결과 PowerBI 대시보드 미리보기
HR 대시보드
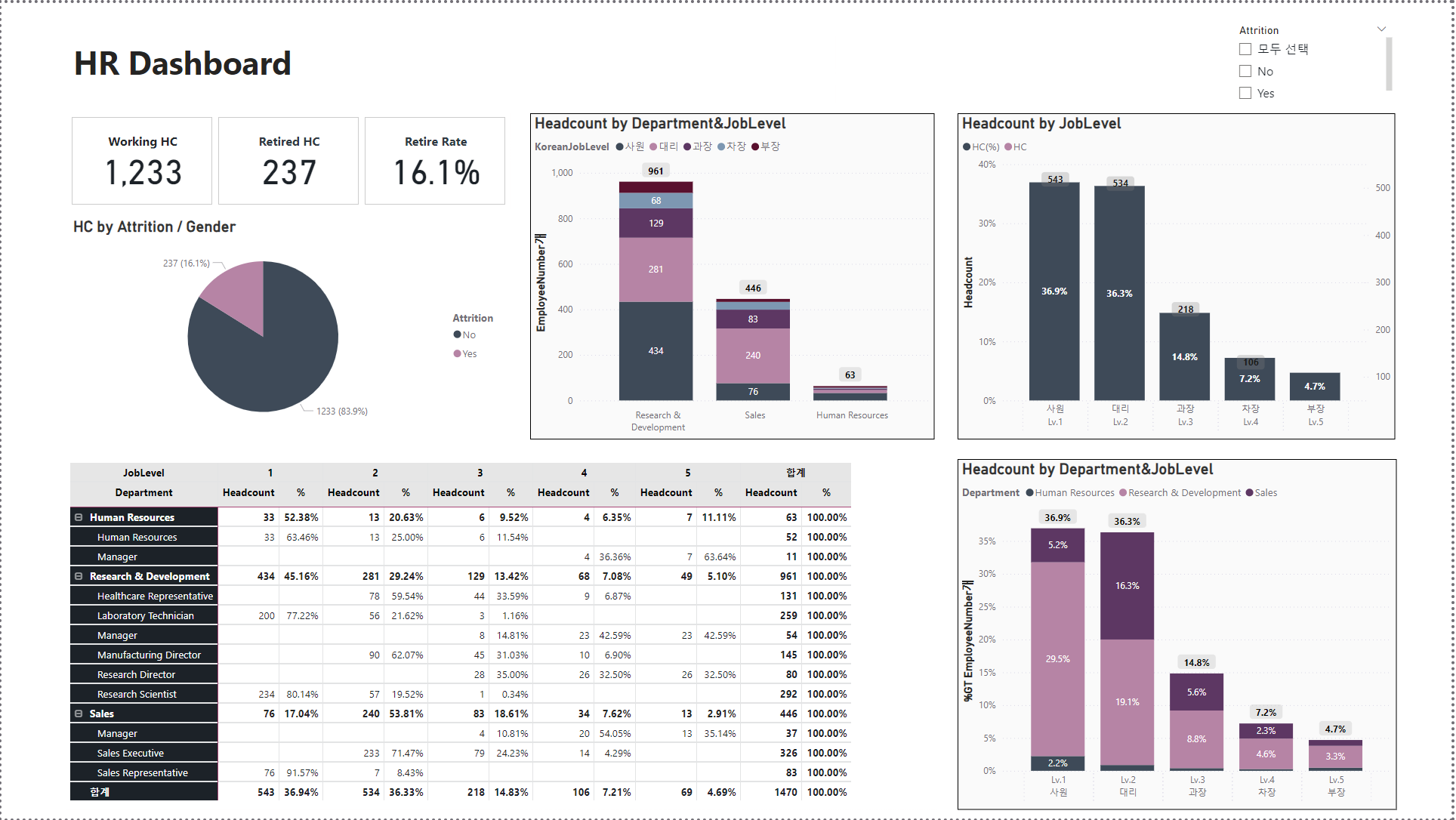
Attrition 대시보드
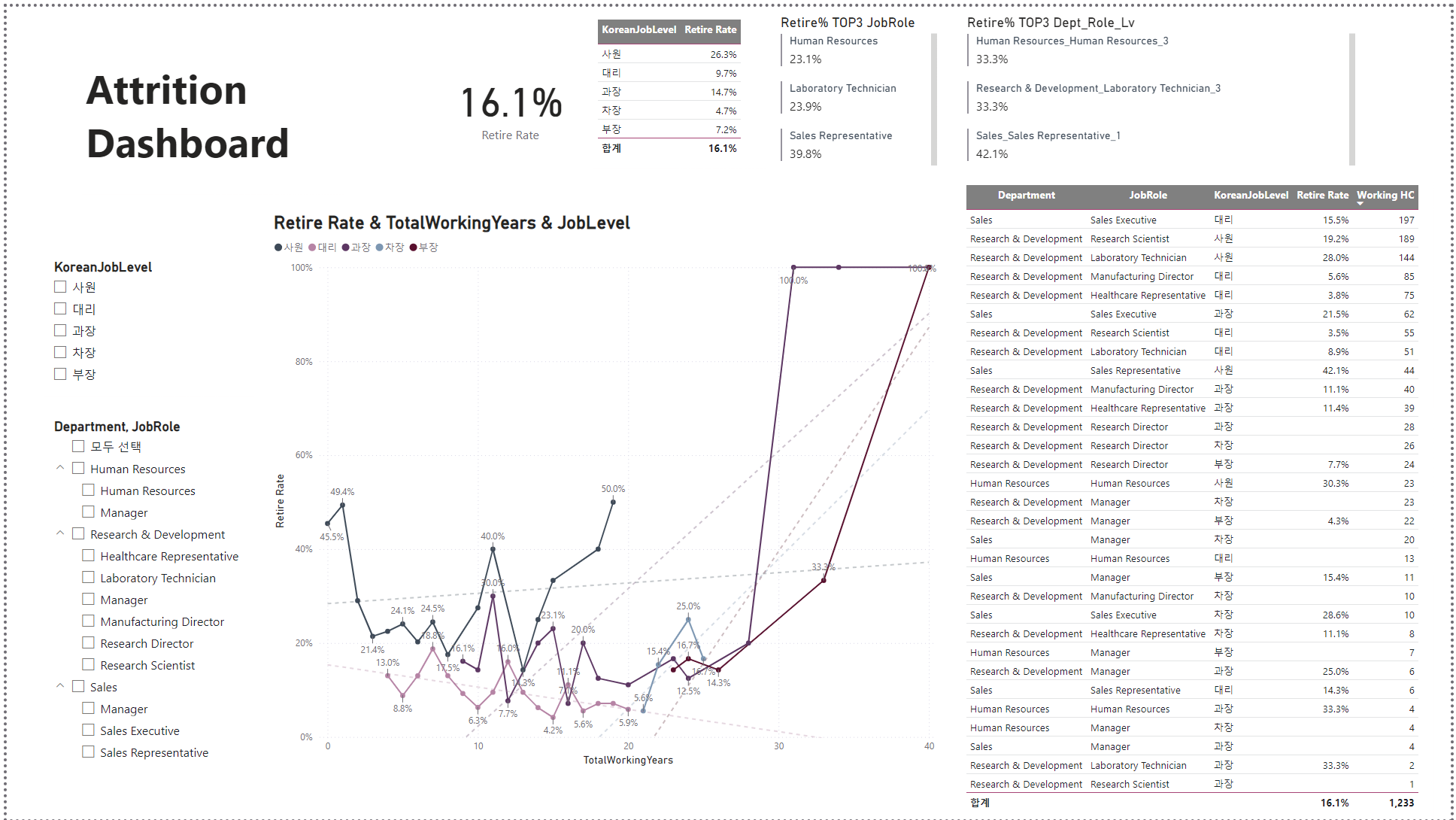
Compensation 대시보드
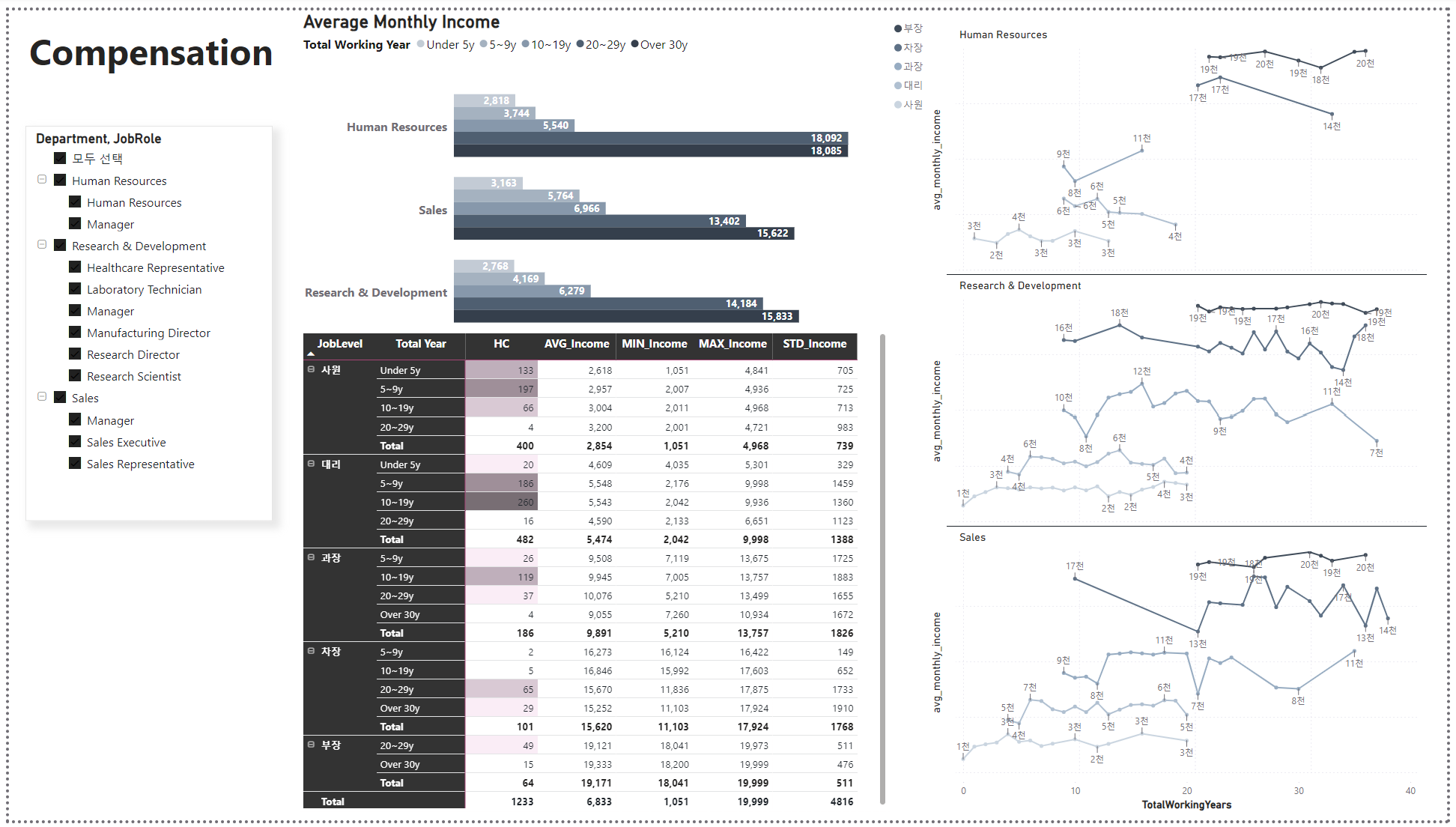
-
데이터 분석
- 어떠한 비즈니스 상황과 데이터셋을 만날까?
- 어떻게 가설을 세우고 인사이트까지 도출할까?
- 어떤 툴을 적재적소에 활요할까?
-
DB
- Data적재
- relationship 이해
- ERD
-
SQL, Python
- Adhoc Analysis
- EDA
- Data Transformation
-
BI
- Visualization
- Reporting
- Automation
- 분석 초기 세팅
- 분석 환경 만들기
- 데이터셋 관계 이해
- 데이터 컬럼 특성 이해
- 데이터 탐구
- Python EDA
- SQL Adhoc Query
- 가설과 인사이트
- 대시보드 시각화
- BI Reporting
- 데이터로 제안/설득
- 조직 Data Literacy 제고
DBeaver
- 오픈 소스
- 다양한 DB 지원
- 직관적 인터페이스
- 쉬운 import + export
- ERD 그리기
Power BI
- 마이크로소프트 business intelligence tool
- 다양한 DB, Data Source Connection
- MS 친화 인터페이스
- Dax & Power Query
- License 가격 경쟁력
< HR 신입 BA가 되었다 ! >
- 진행방식
- HR 파일 관리
- Dataset : kaggle - HR Analytics
데이터 EDA - colab
-
데이터 훑어보기
- Info, describe
- Null check
- Duplicates check
- Type check
-
데이터 재구조화
- Groupby
- Pivot_table
- Stack/Unstack
-
Cols Relation 파악
- Heatmap Correlation
- Bar / Regplot / Histplot
- FacetGrid
- Jointplot
- 반복문으로 Subplots
<Python 공부>
인사이트 도출 및 시각화 결과물 그리기
- Library : Pandas
-
pandas 설치 및 구글 드라이브 마운트
마운트 클릭으로 안될 경우 코드
from google.colab import drive drive.mount('/content/drive') -
data 훑어보기
.Tcolumn이 너무 많을 때 Tranpose -
data 재구조화
pd.pivot_table(index=[], columns='', values='', agg='')fill_values=''- Null 값인 경우 공백으로 채우기stack, unstack 알아두기
-
시각화
Library : Matplotlib, Seaborn
import matplotlib.pyplot as plt import seaborn as sns- Matplotlib 기본적 그래프, 통계, image 처리 python 대표 시각화 library
plt.bar(x축, y축)
- Seaborn Matplotlib 기반 Adds-on 성격 통계적 그래프 많음
sns.heatmap(data , annot = True # Heatmap에 숫자 표기 , fmt = '.1f' # 소수점 표기 , linewidth = 0.5 # line두께 , cmap = 'Blues | YlGnBu | RdYlBu_r' # 색 # 삼각형 반절 mask 씌우기 import numpy as np mask = np.zeros_like(heatmap, dtype=bool) mask[np.triu_indices_from(mask)] = True 이후 sns.heatmap 파라미터에 `mask = mask` 삽입sns.FacetGrid()- bar graph 드릴다운 -전체적인 그래프 레이아웃 -그래프 내용 (x축, y축) -그래프 꾸미기sns.histplot()- bargraph 여러 개 한번에sns.jointplot()- graph 2가지 이상 한 데 보여주기
df.corr()- 컬럼 간의 상관관계 숫자로df.select_dtypes( include='int').corr()- 숫자로 된 컬럼만 되므로 체크 - Matplotlib 기본적 그래프, 통계, image 처리 python 대표 시각화 library
DBeaver
- 데이터셋 읽기
SELECT * FROM schema명.table명;
- Table 분리 Numeric과 String으로
- 데이터
-
Numeric Data - Int
Type Storage(Bytes) Minimum Value Signed Maximum Value Signed TINYINT 1 -128 127 SMALLINT 2 -32768 32767 MEDIUMINT 3 -8388608 8388607 INT 4 -2147483648 2147483647 BIGINT 8 -2^63 2^63-1 -
Numeric Data - Float - 소수부분 포함 숫자
Type Storage(Bytes) 연산속도 소수점 타입 FLOAT 4 하 부동소수점 DOUBLE 8 중 부동소수점 DECIMAL 16 상 고정소수점 DECIMAL - 정교한 작업이 필요할 경우 사용
-
String
Value CHAR(4) Storage Required VARCHAR(4) Storage Required ‘’ ‘ ‘ 4 bytes '’ 1 byte 'ab’ 'ab ‘ 4 bytes 'ab’ 3 bytes 'abcd’ 'abcd’ 4 bytes 'abcd’ 5 bytes 'abcdefgh’ 'abcd’ 4 bytes 'abcd’ 5 bytes
-
- SQL 대소문자 구분
-
Windows - 구분 X
-
Linux - 구분 O
MySQL 설정값 확인
SHOW variables LIKE 'lower%'- 0:구분O / 1:구분X -
OS 상관없이 대문자 ≠소문자 구분 위해 VARBINARY로 Dtype
-
- Table 만들기 1. `CREATE TABLE TABLE명;` → `INSERT INTO;` 2. Source Table → `CREATE TABLE TABLE명 (SELECT FROM );`
- Table Join join 컬럼을 reference 컬럼에 드래그
- Window Function
-
집계된 결과값을 기존 데이터에 추가하여 보여줌
-
결과를 보여주되 결과 건수가 줄어들지 않음
-
합계, 평균, 순위, 순서 등
SELECT WINDOW_FUNTION() OVER (PARTITION BY <Column> -- 집계 기준 ORDER BY <Column>) -- 정렬 기준 FROM Table
-
- LEAD & LAG
-
LEAD : 다음 것을 가져옴
-
LAG : 먼저 것을 가져옴
SELECT LEAD|LAG (<Column>, N) -- 순서 조작 대상 (N번째 뒤|앞의 값) OVER (PARTITION BY <Column> -- 그룹핑 대상 ORDER BY <Column>) -- 정렬 기준 FROM Table
-
Power BI
- 한 페이지에 놓인 차트에 대하여 필터가 한번에 적용
csv 파일
- 테이블 속성 변경
- 컬럼명 변경
- 데이터 변환 - 첫 행을 머리글로 사용
- 데이터타입 변경
- 데이터 변환 - 컬럼 별로 변경
- 데이터 변환 - 전체 컬럼 선택 - 변환 - 데이터 형식 검색 - (변경) - 육안 확인 - 홈 - 닫기 및 적용 숫자 형식 : 자동으로 정수로 바뀜
- 컬럼명 변경
MySQL DB
- 데이터 변환
- 열 추가 - 가장 우측에 생겨남
- 예제의 열 - 선택 열 사용 - 기존 열의 값에 따라 새로운 열의 값 지정 가능
- 조건 열
- 열 병합
- 병합할 열 선택 - 열 병합
- 열 분할
- 열 선택 - 우클릭 - 열 분할
- 텍스트
- 변환 - 텍스트
- 숫자
-
변환 - 숫자
통계 : 많이 쓰지는 않음
-
- 열 추가 - 가장 우측에 생겨남
- 시각화
-
Bar Graph
-
Pie
범례 2개 이상 - 드릴다운 형성
- ↑ 드릴 업
- ↓↓ 다른 범례로 이동
-
Table
피봇 테이블과 비슷
- 기준으로 삼고싶은 컬럼 넣은 후
- 숫자형 컬럼 추가 하여 집계
-
행렬
-
Line Graph
-
- 빈 테이블 만들기 테이블 도구 - 새 테이블
Calculation = {blank()}
- 측정값 만들기 DAX 문법
CACULATE ( <expression -- 집계값> , <filter 1> , <filter 2> [, ...] )- expression
- sum
- average
- min
- max
- count
- distinctcount
- 텍스트는 “” 안에. 쌍따옴표여야 함
- expression
- Slicer : 전체 데이터에 필터를 걸어주는 것. 태블로의 매개변수 같은 것
- 적용되지 않게 하려면 slicer 클릭 - 서식 - 상호작용 편집 - 적용되지 않게 하려는 차트에서 금지 표시 누름
- 적용되지 않게 하려면 slicer 클릭 - 서식 - 상호작용 편집 - 적용되지 않게 하려는 차트에서 금지 표시 누름
- 필터 탭 해당 차트에만 필터 적용할 때 사용 필터 탭 > Slicer
