[Project] Multi-Tenant K8s Cluster on ARM64 - (12) Using Master Node Resource
[Project] Multi-Tenant K8s Cluster on ARM64
목록 보기
12/15

마스터 노드의 리소스 구성은
CPU - 4.0 Core/RAM - 8GB/Storage - 256GB입니다. 여기서 실제 마스터 노드 운영에 필요한 리소스를 제외하면 놀고 있는 리소스가 상당할 것으로 예상이 됩니다. 그래서 더 많은 리소스를 멀티 테넌트에 사용하고자 합니다.
1. 마스터 노드 작동에 필요한 리소스 견적
CPU: 1.0 Core- etcd, kube-apiserver 는 테넌트 파드가 많아질수록 데이터 통신량과 연산량이 급증.
- 물리적인 1코어를 시스템 전용으로 박제해둠으로써, 테넌트 파드가 CPU를 100% 점유하려는 폭주 상황에서도 제어 신호가 밀리지 않고 클러스터 업무 처리가 가능
Memory: 2.0Gi ~ 2.5Gi- etcd 메모리 캐싱과 클러스터 상태 감시 프로세스가 차지하는 비중
- 메모리 부족 시 지연이나 노드 이탈 현상 발생
Ephemeral Storage: 5Gi 이상- 로그와 컨테이너 이미지 레이어들이 쌓이는 공간
- 여기가 꽉 차면 마스터 노드 자체가 DiskPressure 상태에 빠져 멈춤
일반적으로 마스터 노드는 최소 사양 2코어 이상을 권장하지만,, 리소스 제약(홈랩)을 고려하여 1.0 Core 를 물리적으로 예약(Reserved) 하는 방식을 채택했습니다!
2. 마스터 노드에 걸린 제한(Taint) 해제하기
- 현재 마스터 노드에는
Taint가 붙어 있기 때문에 일반 파드가 배포되지 않는다.
# 마스터 노드의 NoSchedule 설정 제거 (명령어 끝의 '-'가 제거를 의미합니다)
kubectl taint nodes master node-role.kubernetes.io/control-plane:NoSchedule-
⚠️ 주의사항:
NoSchedule-을 사용하여 마스터 노드를 개방했습니다. 나중에 테넌트 파드가 배포될 때, 테넌트 파드가 CPU 스케줄링을 두고 경쟁을 하게 되고 이때 마스터 노드의 작업에 영향을 끼칠 수도 있습니다.
이에 대한 명시적 조치로PriorityClass와NodeAffinity라는 설정이 있습니다.
📌 PriorityClass & NodeAffinity
PriorityClass== “누구를 먼저 내보낼 것인가?”쿠버네티스 노드에 자원이 부족해지면 커널은 어떤 파드를 죽여서 노드를 살릴 것인지 결정을 합니다. 이때
PriorityClass는 파드에게 붙여주는 계급장 역할을 합니다.
- 파드마다 숫자(value)를 부여하고, 숫자가 높은 파드일수록 제거 후순위가 됩니다.
- 마스터 노드에서의 활용
- 시스템 파드 (apiserver, etcd 등): 매우 높은 점수 (기본값으로 이미 높음)
- 테넌트 파드: 낮은 점수
- 기대 효과
- 마스터 노드의 메모리가 꽉 차면, 쿠버네티스는 점수가 낮은 테넌트 파드를 먼저 kill 시켜서 마스터 노드의 생존을 최우선으로 보장한다
NodeAffinity== “어디에 위치하게 할 것인가?”
- 파드가 배포될 때 라벨에 따라 선호/비선호를 지정하는 기능
- 마스터 노드에서의 활용
- 테넌트 파드들에게 약한 거부감(Preferred Scheduling)을 부여
- 워커 노드에 공간이 있다면 워커 노드로 먼저 가고, 워커 노드가 꽉 찼을 때만 마스터 노드의 남는 자리를 쓰도록 유도
PriorityClass 리스트 확인하기
kubectl get priorityclasses
or
kubectl get pc
- 현재 쿠버네티스 시스템의
priorityclass만 값이 20억점대로 지정이 되어 있음을 확인할 수 있습니다. - 테넌트 파드들의
priorityclass를 따로 지정하지 않았기 때문에 0점(Default)으로 작동 중입니다. - → 마스터 노드의 생존은 어느 정도 보장이 된 상태!
각 파드들의 PC 값을 한 번에 조회하기
kubectl get pods -A -o custom-columns="NAMESPACE:.metadata.namespace,NAME:.metadata.name,PRIORITY-CLASS:.spec.priorityClassName,VALUE:.spec.priority"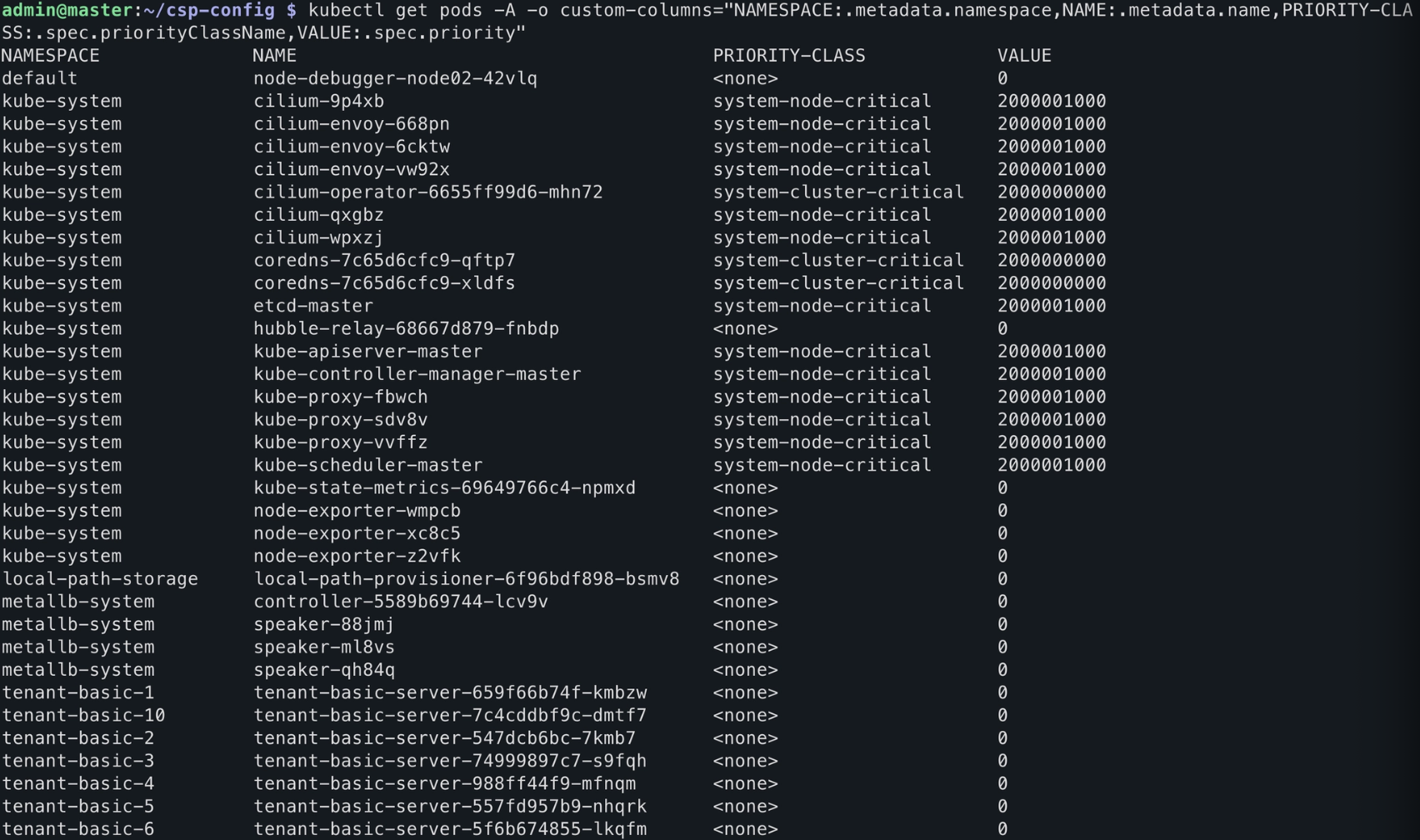
- 시스템 설정 관련 파드들은 모두 20억대의 값(value)을 갖고 있고, 일반 파드들은 기본값인 0을 부여받았음을 확인할 수 있습니다.
3. 리소스 예약 설정(마스터 노드 보호 설정)
- 테넌트 파드가 마스터 노드의 자원을 다 사용하지 못하도록
Kubelet설정 파일을 수정하여 관리자 전용 자원을 강제로 묶음
3-1. 설정 파일 열기
sudo nano /var/lib/kubelet/config.yaml3-2. 리소스 예약 값 추가
kubeReserved(쿠버네티스 관리용) /systemReserved(OS 구동용)kubelet/config.yaml하단에 설정 추가
# 마스터 노드 보호를 위한 리소스 예약 설정
systemReserved:
cpu: "300m"
memory: "500Mi"
kubeReserved:
cpu: "700m" # 시스템과 합쳐서 총 1.0 Core 예약
memory: "2000Mi" # 시스템과 합쳐서 총 2.5Gi 예약
enforceNodeAllocatable: ["pods"]
evictionHard:
memory.available: "500Mi" # 여유 메모리 500Mi 미만 시 테넌트 파드 자동 퇴거
nodefs.available: "10%" # 디스크 여유 10% 미만 시 경고 및 제한systemReserved- 리눅스 운영체제 자체가 동작할 공간을 미리 떼어두는 설정
kubeReserved- 쿠버네티스 관리 객체(kubelet, container runtime 등)를 위한 전용 자원 설정
enforceNodeAllocatable- 노드에서 파드에게 실제로 나누어 줄 수 있는 자원(Allocatable)을 계산할 때, 위에서 예약한 자원들을 강제로 제외하겠다는 선언
- 보통
[”pods”]로 설정하며, 스케줄러는 이 계산된 값을 보고 파드를 배치함
evictionHard- 노드의 자원이 한계치에 도달했을 때, 파드를 강제로 즉시 종료 시켜 노드를 살리는 임계값
4. 마무리 및 설정 반영
4-1. Kubelet 재시작 (필수)
sudo systemctl restart kubelet4-2. 마스터 노드 상태 및 자원 할당량 확인
kubectl describe node master | grep -A 5 "Allocatable:"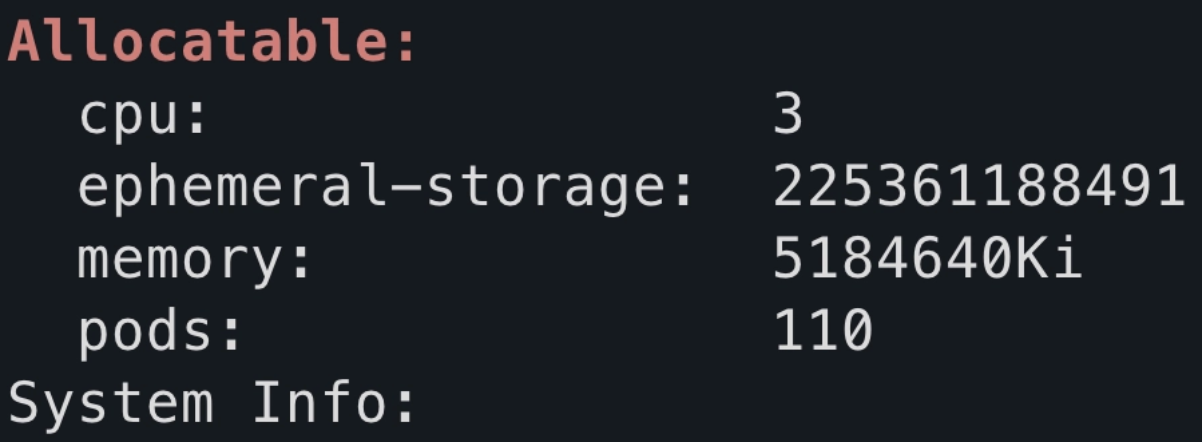
설정이 완료된 후
Allocatable수치를 확인해 보면, 마스터 노드 예약 자원을 제외한“실제 가용 범위"를 확인할 수 있습니다.
cpu: 3
- 4코어 중 시스템용으로 1코어를 예약했기 때문에
cpu - 3가 출력ephemeral-storage: 22536xxxxx
- 256GB 스토리지 중 시스템 영역을 제외하고 파드들이 사용 가능한 저장 공간
memory: 581xxxxxKi
- 전체 RAM 8GB 중, systemReserved + kubeReserved 로 설정한 2.5Gi 와 evictionHard 로 설정한 500Mi 등으로 제외한 수치
pods: 110
- 해당 노드에 최대로 올릴 수 있는 파드의 개수 (쿠버네티스 기본값 == 110)
→ 마스터 노드 예약 리소스 설정 완료!😋

Don’t get mad at the computer.