SQL basic 1강
WINDOW 함수의 개념 & 예제
MySQL로 이렇게 쓰면 값을 다음과 같이 얻을 수 있다.
SELECT 그룹, SUM(값) FROM 테이블 GROUP BY 그룹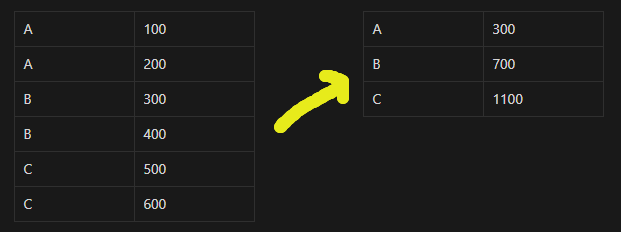
하지만 WINDOW 함수를 사용하면 다음과 같이 얻을 수 있다.
SELECT 그룹, 값, SUM(값) OVER (PARTITION BY 그룹) AS 합계 FROM 테이블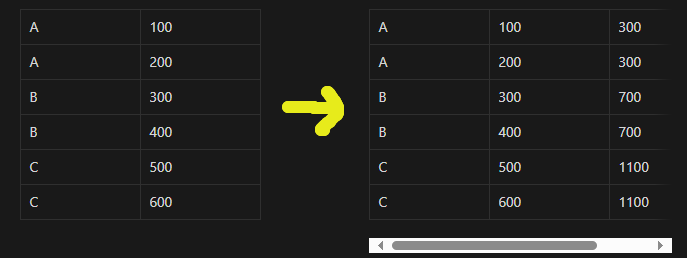
집계 함수는 주로 GROUP BY와 묶이며 데이터의 그룹별 요약을 제공한다.
하지만 WINDOW 함수는 OVER과 묶이며 각 행의 추가적인 정보를 제공한다.
집계 함수(칼럼) OVER([PARTITION BY 컬럼] [ORDER BY 컬럼])
SUM(값) OVER ()
SUM(값) OVER (ORDER BY 열)
SUM(값) OVER (PARTITION BY 그룹 ORDER BY 열)위와 같이 다양한 형식으로 코드를 작성할 수 있다.
SUM 대신 다양한 집계 함수를 사용할 수 있다.
순위 매기기 [RANK, DENSE_RANK, ROW_NUMBER, LAG, LEAD]
이동 계산 [AVG]
누적 합계 또는 누적 평균 [SUM, AVG]
그룹별 집계 [SUM, MAX, MIN]
백분위수 계산 [PERCENT_RANK, NTILE]
예제
코드와 결과 값을 보며 익혀보자.
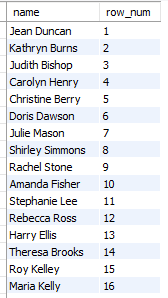
SELECT name,
ROW_NUMBER() OVER (ORDER BY salary DESC) as row_num
FROM employees;설명 : 급여 순으로 각 행에 고유 번호를 부여한다.
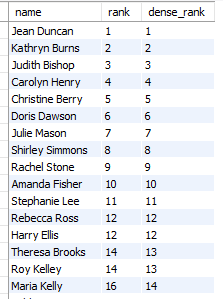
SELECT name,
RANK() OVER (ORDER BY salary DESC) as `rank`,
DENSE_RANK() OVER (ORDER BY salary DESC) as `dense_rank`
FROM employees;설명 : 순위를 매기며 rank()는 동순위 발생 시 순위를 건너 뛰지만 dense_rank()는 건너 뛰지 않는다.
SELECT name,
NTILE(4) OVER (ORDER BY salary DESC) as quartile
FROM employees;설명 : 데이터를 4개의 구간으로 나눈다.
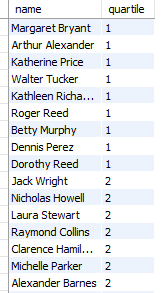
SELECT name,
salary,
LAG(salary, 1) OVER (ORDER BY salary DESC) as prev_salary,
LEAD(salary, 1) OVER (ORDER BY salary DESC) as next_salary
FROM employees;설명 : 현재 행을 기준으로 이전의 행 값 또는 이후의 행 값을 참조한다.
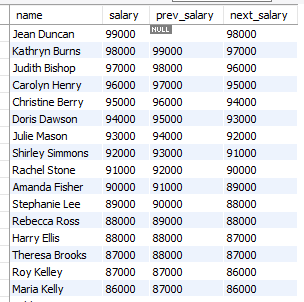
SELECT name,
salary,
FIRST_VALUE(salary) OVER (ORDER BY salary DESC) as highest_salary,
LAST_VALUE(salary) OVER (ORDER BY salary DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as lowest_salary
FROM employees;설명 : RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING는 현재 행 기준으로 이전의 행들과 이후의 행들을 범위로 지정하는 함수이다.
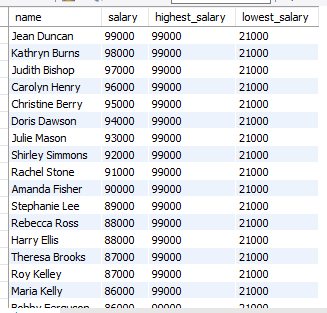
SELECT department,
employee,
salary,
SUM(salary) OVER (PARTITION BY department ORDER BY salary DESC) as cumulative_salary
FROM employees;설명 :각 그룹별 누적 합계를 계산한다.
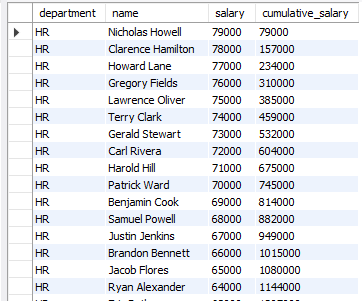
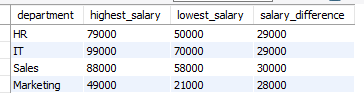
문제
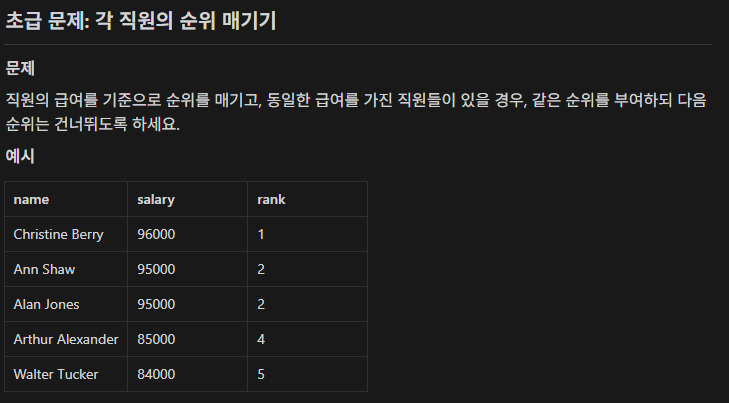
SELECT name, salary, rank() OVER(order by salary desc) as `rank` FROM employees;설명 : 순위를 건너뛰라고 했기 때문에 dense_rank()가 아닌 rank()를 사용한다.
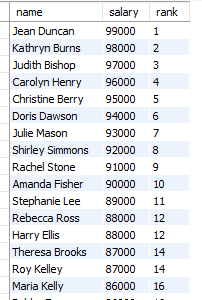
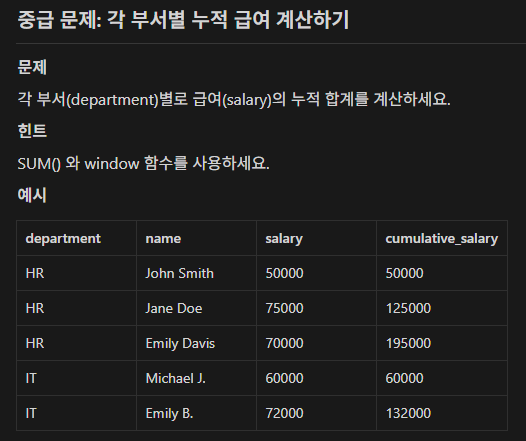
SELECT department, name, salary, sum(salary) OVER (partition by department order by salary, name) as cumulative_salary
FROM employees;설명 : 누적 합계는 예제 마지막 부분이라 기억이 빨리 났다. 추가로 order by에 name을 추가해서 salary가 같을 때 묶여서 누적 합이 나오는 것을 방지했다.
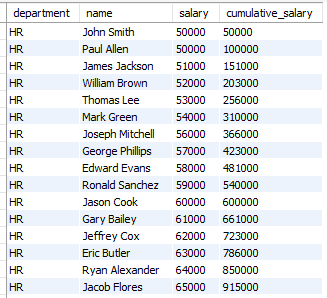
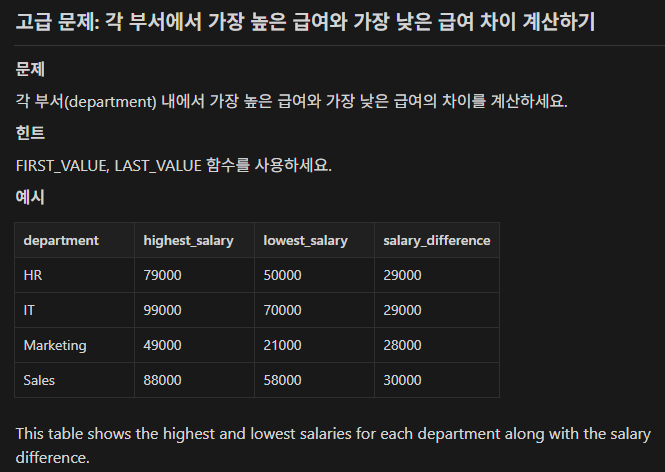
SELECT department, max(salary) highest_salary,
min(salary) lowest_salary, max(salary)-min(salary) salary_difference
FROM employees GROUP BY department;설명 : 간단하게 풀었으나 뭔가 아닌 거 같다. 튜터님이 주신 답과 많이 달라 내일 강의를 잘 들어봐야 할 거 같다.
파이썬 basic 1강

1회차는 쉬웠다.
언어적 특성과 기초에 대해 배웠다.
라이브러리에 대해 배웠다.
판다스를 기준으로 라이브러리 적용은 다음과 같다.
import pandas as pd근데 from을 쓰는 경우가 있는데 이건 라이브러리 내에 하나의 함수만 가져올 때 사용한다.
from matplotlib.pyplot as pltMagic Command라는 게 있다.
대표적으로 %%time이 있다.
이걸 사용하면 뒤에 나오는 셀 전체 수행 후 소요시간을 알 수 있다.
조건에 부합하는 데이터를 가져올 때 다양한 방법이 있지만 나는 마스크를 주로 사용한다.
# true, false의 개념이 아닌 조건에 부합하는 데이터만 슬라이싱하여 가져오고 싶을 때
# mask 메서드로 불립니다. 이름은 반드시 mask 일 필요가 없습니다.
mask = ((df2['Age']>50) & (df2['Gender']=='Male'))
df2[mask]그루핑은 다음과 같이 사용할 수 있다.
# 데이터 그루핑- 기준 1개
df2.groupby('Gender')['Customer ID'].count()
# 데이터 그루핑- 기준 여러개
df2.groupby(['Gender','Location'])['Customer ID'].count()
# 데이터 count 와 nunique(distinct, 중복제거) 차이
df2.groupby('Location')['Age'].count()
df2.groupby('Location')['Age'].nunique()