
Week 6
Day 01
강의 복습 내용
[CV]
What is Computer Vision?
컴퓨터 비전은 기계의 시각에 해당하는 부분을 연구하는 컴퓨터 과학의 최신 연구 분야이다. 인간의 시각이 할 수 있는 몇 가지 일을 수행하는 자율적인 시스템을 만드는 것을 목표로 한다.
컴퓨터 비전에는 Image, Semantic segmentation, Object detection & segmentation, Panoptic Segmentation이 있다.
Image Classification
전세계의 모든 데이터를 갖고 있다면 KNN을 사용해서 Classifiy를 해도 되지만 검색의 시간, 데이터의 용량이 O(n) 만큼 사용되기 때문에 이는 매우 비효율적이다. 이에 대한 대안으로 Neural Network를 사용해 보자!
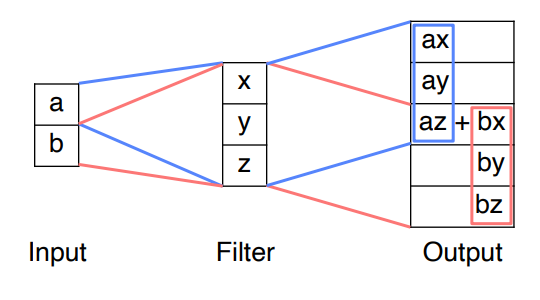
Fully Connected Network는 모든 픽셀들을 서로 다른 가중치로 내적하는 과정을 거친다. 하지만 이러한 과정은 평균 이미지 밖에 표현이 되지 않고, cropped image와 같은 경우에 학습이 안된다는 단점이 있다. CNN을 사용함으로서 이를 해결할 수 있다.
AlexNet
- 7개의 layer가 있음
- Relu 사용
- GPU의 용량 부족으로 2개로 나뉨
- LRN 사용하지 않음 (현재는 Batch Normalization을 사용)
VGGNet
- 3 X 3 필터를 사용해서 깊이를 증가 시킴
- 2 X 2 pooling을 함 (overfitting 방지)
- 일반화가 잘됨
과제 정리
피어세션 정리 및 학습 회고
Day 02
강의 복습 내용
[]
과제 정리
피어세션 정리 및 학습 회고
Day 03
강의 복습 내용
[Image Clasification]
신경망이 더 깊을 수록 복잡한 관계 학습이 가능하게 된다. 그렇게 되면 신경망을 무작정 깊게 쌓아도 될까??
깊은 신경망일수록 최적화하기가 어려워진다.
- Gradient vanishing / exploding -> Batch Norm을 적용해주면 해결된다
- 계산이 복잡해진다
overfittingDegradation problem
[네트워크를 깊게 쌓기 위한 모델들]
GoogLeNet
Inception Module의 구조를 제한했음. 하나의 레이어에 여러 측면으로 activation을 관찰한다. 깊이 확장이 아닌 수평 확장함. 하지만 이렇게 되면 계산 복잡도가 매우 높아지기 때문에 (1 X 1) convolution을 사용하여 메모리 사이즈와 계산에 이득을 가져오게함.
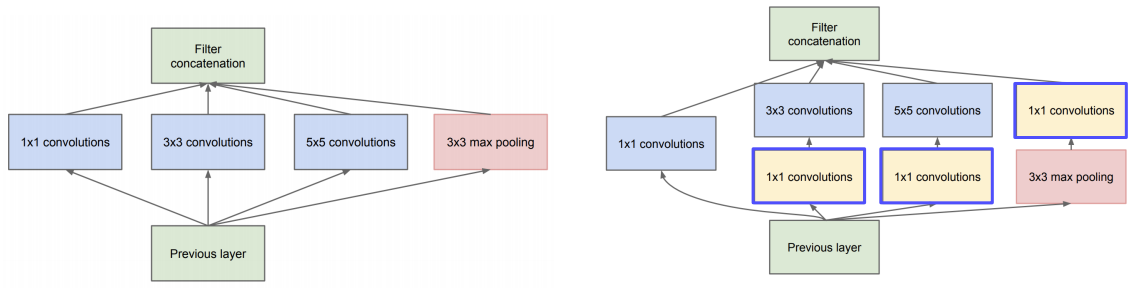
1X1 Convolution 장점
- Channel 수 조절
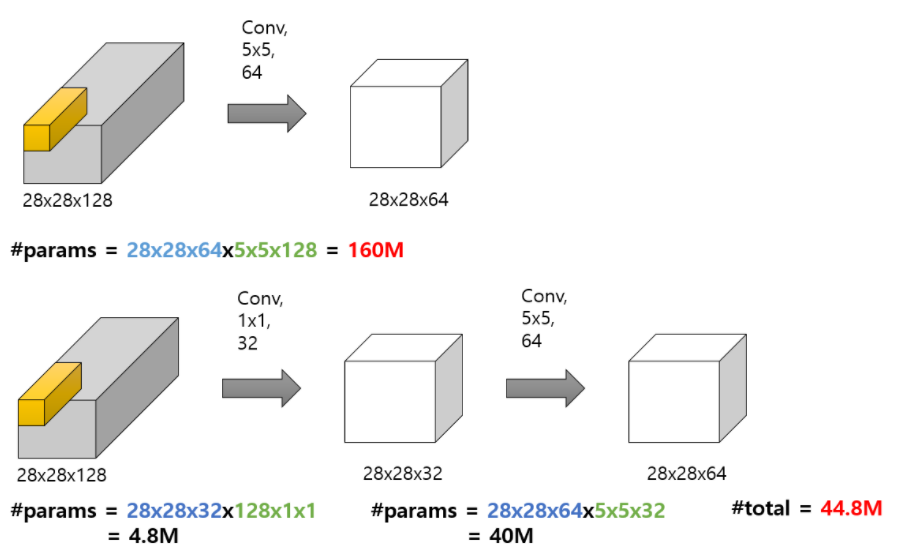
1x1 Conv을 통해 채널 수를 우리가 원하는 만큼 결정할 수 있다. 큰 채널 수를 사용하게 되면 파라미터 수가 급격히 증가하기 때문에 이를 예방하기 위해 1x1을 통해 조절이 가능하다 - 계산량 감소
채널 수 조절은 직접적으로 계산량 감소로 이어지게 된다. 또한 네트워크를 구성할 때 좀 더 깊게 구성할 수 있도록 도와준다.
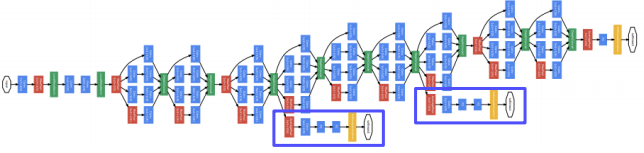
Auxiliary classifiers를 중간에 사용하여 Back Propagation이 사라지는 것을 막는다. 중간의 결과값으로 loss를 구하는 과정을 거치기 때문에 결과적으로 처음 시작 과정까지 loss가 전달된다. Auxiliary classifier는 학습 도중에만 사용이되고 실제 테스트 과정에서는 빠진다.
ResNet
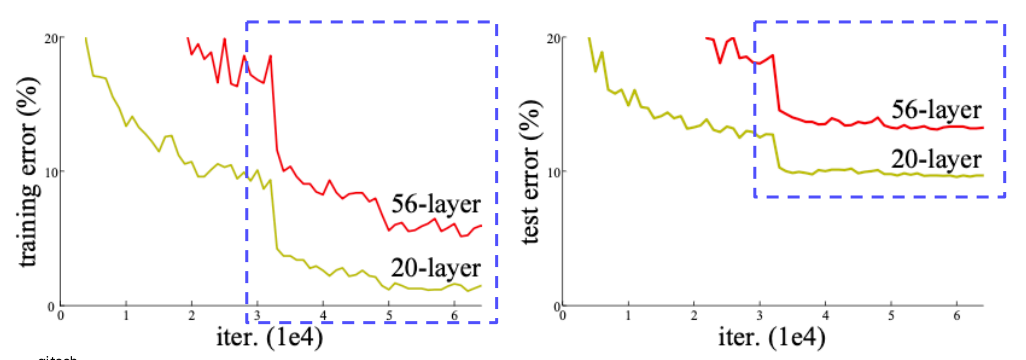
최초로 더 깊은 레이어를 쌓을 수록 더 좋은 성능이 나오는 것을 증명한 논문이다. 논문의 주요 내용은 네트워크의 레이어가 성능에 중요점이라는 것이다.
이전에는 레이어가 깊으면 파라미터가 많아져 오버피팅이 심해질 것이라고 예상했다. 하지만 아래의 사진을 보면 20-layer보다 56-layer의 정확도가 낮은걸 봐서는 오버피팅이 설명되지 않는다. 이는 Degradation problem이라고 하며 최적화 문제로 인해 56-layer가 학습이 안된것이다.
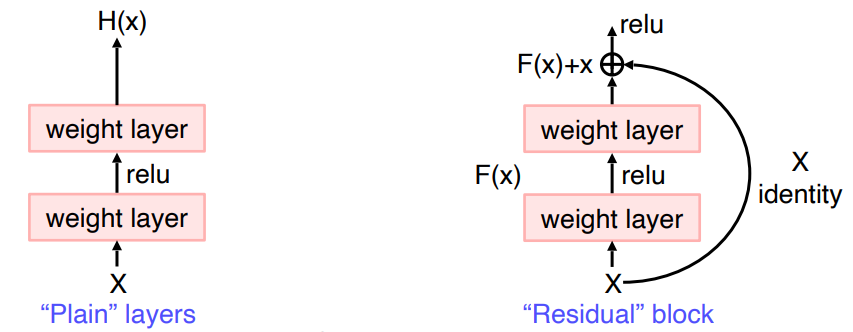
위 문제를 해결하기 위한 방법은 "Residual learning"이다.
(입력이 들어오고 출력이 나오면 입력을 출력에 더한다. (제약조건:입력과 출력의 차원이 같아야된다) F(x)는 입력과 결과값의 차이만 학습한다. -> 왜 좋냐? 가정을 세우고 해봤더니 잘됬다...!)
기존의 네트워크를 H(x)라고 할때, F(x) = H(x) - x로 네트워크를 변형시켜 F(x)+x를 H(x)에 근사하도록 학습하는 것이다. 이렇게 되면 레이어에 대해서 입력과 출력의 차이에 대해서 degradation problem을 해결 할 수 있다는 것이다. 이런 개념을 사용한 것이 "Shortcut connection"이다. Shortcut으로 gradient vanishing을 막을 수 있다.
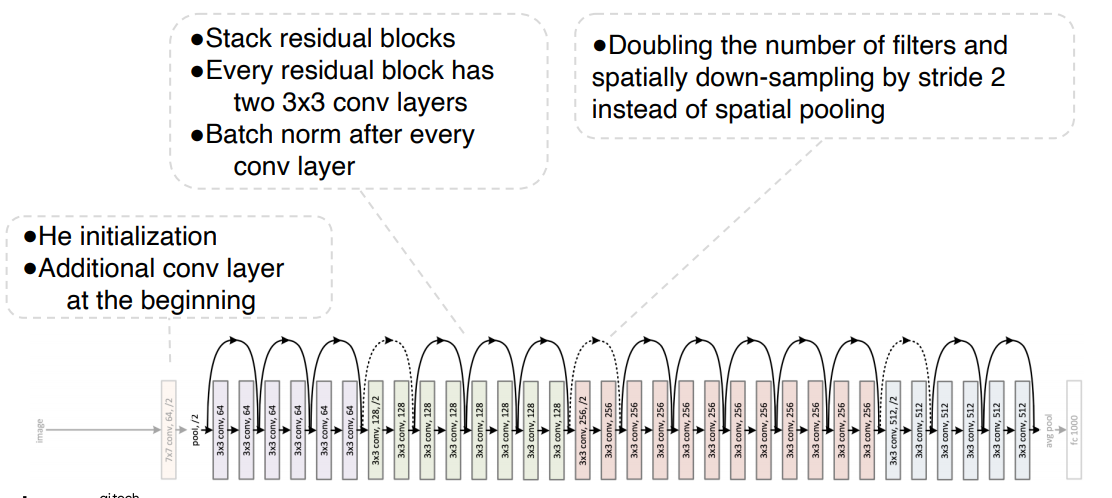
ResNet의 전체적인 구조
DenseNet
채널 축으로 concatenate함. 바로 직전 블록 뿐만 아니라 이전의 레이어과 연결함으로서 이전의 특징들을 참조해서 더 복잡한 학습이 용이하도록 도와준다.
SENet
Activation간의 관계가 더 명확하게 할 수 있도록 채널간의 관계를 모델링, 중요도를 파악해서 attention하는 구조. Squeeze 단계에서 avearage pooling을 통해 각 채널의 분포를 구함. Excitation에서는 채널간의 연관성을 고려해 attention score를 구함. 입력 attention하고 weight을 rescale함
EfficientNet
Width, Depth, Resolution scaling을 적절한 비율로 합쳐서 고안한 모델.
Deformable Convolution
기존 CNN 모델은 고정된 구조만을 사용했지만 Deformable Conv는 좀 더 유연한 영역에서 특징을 추출하는 방법을 제안한다.
Offset을 계산하는 conv layer와 offset 정보를 받아 conv 연산을 수행해 output feture map을 생성한다.
과제 정리
피어세션 정리 및 학습 회고
Day 04
강의 복습 내용
[Semantic Segmentation]
- 픽셀 단위로 분류
- 하나의 픽셀이 어디에 속하는지 구분하는 문제 (같은 클래스의 서로 다른 물체는 구분 못함)
Fully Convolution Networks (FCN)
Image Classification은 출력층이 Fully-connected layer로 구성되어있다. 네트워크의 입력층에서 중간까지 ConvNet을 이용하여 영상의 특징들을 추출하고 출력층에서 fc를 통해 분류한다. 반면 Semantic Segmenation에서 fc를 사용하게 되면 이미지의 위치 정보, 입력 이미지의 크기 고정의 한계가 있다. 이를 보완하기위해 fc를 Conv-layer로 대체한다.
Semantic 모델이 가능해지지만 이러면 굉장히 작은 output이 나오게 된다 (stride와 pooling으로 인해 해상도가 낮아지지만 receptive field가 매우 커져서 좋음). Output을 원래 입력 사이즈로 맞추기 위해 Upsampling을 시도한다.
그렇다면 Upsampling을 통해 해상도를 복구할 수 있을까??? Network에서 Low level은 지역적이고 자세한 정보가 있는 반면, High level은 의미론적인 정보를 갖고있다. 두 특징들을 합치면 어떨까?? 중간 단계의 특징들을 합치면 더 좋은 결과가 나옴! (Skip Connections)
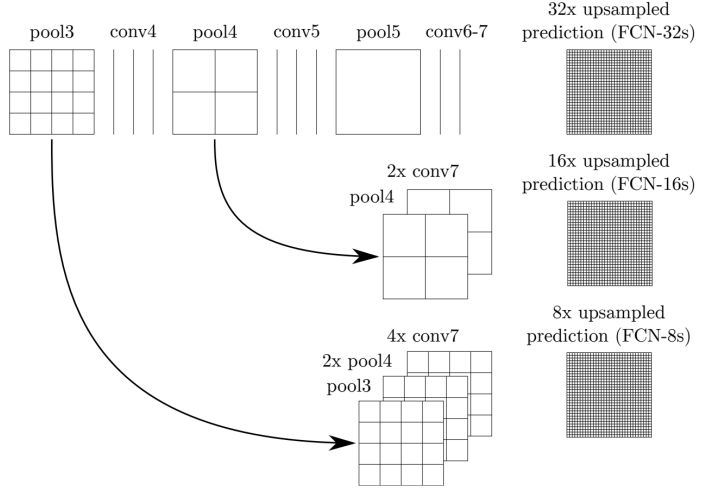
Upsampling
Receptive field를 최대한 키우고 나서, 원래의 입력 사이즈를 맞추기 위해 Upsampling을 사용한다.
- Transposed convolution
중첩이 계속 되면???
- Upsampling and convolution
U-Net
- FCN과 비슷
- Similar to skip connections
- 더 정교함
- Contracting Path : 일반적인 CNN과 동일함. 채널 수 늘리고 해상도 떨어짐
- Expanding Path : 채널 줄이고 해상도 높아짐. 한번에 upsampling, 대칭으로 대응하는 activation map을 사용
- Concatenation of feature maps provides localized information
DeepLab
CRF : 후처리로 사용되는 툴
Dilated(Atrous) Convolution : Weight 사이를 한칸씩 건더 뛰어 더 넓은 영역을 고려함
과제 정리
피어세션 정리 및 학습 회고
Day 05
강의 복습 내용
[Object Detection]
Instance Segmentation : 같은 클래스라도 객체가 다르면 구분
Panoptic Segmentation : Instance + 배경 정보 + 알파
Object Detection
- classification + box localization (class, Xmin, Ymin, Xmax, Ymax)
Gradient-based Detector(HOG)
- 영상의 경계선의 특징으로 모델링 하면 되겠다! (픽셀의 변화량의 각도와 크기를 고려하여 feature를 추출)
- 사람의 직관을 통한 알고리즘 설계
- SVM을 통해 물체를 판별
Selective Search
- 다양한 물체 후보군에 대해서 영역을 특정해서 제안 (Box proposal)
- 비슷한 색끼리 분할 (Over segmentation)
- 비슷한 영역 합침 -> 바운딩 박스를 추출 -> 물체의 후보군으로 사용
Two-stage detector
R-CNN
- Selective Search와 같이 region proposal을 구함
- CNN input에 적절한 사이즈로 warp
- Trained된 CNN에 넣어 카테고리를 분류함 (마지막의 FC레이어만 학습을 함)
- 각각의 Region propsal을 CNN에 넣어야 되기 때문에 속도가 느림
- Region Proposal은 별도의 알고리즘이기 때문에 학습을 통한 성능 향상에 한계
- wraping하는 과정에서 input 이미지 정보의 손실
- 학습이 여러 단계이기 때문에 느림
Fast R-CNN
- 영상 전체에 대한 feature를 한번에 추출하고 이를 재활용
- Conv feature map을 뽑는다, feature map에서 RoI를 찾는다
- RoI pooling layer : ROI에 해당하는 feature를 추출 후 resize
- bounding box regression, classification 을 수행
- feature만 재활용 했는데 R-CNN보다 빠름
- 하지만 별도의 알고리즘을 사용하기 때문에 학습을 통한 성능 향상에 한계
Bounding Box regression : 예측하는 박스가 ground truth와 유사하도록 학습
Faster R-CNN
- End to end object detection
- IoU(Intersection over Union) = Area of Overlap / Area of Union
- Anchor boxes : 비율과 스케일이 다른 영역을 각 위치마다 지정한 박스
- Region Proposal Network(RPN)
- Feature map 관점에서 매 위치마다 K개의 적당한 Anchor box를 고려
- 2K classification score
- 4k coordinates (왜 다시 뽑음??? 더 정교하게 찾기 위함)
- 영상으로 부터 feature map을 미리 뽑아
- RPN에서 여러개를 제안
- RoI pooling을 실시
- Non Maximum Suppression (NMS)
- 필요한 바운딩 박스만 남기도록
Single-stage detector
정확도를 포기하고 속도를 확보해서 real time detection. ROI pooling을 사용하지 않고 곧 바로 box regression, classification을 수행함
- RoI가 없으므로 모든 영역에서 loss가 발생함 -> class imbalance 문제 발생 / 정확도 낮아짐
- Focal loss (Cross entropy의 확장) : 정답에 가까운거는 gradient가 무시되고, 잘못 판단된 곳에는 강한 weight를 둔다
You Only look once (YOLO)
Input image를 SxS(마지막 layer의 해상도) grid로 나누고, 각 그리드에 4개의 좌표와 confidence score를 예측하고 결과에 따라 class score를 예측한다.
Single Shot MultiBox Detector (SSD)
Multi scale object를 더 잘 처리하기 위해서 중간 feature map을 각 해상도에 적절한 bounding box를 출력할 수 있도록 한다.
- Vgg를 backbone
- 각 scale 마다 object detection 결과를 출력하도록 함으로서 다양한 scale의 object에 잘 대응
RetinaNet
Focal loss의 효과를 입증하기 위해 간단한 dense dector 모델. Single stage detector의 단점인 class 불균형 문제를 해결.
- Feature Pyramid Networks(FPN)
각 추출 된 결과들인 low/high resolution들을 묶는 방식이다. 이미 계산 된 특징을 재사용 하므로 멀티 스케일 특징들을 효율적으로 사용할 수 있다. - Class, Box가 따로 구성되어있어 classification, box regression을 자세히 함
DETR
Transformer를 object detection에 활용한 사례
- CNN과 position encoding으로 부터 입력 토큰 생성
- transformer encoder -> (object queries) -> transformer decoder
과제 정리
피어세션 정리 및 학습 회고
