파이토치로 시작하는 딥러닝 기초 (부스트코스) - Lab-05 Logistic Regression
GitHub 주소
로지스틱 회귀: 두 데이터 요인 간의 관계를 찾는 데이터 분석 기법
예측값은 일반적으로 예(1) 또는 아니요(0)와 같은 유한한 수의 결과를 가짐
로지스틱 회귀 함수는 [-inf, inf]의 값을 갖게 되는데
이후 sigmoid 함수에 의해 [-1, 1]의 값을 갖게 됨
시그모이드 함수
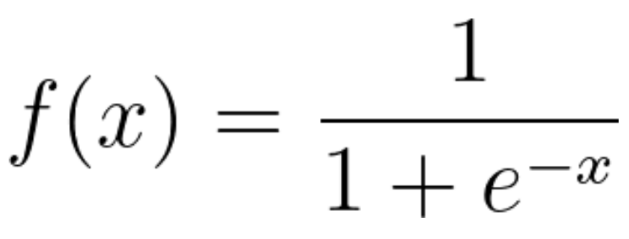
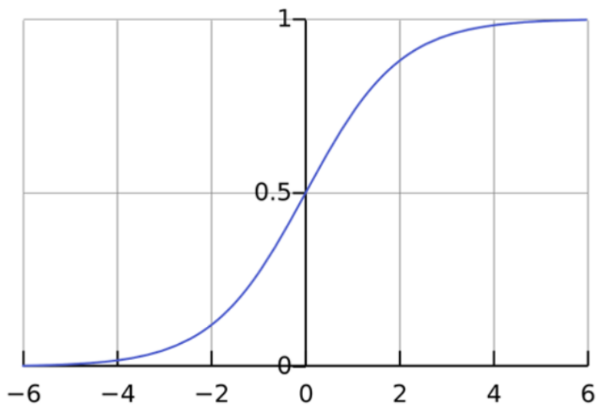
출처
구현
강의에서의 Hypothesis 함수와 cost 함수는 아래와 같이 정의하였다.
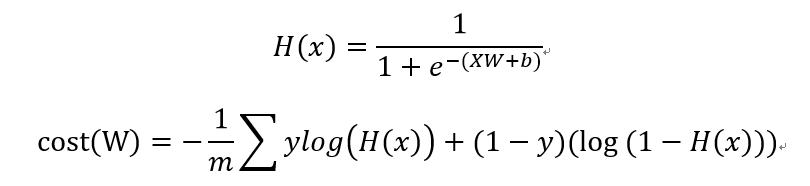
cost는, 위와 같이 정의할 수도 있지만
아래처럼 함수 하나만 써서 간단하게 정의할 수도 있다.
losses = -(y_train * torch.log(hypothesis) + (1 - y_train) * torch.log(1 - hypothesis))
cost = losses.mean()
cost = F.binary_cross_entropy(hypothesis, y_train)hypothesis도 비슷하다
아래와 같이 정의할 수도 있지만
hypothesis = 1 / (1 + torch.exp(-(x_train.matmul(W) + b)))
# 또는
hypothesis = torch.sigmoid(x_train.matmul(W) + b)이전 강의 내용대로, nn.Module을 이용하여 구현하면 더 편하다.
class BinaryClassifier(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(8, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
return self.sigmoid(self.linear(x))참고로
X의 size = (5, 8)
W의 size = (8, 1)
b와 y의 size = (5, 1)
모델의 정확성 검사
prediction = hypothesis >= torch.FloatTensor([0.5]) # 0.5보다 크면 1, 작으면 0의 값을 갖도록 함
correct_prediction = prediction.float() == y_train # 예측값과 실제 y값이 같으면 1, 아니면 0을 갖도록 함
accuracy = correct_prediction.sum().item() / len(correct_prediction) # 얼마나 같게 나왔는지결론적으로, 최종 코드는
class BinaryClassifier(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(8, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
return self.sigmoid(self.linear(x))
model = BinaryClassifier()
xy = np.loadtxt('data-03-diabetes.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
x_train = torch.FloatTensor(x_data)
y_train = torch.FloatTensor(y_data)
# optimizer 설정
optimizer = optim.SGD(model.parameters(), lr=1)
nb_epochs = 100
for epoch in range(nb_epochs + 1):
# H(x) 계산
hypothesis = model(x_train)
# cost 계산
cost = F.binary_cross_entropy(hypothesis, y_train)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 20번마다 로그 출력
if epoch % 10 == 0:
prediction = hypothesis >= torch.FloatTensor([0.5]) # 0.5보다 크면 1, 작으면 0의 값을 갖도록 함
correct_prediction = prediction.float() == y_train # 예측값과 실제 y값이 같으면 1, 아니면 0을 갖도록 함
accuracy = correct_prediction.sum().item() / len(correct_prediction) # 얼마나 같게 나왔는지
print('Epoch {:4d}/{} Cost: {:.6f} Accuracy {:2.2f}%'.format(
epoch, nb_epochs, cost.item(), accuracy * 100,
))