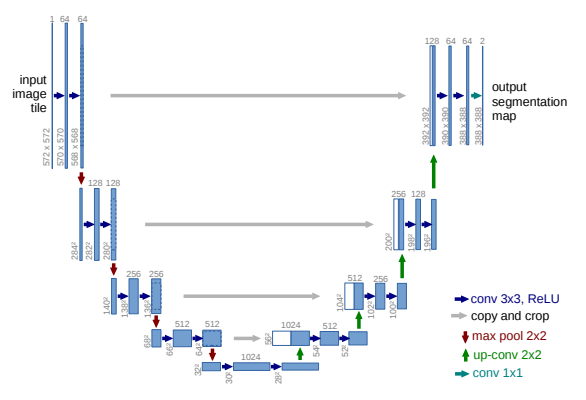
- Segmentation 테스크를 수행하는 모델 중 하나
- Biomedical 에 사용하기 위해서 만들어짐
- U-Net은 End-to-End 방식의 Fully-Convolutional Network(=FCN)를 기반으로 한 모델
Introduction
-
CNN classification 분야의 큰 발전을 가져옴

-
보통 CNN 은 1가지 label 이 있는 classification task 에서 사용이 되었는데, biomedical image 처리에서는 각 pixel이 라벨링 되어있는 localization이 포함이 되어 있어야 했다.(biomedical image는 한 이미지 안에 여러개의 세포가 들어있기 때문) -> so, sliding-window 방법을 사용했다.

-
sliding-window 방법을 사용해서 픽셀과 픽셀 주변의 영역을 받아 픽셀에 담긴 정보가 어떤 객체를 나타내는건지 판단하는 방식을 사용 -> 학습 데이터가 이미지 단위가 아닌 이미지 속 일부가 한 단위(patch)가 되기 때문에 데이터셋이 더 다양해진다
-
sliding-window의 문제점

1) 검증이 완료된 patch에 대해 중복해서 다음 patch를 검증하기 때문에 학습되는 속도가 매우 느리다.
2) localization의 정확도와 context(이미지 내의 정보를 인식하는 정도)의 trade-off관계가 있었다. patch를 키울수록 max-pooling layer가 많이 필요하기 때문에 localization의 정확도가 낮아지고(더 넓은 범위의 이미지를 한 번에 인식할 수 있어 context 파악에 큰 효과가 있지만 넓은 범위를 인식하게 되므로 localization의 정확도에서는 성능이 떨어지게 됨), 반대로 patch의 사이즈를 줄이면 context가 낮아진다.
- sliding-window 해결방안 -> FCN(Fully Convolution Network)을 발전시킨 모델 제시
모델의 main idea - U-Net은 매우 적은 수의 훈련 이미지로 작동하고 보다 정확한 segmentation을 생성했다.
- pooling 연산자가 upsampling 연산자로 대체되어 해상도를 높였다.->Expansive Path
- localize를 시키기 위해서는 각 단계별로 추출된 높은 해상도의 features와 upsampled된 output을 결합했다. 이런 식의 구조로 인해 convolution layer들이 정보를 더 정확하게 학습할 수 있게 된다.
U-Net 구조의 특징
- upsampling을 하는 부분에서도 channel이 많은 feature를 사용->higher resolution layer에 context information을 전파함 => U자 모양의 모델
- FCN(Fully Connected Layers) 사용 X
overlap-tile strategy 사용
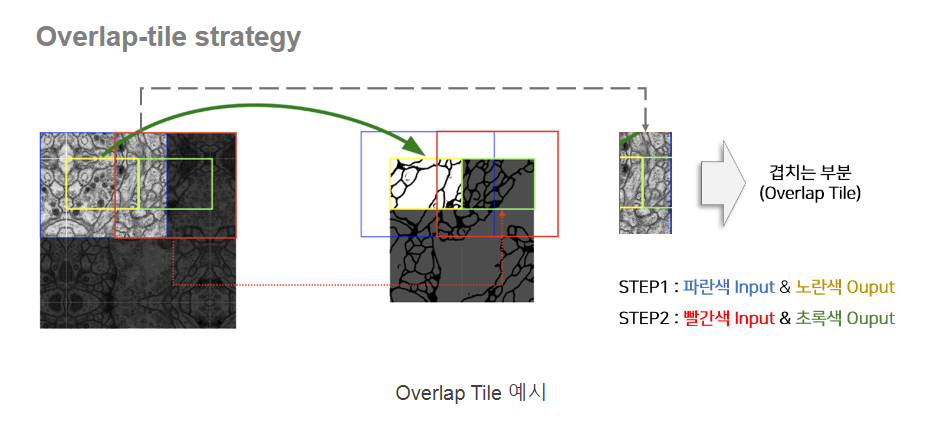
이미지의 크기가 큰 경우 이미지를 자른 후 각 이미지에 해당하는 Segmentation을 진행해야 합니다. U-Net은 Input과 Output의 이미지 크기가 다르기 때문에 위 그림에서 처럼 파란색 영역을 Input으로 넣으면 노란색 영역이 Output으로 추출됩니다. 동일하게 초록색 영역을 Segmentation하기 위해서는 빨간색 영역을 모델의 Input으로 사용해야 합니다. 즉 겹치는 부분이 존재하도록 이미지를 자르고 Segmentation하기 때문에 Overlap Tile 전략이라고 논문에서는 지칭합니다.경계 영역의 픽셀을 예측하려면 이미지의 누락된 context는 입력 이미지를 미러링하여 외삽됩니다. overlap-tile strategy 네트워크를 큰 이미지에 적용하는 데 중요합니다.
- training data 가 적기 때문에 augmentation 사용 -> elastic deformation augmentation 적용
- 많은 cell segmentation tasks는 동일한 class의 접촉하는 개체를 분리하는 것이다. -> 세포가 여러개 붙어있어 구분이 힘들다. => 세포 사이를 구분하는 것에 높은 가중치를 둔 loss function으로 이를 구현함
Network Architecture
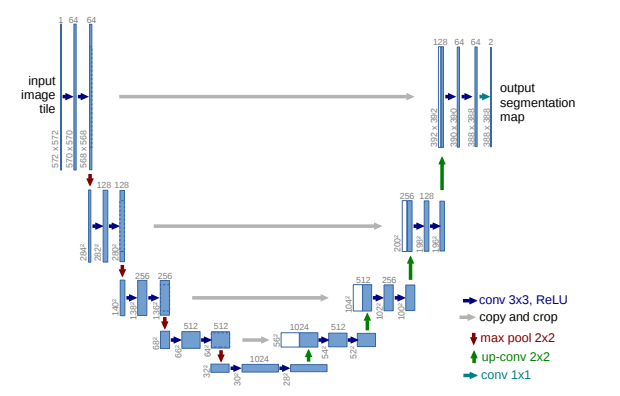
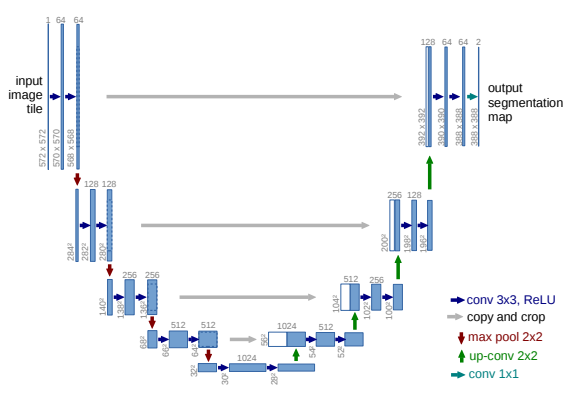
Contraction Path + Expansive Path 로 이루어짐
1. Contraction Path 특징 (Downsampling)
- Convolution network 수행 -> fully connected layer 사용 x
- 두 번의 3x3 convolution 후, Relu 사용
- 한 번의 2x2 max-pooling(stride 2), down-sampling 시에는 2배의 feature channel 적용
- Expansive Path(Upsampling)
- Down-sampling을 수행하는 max-pooling layer 대신 Up convolution layer로 치환
- 두 번의 3x3 convolution 후, Relu 사용
- Contraction Path에서 추출된 feature map을 가져와 부착(중앙부분을 crop한 featuremap->가장 부분이 손실되는 것을 방지하기 위해서)
- 마지막에는 1x1 convolution을 두어 마지막에 cell, membrane을 구분함 -> 최종적으로 판단할 class 개수가 2개임.
Training
- SGD(Stochastic Gradient Descent) 사용
- Unpadded convolution 때문에 output 이미지의 사이즈가 input 사이즈보다 작다.->GPU메모리를 최대한 활용하기 위해 batch 크기를 키우는 것 보다는 input의 tile를 키우는 것이 좋다.
- momentum값은 0.99로 사용하기 때문에 이전 샘플이 현재 샘플을 optimize하는데 큰 영향을 준다.
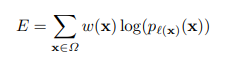
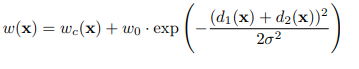
-> energy function : 마지막에 얻은 feature map 에 픽셀 단위로 soft-max를 수행하고, 여기에 cross entropy loss function을 적용한 식
x -> feature map에 있는 각 픽셀
w(x) -> weight map (픽셀 별로 가중치를 부과하는 역할)
d1 -> 가장 가까운 클래스의 테두리와의 거리
d2 -> 두 번째로 가까운 클래스의 테두리와의 거리- weight map 의 효과
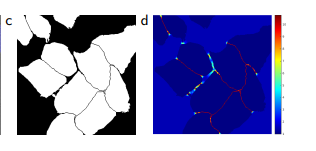
세포 사이에 간격이 촘촘한 경우, 이런 간격을 구분하는 학습을 하도록 만들어준다. - 깊은 신경망에서는 다양한 cnn layer와 path가 존재하기 때문에 초기값은 매우 중요
U-Net의 가중치는 헌 뉴런에 들어오는 노드의 개수를 N이라고 하면 root(2/N)의 표준 편차를 가진 가우시안 분포를 이용해 가중치를 초기화 합니다. 예를 들어 3X3 CNN에 channel = 64인 feature map이 들어오면 해당 CNN의 N = 9x64 = 576 이다.
Data Augmentation
- 학습 데이터가 부족할 때 모델이 invariance하고 robustness하게 학습되기 위해서는 augmentation이 필수이다.
- 현미경 등으로 촬영하는 사진들(microscopical image)은 색깔이 다양하지 않고 회색빛깔로 이루어져있고 객체간 구별도 선명하지 않기 때문에 Data Augmentation을 이용해 풍부한 데이터셋을 만드는게 더욱 필요하다.
Experiments
모델의 성능을 평가하기 위하여 EM Segmentation challenge의 Dataset을 활용한다. EM Segmentation challenge Dataset은 30개의 Training 데이터를 제공한다. 각 데이터는 이미지와 함께 객체와 배경이 구분된(0 or 1) Ground Truth Segmentation Map을 포함하고 있다.
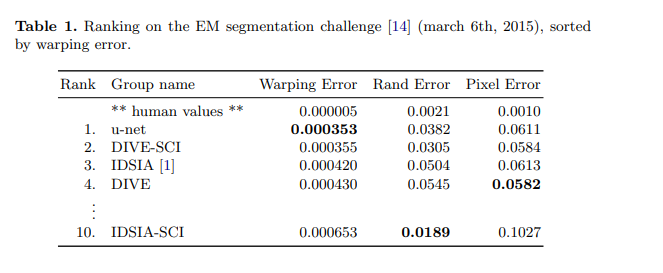
- Warping Error : 객체 분할 및 병합이 잘 되었는지 세크멘테이션과 관련된 에러
Warping Error를 기준으로 “EM Segmentation” 데이터에서 U-Net 모델이 가장 좋은 성능을 보이고 있다.
세포 분류 대회인 ISBI cell tracking challeng 에서 모델의 성능을 평가한 표
“PhC-U373” 데이터는 위상차 현미경으로 기록한 35개의 이미지를 Training 데이터로 제공한다.
“DIC-HeLa” 데이터는 HeLa 세포를 현미경을 통해 기록하고 20개의 이미지를 Training 데이터로 제공한다.
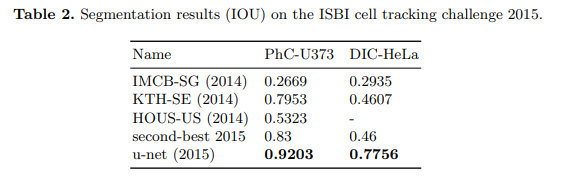
- U-Net 모델은 “PhC-U373” 데이터에서 92% IOU Score를 획득하였으며 2등 모델이 획득한 점수 83% 와 현격한 차이를 보이고 있다.
- U-Net 모델은 “DIC-HeLa” 데이터에서 77.5% IOU Score를 획득하였으며 2등 모델이 획득한 점수 46% 와 현격한 차이를 보이고 있다.
Conclusion
- U-Net은 biomedical segmentation에서 좋은 성능을 보여준다.
- elastic deformation이 포함된 Data augmentation 덕분에 적은 사이즈의 데이터셋만 요구하고 합리적인 학습 시간(NVidia Titan GPU (6 GB)에서 10시간 학습)을 가진다.
