Definition
한국말: 비슷한거끼리 묶어(주어진 데이터 X 사이의 유사한 데이터들을 묶어주는 방법)
서양언어: "clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar(in some sense) to each other than to those in other groups (clusters).
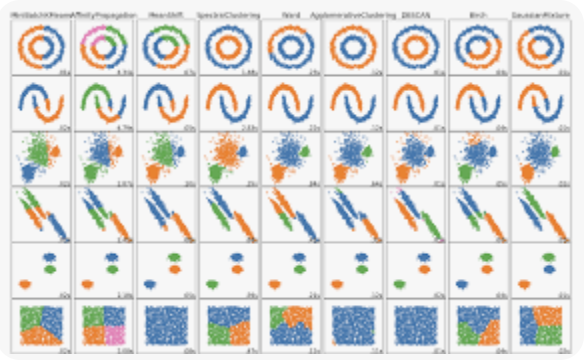
- input data는 벡터이며(feature vector), target value는 없음.
- target value가 없다보니, feature vector가 굉장히 중요 → feature engineering의 영향을 많이 받음
< 대표 model >
1. K-means
2. Hierarchical Agglomerative Clustering
3. DBSCAN
< 대표 예시 >
1. News Clustering(비슷한 뉴스기사 그룹)
2. Customer Segmentation(고객 집단이 어떻게 되는지) → 마케팅,추천시스템에서 많이 사용
< important point>
1. similarity meaure (어케 유사성 측정?)
2. data representation(어케 표현?)
3. grouping method (어케 묶냐?)
K-Means
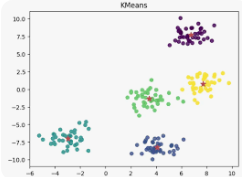
Definition
주어진 데이터에서 K개의 중심점을 찾아서 묶는 방법.
- 클러스터링 중 가장 대표적인 모델
- 1960s에 처음 제안되어 지금까지도 제일 많이 사용
- 평균(mean)을 기준으로 데이터들을 묶어줌
- 모델이 직관적이고 간단하며 빠름 + 결과가 부조건 나온다는 것이 보장(수렴성)
Algorithm
- 랜덤하게 K개의 데이터를 선택하여 기준(centroid)으로 정한다.
- 선택하지않은 모든 데이터에 대해서 선택한 K개의 (centroid) 중 가장 가까운 데이터(euclidean distance)를 찾는다.
- 가깝다고 정해진 데이터끼리 묶어서 새로운 클러스터를 만든다.
- 새롭게 구성된 클러스터에 속하는 데이터들의 평균을 구한다.
- 새로 계산한 평균을 새로운 K개의(centroid) 기준으로 정한다.
- 2번 과정부터 다시 반복한다.
- 새롭게 업데이트 되는 데이터가 없다면 종료한다.
ineritia: cluster의 중심 centroid로부터 클러스터 내 각 데이터 포인트까지의 거리의 제곱 합
Pros and Cons
- Pros
- 아주 빠름. 거의
- 모델의 수행원리가 간단해서 해석이 용이 → unsupervised learning들은 해석이 굉장히 중요!
(target value가 없으므로) - objective function이 convex라서 무조건 수렴. (언젠가 정답은 나온다!)
- Cons
- mean을 기준으로 하기 때문에 outlier에 굉장히 취약
- 데이터의 모양이 hyper-spherical이 아니라면 잘 묶이지 않음
- initial centroid를 어떻게 고르냐에 따라 성능이 천차만별로 바뀜
→ K-means++ (2007)가 이 문제를 어느정도 개선했음.(지금 sklearn 구현 모델) - K가 하이퍼파라미터(2차원 데이터면 판단가능한데 차원 늘어날 수록 직관적이지 않아 판단 힘듬)
→ K를 어떻게 해야 가장 좋은 성능이 나올 지 알 수 없음(일단은)
Hierarchical Agglomerative Clustering
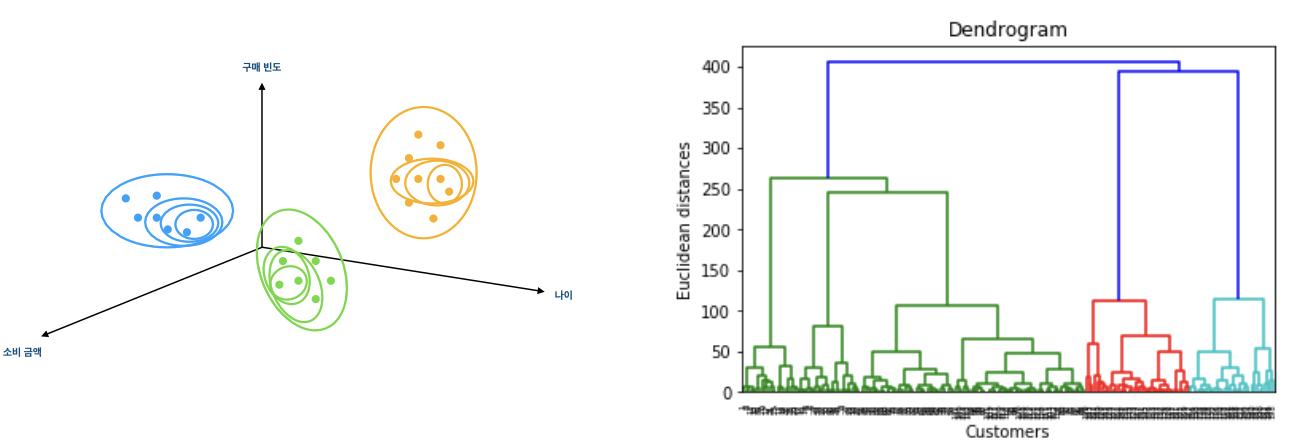
Definition
데이터의 계층 구조를 파악하는 클러스터링 방법
- HAC는 상향식 계층 클러스터링. 위의 그림처럼 아래부터 위로 점차 데이터를 묶어가기 때문.
- 위와 같은 그림을 Dendrogram이라 부름
- Dendrogram x축은 데이터 하나하나를 의미하고, y축은 유사도 (대부분 euclidean distance)를 나타냄
- 모든 데이터간 유사도를 계산해야하기 때문에 많이 느림.
Algorithm
- 모든 데이터를 각자 독립적인 클러스터로 세팅.(서로 다른 N개의 cluster label을 부여받음)
- 유사도(similarity)와 묶는 방식(linkage)을 정함.( 유사도는 euclidean distance, 묶는 방식은 single)
- 가장 유사도가 높은 2개의 클러스터를 고름
- 정해진 방식으로 묶는다. (single의 경우 가장 가가운 데이터의 pair가 포함된 두개의 클러스터를 합친다)
- 모든 데이터가 묶여서 하나의 클러스터가 될 때까지 3,4번 반복 , 모든 데이터가 묶이면 dendrogram 그릴 수 있음.
- dendrogram에서 특정 threshold(distance)를 기준으로 세로롤 잘랐을 때, 나뉘는 클러스터들을 최종 클러스터로 선정
가장 특징이 떨어져있는 것들이 맨 위에서 먼저 떨어짐 (물론 밑에서 시작하긴 하지만 결과만 놓고보면)
Pros and Cons
- Pros :
- 원하는 similarity와 linkage를 사용할 수 있어, 다양한 공간에서 다양한 형태의 클러스터를 찾을 수 있음.
- dendrogram을 이용하여 , 데이터에 따라 유연하게 최적의 클러스터 개수를 정할 수 있음.
- 어떤 linkage 방법을 사용하더라도, 하나씩 클러스터가 줄어들기 때문에 원하는 클러스터 개수를 찾을 수 있음.
- Cons :
- k-means에 비하면 매우 느림. 대용량 데이터에는 적합하지 않음.

Real Cryptocurrency Trader & AI Engineer LV.0