계획 

오늘 위키독스 20문제를 하고 개인과제를 했는데 판다스 개인 과제가 생각보다 어려웠다.
배웠는데 다 까먹어서 체화의 중요성을 느끼고 경각심을 동시에 느꼈다.
위키독스
185번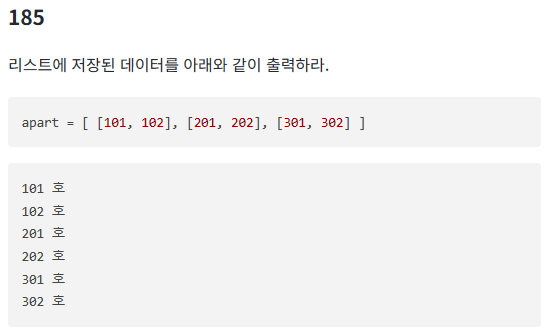
apart = [ [101, 102], [201, 202], [301, 302] ]
for i in apart:
print(i,'호')
###
for row in apart:
for col in row:
print(col, "호")첫번째 코드로 사용하면 [101, 102] 호와 같이 출력된다.
이중 리스트이기에 한 번 더 빼야 하는 거 같다.
그래서 두번째 코드처럼 작성해야 아래와 같이 출력이 된다.
186번 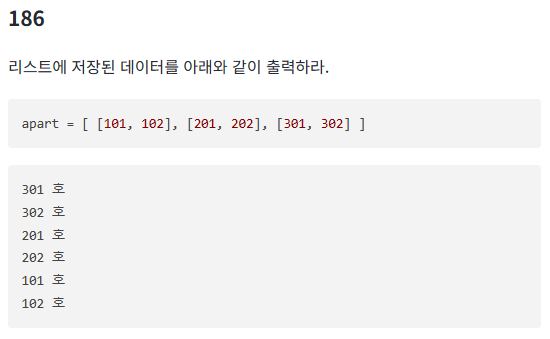
apart = [ [101, 102], [201, 202], [301, 302] ]
for i in apart:
for j in i[::-1]:
print(j,'호')
###
apart = [ [101, 102], [201, 202], [301, 302] ]
for i in apart[::-1]:
for j in i:
print(j,'호')첫번째 코드는 이중 리스트의 순서를 바뀌게 된다.
두번째 코드처럼 해야 아래와 같이 큰 리스트에 영향을 줄 수 있다.
193번 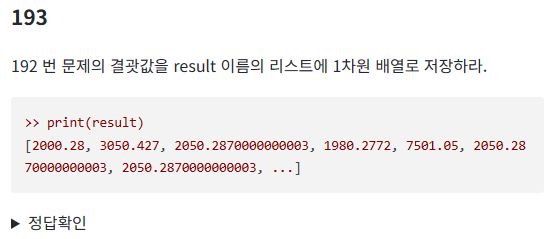
data = [
[ 2000, 3050, 2050, 1980],
[ 7500, 2050, 2050, 1980],
[15450, 15050, 15550, 14900]
]
result=[]
for i in data:
for j in i:
result = j*1.00014
print(result)
###
result=[]
for i in data:
for j in i:
result.append(j*1.00014)
print(result)첫번째 코드는 result라는 리스트에 값을 부여하는 것이다.
그래서 추가되지 않고 2000.28부터 부여되다 마지막에 마지막 값이 부여된다.
두번째 코드처럼 append매서드를 사용해야 리스트에 추가가 된다.
195번 
ohlc = [["open", "high", "low", "close"],
[100, 110, 70, 100],
[200, 210, 180, 190],
[300, 310, 300, 310]]
for i in ohlc:
for j in i[3]:
print(j)
###
for row in ohlc[1:]:
print(row[3])첫번째 코드처럼 하면 컬럼명인 close부터 print를 한다.
심지어 밑에는 정수형이므로 에러까지 난다.
두번째 코드처럼 해야 컬럼명 리스트 이후에 값을 얻을 수 있다.
판다스 개인 과제
4번 
iris.describe()R에서 Summary함수를 자주 사용했지만 파이썬에서는 describe()매서드를 사용해야 한다.
6번 
df1 = pd.DataFrame(iris[['Species']=='Iris-setosa'])
df1
###
df1 = pd.DataFrame(iris[iris['Species']=='Iris-setosa'])
df1그냥 첫번째 코드처럼 하면 안된다.
두번째 코드처럼 해야 한다.
기본 양식이니 기억하자.
7번 
iris.groupby('Species').mean('Sepal Length')
###
iris.groupby('Species')['Sepal Length'].mean()첫 코드를 사용하면 이유는 모르겠지만 전체적인 평균이 나온다. 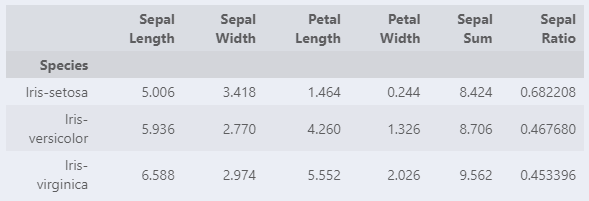
두번째 코드를 사용해야 Sepal Length만 나온다. 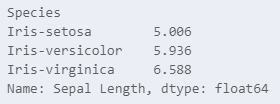
10번 
iris['Species'].value_counts()value_count() 매서드를 사용하면 된다.
정리
챌린지 문제에 벽을 느꼈다.
배워야 할 게 많다.
자만하지 말고 기초부터 다지자.
아직은 기초를 다질 수 있다.
내가 못하는 것을 인정하고 겸손하고 성실하게 공부하자.
