
Index
검색을 빠르게 만들기 위해 "따로 복사 후에 정렬해둔 컬럼"을 index라고 한다
(프라이머리키랑 같음)
index 생성시 타입
Btree(B+tree) 아래 설명 참고
Rtree는 2차원 좌표값을 저장한 컬럼일 때 사용 (예를 들어 위도/경도)
Full text는 긴 문장에서 원하는 단어 빠르게 찾고 싶을 때 사용
index생성 및 성능 확인
하나의 컬럼에만 적용
CREATE INDEX 인덱스이름작명 ON 테이블명 (컬럼명);
다중컬럼
CREATE INDEX 인덱스이름작명 ON 테이블명 (컬럼명1, 컬럼명2);- 다중 컬럼에 적용시 적용 순서가 중요(예 위 다중 컬럼에선 컬럼1에만 조건문을 줘서 찾는 경우 index가 적용되나 컬럼2에만 조건문을 주면 적용이 안됨)
- dbeaver에선 select문 작성 후 실행계획 보기 클릭 혹은 explain select~~ 입력 후 아래 박스 cost(소요시간) 참고
- MySQL workbench에서 쿼리문 작성 & 실행하고 우측 Execution plan 눌러보면 더 상세히 조회가능
fulltextIndex 검색기능
컬럼명 LIKE %단어% 로 검색기능을 만들 순 있으나
- % 기호를 맨 앞에 쓰면 인덱스활용을 못하고
- 문장이 좀 길거나 행이 너무 많아지면 LIKE 만으로는 매우 느리게 동작(짧은 문장은 그냥 LIKE쓰자)
그래서 fulltextIndex 사용
인덱스 생성
CREATE FULLTEXT INDEX 인덱스이름작명 ON 테이블명(컬럼명);
검색
SELECT * FROM library WHERE MATCH(컬럼) AGAINST('검색어'); 위의 인덱스의 경우 띄워쓰기 단위로 단어를 잘라 인덱스를 매겨놓고 검색하는 방식인데 띄워쓰기가 다 틀릴 수도 있으니
CREATE FULLTEXT INDEX 인덱스이름작명 ON 테이블명(컬럼명) WITH PARSER ngram; 를 사용하여 인덱스 제작하여 사용하는 것도 방법
but 위 같은 경우 연관된 검색어를 다 찾아준다.(정확도순 자동 정렬)
예: '기린을' 검색시 기린, 린을 등이 들어간 단어는 모두 찾아줌
Binary Search Tree
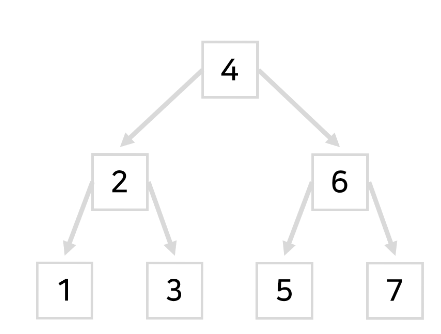
이진 탐색 트리(Binary Search Tree, BST)는 이진탐색과 연결리스트(Linked List)를 결합한 자료구조이다.
이진탐색
장점 : 탐색에 소요되는 시간복잡도는 O(log n)으로 빠름
연결리스트
장점 : 자료 입력, 삭제에 필요한 시간복잡도는 O(1)로 빠름
단점 : 탐색하는데 O(n)의 시간복잡도를 가짐.
이진 탐색 트리는 이 둘의 장점을 합쳐보고자 만들어진 자료구조이다.
B-tree (비 트리)
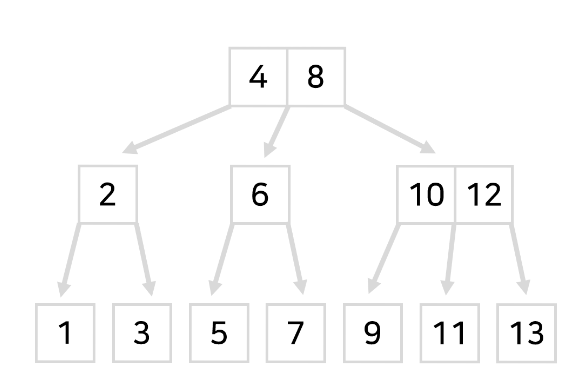
- 하나의 네모칸 안에 숫자를 여러개 담아놓는 식으로 배치하고
- 갈림길을 3개 이상으로 쪼개놓기
B+tree(비 플러스 트리)
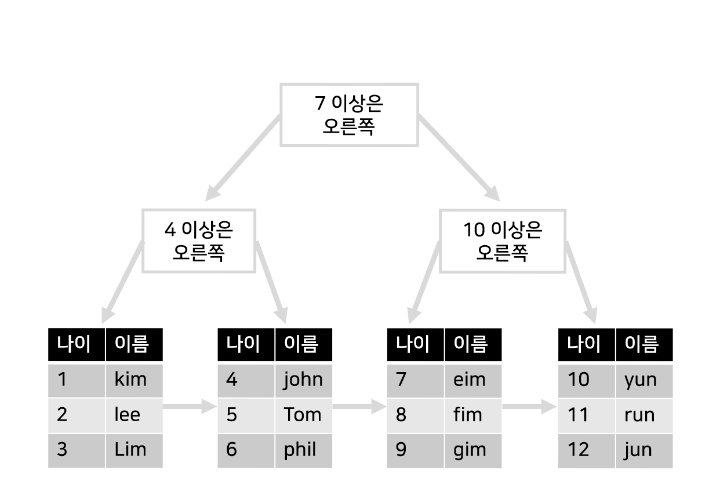
B+tree라고 해서 데이터를 트리 중간중간에 보관하는게 아니라 가장 밑에만 보관하는거
범위검색을 할 때 훨씬 빠르게 찾을 수 있습니다.

춘식이는 너무 귀엽습니다.