why?
평가 데이터나 검증 데이터가 원본 데이터를 잘 반영하지 못한다면?
- 모델의 학습과 실험이 올바르게 진행되지 않음
- 검증 데이터와 평가 데이터의 분포가 다르거나 서로 다른 패턴을 보유하고 있을 경우,
학습 데이터를 올바르게 검증해도 평가 데이터에 대해서는 성능이 좋지 않은 결과 - 따라서, 검증 데이터와 평가 데이터를 잘 설정하는 것이 중요
Holdout
가장 기본적인 분할 방법
- 전체 데이터를 8:2 등과 같이 일정 비율로 분리하는 기법
- 랜덤하게 분리하거나, 경우에 따라 가장 최근 20%를 검증데이터로 사용
- 주어진 데이터의 특징에 따르거나 목적에 따라 다르기에,데이터와 도메인에 대한 이해를 바탕으로 진행
장점
빠른 속도로 모델 검증 가능하여, 가장 기본적이지만 많이 사용되는 방법론
단점
- 일부 데이터(20%의 검증 데이터)가 학습에 참여하지 못함으로 성능이 일반적으로 낮은 편
- 전체 데이터가 아닌 일부 데이터에 대해서만 검증했기에 완전히 신뢰성 있다고 보장할 수 없음
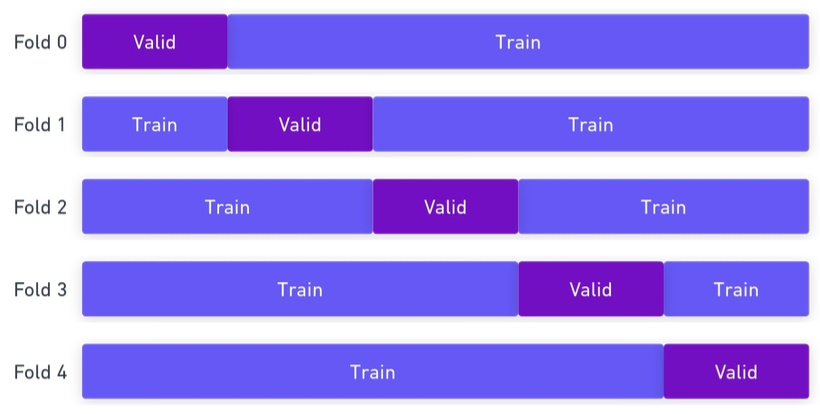
K-Fold
K번의 Holdout으로 데이터를 분리하는 방법
- K-1개를 학습 세트로, 1개를 검증 세트로 사용
- 동일한 Fold가 없도록 설정
- 최적의 학습,검증 Fold셋을 찾아내거나 모델들의 결과를 앙상블해서 사용
장점
- 데이터셋 내의 모든 데이터를 훈련에 활용 가능
- 전체 데이터에 대한 검증을 하기에, 신뢰성을 보장
- Fold별 결과물을 앙상블 하기에, 대부분의 경우 Holdout대비 높은 성능
단점
- 모델 훈련 및 평가 소요시간 증가 (Holdout대비 K배)
- K의 선택이 필요
Stratified K-Fold
- K개의 Fold를 구성하는 방법은 K-Fold와 동일
- 하지만, Fold별 Y의 비율도 동일하게 하는 분할 방법
- 데이터의 양이 적거나 불균형이 심한 데이터에 대해 K-Fold 적용 시 분포가 크게 달라지는 현상을 방지

장점
- K-Fold의 장점
- 데이터셋 내의 모든 데이터를 훈련에 활용 가능.
- 전체 데이터에 대한 검증을 하기에, 신뢰성을 보장.
- Fold별 결과물을 앙상블 하기에, 대부분의 경우 Holdout대비 높은 성능.
- Y의 분포가 동일하기에, 불균형에서 오는 부분이 일부 해소
단점
- K-Fold의 단점
- 모델 훈련 및 평가 소요시간 증가 (Holdout 대비 K배)
- K의 선택이 필요.
Group K-Fold
- 특정 목적하에 사용되는 확장된 K-Fold 방법
- Train과 Valid에 같은 값이 들어가지 않도록 Group을 구성 후, Fold별로 Group을 분배
- 새로운 사람에 대해 예측하는 경우나 일반적으로 환자 데이터에 사용하기 유리
- 새로운 환자의 질병을 예측해야하는 데이터에서 Train과 Valid에 같은 환자의 정보가 들어있으면, 모델이 해당 환자의 패턴을 미리 파악하게 되는 문제가 발생할 수 있음

장점
- K-Fold의 장점
- 데이터셋 내의 모든 데이터를 훈련에 활용 가능.
- 전체 데이터에 대한 검증을 하기에, 신뢰성을 보장.
- Fold별 결과물을 앙상블 하기에, 대부분의 경우 Holdout대비 높은 성능.
- Group 분배 가능
단점
- K-Fold의 단점
- 모델 훈련 및 평가 소요시간 증가 (Holdout 대비 K배)
- K의 선택이 필요.
Time-Series Split
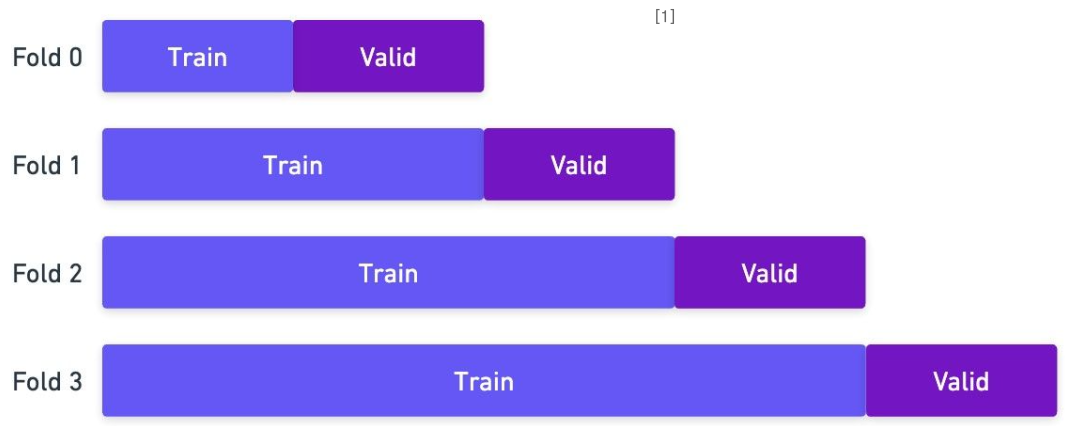
시계열 데이터에 사용되는 확장된 K-Fold 방법
- 시간에 따른 순서가 존재하기에, 기존의 K-Fold를 사용하면 미래의 데이터로 과거를 예측하는 일이 발생
- 따라서, 과거의 데이터를 통해 미래를 예측하는 데이터의 구조를 유지한 채 Fold를 나누는 방법
장점
- K-Fold의 장점
- 데이터셋 내의 모든 데이터를 훈련에 활용 가능.
- 전체 데이터에 대한 검증을 하기에, 신뢰성을 보장.
- Fold별 결과물을 앙상블 하기에, 대부분의 경우 Holdout대비 높은 성능.
- 다양한 기간(Fold1=1주, Fold2=2주, ...)에 대한 학습 결과를 얻을 수 있어, 일반화의 성능을 높일 수 있는 장점.
단점
- K-Fold의 단점
- 모델 훈련 및 평가 소요시간 증가 (Holdout 대비 K배)
- K의 선택이 필요.

Real Cryptocurrency Trader & AI Engineer LV.0