Neural Machine Translation
- 한 언어에서 다른 언어로 단어를 번역하는 데 사용되는 소프트웨어이다.

conditional probability 직접 계산 가능
x=source
y=target- NMT는 Neural Network를 사용하여 순차적으로 등장하는 데이터인 sequence input을 넣었을 때, sequence 결과물이 출력된다.
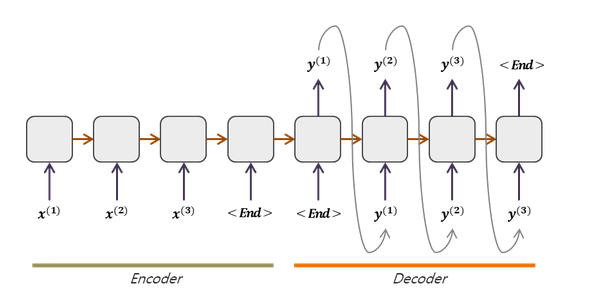
- Encoder-Decoder 2개의 RNN(or LSTM,GRU)을 이어붙인 Sequence-to-Sequence 모델의 기본형태
Seq2Seq 모델 구조
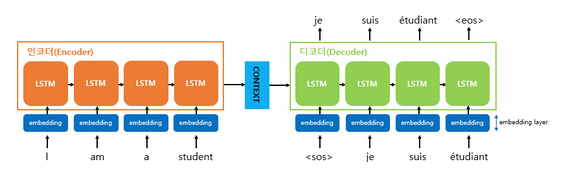
- Encoder-Decoder model 이라고도 불림
- encoder : 입력문장의 모든 단어들을 순차적으로 입력받은 뒤에 마지막에 이 모든 단어 정보들을 압축해서 하나의 'context vector'로 변환
- decoder : 'contect vector'를 받아서 번역된 단어를 한개씩 순차적으로 출력- 입력된 sequecne로부터 다른 도메인의 sequence를 출력하는 다양한 분야에서 사용되는 모델
-> Encoder
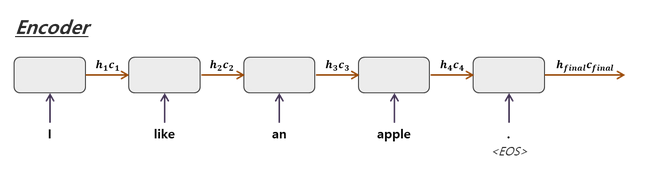
- 인코더는 source sentence를 인코딩함
- 인코더 LSTM 셀은 모든 단어를 입력받은 뒤에 인코더 LSTM 셀의 마지막 시점의 은닉 상태를 디코더 LSTM 셀로 넘겨줌->context vector가 디코더의 첫번째 hidden 셀에 들어간다
- 입력 시퀀스가 종료하면 <EOS>,<END> 등으로 표기함
- LSTM 이기 때문에 hidden state와 cell state가 나옴
-> Decoder
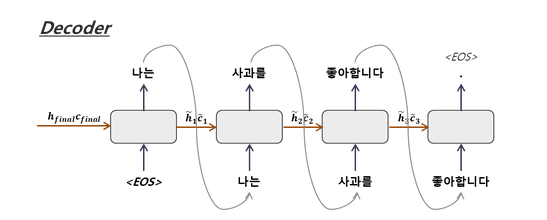
- 인코딩을 condition으로 target sentence 를 생성하는 language model
- 디코더의 첫 시작은 인코더의 종료표기인 <EOS>,<END> 등으로 시작함->두 번째 LSTM의 입력값으로 이용
- 시퀀스의 끝인 <EOS>에 도달할 때까지 진행
- Train : Target sentence의 timestep별 word가 다음 timestep의 word를 예측하기 위한 입력으로 사용됨- Test : Decoder RNN의 timestep 별 output이 다음 timestep의 입력으로 사용됨
디코딩 과정에서 단어를 선택하는 방법
softmax를 통해 확률값을 취해준 뒤 가장 높은 확률을 가진 단어를 선택하는 방법(Greedy Search)와 가장 좋은 방법이 나올 수 있는 모든 경우의 수를 고려한 뒤 누적확률이 높은 경우를 선택하는 방법(Beam Search) 이 있다.
1. Greedy Search
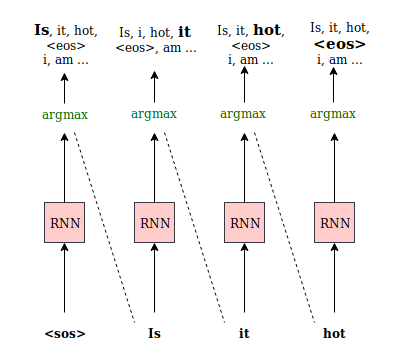
- Fully connect layer를 통과한 결과에 softmax를 취하여 가장 높은 확률을 가지는 단어 한개를 선택
- 단어 한개만 선택 가능하기 때문에 부자연스러운 문장이 생성될 수 있다.
- Beam Search
greedy search를 사용하면 높은 확률 값의 단어가 정확한 단어를 예측한 게 아닐 수도 있음
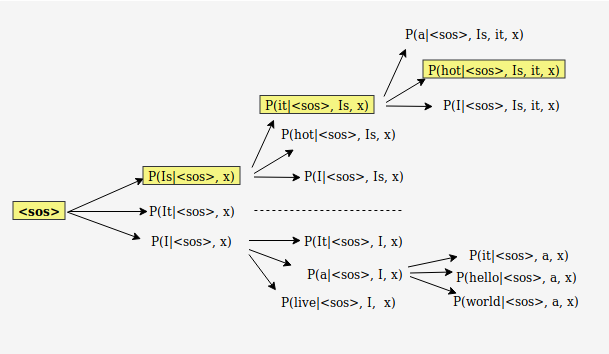
Algorithm
1) 각 step에서 각각의 후보 시퀀스를 모든 가능한 다음 step으로 확장
2) 확장된 후보 step에 대해 점수를 계산하는데, 점수는 모든 확률 값을 곱하여 얻음
3) 가능도가 높은 k개의 시퀀스만 남기고, 나머지 후보들은 삭제
4) 시퀀스가 끝날 때까지 반복
-> 시퀀스의 끝 판별
- <eos> 토큰 등장
- 설정한 최대 길이 도달
- threshold likelihood 밑으로 가능도가 낮아짐- 매번 하나의 출력값이 아닌 Beam 개수(k)만큼 출력값을 내놓도록 하여 다양성을 주고 마지막에 가장 좋은 sequence가 무엇인지 판단하도록 하는 방법
- 가장 낮은 Blue numbers 선택->성능평가지표
성능을 높이는 방법
- Seq2Seq with Attention->후에 포스팅
- Teacher-Forcing 기법
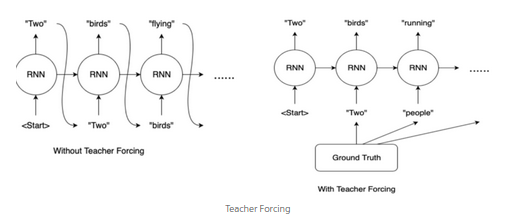
- 모델 학습 시 Decoder에서 실제 정답 데이터를 사용할 비율을 설정하는 하이퍼파라미터
- Encoder 과정에서는 Label을 알고 있기 때문에 입력에 참 값을 넣어 학습하지만, Decoder 과정에서는 참값을 알 수 없기 때문에 예측값이 잘못되었을 때 다음 input값에 예측값을 넣으면 잘못된 결과가 나온다.so, 예측값을 그대로 넣어주는 게 아니라 Ground TRuth 값을 넣어줌
- 높게 설정할수록 빠른 학습이 가능해지지만, 너무 높으면 overfitting 문제 발생
참고자료
https://towardsdatascience.com/word-sequence-decoding-in-seq2seq-architectures-d102000344ad
https://yjjo.tistory.com/35
https://blog.naver.com/PostView.naver?blogId=sooftware&logNo=221790750668
https://eliza-dukim.tistory.com/36
https://littlefoxdiary.tistory.com/4
