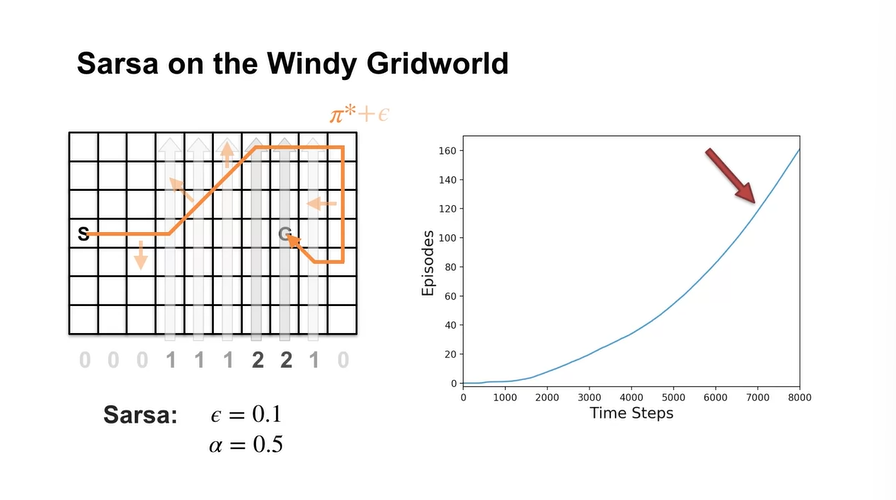
처음 2000번까지의 기울기를 보면 episode가 훨씬 빨리 완료되고, 7000번쯤 되어서는 policy improvement가 급격하지 않다는 것을 알 수 있다.
-
Exploration은 optimal policy로 향해가는 과정을 약간 해칠 수 있기 때문에, episode가 끝났을 때 policy를 업데이트 하는 MC control은 적절하지 않을 수 있다.
- Sarsa는 episode 중에 bad policy임을 알 수 있기 때문에 즉시 다른 policy로 바꾼다면 문제가 생기지 않는다는 장점이 있다.
-
- Summary

Off-policy TD Control: Q-learning
What is Q-learning?
-
Q-learning에 대해 다뤄보자.
- Q-learning은 대부분의 게임 알고리즘에서 쓰이는 알고리즘이라고 한다.
- 이번 강의에서는 Q-learning 알고리즘과 Bellman optimality equations간의 관계에 대해 다루게 된다.

- Sarsa 알고리즘과 Q-learning의 차이점은 max (action-value)를 선택한다는 점에 있다.

-
Sarsa는 Bellman equation for action-value의 sample 버전이라고 볼 수 있다.
-
Q-learning은 Bellman optimality equations의 sample 버전이다.
- 이를 통해 evaluation & improvement step을 밟지 않고도 로 directly하게 학습할 수 있다.
-

-
Sarsa는 Policy Iteration이고 Q-learning은 Valu Iteration에 비유할 수 있다.
- 두 알고리즘 모두 sample based Dynamic Programming이라는 점에서 공통점을 가진다.
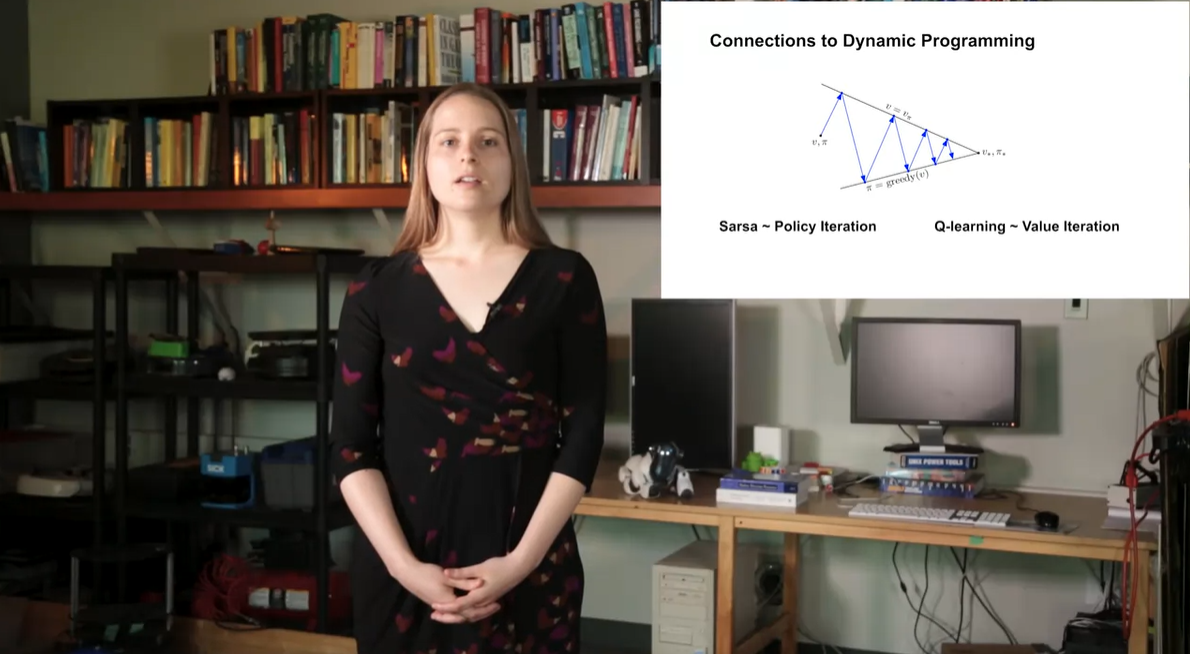
- Summary

Q-learning in the Windy Grid World
- Q-learning in the Windy Grid World 예제를 살펴보자.

- 이번 강의에서는 MDP example에서의 Q-learning 학습 방식과 여러 알고리즘의 performance를 비교해볼 예정이다.
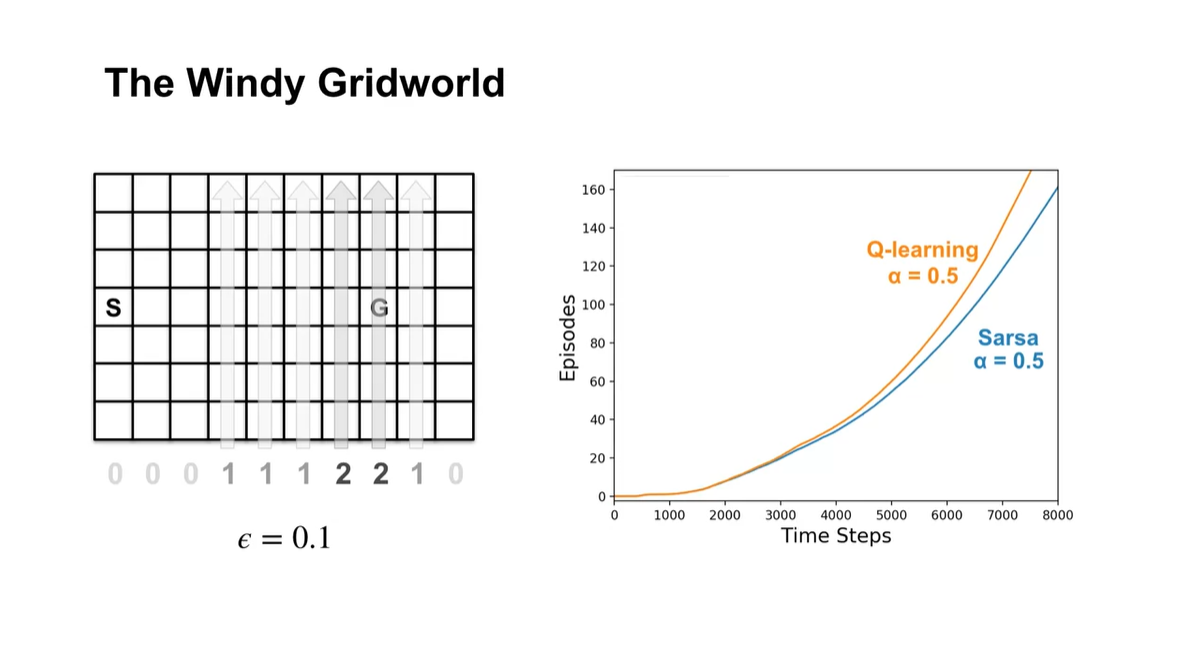
-
만약 같은 parameter 를 설정하였다고 하면 아래와 같은 그래프가 그려진다.
-
Sarsa는 greedy behavior를 value function에 평균값으로 업데이트 하기 때문에 더 나은 성과를 낼 수 있다.
-
Q-learning은 매순간 최대치를 차지하며 즉각적으로 업데이트하기 때문에 수렴 속도가 빠르다는 특징이 있다.
-
-
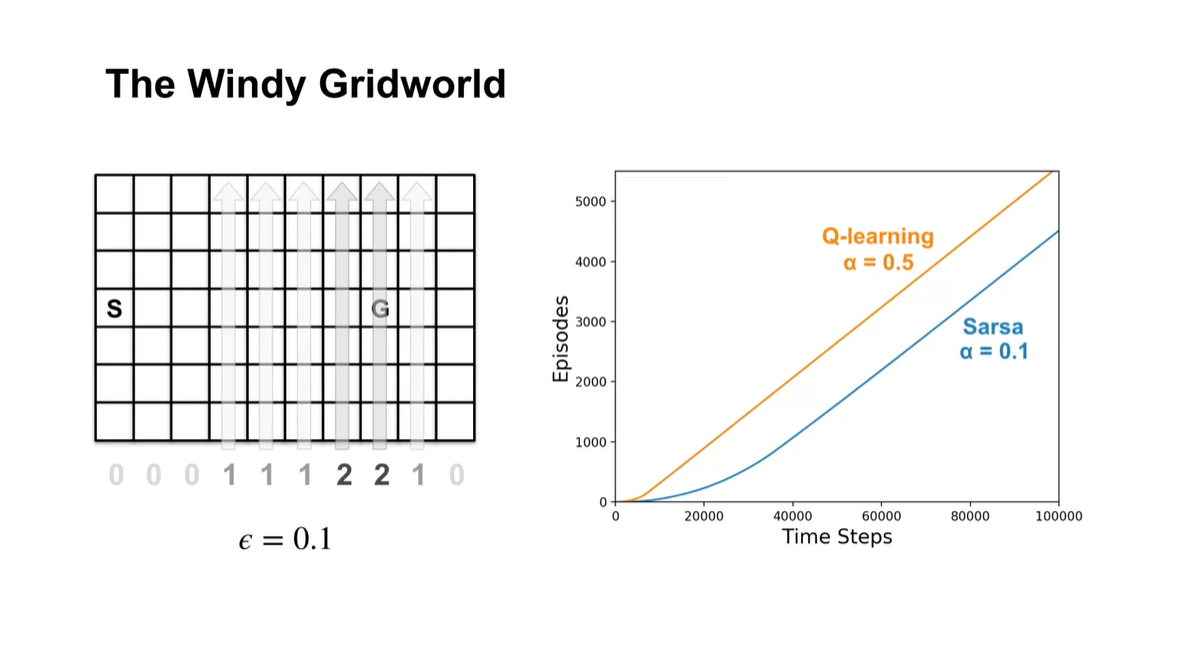
만약 Sarsa의 값을 0.1로 설정한다면 어떻게 될까?
-
아래와 같이 Q-learning과의 기울기가 거의 비슷해지는 것으로 미루어보아, 두 알고리즘 모두 동일한 정책으로 수렴하고 있다는 것을 알 수 있다.
-
이를 통해 , , initial state 모두 학습 효과와 속도에 영향을 미치고 있음을 알 수 있으므로, 다양한 실험을 통해 적절한 optimal 값으로 향해가도록 만들면 된다.
-
- Summary

How is Q-learning off-policy?
- Q-learning off-policy란 무엇일까?
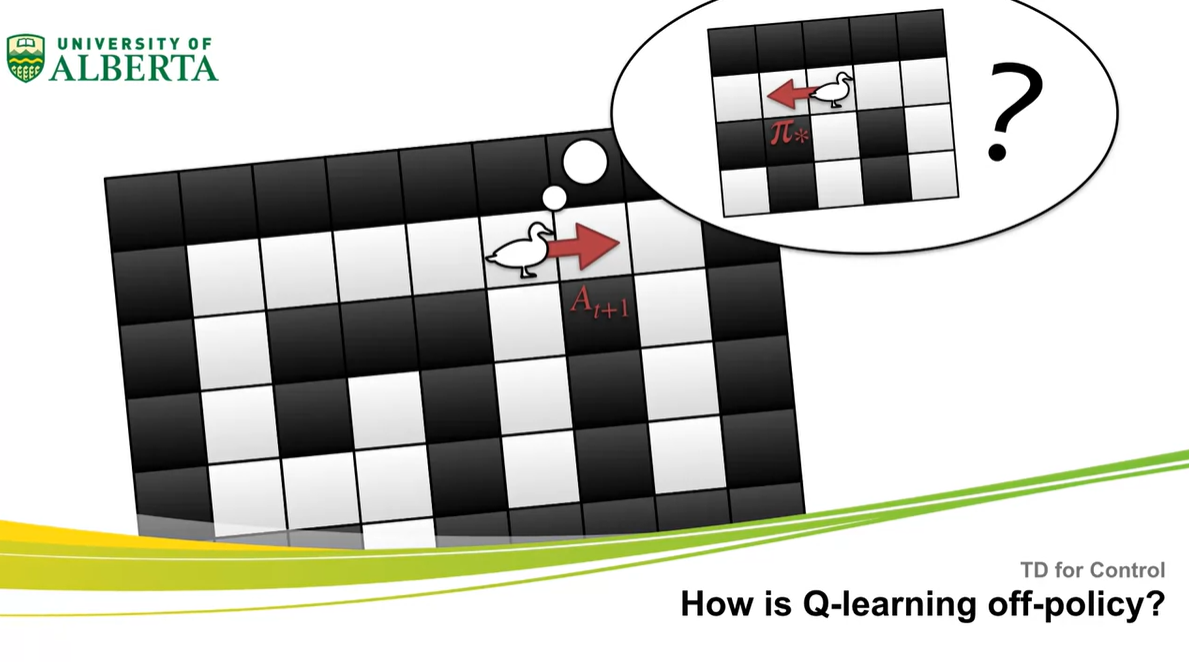
-
이번 강의에서는 importance sampling 없이 Q-learning이 어떻게 off-policy일 수 있는지에 대해 다뤄보도록 하겠다.
- On-policy나 Off-policy가 control에 어떠한 영향을 미치는지에 대해 묘사해보도록 하자.

-
Sarsa는 on-policy 알고리즘으로, behavior 정책에서 sampling한 다음 step의 value를 boostrap한다.
-
Q-learning은 다음 step에서 가장 큰 action-value를 boostrap한다.
- 따라서 Q-learning은 optimal policy를 추정하여 target policy를 추정해나가는 과정이라고 볼 수 있다.
-

- Target policy는 항상 optimal하지만 Behavior policy는 그렇지 않아도 된다.
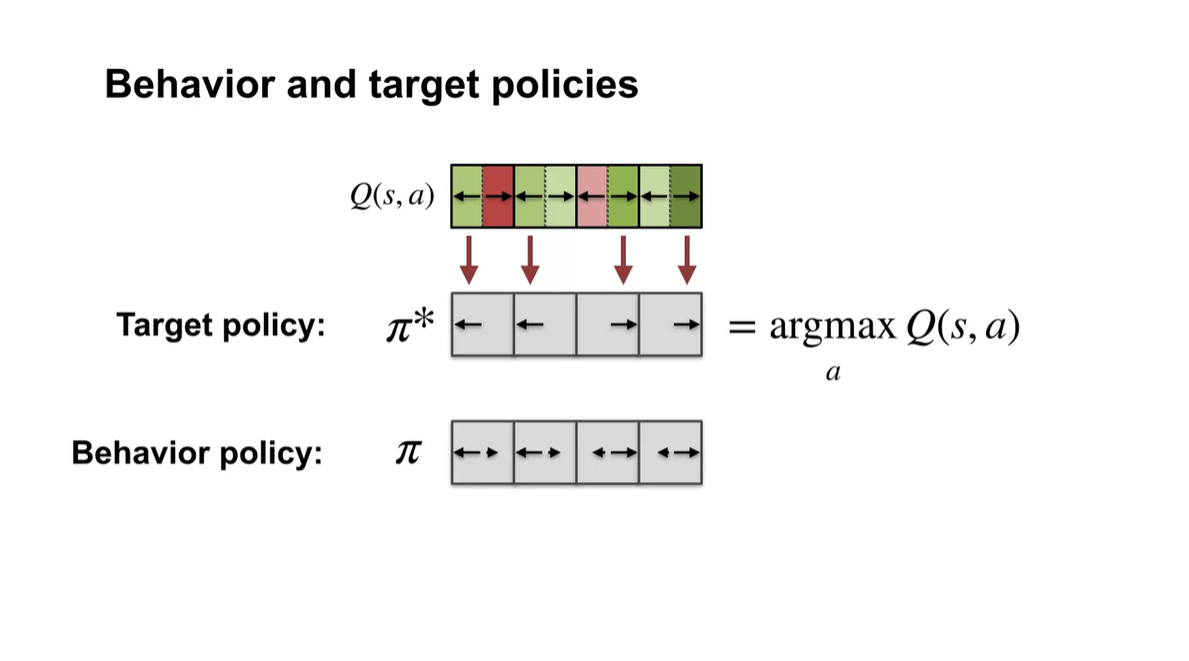
-
Q-learning이 off-policy라면 왜 importance sampling ratio를 볼 수 없을까?
-
이는 Agent가 알 수 없는 policy로 action을 추정하고 있기 때문에 차이를 보정하기 위한 ratio를 따로 정정할 필요가 없다고 한다.
- 아래와 같은 예시에서는 maximal 를 구하여 맨 오른쪽 경로로 향하게 되었음을 알 수 있고, 이 때의 policy 를 1로 설정하였음을 알 수 있다.
-
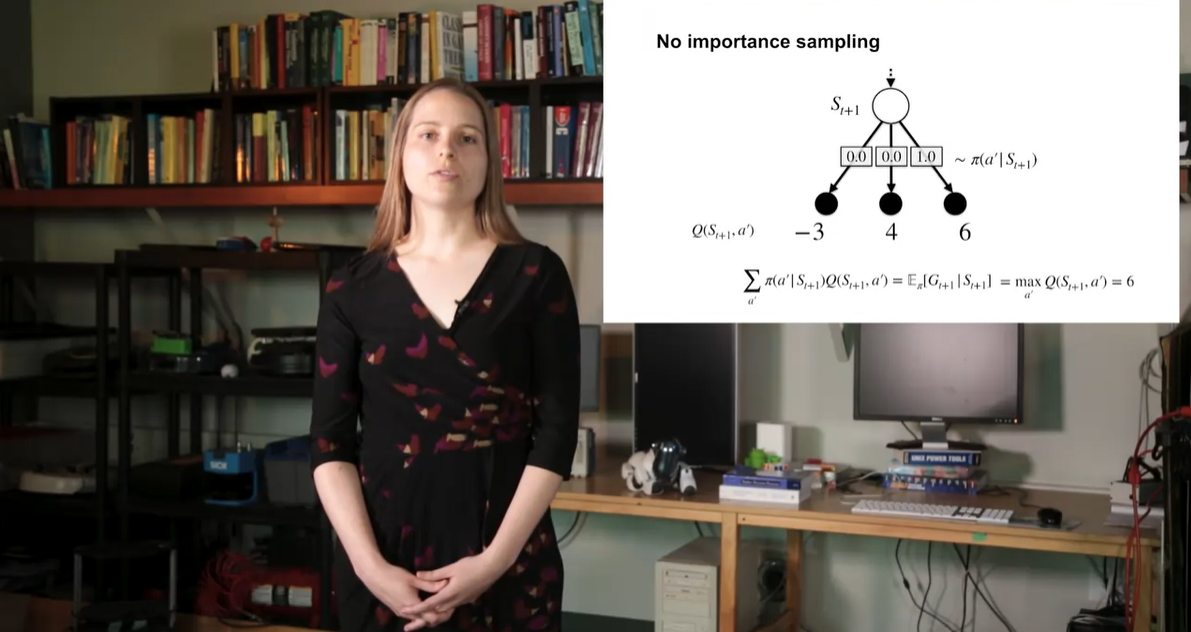
-
The cliff walking environment에서의 상황을 보자.
-
Q-learning은 당장의 maximal action-value만을 고려하기 때문에 전체 rewards가 Sarsa 알고리즘에 비해 높지 않다.
-
Sarsa는 조금 더 enable하고 safety한 경로로 움직이는 것을 알 수 있다.
-
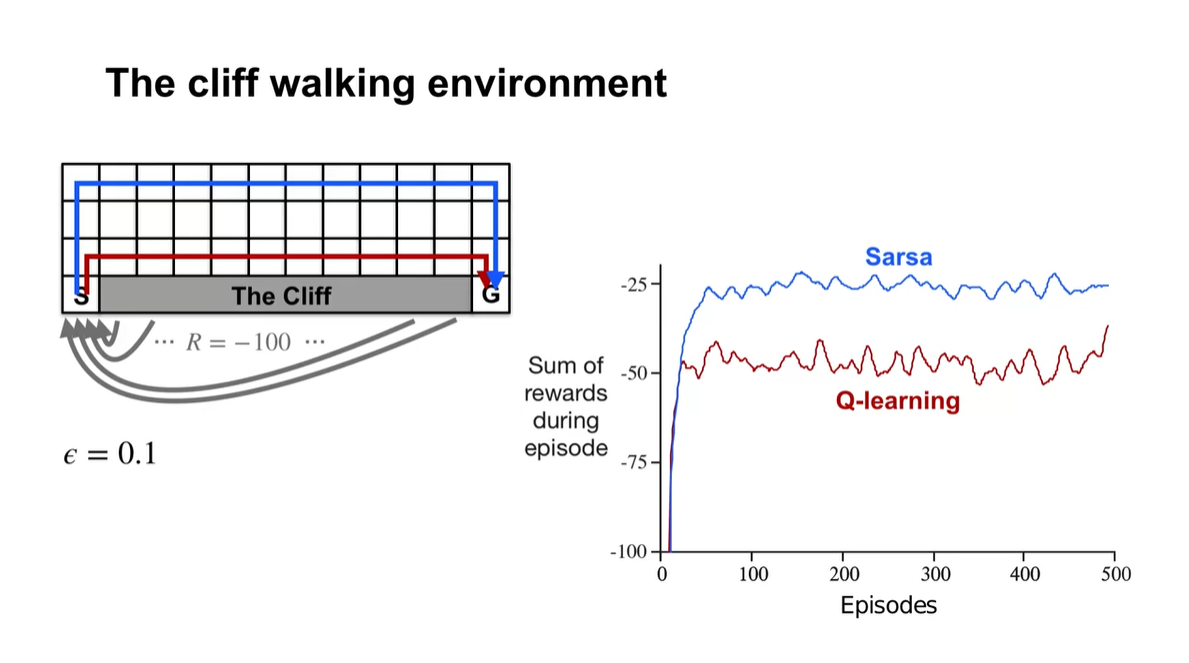
- Summary

Expected Sarsa
- Expected Sarsa라는 또 다른 TD control 개념에 대해 알아보자.
- 이번 강의에서는 Expected Sarsa 알고리즘에 대해 설명한다.

-
Bellman equation으로부터 action-value를 계산하는 방법은 다음과 같이 policy 를 따르는 모든 action-value의 expectation으로 구하였다.
-
Sarsa는 현 상태에서의 Q와 다음 상태에서의 Q의 차이를 더함으로써 지속적인 업데이트를 하는 알고리즘이다.
-
이 때 state는 MDP process를 따르고 agent는 이미 policy를 알고 있는 상황에서 action을 취하고 있는데, 왜 다음 action을 sampling해야 할까?
- 각 action을 취할 확률에 따른 가중치를 두어 expected value를 구하고 싶기 때문이다.
-

- Expected sarsa에서 policy 확률에 따른 어떠한 action-value를 모두 구하여 평균을 내었더니 1.4의 값이 예상되었다고 해보자.

-
Expected sarsa는 이러한 평균치를 곧바로 다음 action 예상 값으로 활용한다.
-
즉, 어떠한 state에서의 하나만 뽑힌 action-value만을 고려하는 것이 아니라 매번 평균 낸 expected value로 TD 알고리즘을 적용하는 것이다.
- 다시 말해 기존 sarsa 알고리즘에서 어떠한 action을 잘못 선택하였을 경우, 값이 잘못된 방향으로 업데이트 될 위험성을 줄여주는 효과를 갖는다.
-

-
이렇게 되면 Expected sarsa는 sarsa에 비해 낮은 variance를 가진다는 특징이 생긴다.
- 단점은 action 경우의 수가 늘어날수록 평균을 계산하는 데 더 많은 비용이 든다는 점이다.

- Summary

Expected Sarsa in the Cliff World
- Expected Sarsa를 Cliff World example에서 다뤄보자.
- 이번 강의에서는 Expected sarsa behavior 개념에 대해 알아볼 예정이며, Expected sarsa와 sarsa를 비교해 볼 것이다.

-
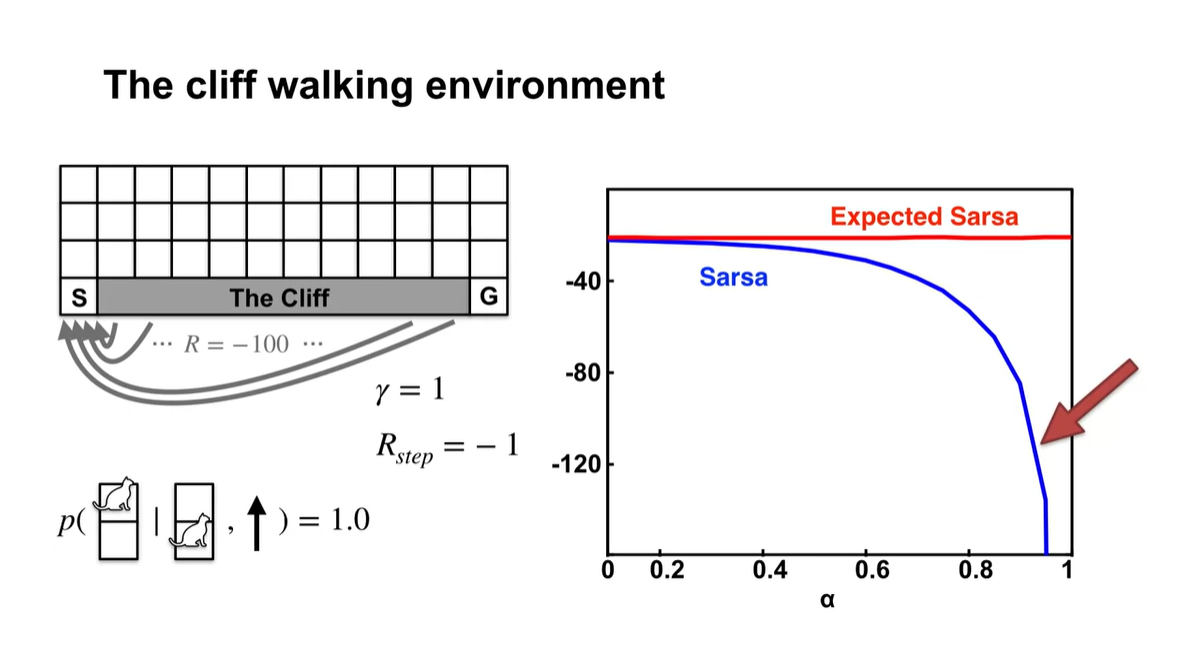
아래 그래프에서 x축은 step size 를 나타내고 y축은 average return을 나타낸다.
-
거의 모든 값에서 expected sarsa가 sarsa에 비해 더 높은 값을 가진다.
- 이는 무작위적인 평균을 구하기 때문에 step size가 늘어나더라도 특정 값으로 수렴하지 않는다고 볼 수 있다.
-
또한, 이러한 환경은 결정론적인 환경이라 sample 뽑기 이외의 다른 무작위성을 고려할 필요가 없다.
-

-
100,000개 이후 에피소드 그래프를 그리면 아래와 같다.
- Expected sarsa는 robust하게 특정 값에 머무르지만, sarsa는 오히려 step size가 커질수록 떨어지는 양상을 볼 수 있다.
- Summary
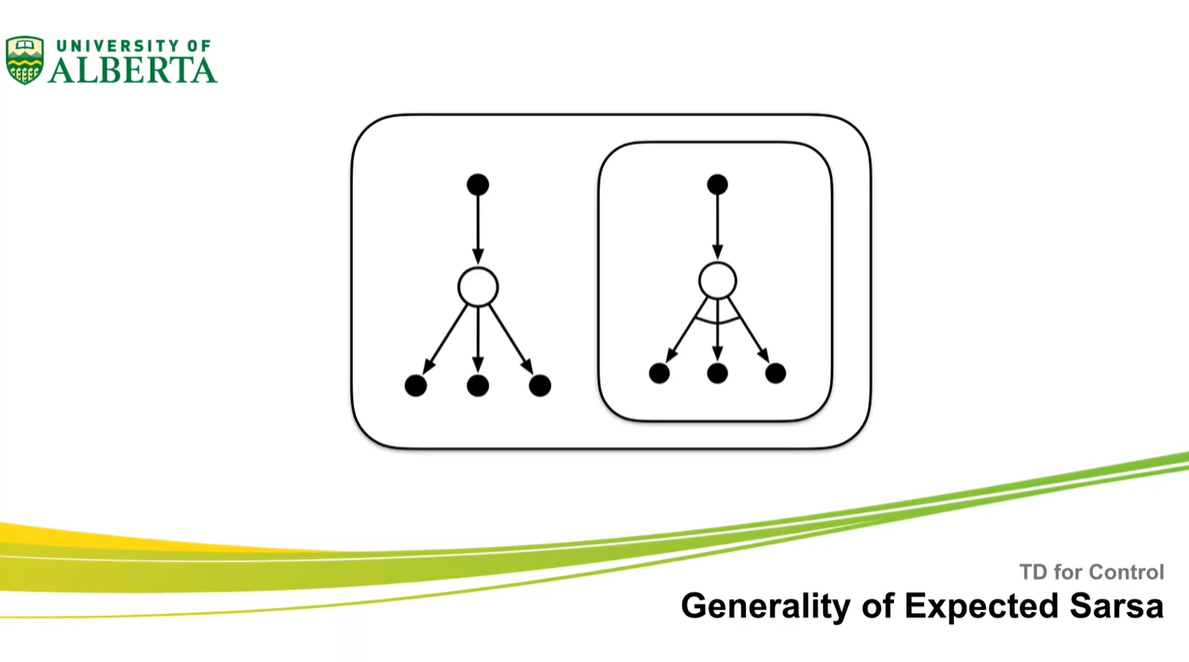
Generality of Expected Sarsa
- Expected Sarsa를 일반화하여 정리해보자.
-
이번 강의에서는 TD control 내용인 Sarsa, Q-learning, Expected Sarsa를 비교해 볼 것이다.
- Sarsa와 Expected sarsa는 Bellman equation에 근사하고, Sarsa와 Q-learning이 어떤 관련이 있는지 알아볼 예정이다.

-
Expected Sarsa에서는 를 따르는 특정 action에 대한 기대치를 계산하여 업데이트 한다.
-
이는 다음 state에서 취한 실제 action과는 독립적으로 계산된다는 점에 유의하여야 한다.
- 그리고 이러한 는 실제 행동 space인 와 같을 필요는 없다.
-
즉, Q-learning과 마찬가지로 Expected Sarsa에서는 policy를 벗어난 학습을 할 수 있다는 점이 특징이다.
-

-
만약 behavior policy에서 가장 가치가 높은 기대치를 greedy하게 뽑으려 한다면 어떻게 될까?
- 이는 Q-learning에서 다루는 다음 상태에서의 action-value 최대치를 계산하는 것과 같은 수식이다.
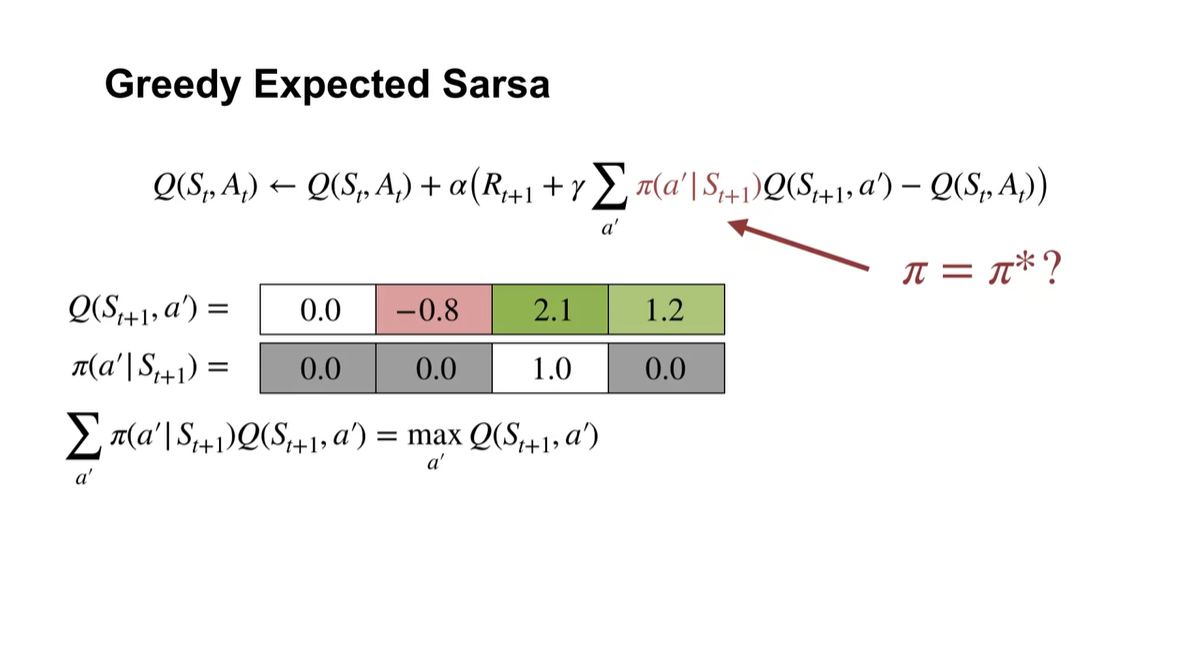
- 다시 말해, Q-learning은 Expected Sarsa의 조금 특별한 경우에 해당한다.

- Summary

Week 3 Summary