Background
Transfer learning
- Data가 부족한 상황이거나 수집하는 데 많은 비용이 드는 경우에서 Model 구축을 위해 Data가 풍부한 분야에서 훈련된 Model을 재사용하는 학습 기법을 의미한다.
Catastrophic forgetting
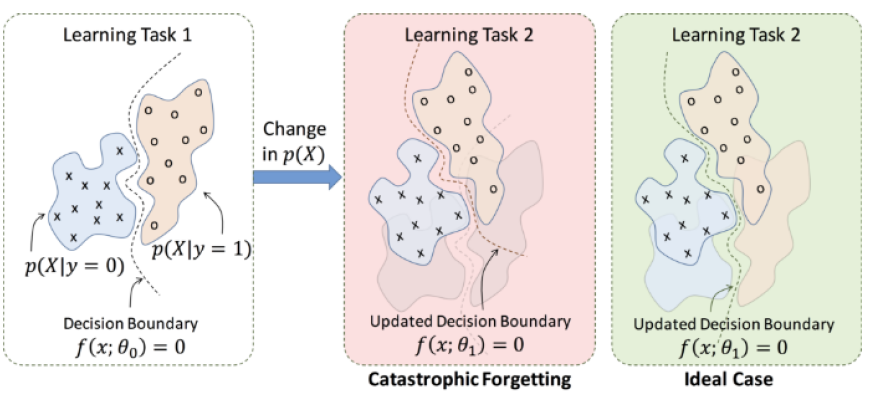
- Transfer learning을 진행하는 과정에서 Neural network가 다른 종류의 Task를 학습하면 이전에 학습했던 Task에 대한 성능이 감소하는 현상이다.
Continual learning
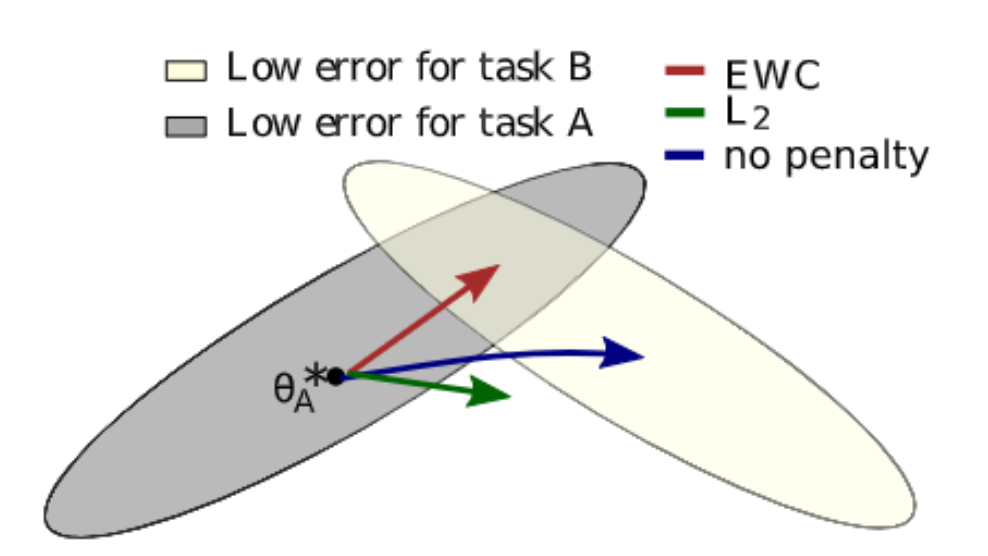
- 획득한 지식을 점진적으로 확장하고 미래 학습에 사용하는 것을 목표로 무한한 데이터 스트림에서 학습하는 것을 Continual learning이라고 한다. 이를 위한 방법론으로 Regularization, Dynamic Structure, Memory 기반의 방법들이 있으며 본 논문에서는 Regularization 기반의 방법론 중 대표적인 방법론인 EWC(Elastic Weight Consolidation)을 알아볼 것이다.
Motivation
-
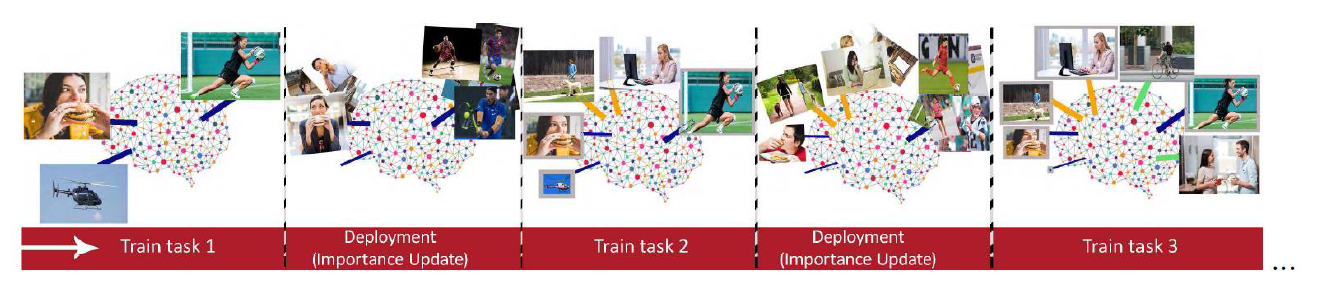
기존의 Continual learning은 두가지 Task 사이에서 수행되거나, 용량, 시간 등이 여유로운 상황에서의 학습이 수행되었다. 하지만, Real-world에서는 제한된 환경에서 여러가지 Task가 계속해서 주어지는 상황을 커버해야 한다.
-
따라서, 본 논문에서는 이전 Task들에 대해 Model이 전부 기억하려고 하기보다는 덜 중요한 정보는 잊고 중요한 정보는 보존하는 방식을 제안한다. 즉, Network의 parameter weight들의 Importance를 계산하고 계산된 중요도를 기반으로 Regularization term을 통해 중요한 Weight의 갱신을 방지한다.
Proposed Method
Importance weight
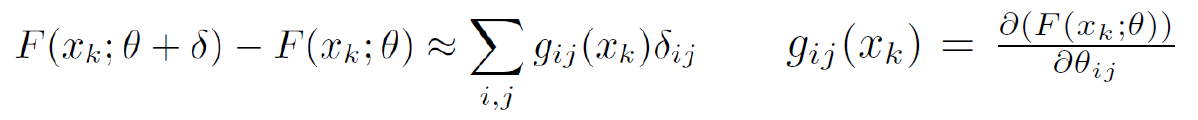
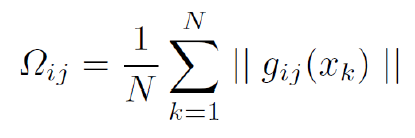
-
Importance weight는 network의 parameter 변화에 대한 학습된 function의 민감도를 나타낸 것으로 모든 data point에서 parameter에 대한 Output function의 변화량의 평균을 뜻한다. 즉, network의 parameter가 변할 때 learned function 대비 Output function이 크게 변하면 해당 parameter에 높은 중요도를 부여한다.
-
Importance weight를 계산할 때, output function이 multi-dimension인 경우 계산해야 하는 Gradient가 많아지게 되므로 learned function의 output에 L2 norm을 취하여 n(length of output vector)배 빠른 계산을 수행하게 한다.
Regularization
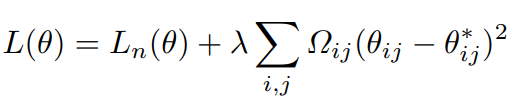
- n번째 task의 학습에 대해 loss function은 다음과 같이 정의된다. 높은 중요도를 가진 weight는 기존 parameter에서 크게 변하지 못하게 하고, 낮은 중요도를 가진 weight는 기존 parameter에서 크게 변하는 것을 허용한다.
Experiments
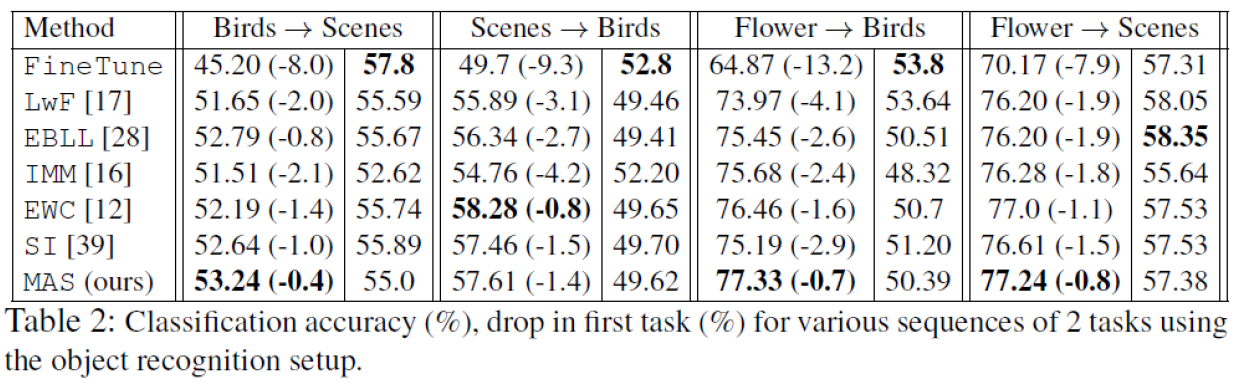
- ImageNet으로 Pretrain한 AlexNet을 기반으로 실험을 진행 하였으며 여러 Task를 수행한 뒤, Performance drop을 관찰하였다.
- 3가지 Task에서 FineTune method의 최종 성능이 가장 좋게 측정되었는데, 이는 FineTune method의 특징에 기인한 것으로 생각된다. 본 논문에서 제안한 MAS Method는 최종 Task의 성능은 다른 Method보다 낮은 경우가 있지만 이전 Task의 Performance drop이 가장 적다는 점에서 Continual learning이 지향하는 학습 방향대로 학습이 이루어진다고 할 수 있다.
Conclusion
- Longer sequence에서 Continual learning을 수행하였으며, Loss function을 도입하여 Loss를 최소화시키는 방식의 학습이 아닌 모델은 하나의 Function으로 근하사여 Importance weight를 계산하는 과정에 label이 필요하지않은 장점이 있다.

Researcher