SQL basic 2강
서브쿼리
서브쿼리는 SQL 문장에서 메인 쿼리 내부에 포함된 쿼리이다. 메인 쿼리의 일부로 실행되어 메인 쿼리의 결과를 제한하거나 계산하는 데 사용된다.
select, from, where, having안에 사용할 수 있다.
- 서브쿼리의 종류
- 단일 행 서브쿼리
- 하나의 행만 반환하는 서브쿼리
- 다중 행 서브쿼리
- 여러 행을 반환하는 서브쿼리
- 상관 서브쿼리
- 외부 쿼리의 각 행에 대해 한 번씩 실행되는 서브쿼리
- 단일 행 서브쿼리
- 서브쿼리랑 자주 쓰는 함수
- IN : 서브쿼리가 반환한 값 중 하나라도 일치하는 경우
- EXISTS : 서브쿼리가 하나 이상의 행을 반환하는 경우
- ANY : 서브쿼리가 반환한 값 중 하나라도 조건을 만족하는 경우
- ALL : 서브쿼리가 반환한 모든 값이 조건을 만족하는 경우
with절은 임시로 테이블을 만드는 것이다.
가독성이 좋고 테이블을 여러 번 사용할 때 with절을 사용하면 간편하다.
실습
이번 실습은 테이블을 주지 않았다.
문제만 보고 하라고 하셔서 당황했지만 실제 코딩테스트에 이렇게 하는 경우가 있다고 하니까 해보자.
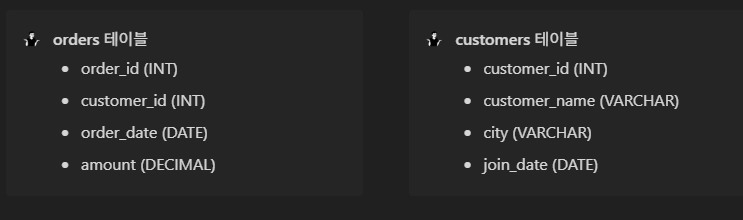
select customer_name
from customers
where customer_id in
(
select distinct customer_id
from orders
where order_date >= date_trunc('month',current_date - interval'month')
and order_date < date_trunc('month',current_date)
);설명 : date_trunc() 함수에 대해 알게 되었다.
where 절을 해석해 보자면 order_date가 현재 월 - 한 달로 => 저번 달보다 크거나 같으면서,현재 달보다 작은 달이니까 저번 달을 말하는 것이다.

select city, customer_name, order_count from
(
select city, c.customer_id, customer_name, count(order_id) order_count,
rank() over(partition by city order by count(order_id) desc) `rank`
from orders o join customers c on o.customer_id = c.customer_id
group by city, customer_name
) a
where rank = 1;설명 : 서브쿼리부터 설명하자면, 두 테이블을 조인하고 필요한 컬럼을 select했다.
그리고 도시별로 가장 많은 주문을 한 사람을 고르기 때문에 rank와 윈도우 함수를 사용해서 rank 컬럼을 만들었다.
그리고 where에서 rank를 1만 설정해서 추출했다.
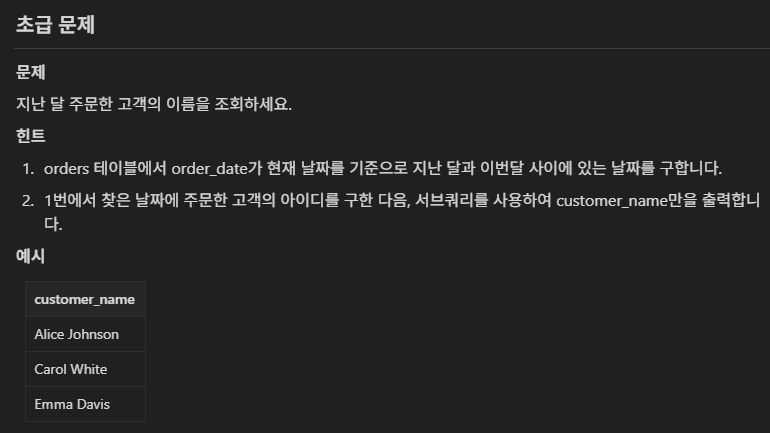
select customer_name, sum(amount) total_amount from orders o join customers c on o.customer_id = c.customer_id
where sum(amount) > (select avg(amount) from orders group by customer_id)
group by o.customer_id;
select customer_name, sum(amount) total_amount from orders o join customers c on o.customer_id = c.customer_id
where sum(amount) > (select avg(amount) from (select sum(amount) total_amount from orders group by customer_id)a)
group by o.customer_id;설명 : 아래 코드가 맞는 거 같다.
위에 코드는 내 것인데 아쉬운 게 당최 내 코드가 맞는지 확인을 못한다, 데이터가 없어서.
SQL basic 3강
CTE
CTE는 Common Table Expression의 약자로 SQL에서 쿼리의 가독성과 재사용성을 높이기 위해 사용된다.
주로 복잡한 쿼리를 단순화하거나 쿼리 내부에서 재귀적으로 데이터를 처리할 때 유용하다.
WITH 절을 사용하며 일시적인 이름을 가지는 테이블로 반복해서 사용 가능하다.
CTE는 사용하는 쿼리 블록에서만 존재하며, 쿼리가 실행된 이후에는 사라지기에 다시 사용할 수 없다.
- CTE의 장점
- 일회성: 기존의 뷰나 파생 테이블, 임시 테이블을 대신하여 일회성으로 사용할 수 있습니다.
- 가독성: 복잡한 쿼리를 단계별로 분리하여 이해하기 쉽게 만듭니다.
- 재사용성: 동일한 쿼리 블록에서 여러 번 사용될 수 있습니다.
- 모듈화: 쿼리를 작은 부분으로 나누어 유지보수하기 쉽게 만듭니다.
- 재귀적 쿼리: 재귀적 데이터를 처리할 때 유용합니다.
실습
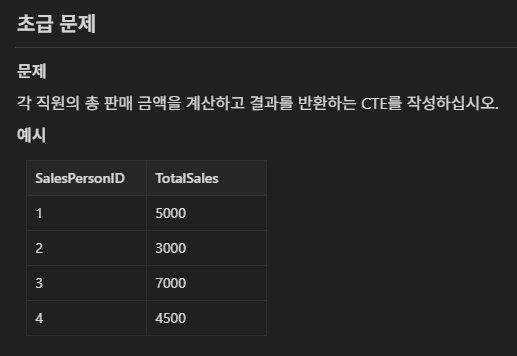
with a as (
select SalesPersonID, sum(SalesAmount) totalsales from sales group by 1
)
select * from a;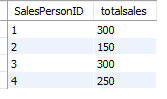
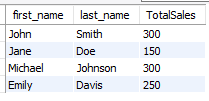
with a as (
select SalesPersonID, sum(SalesAmount) TotalSales from sales group by 1
),
b as (
select id, SUBSTRING_INDEX(name, ' ', 1) first_name, substring_index(name, ' ', -1) last_name from employees
)
select first_name, last_name, TotalSales from a join b on a.SalesPersonID = b.id;설명 : substring_index에 대해 배웠다.
구분자를 이용해서 구분하고 인덱스를 이용해 선택하면 된다.
지금 궁금해서 -1 대신에 2를 넣었더니 풀 네임이 나온다.
매커니즘을 대충 이해할 수 있게 되었다.
고급 문제는 파일 오류로 불가능했다.
