Sequence-to-sequence 이해하기
입력된 시퀀스(문장)을 다른 시퀀스로 변환하는 모델로, 인코더 RNN과 디코더 RNN로 구성
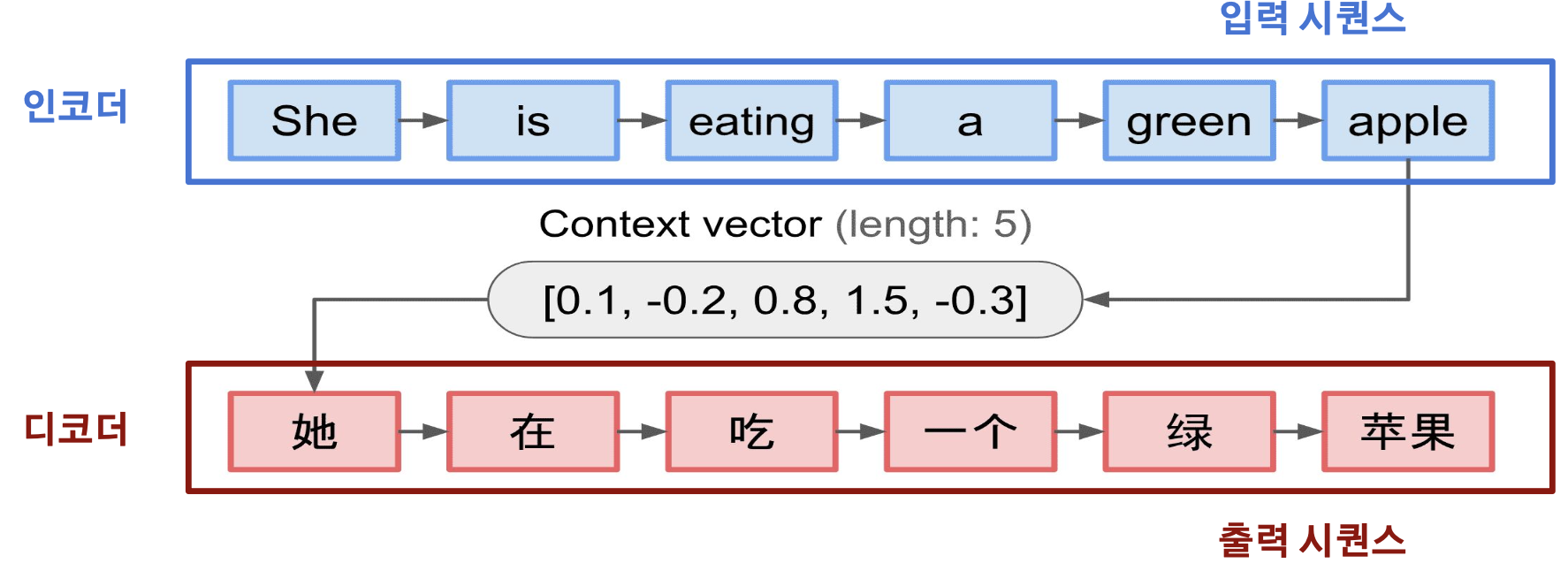
인코더 (Encoder)
: 입력 시퀀스를 받아들여 고정된 길이의 벡터로 변환함. 이 벡터는 입력 시퀀스의 정보를 압축적으로 담고 있음. 이 벡터를 문맥 벡터(context vector)라고 부름
디코더(Decoder)
: 문맥 벡터를 받아들여 출력 시퀀스를 생성
디코더는 문맥 벡터와 이전에 생성한 출력을 기반으로 다음 출력을 생성함
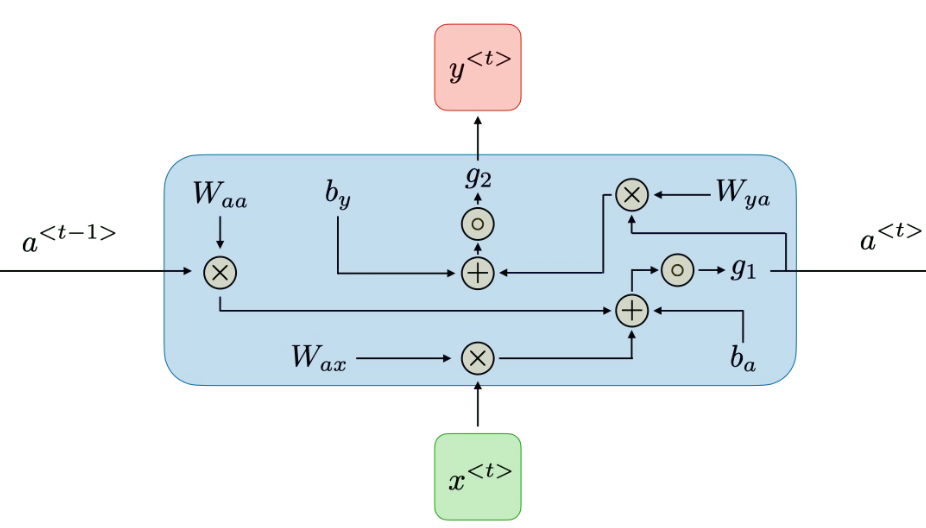
RNN 이해하기

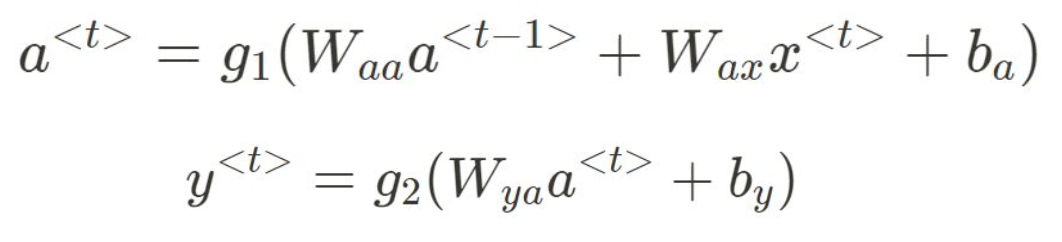
손실 함수 (Loss function)
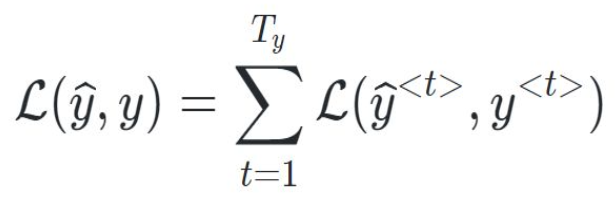
시간 순서 역전파 (Backpropagation through time)
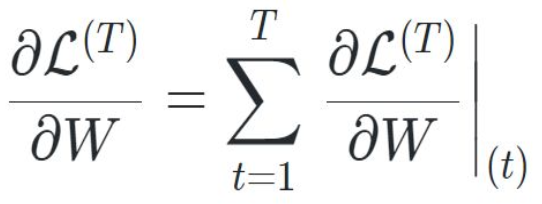
One-to-one: ex) 고양이, 강아지 분류
One-to-many:한 개의 입력으로 시퀀스 여러개 출력
many-to-one: ex) 감정분석
many-to-many: ex) 기계번역, 형태소 분석
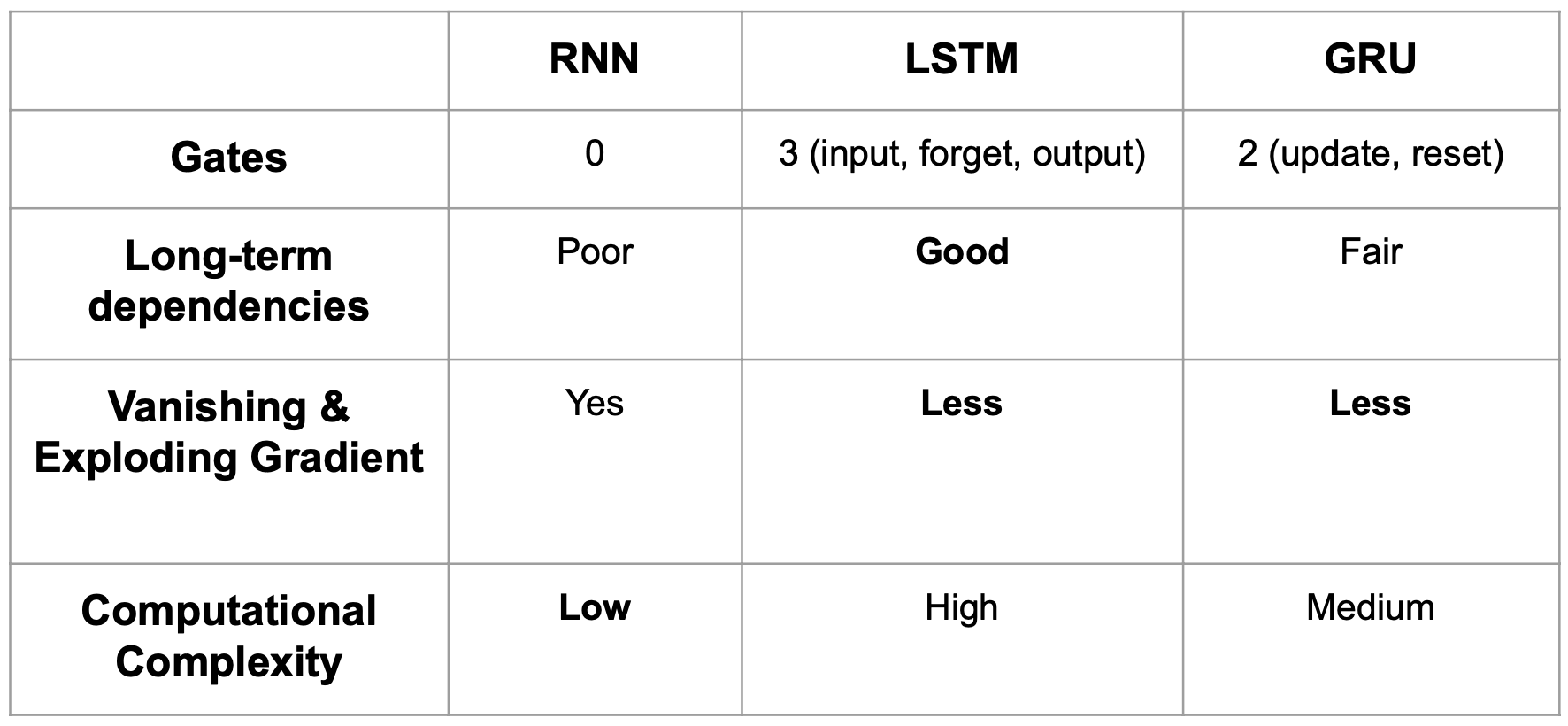
RNN의 장단점
장점
- 모든 길이의 시퀀스를 입력으로 처리 가능
- 시간에 따라 가중치를 공유하여, 입력 시퀀스가 길어져도 모델 크기가 증가하지 않음 • 과거 정보를 고려하여 다음 시간의 출력을 계산함
단점
- 매번 시간에 따라 출력을 계산하므로, 병렬 처리가 불가능하여 계산 속도가 느림
- 입력 혹은 출력 시퀀스가 길어지면 오래전 정보를 반영하기 어려움 (Long-term dependency)
- 현재 상태에 대한 미래 입력을 고려할 수 없음
LSTM & GRU 이해하기
Gradient vanishing / exploding
기존 RNN의 역전파 과정에서 그래디언트가 너무 작아져서(gradient vanishing) 가중치 업데이트가 잘 안 되거나, 그래디언트가 너무 커져서(gradient exploding) 가중치 값이 엄청나게 커지는 문제가 발생
- 이로 인해 모델이 불안정해지고, 시퀀스 데이터의 장기 의존성을 제대로 학습하지 못하게 됨
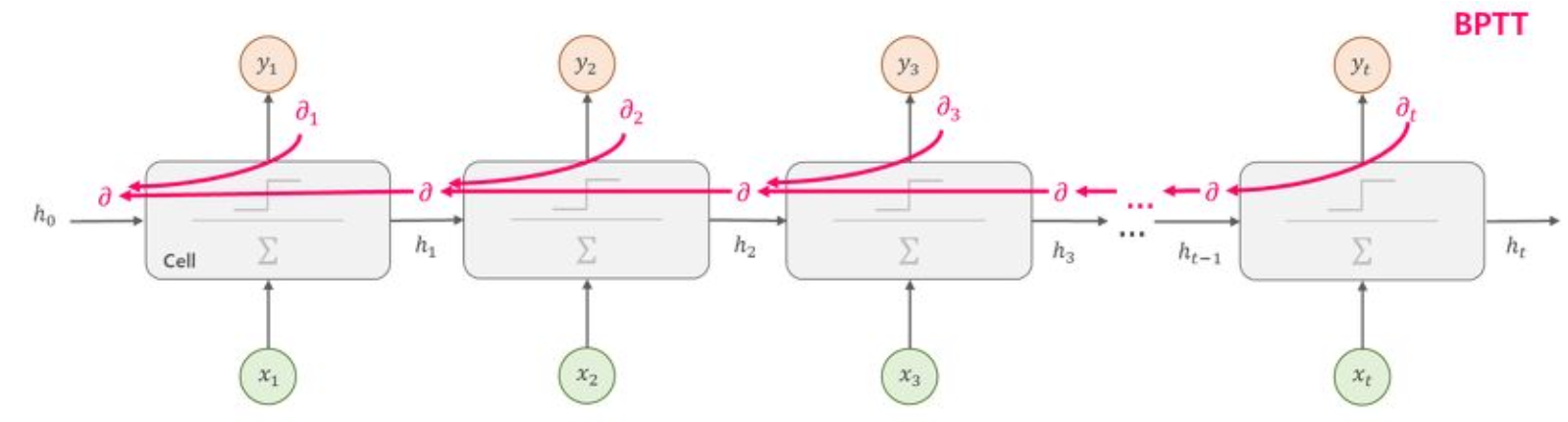
LSTM
RNN에서 발생하는 Long-term dependency problem 완화 방법으로 LSTM은 cell state와 gate라는 메커니즘을 도입
- 필요한 정보만을 선택적으로 업데이트하거나 삭제하는 방법을 도입 (정보를 잘 기억하고 활용)
sigmoid 활성화 함수
- 출력 값의 범위를 [0, 1]로 제한하여, 게이트에서 어떤 정보를 통과시킬지 결정하는 데 사용됨
현재 시간 단계에서의 cell state 후보
- 현재 입력과 이전 hidden state에 기반하여 계산됨
현재 시간 단계에서의 cell state
- forget gate가 결정한 대로 이전 cell state의 일부를 잊고, input gate가 결정한 대로 새로운 정보를 추가하여 업데이트됨
forget gate, input gate, output gate
- 이전 cell state의 어느 부분을 잊을지, 새로운 정보를 얼마나 추가할지, 어느 부분을 hidden state로 출력할지 결정
Forget gate
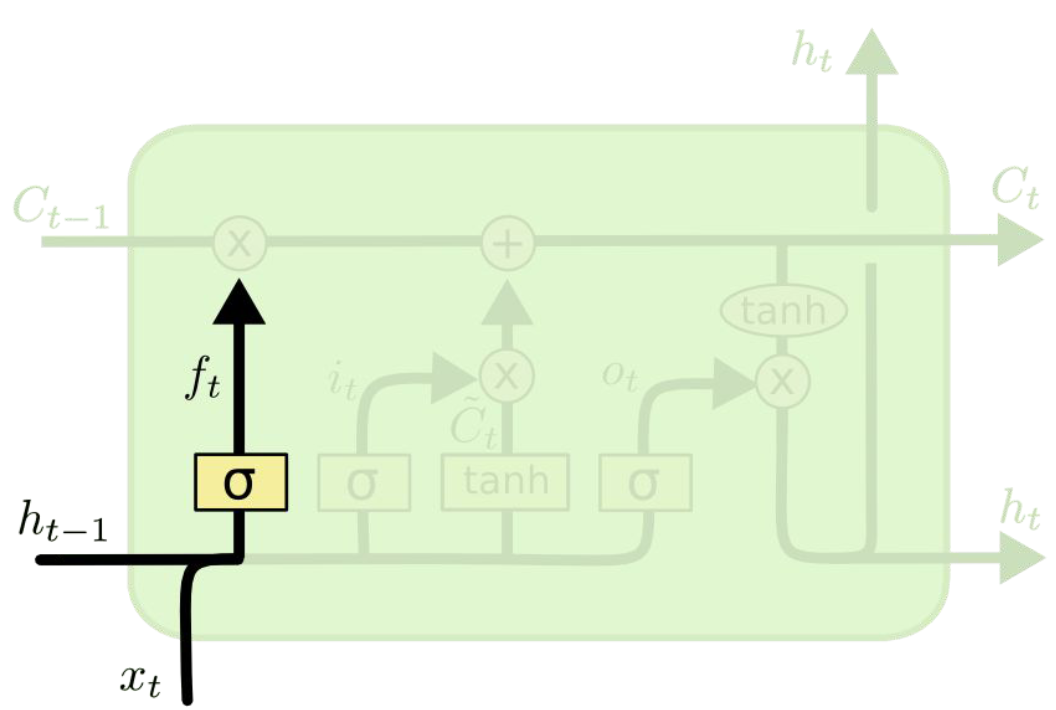
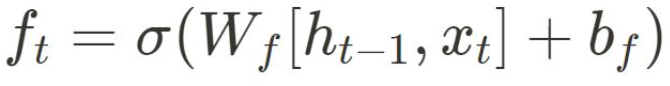
• forget gate layer로, 이전 cell state의 어느 정보를 버릴지 결정 Wf와 bf 는 학습 가능한 가중치와 편향
• 시그모이드 함수 sigmoid는 출력을 0과 1 사이로 제한하여 어떤 요소를 완전히 잊어버릴지(0) 또는 완전히 기억할지(1) 결정
Input gate
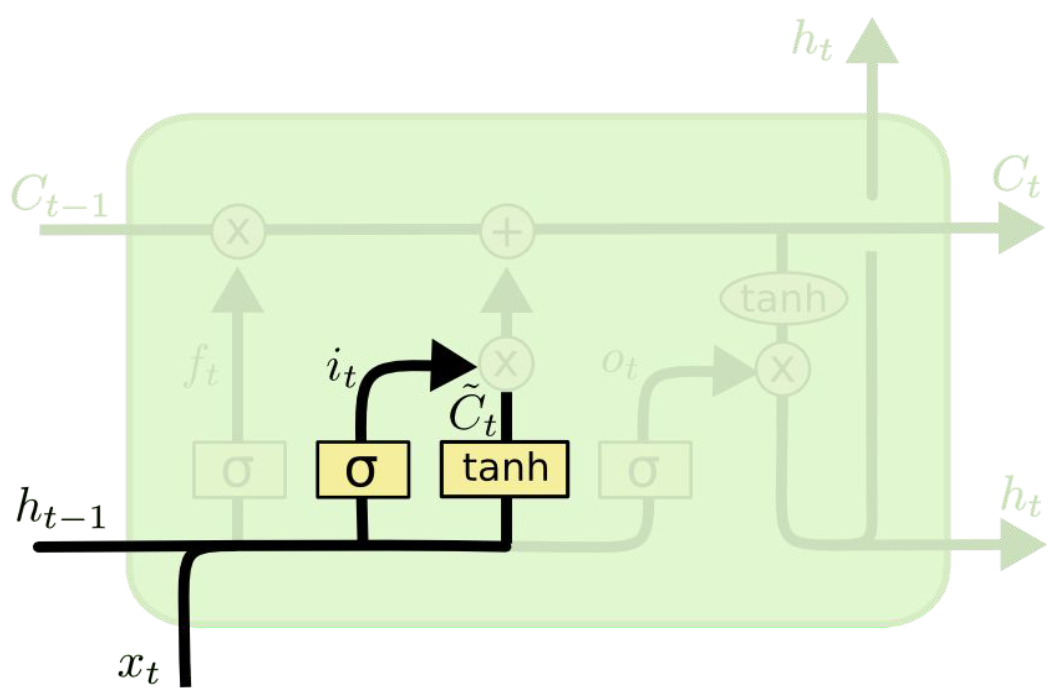
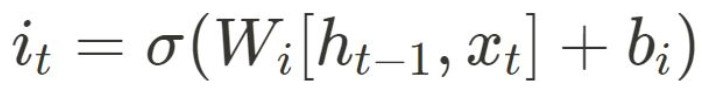
-
input gate layer로, 어떤 새로운 정보를 cell state에 저장할지 결정
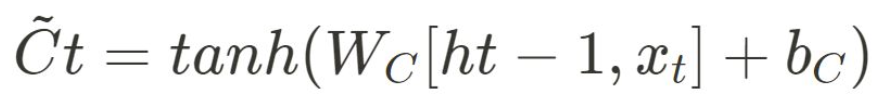
-
새로운 후보 cell state를 생성. 이후에 후보 cell state 정보 중 일부가 cell state에 저장
Cell state
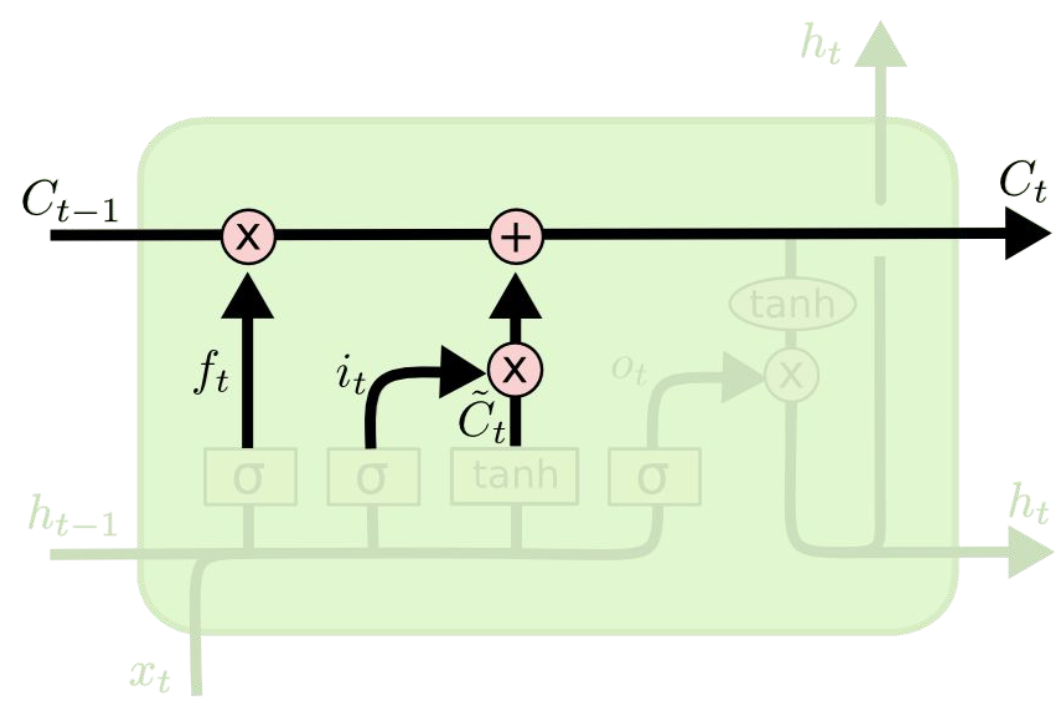
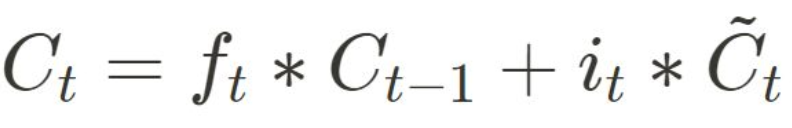
- cell state 업데이트로, 먼저 forget gate를 통해 결정된 정보를 잊어버린 다음, input gate에서 결정된 정보를 추가
Output gate
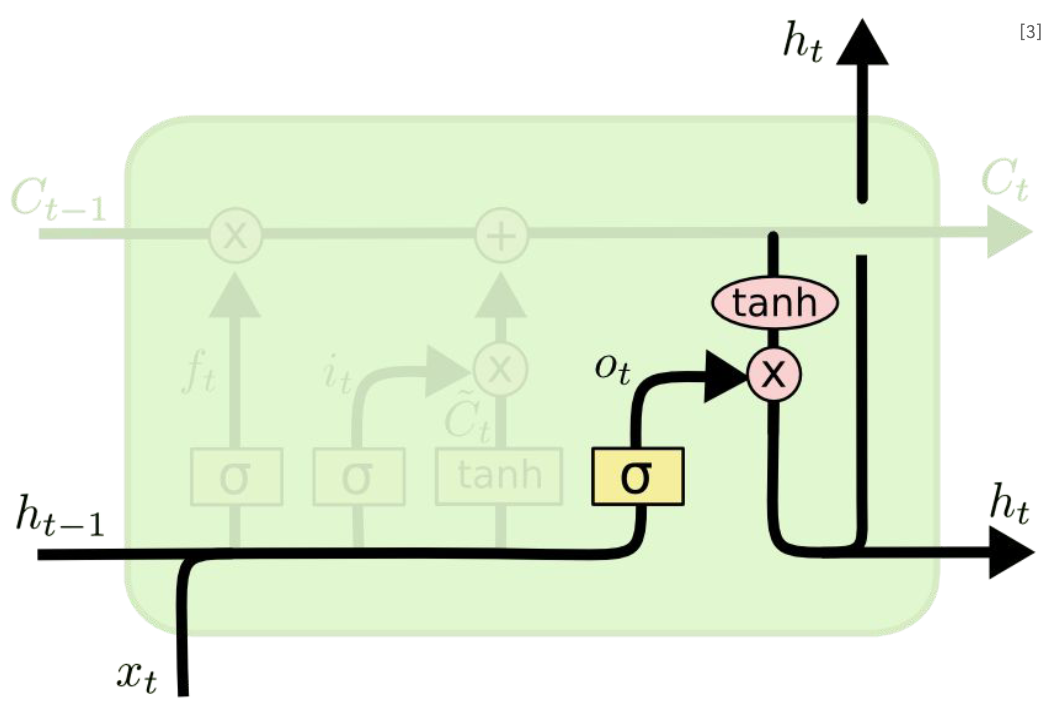
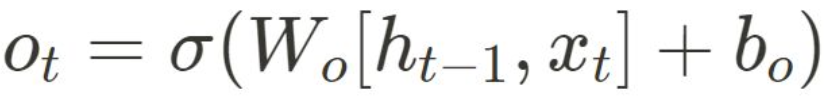
• output gate로, 다음 hidden state가 무엇을 출력해야 하는지 결정
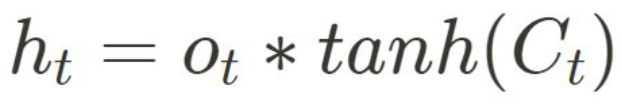
• output gate 값과 현재 시간단계의 cell state 값을 통해 현재 hidden state를 계산
GRU
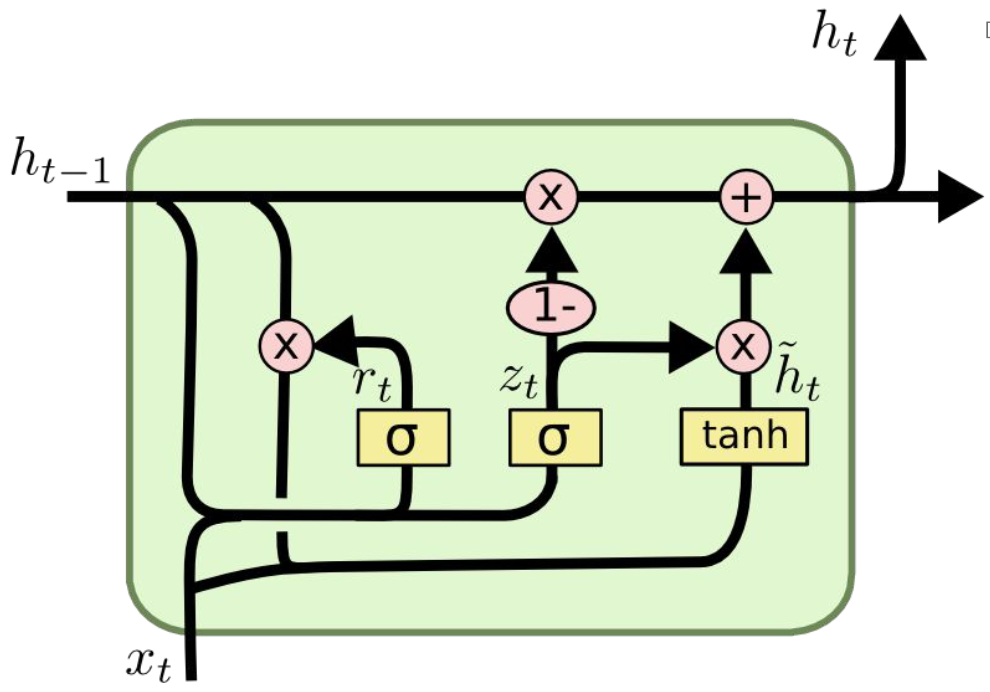
-
update gate로, 현재 hidden state를 얼마나 업데이트할지 결정
-
reset gate로, 이전 hidden state를 얼마나 '잊어버릴지' 결정
-
새로운 후보 hidden state를 계산
-
후보 hidden state를 통해, 현재 hidden state를 업데이트
RNN vs LSTM / GRU