언어모델이란?
자연언어란?
- 인간의 언어
- 정보전달의 수단이자 인간 고유의 능력으로 인공언어에 대응되는 개념
언어모델의 정의
- 언어를 이루는 구성 요소(글자, 형태소, 단어, 단어열(문장), 문단 등)에 확률값을 부여하여 이를 바탕으로 다음 구성 요소를 예측하거나 생성하는 모델
- 단어 시퀀스에 확률을 할당(assign)
=> 언어모델은 가장 자연스러운 단어 시퀀스를 찾거나 문맥 정보를 이해하는 모델
언어모델의 종류 및 특징
전통적인 언어모델
통계기반 언어모델
- 통계적 언어 모델은 단어열이 가지는 확률 분포를 기반으로 각 단어의 조합을 예측하는 전통적인 언어 모델
=> 실제로 많이 사용하는 단어열(문장)의 분포를 정확하게 근사하는 것 - 주어진 단어를 바탕으로 다음 단어로 올 확률이 가장 높은 단어를 예측하는 일련의 과정을 의미
=> 언어 현상에 조건부 확률 적용

딥러닝 기반 언어모델
- 퍼셉트론을 기반으로한 인공 신경망 설계를 통해 단어의 의미적 유사성을 학습할 수 있도록 설계
=> ‘문맥’을 반영. 기존의 희소성 문제를 완화 - 학습 코퍼스에 없어도, 문맥을 참고하여 보다 정확한 예측
- 피드 포워드 신경망 -> 순환 신경망 -> Transformer
영향력
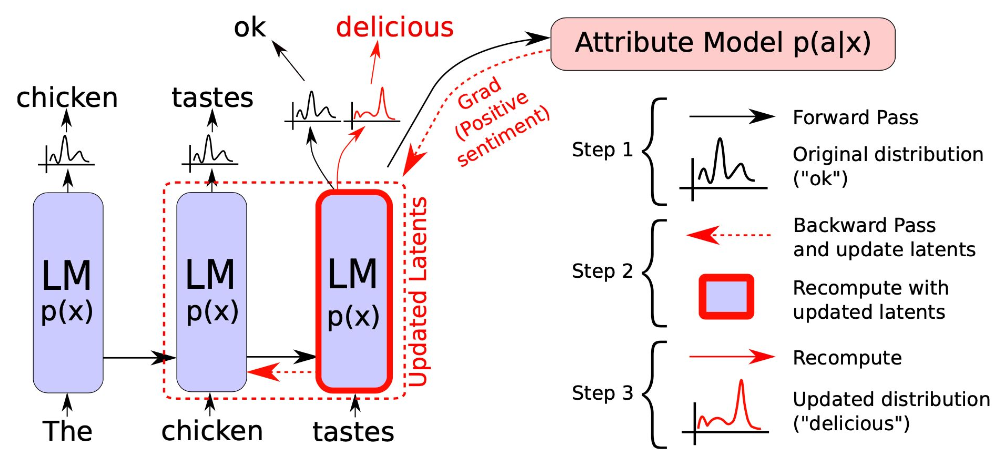
Transformer의 등장 이후로 NLP연구의 메인 트렌드
- Encoder만 사용하는 BERT family
- Decoder만 사용하는 GPT family
- Encoder-Decoder(Seq2Seq)구조를 가지는 BART family, Transformer-XL family 등
Encoder vs Decoder
Encoder:
각 stage에 어텐션 레이어가 초기 문장의 모든 단어에 접근 가능
=> Encoder 모델은 전체 문장의 이해를 요구하는 task에 가장 적합
Decoder:
각 stage에서 문장 내에서 주어진 단어의 앞쪽만 접근가능
=> Decoder 모델은 텍스트 생성과 관련 task에 가장 적합
Encoder의 대표 모델
BERT (Bidirectional Encoder Representations from Transformers)
- Contextual Embedding
- Masked Language Modeling(MLM): 마스킹된 토큰을 예측
- Next Sentence Prediction(NSP): 문장이 다른 문장과 이어질 확률을 예측
RoBERTa (Robustly optimized BERT approach)
- 더 긴 시퀀스, 많은 훈련 데이터로 더 큰 배치에서 오래 학습
- NSP 없이 Dynamic Masking 적용
=> 성능이 크게 향상
Decoder의 대표 모델
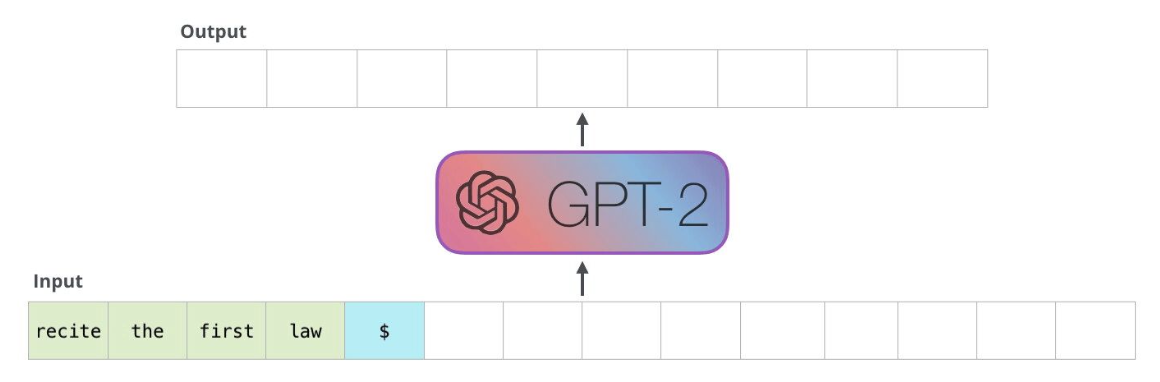
GPT (Generative Pre-trained Transformer)
- Auto-Regressive
- 주어진 Input을 기반으로 다음에 올 토큰을 예측
=> 시퀀스의 한쪽만 참고
- 추가적인 fine tuning 없이도 자체적으로 충분히 좋은 성능
=> Few-shot / Zero-shot의 등장

Sequence-to-Sequence의 대표 모델
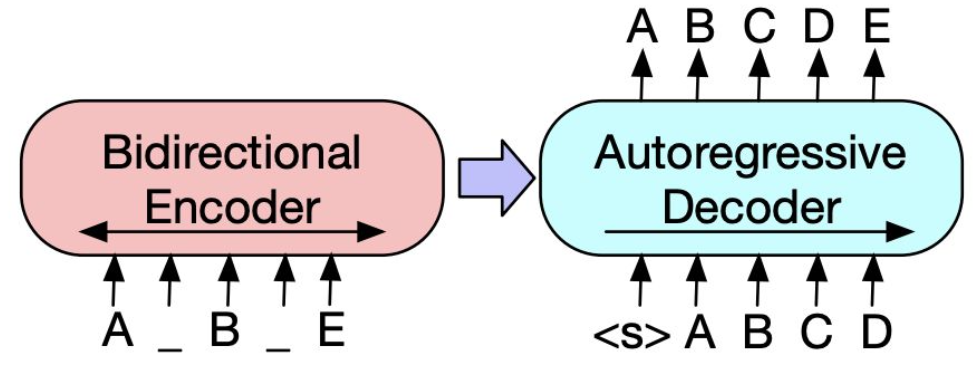
BART (Bidirectional Auto-Regressive Transformer)
- Encoder와 Decoder를 모두 사용한 사전학습 모델
- Encoder에서 input을 입력 받아 표현형 벡터로 변환
=> Decoder에서 해당 벡터를 기반으로 다음 토큰을 생성
- 5가지 Denoising technique을 사용해 self-supervised learning으로 사전 학습
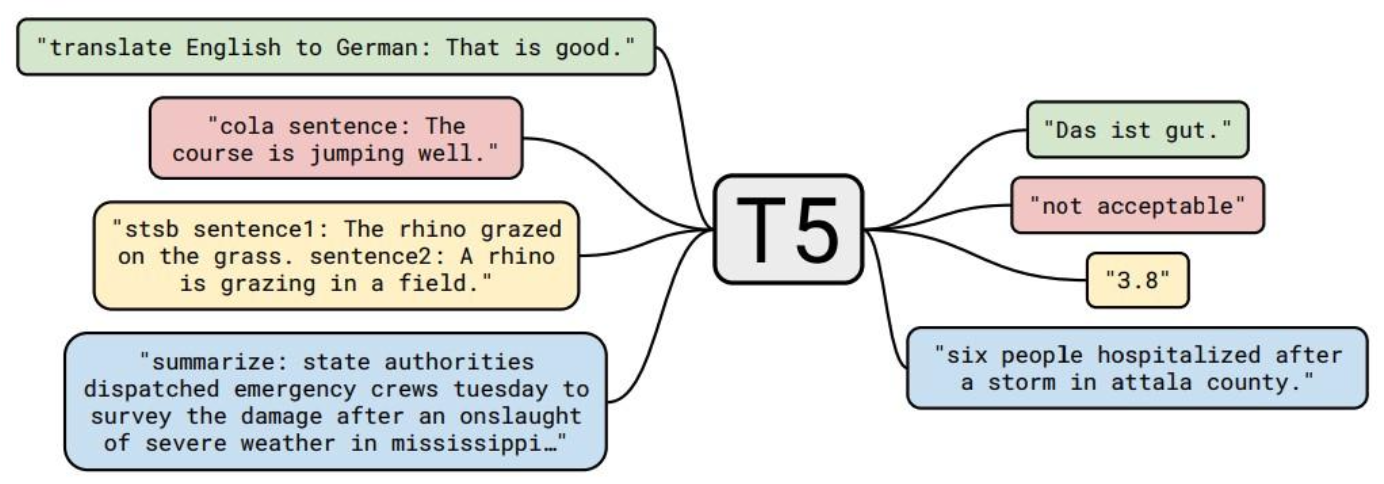
T5 (Text-to-Text Transfer Transformer)
- Text-to-text problem: input으로 text를 받아서, output으로 새로운 text를 생성하는 문제
- 다양한 text processing problem ⇒ Text-to-text 문제로 변형

Real Cryptocurrency Trader & AI Engineer LV.0