Feature selection
Feature selection의 중요성
- 학습에 필요한 변수를 중요도에 따라 선택하는 과정 (=모델 학습에 불필요한 변수를 생략하는 과정)
→ 변수의 중요도를 어떻게 정의하고, 평가할지에 따라 방법론이 나뉨 - 변수 선택을 시행하는 이유
- 차원의 저주 (Curse of Dimensionality) 해소 : 모델의 복잡도를 낮출 수 있음
- 차원의 저주 : 데이터의 차원이 학습 데이터 수보다 증가하면서 모델의 성능이 저하되는 현상
- 모델의 성능 향상 및 과적합(Overfitting) 완화
- 학습 및 추론시간, 메모리 개선
- 더 적은 변수들을 활용해 해석 가능성 증대
02 Feature selection의 방법
2.1 Overview
대표적인 변수선택의 3가지 접근법
-변수의 중요도를 평가하는 방법, 기준에 따라 분류
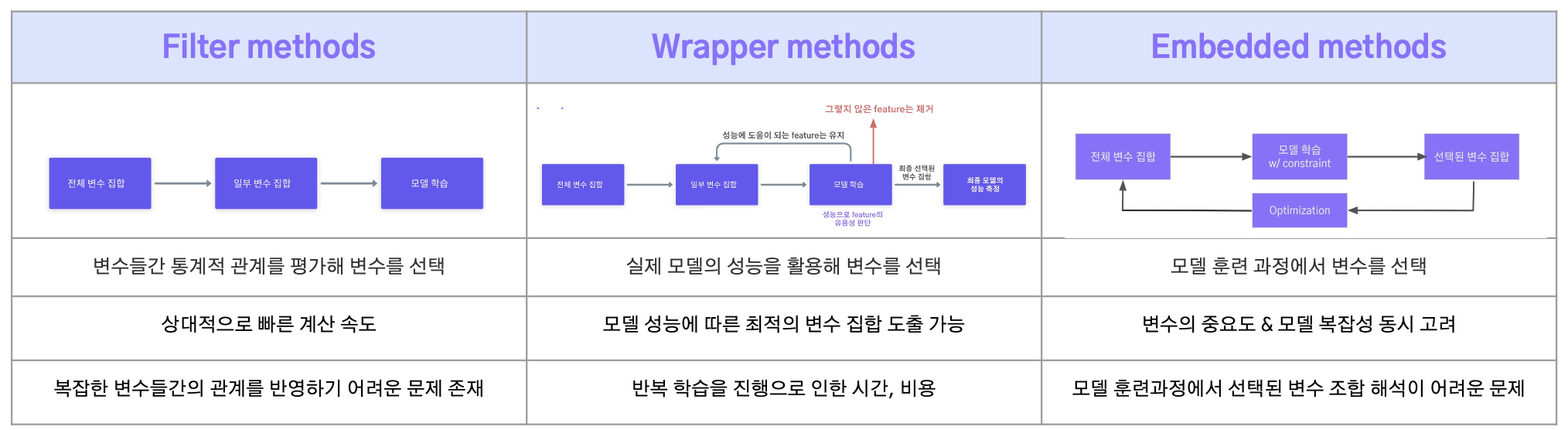
- Filter methods : 변수들간 통계적 관계를 기반으로 변수의 중요도 설정
- e.g. 상관관계, 분산 기반 방법
- Wrapper methods : 실제 머신러닝 모델의 성능을 기반으로 변수의 중요도 설정
- e.g. Forward selection, Backward elimination
- Embedded methods : 모델 훈련 과정에서 변수의 중요도 설정
- e.g. Feature importance, Regularizer 기반 선택
2.2 Filter methods
변수간의 통계적 관계를 평가해 변수의 중요도를 결정하는 방법
- 통계적 관계 = 변수 간의 상관관계, 분산 고려
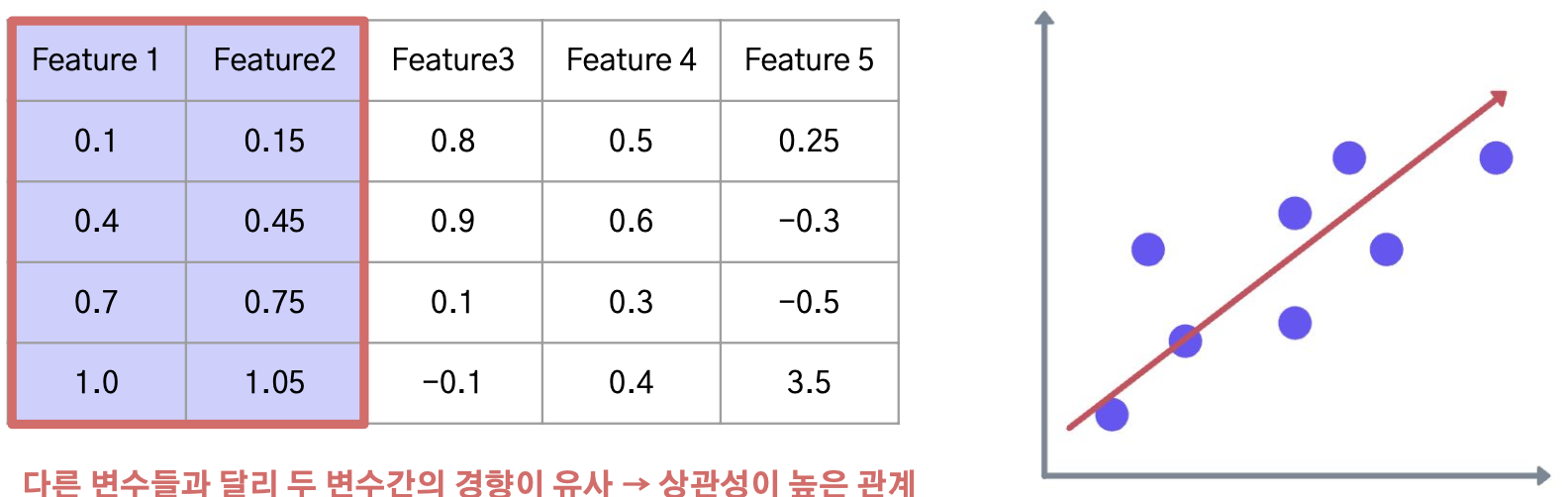
- 상관관계 : 변수들 간의 상관계수를 계산해, 상관관계가 높은 변수들을 제거
- 분산 : 분산이 낮은 변수들을 제거해 변동성이 낮은 변수 제거
- 상대적으로 빠른 계산 속도
Correlation 기반 변수 선택
Chi-square test 기반 변수 선택
-
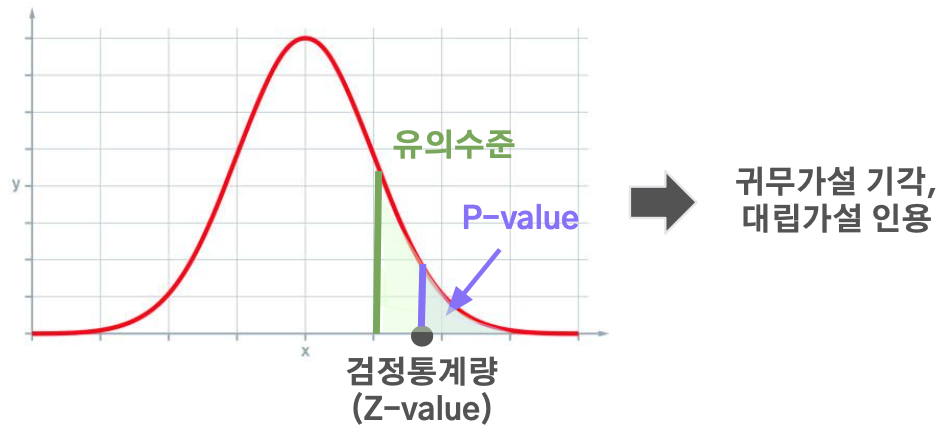
카이제곱 독립 검정 : 두 범주형 변수 간의 유의미한 관계가 있는지 검정하는 방법
- 귀무가설 (H0) : 두 변수들 사이에는 관계가 없다
- 대립가설 (H1) : 두 변수들 사이에는 관계가 있다
➝ p-value가 유의하면, 귀무가설을 기각 + 대립가설을 인용 (=두 변수 사이에는 관계가 있다)
-
Target variable과 독립변수들의 관계성을 카이제곱 통계량으로 판단
- 카이제곱 통계량을 검정통계량으로 하고, p-value를 구해 유의수준으로 검정력을 판단
○ 최종적으로 관계가 있는 변수들만 선택
- 카이제곱 통계량을 검정통계량으로 하고, p-value를 구해 유의수준으로 검정력을 판단
2.3 Wrapper methods
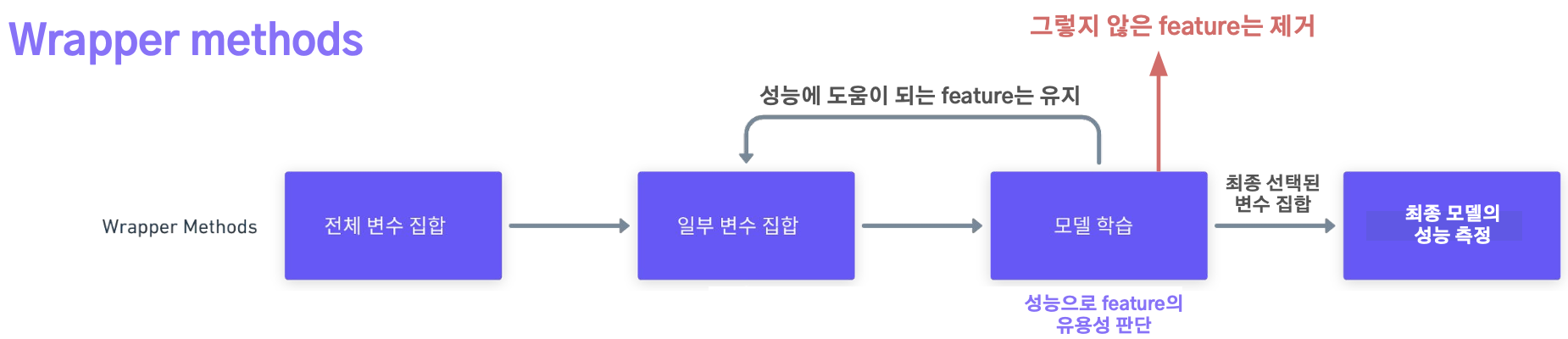
- 실제 모델의 성능을 활용하여 변수를 선택하는 방법
- 모델을 반복적으로 학습시키고 검증하는 과정에서 최적의 변수 조합을 찾는 방법
- 순차적 특성 선택(Sequential Feature Selection) : 변수를 하나씩 추가하면서 탐색
-> forward selection - 재귀적 특성 제거(Recursive Feature Elimination) : 변수를 하나씩 제거하면서 탐색
-> backward selection
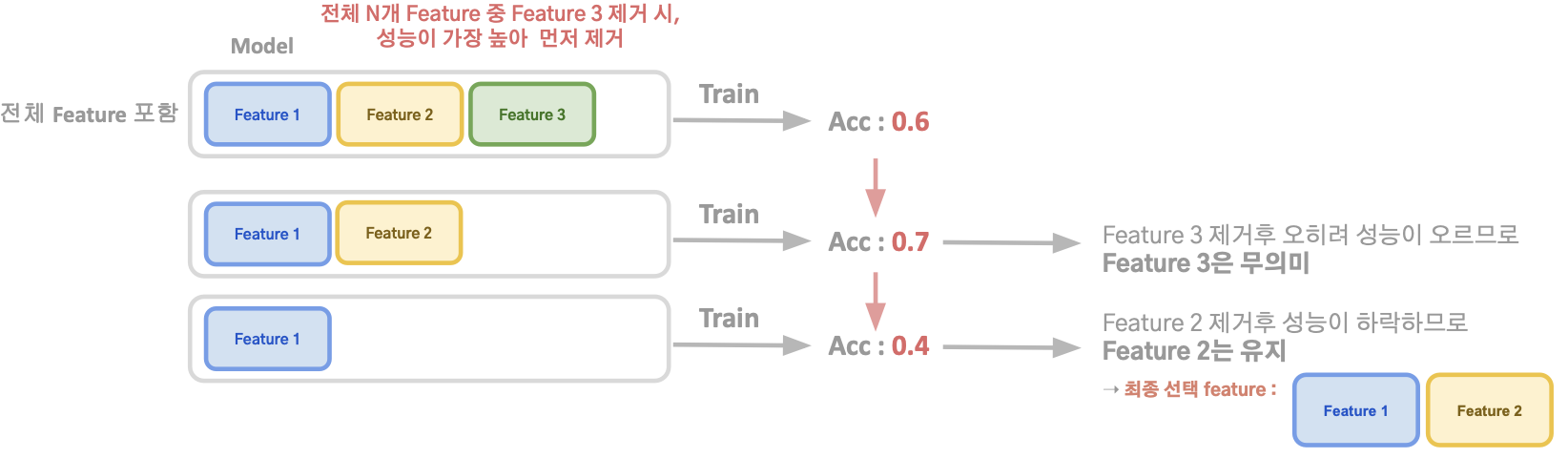
Forward Selection
- 아무런 Feature가 없는 상태에서 시작해 하나하나 유의미한 Feature를 추가해 나감
- “유의미”의 기준 ➝ 모델의 성능 및 평가지표 (성능이 상승하면 해당 Feature를 추가)
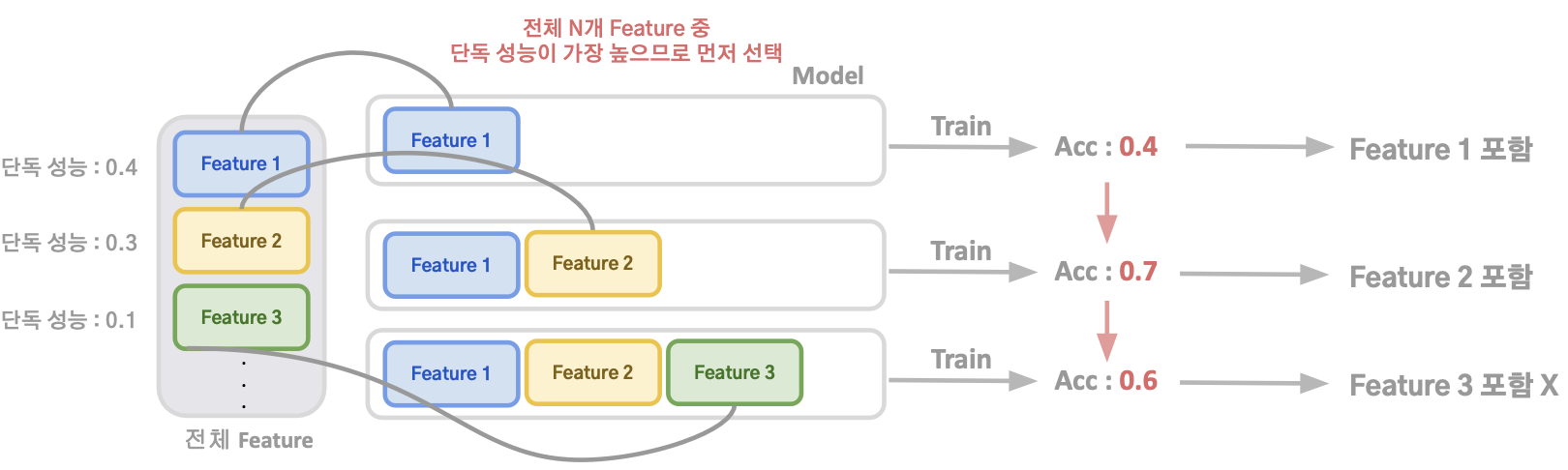
- “유의미”의 기준 ➝ 모델의 성능 및 평가지표 (성능이 상승하면 해당 Feature를 추가)
Bakcward Selection
- 전체 Feature들 중에서 가장 무의미한 Feature를 제거해 나감
- 모든 feature를 가진 모델에서 시작해 모델에 도움이 되지 않는 Feature를 하나씩 줄여 나가는 방식
- “무의미”의 기준 ➝ 해당 Feature를 제거 시, 모델의 성능 하락폭이 얼마나 되는지?
2.4 Embedded methods
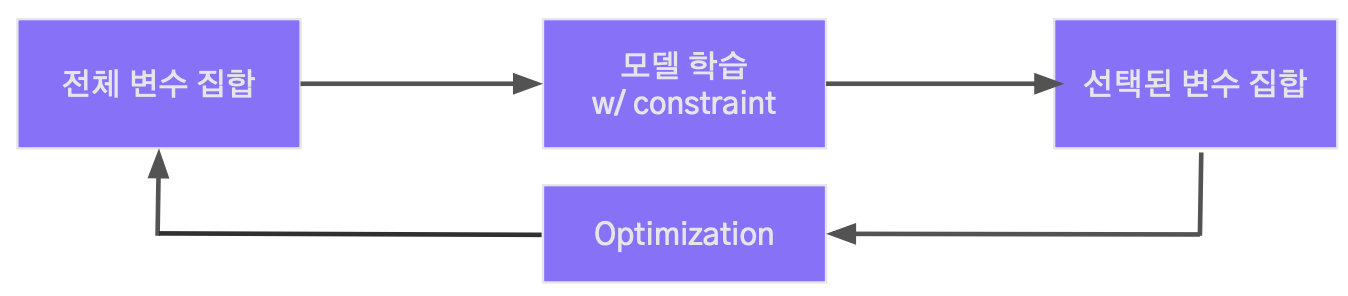
- 모델의 훈련 과정에서 변수의 중요도를 평가해, 이를 기반으로 모델에 대한 변수의 기여도를 결정하는 방법
- 트리 모델 Feature importance 기반 : 트리 split 기여도에 따른 importance를 이용
- 규제(Regularizer) 기반 : L1, L2 등의 규제를 이용해 변수의 기여도 결정
➞ 모델의 특성을 잘 반영하고, 변수의 중요도와 모델의 복잡성을 동시에 고려 가능
Feature Importance
- 트리 node 분할의 기준
- 노드의 순수도를 나타내는 Gini 계수, Entropy 등을 활용
- 특정 feature가 트리의 순수도가 높은 분할에 도움이 된다면 해당 feature는 중요도가 높다고 이해
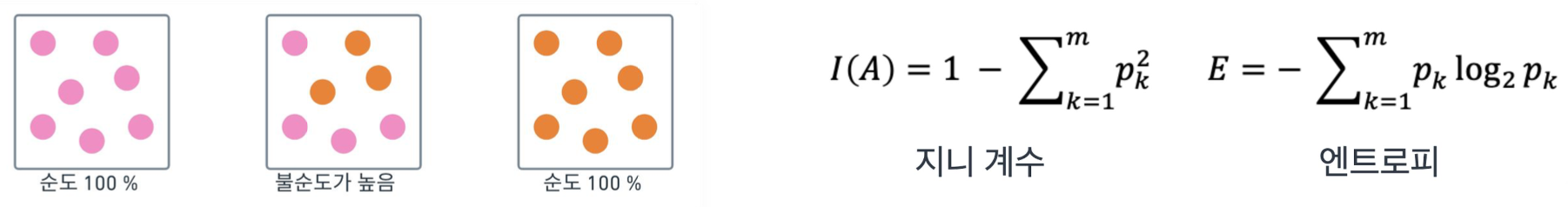
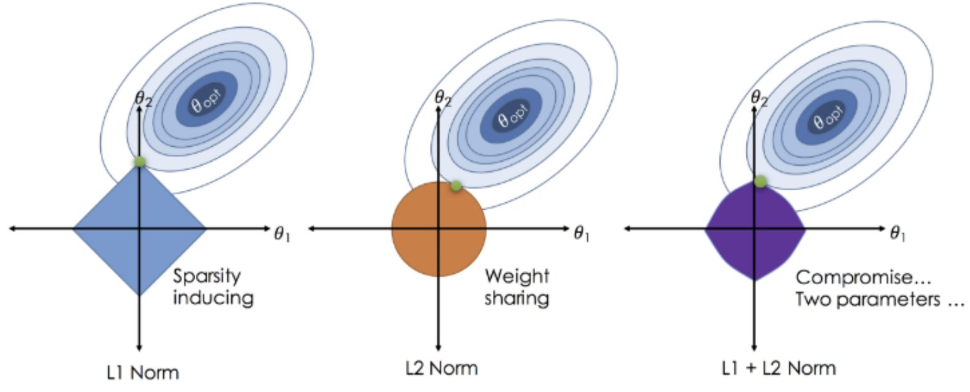
Regularization
- L1, L2 등의 Regularization을 사용해 특정 Feature의 Weight를 0 또는 0으로 가깝게 만들어 Feature 제거의 효과
- L1 : Weight를 0으로 변환
- L2 & ElasticNet : Weight를 0으로 가깝게 변환
- 아래 Regularizer 항을 모델에 추가함으로써 실현
2.5 Summary
03 Feature selection의 실전 사례
3.0 Correlation, Feature importance, Permutation importance 기반 Selection
Feature importance 기반 selection
- 학습된 트리 모델의 중요도를 기반으로 중요도가 낮은 변수들을 제거하는 방법
➞ Feature importance가 낮을 수록 모델 성능 향상에 상대적으로 적은 기여를 할 것이라는 가정 ➞ 트리 모델의 성능에 따라 최적의 변수 조합을 선택
Permutation importance 기반 selection
- 검증 데이터셋의 Feature를 하나하나 shuffle하며 성능 변화를 관찰하는 방법 ○ Shuffle의 의미 = 해당 Feature를 Noise(의미없는 변수)로 만드는 과정
- 만약 해당 Feature가 중요한 역할을 하고있었다면, 모델 성능이 크게 하락할 것
- 검증 데이터셋 Feature의 shuffle로 인해 모델이 학습했던 분포와 크게 달라져 모델의 예측 성능이 하락
➞ 해당 Feature가 상대적으로 모델 성능에 기여를 많이 했을수록 성능 하락폭이 큼
- 검증 데이터셋 Feature의 shuffle로 인해 모델이 학습했던 분포와 크게 달라져 모델의 예측 성능이 하락
<단점>
- Feature 개수가 많다면 효율적이지 못할 가능성 존재
- Random permutation에 의존하기 때문에, 실행마다 Feature importance 결과가 상이 할 수 있는 문제
3.1 Target permutation
-
Shuffle된 Target 변수 모델을 학습시킨 후, Feature importance와 Actual feature importance를 비교해 변수를 선택
-
진행 과정
1) Null importance 도출: Target 변수를 여러번 임의로 Shuffle해 모델 학습 후 Null importance의 분포 도출
→ 목적변수와 관련 없는 변수를 모델이 어떻게 이해하는지를 보여줌 2) Original importance 도출: 원래 데이터셋에서 Importance 도출
3) 1)과 2)에서 구한 Importance를 비교해 실제로 중요한 변수를 선택 가능
<장점>
- Feature들끼리의 상호작용을 고려 가능
- 높은 분산을 가지거나, Target 변수와 관련 없는 변수들을 쉽게 도출 가능
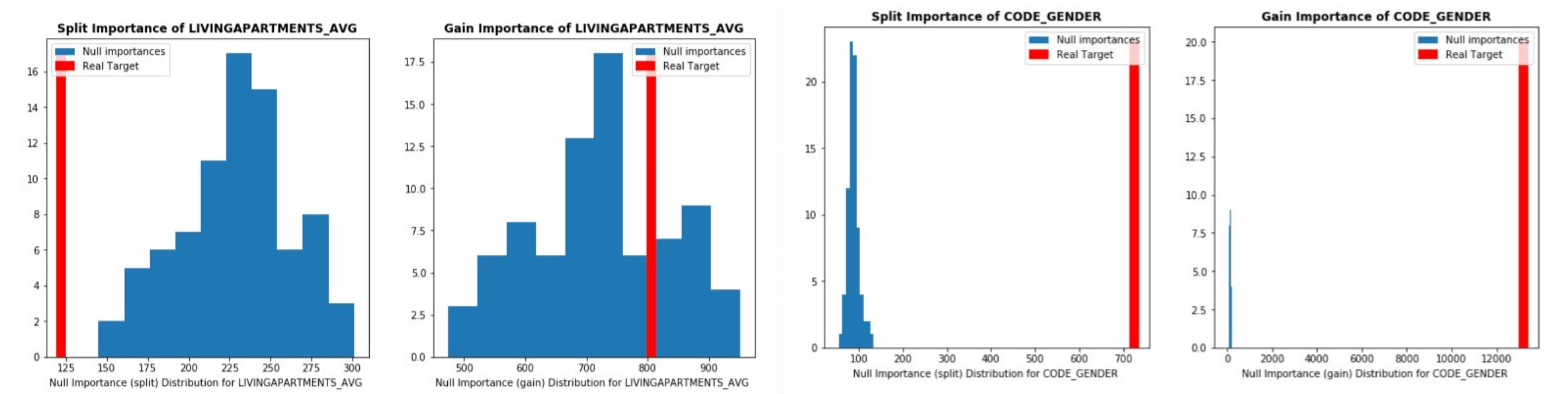
- Target permutation에서의 변수 선택 → Scoring
1) Actual importance와 Null importance distribution이 떨어진 표본수 계산
2) Actual/Null Max, Mean 등의 비율을 계산해 선택
3.2 Adversarial validation
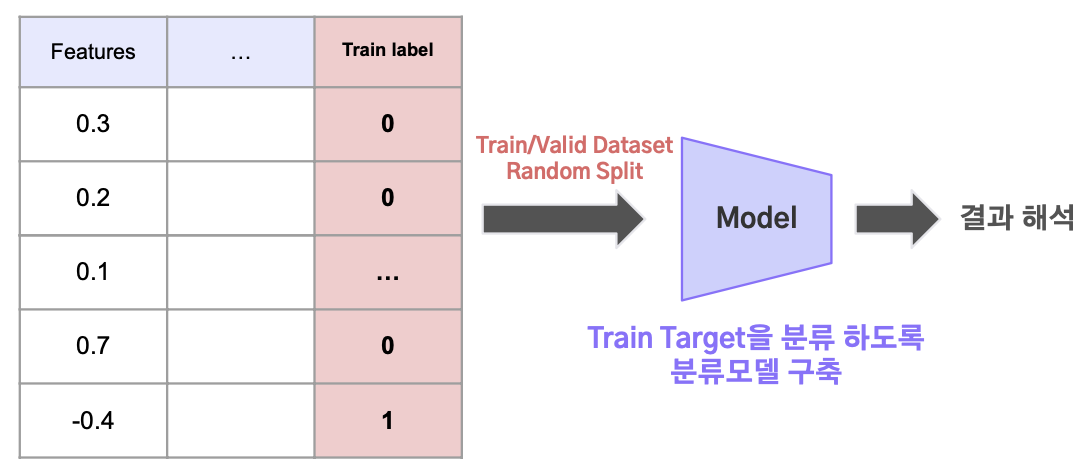
- 학습 데이터셋과 검증 데이터셋이 얼마나 유사한지 판단하는 방법
- 학습 데이터셋의 Target 값은 1로, 검증 데이터셋은 0으로 지정 후 Binary classification 모델링
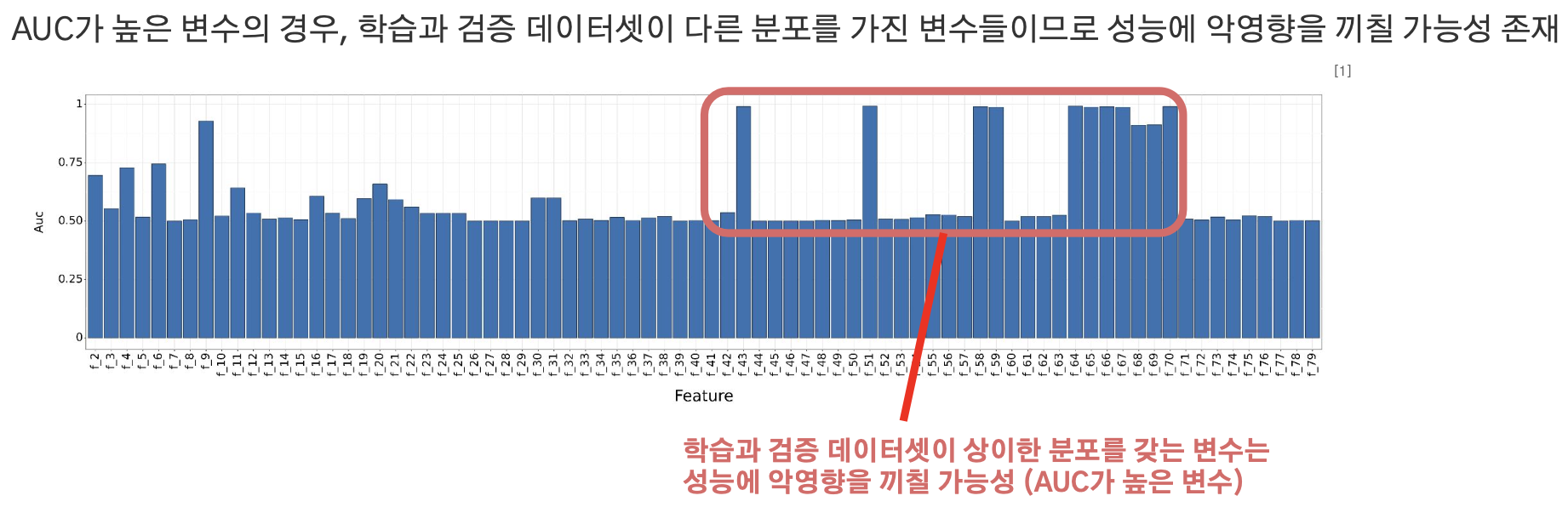
- 만약 학습 데이터셋과 검증 데이터셋의 경향이 비슷하다면, 위 모델의 분류 성능은 낮을 것
- 만약 학습 데이터셋과 검증 데이터셋의 경향이 다르다면, 위 모델의 분류 성능은 높을 것
→ 이 모델의 분류에 도움이 되는 Feature는 과적합을 유발할 수 있으므로 제거하는 방식
- 학습 데이터셋의 Target 값은 1로, 검증 데이터셋은 0으로 지정 후 Binary classification 모델링
- 진행과정
1) 학습 데이터셋은 0, 검증 데이터셋은 1로 변수 설정
2) 학습 + 검증의 데이터셋을 무작위로 분할
3) 위 2) 데이터로 1)의 Target을 분류 하도록 모델 학습
4) 3)의 모델 결과를 AUC나 Feature importance를 해석

Real Cryptocurrency Trader & AI Engineer LV.0