[Project] Multi-Tenant K8s Cluster on ARM64 - (11) Monitoring Dashboard
[Project] Multi-Tenant K8s Cluster on ARM64

이번에는 홈랩의 모니터링 서버를 구축해보려고 합니다. 고도화 해볼 요소가 많은 부분인데, 우선 간단하게
Node-Exporter/kube-state-metrics + Prometheus + Grafana를 사용하겠습니다.
아키텍처 후보
우선 공통적으로 모니터링 서버를 클러스터와 격리시키면 좋겠다고 생각했습니다. 외부 클라우드 서비스에 모니터링 서버를 띄우는게 괜찮은지는 모르겠다만,,
‘클러스터와 모니터링 서버의 격리’에 초점을 두기로 했습니다.
1안) - 각 노드에 모니터링용 포트를 개방하여 외부 모니터링 서버와 연결하기 (포트포워딩)
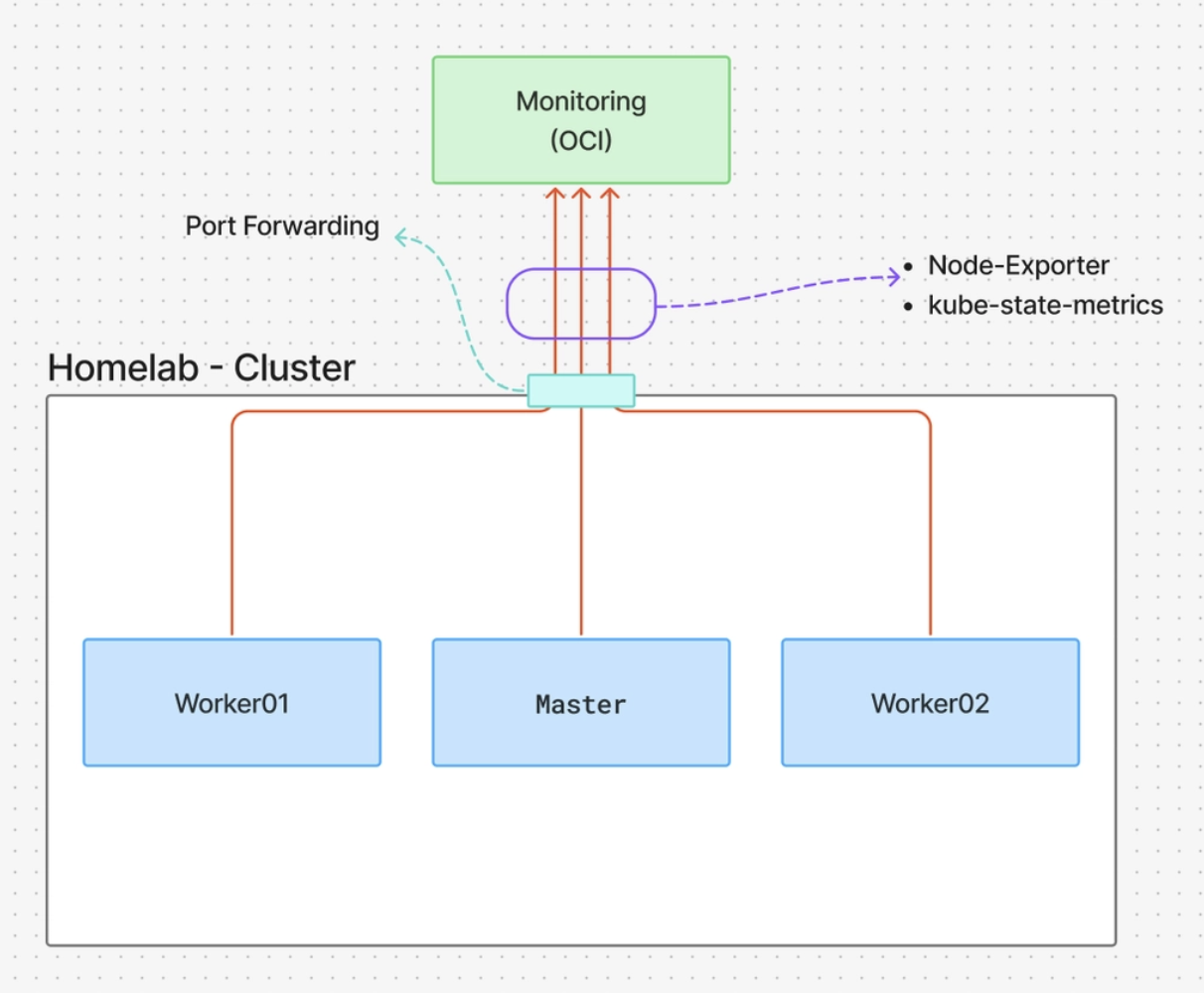
장점- 구축이 비교적 간단하다. (모든 노드에 대한 포트를 열고 연결하면 되므로)
단점- 현재 클러스터에서는 Bastion 방식으로 워커 노드를 숨기고 있는데 이 구조가 깨지게 됨
- 매트릭이 오고 가는 통로가 외부에 노출되므로 보안상 위험할 수 있음
2안) - 마스터 노드와 모니터링 서버만 연결하고, 이때 연결 방식은 VPN 방식을 사용하기 (VPN + Bastion 구조)
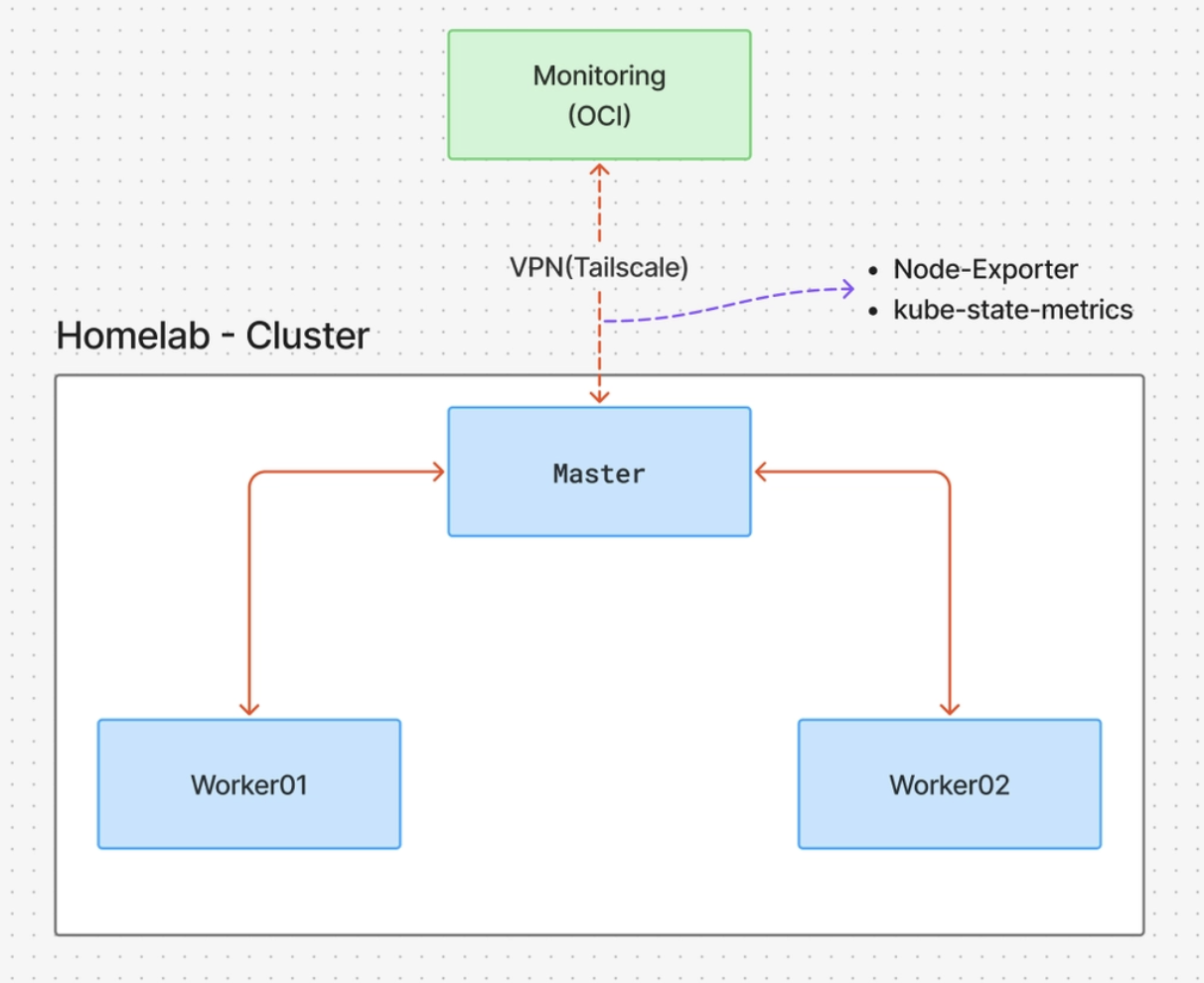
장점- 기존 클러스터 구축 방식과 동일하게 Bastion 구조로 워커 노드를 외부로 노출시키지 않음
- 마스터 노드와 모니터링 서버만 연결을 하고, 이를 VPN 방식으로 연결했기 때문에 매트릭이 지나는 통로를 숨길 수 있음.
- 공인 IP 노출 없이 NAT 환경(가정용 공유기)을 통과하여 양방향 통신을 함. -
Hole Punching
- 공인 IP 노출 없이 NAT 환경(가정용 공유기)을 통과하여 양방향 통신을 함. -
단점- 마스터 노드를
Metric Gateway로도 사용하게 됨.(트래픽 집중 현상이 발생하지 않을까..? 하는 생각이 듭니다.) - 구축이 비교적 복잡하다.
- 마스터 노드를
클러스터 아키텍처상 Bastion 방식을 채택하고 있으므로 이를 유지하고자
2안의 방식으로 구축을 진행하겠습니다.
전체 아키텍처
- 라즈베리파이 클러스터 (데이터 생성)
Node Exporter&Kube-state-metrics가 각각 하드웨어 지표와 쿠버네티스 상태 정보를 생성
- OCI 인스턴스 (수집 및 시각화)
Prometheus가 Tailscale을 통해 라즈베리파이의 데이터를 Scraping 하여 저장하고,Grafana가 이를 시각화
- 보안 게이트웨이 설계
- 보안을 위해 워커 노드를 외부에 노출하지 않고, 마스터 노드를 통해서만 지표가 나가도록 설계
1단계: OCI 인스턴스 보안 설정 (Ingress)

- Security List 규칙 추가
- 3000 (Grafana 웹 대시보드 접속용)
- 9090 (Prometheus 타겟 상태 확인 및 디버깅 확인용)
- OS 방화벽(iptables/firewalld) 설정
- OCI 보안 리스트뿐만 아니라 인스턴스 내부 방화벽에서도 해당 포트를
ACCEPT하도록 설정
- OCI 보안 리스트뿐만 아니라 인스턴스 내부 방화벽에서도 해당 포트를
2단계: 네트워크 연결 (Tailscale VPN)
- 공인 IP 노출 없이 안전하게 데이터를 전송하기 위한 연결
- Tailscale 설치
- OCI 인스턴스와 라즈베리파이 마스터 노드에 각각 설치하여 사설 IP로 통신하도록 설정
- MTU 최적화
- 대량의 메트릭 데이터(특히
kube-state-metrics) 전송 시 패킷 유실을 방지하기 위해 Tailscale 인터페이스의MTU를1280으로 조정- ⚠️ 현재 구축 환경에서는 kube-state-metrics 가 수집한 매트릭이 유실되거나, OOM이 발생하여 인스턴스가 다운되는 상황이 자주 발생.
- 대량의 메트릭 데이터(특히
3단계: 라즈베리파이 에이전트 배치
Node Exporter- 각 노드의 CPU, 메모리, 온도 등의 지표 수집
kube-state-metrics- 쿠버네티스 API 를 통해 파드, 노드, 배포 상태 등을 수집
- NodePort 설정: OCI에서 접근할 수 있도록 30080 포트 개방
- 리소스 최적화: 타임아웃 방지를 위해 CPU/Memory Request 를 명시적으로 할당
4단계: OCI Prometheus & Grafana 구축
Docker Compose 구성- 두 서비스를 컨테이너로 띄워 관리 효율성 높임
Prometheus 네트워크 모드 (network_mode: host)- 컨테이너 내부가 아닌 호스트의 Tailscale 네트워크를 직접 사용하도록 설정하여 통신 장애를 해결
prometheus.yml 설정- scrape_interval 과 scrape_timeout 을 조정하여 지연 시간 극복
- 대시보드 필터링을 위해
cluster: ‘raspberry-pi-cluster’라벨을 강제로 부여
⚠️ 문제 발생
- 현재 모니터링 서버는 OCI(Oracle Cloud Architecture) 프리티어 계정으로 받은 인스턴스에 띄워져 있습니다.
- Node-Exporter가 수집하는
매트릭 + Refresh 1m는 문제가 없는데,kube-state-metrics + Refresh 1m조합은 인스턴스가 터지는 상황이 계속 발생했습니다.- 너무 많은 양의 매트릭 + 전송량 + Refresh 주기 등의 문제로 OOM이 발생하여 인스턴스가 다운되는 것 같음.
→ 우선, 모니터링 대시보드 구축이 첫 목표였기에 Node-Exporter 의 매트릭을 사용하여 모니터링 대시보드를 구축하겠습니다.
→ Relabeling 기능 사용, 인스턴스 사양 업그레이드, gRPC 도입 등으로 추후 해결해보겠습니다.
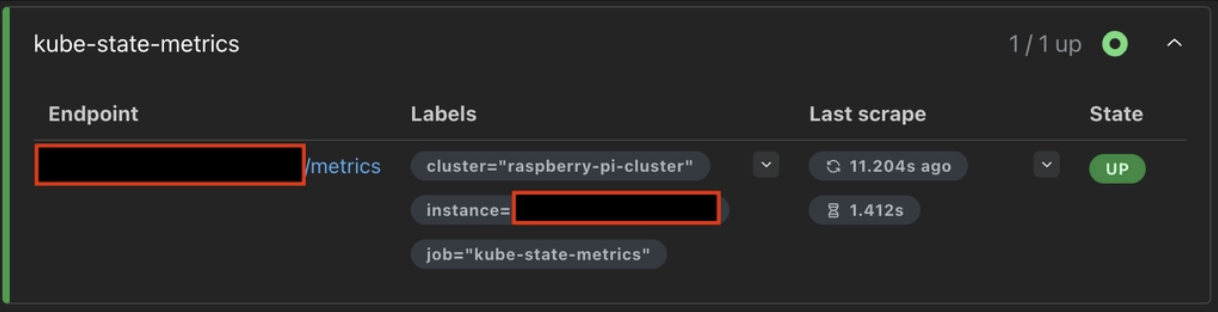
Prometheus는 정상적으로 연결이 되어 있는 상태이므로,,, 추후 모니터링 고도화 작업을 진행하며kube-state-metrics또한 살려보겠습니다..!
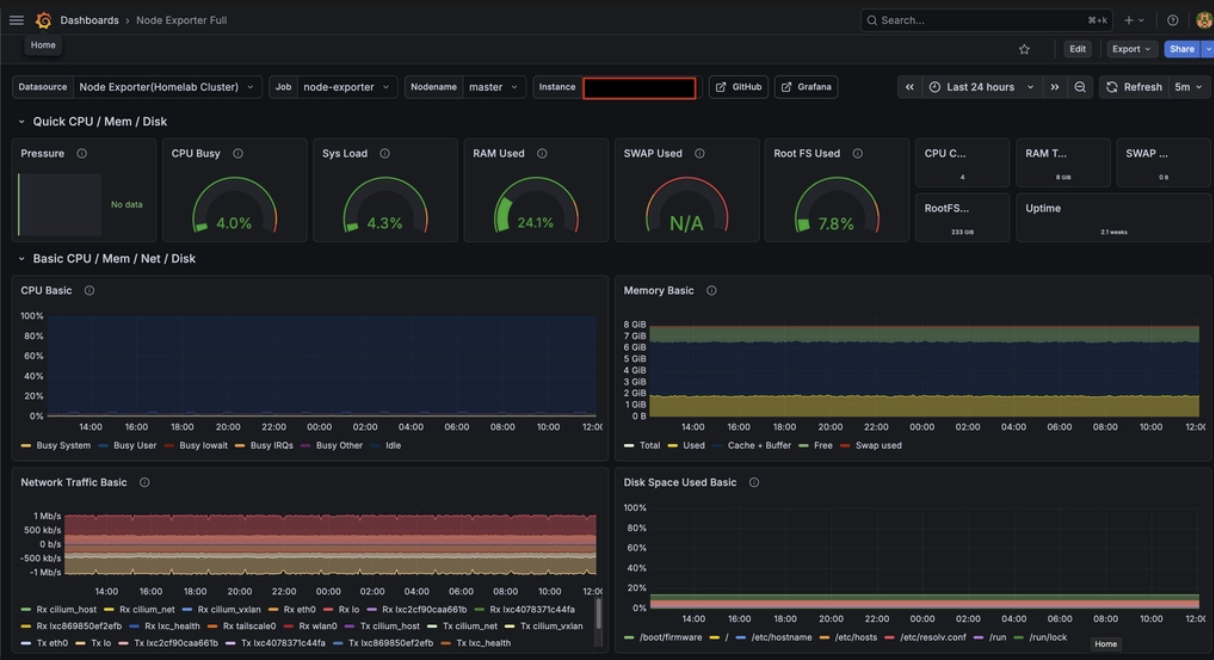
5단계: Grafana 시각화
- 데이터 소스 연동
- 특정 URL로 Prometheus 연결
📌 모니터링 방법론 (USE, RED, Fore golden signal)
- 이번 포스팅에서 자세히 다룰 것은 아니지만, 다양한 방법론이 있기에 이들을 학습해보고 적절히 도입을 해보면 좋을 것 같습니다.
USE Method - 인프라 시스템 중심 / Node-Exporter
하드웨어 자원의 상태를 확인하기 위한 방법론
Utilization (사용률)
- 자원이 얼마나 사용되었는가?
- ex: node_cpu_seconds_total
Saturation (포화도)
- 자원이 얼마나 줄을 서서 기다리고 있는가?
- ex: node_load1
Errors (에러)
- 하드웨어/드라이버 레벨의 에러 발생 횟수
- ex: node_net_errs_total
RED Method - 서비스 중심 / App 메트릭, kube-state-metrics
사용자가 느끼는 서비스의 품질을 측정하기 위한 방법론
Rate (TPS 등)
- 초당 요청 수
- ex: http_request_total
Errors (에러)
- 실패한 요청 수
- ex: HTTP 500 에러 비율
Durations (응답 시간)
- 요청을 처리하는 데 걸린 시간
- ex: http_request_duration_seconds_bucket
Four golden signal / 구글 SRE 팀의 핵심 지표
구글에서 정의한 가장 유의미한 4가지 지표. RED 메서드의 확장판..?
Latency (지연 시간)
- 서비스 응답에 걸리는 시간
Traffic (트래픽)
- 서비스에 대한 수요
Errors (에러)
- 명시적에러(500), 암시적 에러(성공했지만 응답 내용이 잘못됨) 등
Saturation (포화도)
- 서비스가 얼마나 꽉 찼는지.
- CPU 뿐만 아니라 큐의 길이나 메모리 잔량 포함
USE - 인프라(Hardware)
RED - 서비스(Software)
Golden Signals - 사용자 경험(SRE)
마무리
모니터링 시스템 고도화와 로깅 시스템 고도화에 재밌는 작업들이 많을 것으로 예상됩니다. 현재는 Node-Exporter + Prometheus + Granfana 조합만을 사용하고 있지만, 고도화 과정에서
- kube-state-metrics 사용
- Loki 도입
- ⭐️ Opentelemetry + gRPC + Grafana 구축
등을 해보면 좋을 것 같습니다. (gRPC로 로그나 매트릭을 보내게 된다면 통신 부담이 조금은 덜 하지 않을까 싶습니다..)
그리고 매번 모니터링 시스템을 ‘구축’ 만 해보았는데, 이번 기회에 다양한 방법론도 도입해보고 ‘어떻게 유의미한 데이터를 만들어낼 수 있을지’ 에 대해서도 고민해보면 좋을 것 같습니다.
