본 포스팅은 충남대 정상근 교수님의 강의를 참고하였습니다. 개인 공부를 기록하는 목적의 포스팅이며, 문제가 될 시 삭제하겠습니다.
Convolutional Neural Network (CNN)
Data transformation은 말 그대로 데이터 변형하는 것이다. 그 중 데이터 사이즈의 변화를 'dimension reduction'이라 부른다. 여기서 포인트는 입력 데이터의 특징을 유지하면서 줄이는 것이다. 이러한 데이터 변형은 대부분 이미지 처리에서 사용하는데, 유명하면서도 대부분 사용하는 CNN 알고리즘에 대해서 알아보자.
CNN 중요성
이미지를 통해 무엇인가 인식하기 위해서는, 기존의 이미지(input image)에 필터(Convolution Kernel)를 적용하여 결과 이미지(Feature map)를 얻는 과정이 필요하다. 이 때 기존의 이미지에 적용하는 필터를 커널(Kernel)이라고도 하는데, 과거에는 이러한 필터를 사람이 직접 만들었다. 같은 이미지라도 살짝 회전되어 있거나, 크기가 다르거나, 변형이 조금만 생겨도 분류하는데 어려움을 겪었다. 그런 경우에 대한 훈련데이터가 모두 필요했고, 그만큼 훈련시간도 상당히 길어진다는 단점이 있었다. 그래서 이미지 픽셀을 그대로 입력받기보다는 이미지를 대표하는 특성을 찾아내서 분류하는 것이 효과적이었는데 기존에는 사용자의 판단에 따라 특성이 결정되었는데, 이러한 특성을 찾아내는 과정을 CNN이 자동화시켰다.
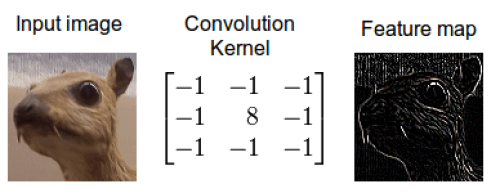
CNN을 이용하면 실생활에서 옷, 사람, 얼굴, 표정, 동물, 숫자 등 많은 것들을 높은 확률로 인식할 수 있다. 일례로 딥러닝 애플리케이션은 CNN을 통해 수천 개의 병리학 보고서를 분석하여 암세포를 시각적으로 검출하며, 자율 주행 자동차가 객체를 감지하고 도로 표지판과 보행자의 차이를 구분할 수 있는 것도 CNN을 적용한 결과이다.


용어
- Channel
- RGB 데이터를 처리하는 경우, 같은 이미지라도 Red, Green, Blue
- 하나의 이미지를 구성하고 있는 여러가지 다른 Feature들을 표현할 때 Channel로 표현한다.
- 이미지를 표현한 여러가지 Feature Map을 각각 하나의 Channel이라 할 수 있다.
- 각각의 채널에 대한 Feature Map들을 모두 하나로 합치면 다시 하나의 Feature Map을 얻을 수 있다.
- 이러한 경우, Multi Channel Filter Dimension은 (가로,세로,Feature Map의 수)로 나타난다.
- 이미지를 표현한 여러가지 Feature Map을 각각 하나의 Channel이라 할 수 있다.
- Filter, Kernel
- Stride
- 이미지에서 Filter를 적용하는 간격을 Stride라 한다. 이미지의 경우, 한 픽셀을 적용한 후, 다음 픽셀을 현재 픽셀에서 얼마나 떨어져 있는 픽셀로 고르는지에 대한 기준이 된다.
- Padding
- Convolution Layer에서는 Filter와 Stride의 작용으로 Feature Map이 입력데이터보다 작다. 이를 방지하기 위해 기존 이미지의 바깥쪽에 임의로 채워주는 값을 패딩(padding)이라 한다.
- Feature Map, Activation Map
- Convolution kernel을 적용하여 새로운 이미지를 만들었을 때, 기존 이미지의 특징(feature)를 나타낸 이미지이므로 이를 피처맵(Feature Map)이라 한다.
- Activation Map: 아무리 복잡한 신경망이라 하더라도 모두 선형관계이다. 하지만, 일상생활에서 보면 비선형 관계인 경우가 대부분이다. 그렇기 때문에 일상생활에 적용하기 위해 비선형 관계를 적용해야 하는 경우가 많은데, 이 때 사용하는 함수가 Activation Function이다. Activation Map은 이러한 함수를 적용하여 나온 Feature Map을 말하는 것이다.
- Pooling
- 다양하게 나타난 Feature 중에서 중요한 Feature만 선택하는 것. (차원 축소와 비슷한 의미)
- Convolution kernel을 적용한 Feature Maps 중 각 중요한 특징을 뽑아서 다시 쓸 때, 그 특징을 뽑는 방법에 따라 Max pooling, Min pooling, Average Pooling을 적용할 수 있다.
CNN 알고리즘
CNN은 은닉층이 여러개인 DNN을 응용한 알고리즘이다.

CNN에서는 이미지를 Convolution으로 변환한(특성 추출) 다음 은닉층에 넣고(Pooling Layer/분류), 여기서 계산된 결과를 다시 은닉층에 넣는 과정을 반복한다. 이 과정을 통해 이미지를 대표하는 특징을 학습하여 이미지를 분류하여 인식한다.
필터를 적용하는 방법을 도식화한다면 다음과 같다.

이렇게 이미지에 필터를 적용하여 Feature Map을 뽑아낸다.
이미지의 특징은 대부분 하나로 설명되지 않는데, RGB 이미지의 경우 Red, Green, Blue로 나누어 특징을 나타낼 수 있다. 이러한 특징을 나타낸 것들을 채널(Channel)이라 하는데, 모든 필터를 각 채널에 적용하여 Pooling Layer에 넣는다. 이 과정을 도식화하면 다음과 같다.

이러한 과정을 여러번 반복하면 연산량이 기하급수적으로 늘 것이므로 이를 방지하기 위해 Polling Layer에서는 적당히 크기도 줄이고, 특정 feature를 강조하는 일을 한다. 처리 방법으로는 Max Pooling, Min Pooling, Average Pooling이 있는데, CNN에서는 주로 Max Pooling을 사용한다.

