[edu] zerobase
1.[ZB] SQL - 기초

Database: 여러 사람이 공유하여 사용할 목적으로 체계화 → 통합, 관리하는 데이터 집합체 DBMS | Database Managemnet System : 사용자 요구에 따라 정보 생성, 데이터베이스 관리해주는 소프트웨어 RDB | Relational
2.[ZB] SQL - Python
pip install mysql-connector-python쿼리 작성 - execute SQLquery에Table 생성시 - CRAETE TABLE \~\~~ 쿼리Table 삭제시 - DROP TABLE \~\~~ 쿼리SQL 파일 가져오기SQL 파일 내에 쿼리가 여러
3.[ZB] GIT
형상 관리 시스템 ( Configuration Management Systems (CMS))버전 관리 시스템 ( Version Control Systems (VCS))Source Data + History(이력)협업, 작업추적, 복구 등 가능Local Version C
4.[ZB] Python
데이터 불러오기import pandas as pddf = pd.read_csv(파일명)컬럼이 한글일 때 df = pd.read_csv(파일명, \*\*encoding = ‘euc-kr’\*\*) 데이터 출력iloc : 원하는 순서, 위치에 따라 데이터 출력 loc
5.[ZB] 선형대수 - chap1. 벡터
1. 벡터의 정의 : 크기와 방향을 모두 가지는 어떤 양 우리 주변의 세계를 보고 이를 코드로 영리하게 묘사하는 방법 사물의 움직임을 프로그래밍하기 위한 가장 기본적인 구성요소 물리 및 공학 위치, 속도, 힘 등과 같은 크
6.[ZB] 선형대수 - chap2. 행렬
행렬 : 데이터가 사이즈 내에 정리되어 있는 형태$m \\times n$ 행렬 - (i, j)로 이루어짐$A{m,n} =\\begin{pmatrix}a{11} & a{12} & \\cdots & a{1n} \\a{21} & a{22} & \\cdots & a{2n} \
7.[ZB] 선형대수 - chap3. 선형대수학
선형대수학을 통해 어떻게 데이터의 해를 찾아 나가는지★★★ LU분해, 고유벡터, 대각화, 특이값 분해(SVD)선형방정식(Linear Equation) $a_1x_1 + a_2x_2 + \\cdots + a_nx_n = b$ 비선형 방정식 (Nonlinear Equa
8.[ZB] 기초통계
데이터의 종류Numerical Data(수치형): 수치 값으로 표현되는 데이터. 연속적 or 이산적ex.) 연속적 : 키, 몸무게, 온도 등ex.) 이산적 : 판매된 제품 개수, 사람 수 등분석 방법중앙값, 평균, 표준편차 등의통계적 수치를 사용시각화 - 히스토그램,
9.[ZB] 머신러닝 - Chap1. Regression|회귀
데이터정형데이터 : Table 데이터, N×P metrix, Excel Data비정형데이터 : Image, TextMachin Learning 종류지도학습 - Y가 O회귀(regression)분류(classification)비지도학습 - Y가 XClustering차원축
10.[ZB] Sample Project
제로베이스의 샘플프로젝트 수업은, 데이터 분석을 공부함에 있어 간단하지만 데이터 분석의 일련의 과정을 공부함과 더불어 다양한 도메인을 접해보는 데에 의의가 있다. 분석의 내용과 코드 또한 주어져 있지만, 하나씩 분석의 내용을 뜯어보고 곱씹어가며 흐름을 익히고, 모르는
11.[ZB] Sample Project -1
데이터 EDA + Regression 예측 (다항회귀)date 형식이 일-월-년도 였는데 pd.datetime(df’Date’)에서 오류가 생김 pd.datetime(df’Date’, format=’%d-%m-%Y’)로 했을 때는 작동했으나, 기존 결과와 차이가 있었다
12.[ZB] 머신러닝 - Chap2. Classification|분류
2가지 - 옳다 / 그르다 or 2개 이상의 Class모델의 학습 방향순도(Homogeneity)를 최대로 증가시키는 방향불순도(Impurity) or 불확실성(Uncertainty)을 최소로 감소시키는 방향Loss Function= Measuring ImpurityG
13.[ZB] SQL분석 - chap1. 시장동향이해
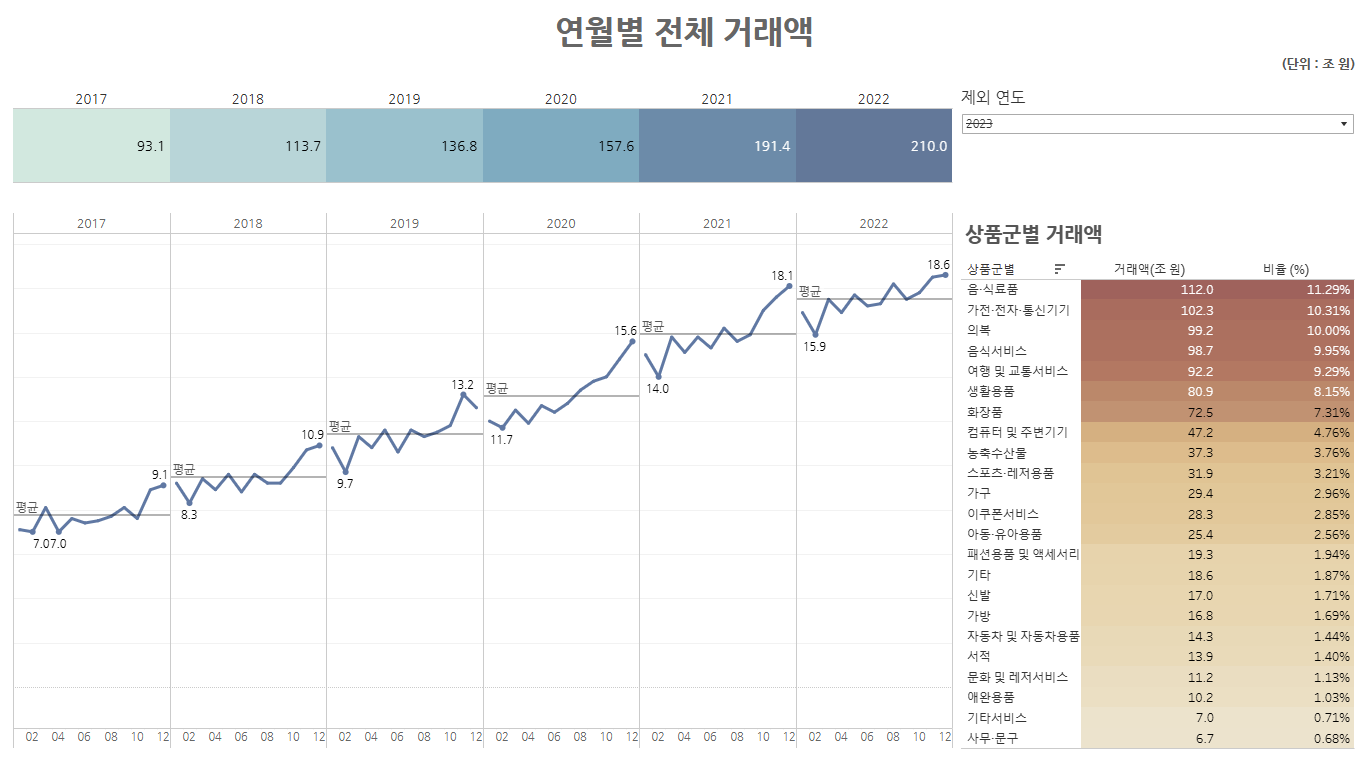
과제 - (집계/전처리) 데이터셋 체크, 지표설계 - (시각화) 인사이트BI Tool - Tableau, Looker Studio, Power BIBI ( Business intelligence )= 비즈니스 의사결정을 위한 전 과정데이터를 통한 구체적인 방향성 도출
14.[ZB] SQL분석 - chap2. 이커머스 사업현황파악
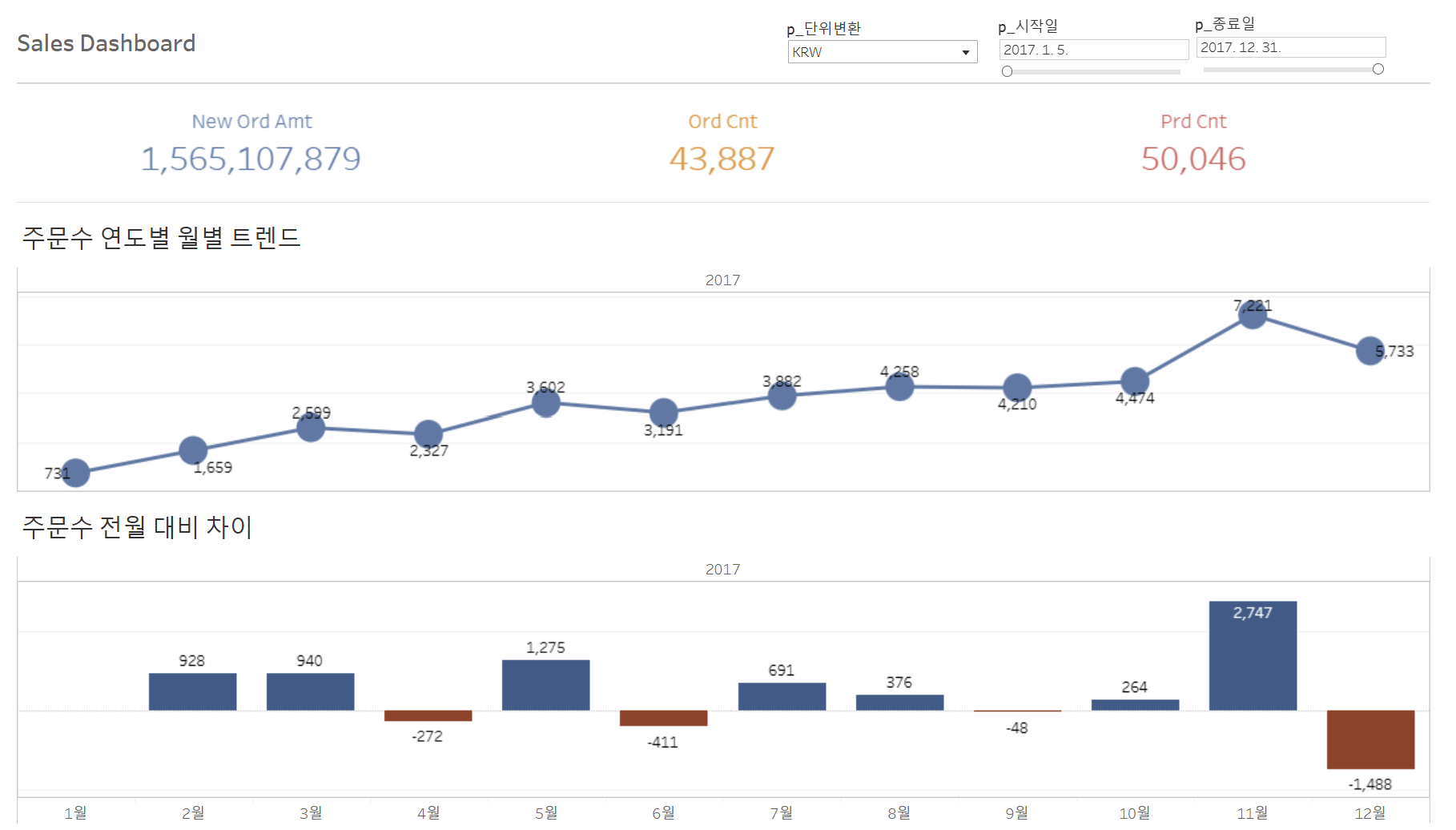
< 이커머스 주문 데이터 분석과 사업 현황 >진행방식Google Big Query태블로 / 루커스튜디오Data set : kaggle ( olist )측정되어야 하는 비즈니스 ( 지표의 중요성 )구체적인 목표 설정성공 여부 판단의 근거우선순위 설정 및 개선접근할
15.[ZB] SQL분석 - chap3. 고객 행동 분석 -> 서비스 헬스체크
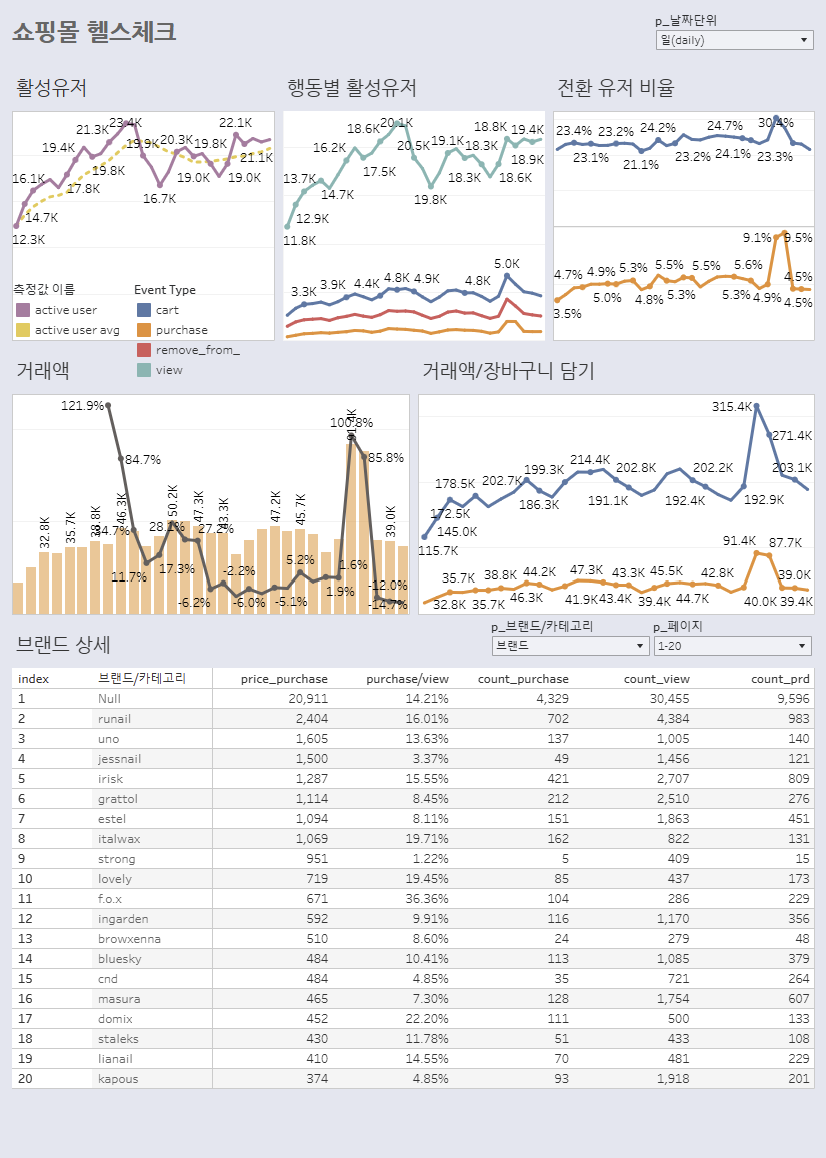
< 고객 행동 분석을 통한 서비스 헬스 체크>결제 이전에 일어나는 일은 뭘까? (고객 행동 데이터)프로덕트 기획 단계문제 발굴 및 평가, 개선신규 페이지 반응률마케팅매체 성과 관리 ( 퍼포먼스 마케팅 )배너별 클릭률누구에게 어떤 푸시Dataset : kaggle&
16.[ZB] SQL분석 - chap4. HR 데이터를 통한 채용 기획
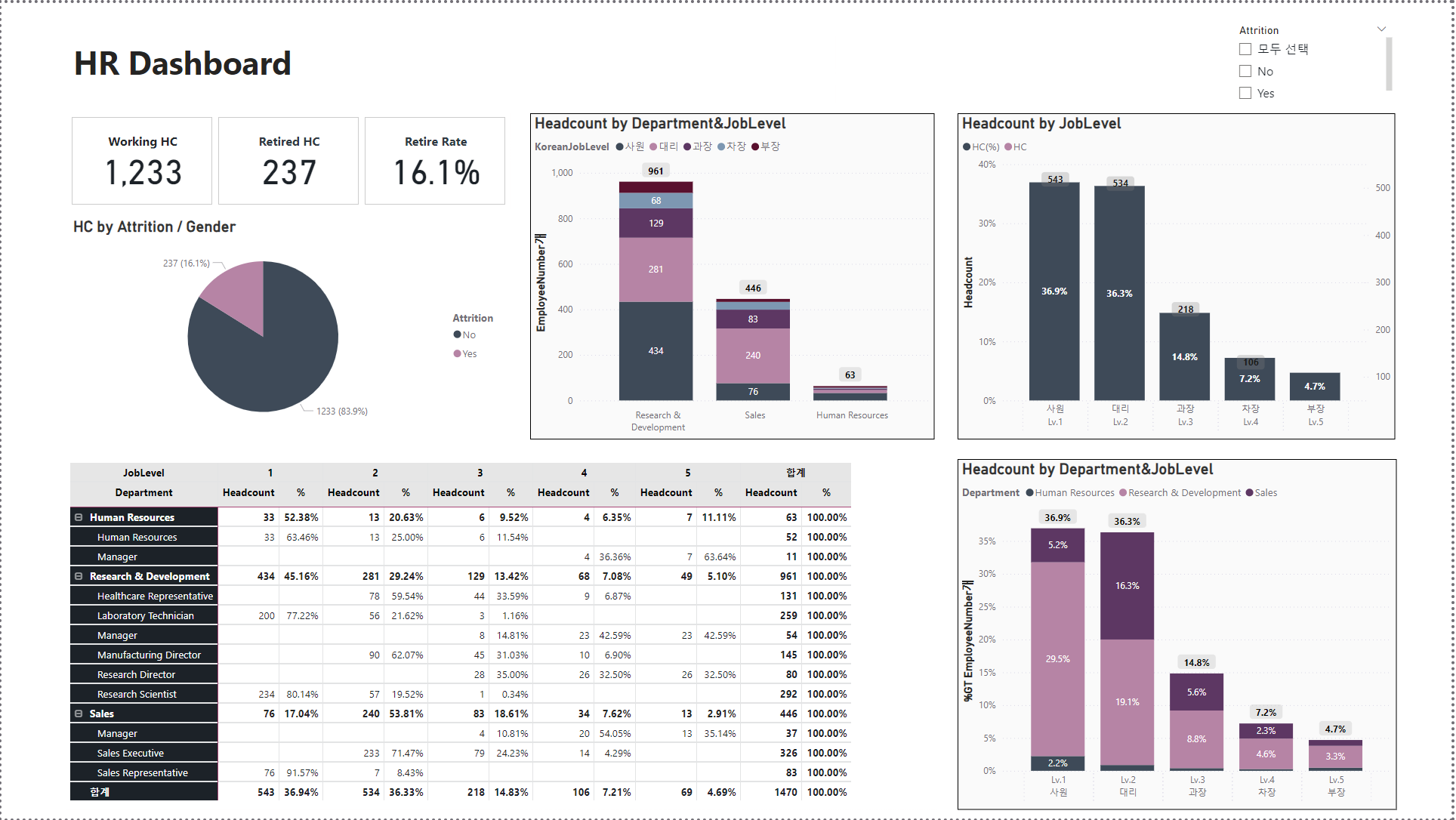
데이터 분석어떠한 비즈니스 상황과 데이터셋을 만날까?어떻게 가설을 세우고 인사이트까지 도출할까?어떤 툴을 적재적소에 활요할까?DBData적재relationship 이해ERDSQL, PythonAdhoc AnalysisEDAData TransformationBIVisua
17.[ZB] SQL분석 - chap5. 재고 분석을 통한 물류 기획 관리
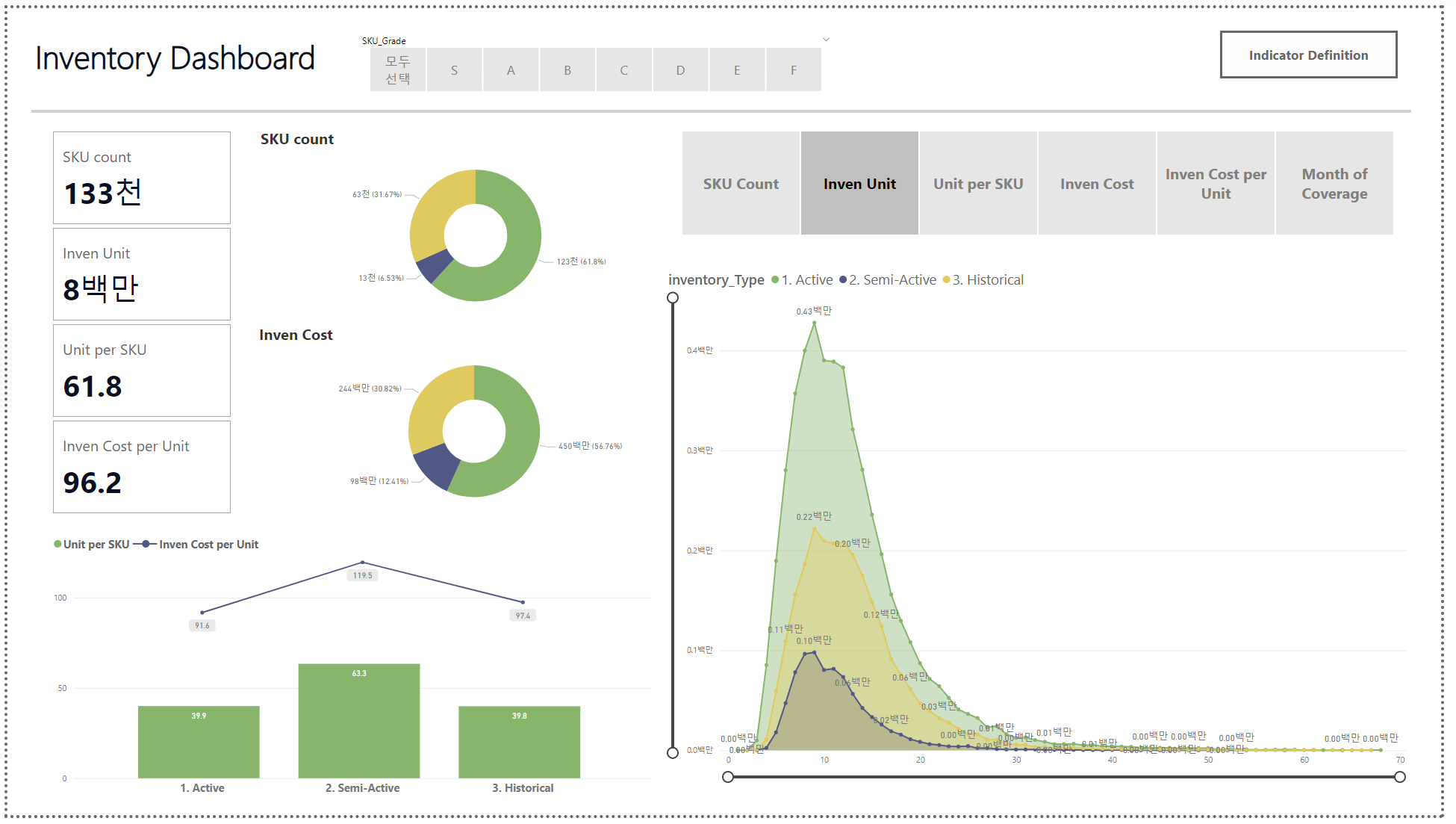
<악성 재고 파악과 관리(최소화) 방안 플랜>Historical / Active 차지 비중Historical 재고의 추산 가치?재고가 얼마나 오랫동안 창고에 보관되어 있었는지?재고를 다 판다는 가정 - 얼마나 시간이 필요?Historical 재고들에도 등급을 세워
18.[ZB] TeamProject 2 - 데이터 EDA
<취합본 내용>fraud_bool=0의 비율을 낮추어서 모델의 recall값을 올릴 수 있다f1-score 가 높아질수록 좋은 것머신러닝 코드 dacon에서 검색해서 참고해봐TabNet 공부현재까지의 스토리 작성TabNet 적용해서 f1 높게 만들기learning
19.[ZB] TeamProject 1 - 주제 선정 및 기획안 작성
우울증에 영향을 미치는 요인에 대한 분석 https://www.kaggle.com/datasets/diegobabativa/depression/data https://www.kaggle.com/datasets/muhammadfaizan65/ment
20.[ZB] SQL분석 - chap.6 유통 SCM 데이터 분석
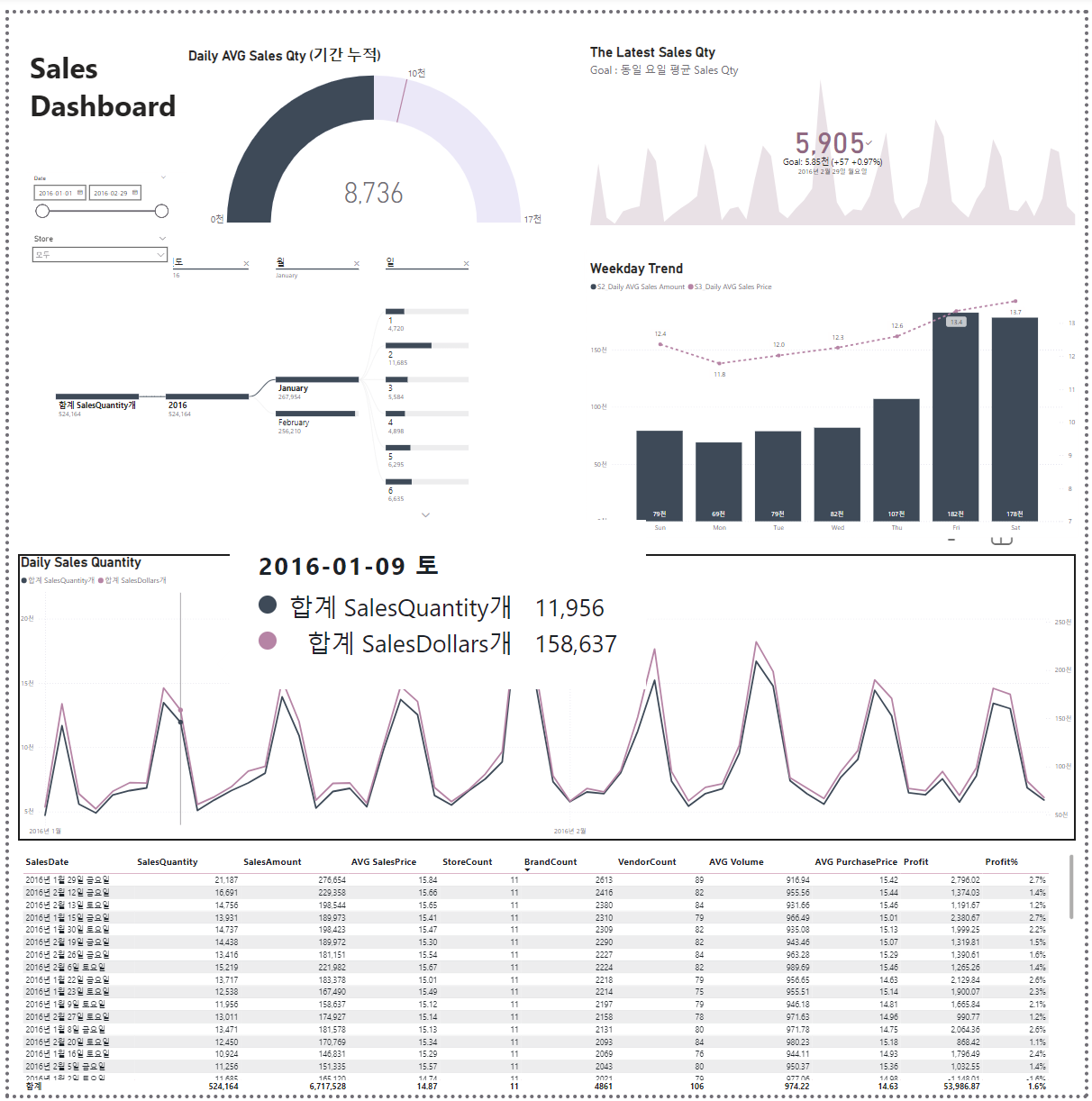
<유통/물류 Process Innovation Deep-dive Project>Role : 주류 오프라인 유통업체SCM 프로젝트 데이터 분석 담당자SCM : Supply Chain Management - 공급망 관리 공급망 구성요소들 간에 이루어지는 전체 프로세
21.[ZB] TeamProject 3 - ML + EDA(2)
Tabular 데이터에 특화된 딥러닝 모델 from pytorch_tabnet.tab_model import TabNetClassifier 특징Attention machanism : 중요하지 않은 특성에 대한 계산을 줄이고 모델의 효율성을 높임End-to-End :
22.[ZB] SQL분석 - chap.7 대규모 주류 판매 데이터
<대규모 주류 판매 데이터 분석>Role : 주류 산업 데이터 컨설턴트데이터 처리 ~ 리포팅데이터셋 : kaggleIowa Liquor Sales데이터 소개Raw 데이터를 다룰 줄 아는 능력 중요Spark - 데이터 처리,데이터 분석 + colabSQL, 스트리밍
23.[ZB] TeamProject 4 - 해석 및 정리
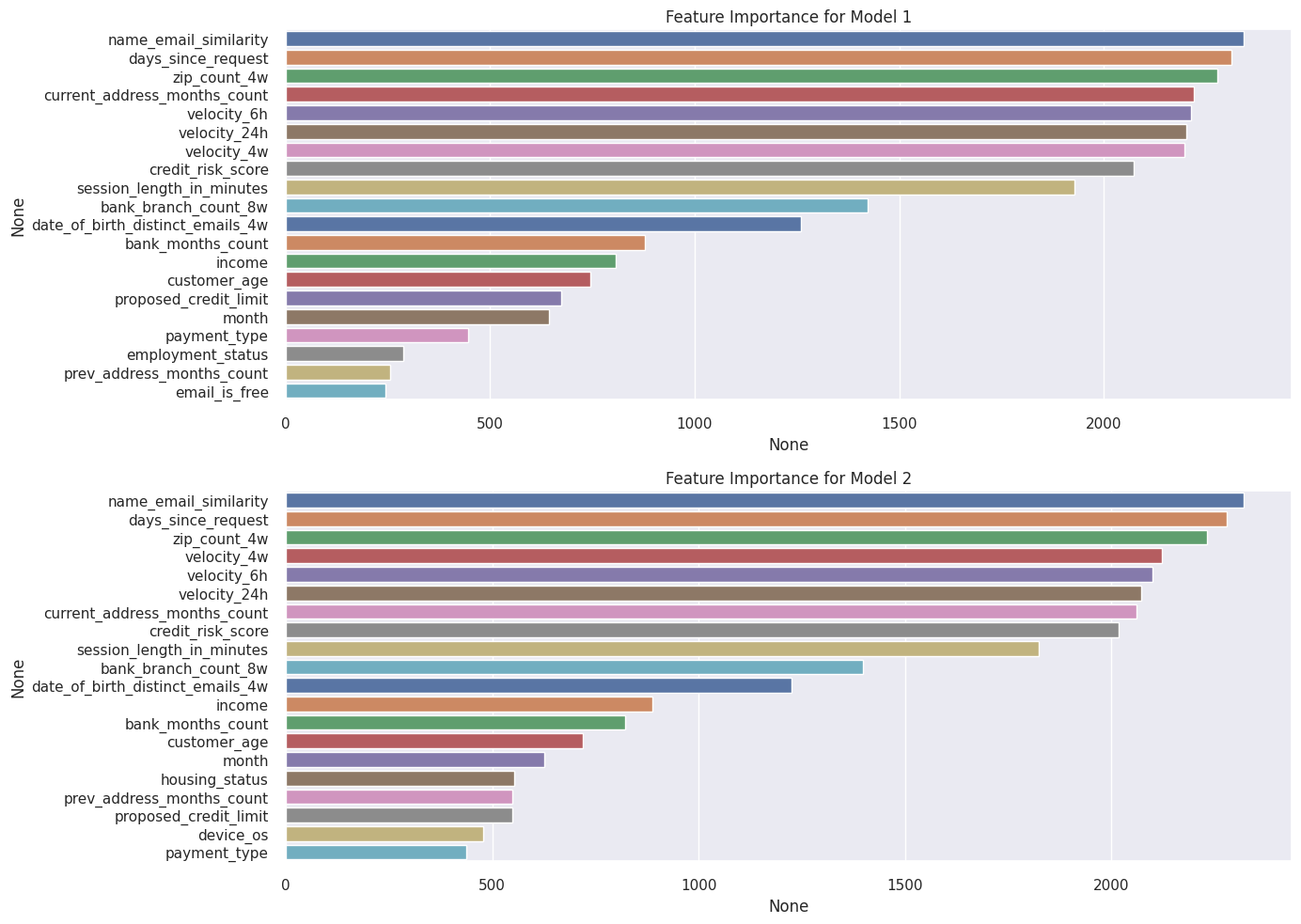
: 성능이 잘 나오지는 못하였으나 rule extraction을 참고하여 action을 추출해보았다.개요데이터 전처리Data EDA -1Modeling -1Data EDA -2Modeling -2해석
24.[ZB] SQL분석 - chap.8. 지역별 주류 판매 데이터 분석
대체적으로 SQL 복습같은 느낌이었다.메타데이터 : 다른 데이터를 설명하는 데이터정보의 효율적 압축필요 시에 join하여 활용Workbench - 비주얼데이터베이스 설계도구MySQL Connections - + - 작성 — OKschema : mysql의 데이터베이스
25.[ZB] SQL분석 - chap.9 주류 시장 대시보드 발행

chap9 주류 시장 대시보드 Tableau 링크Tableau 대시보드 : 한 화면에서 다양한 정보를 중앙집중적으로 관리하고 찾을 수 있도록 보여주는 인터페이스 복잡한 정보를 알기 쉬운 형식으로 정보를 시각화 해 표현 좋은 시각화란분석의 관점을 명확히 표현하였는지
26.[ZB] DateLemur SQL-Medium 문제풀기
User's Third Transaction Tweets' Rolling Averages Highest-Grossing Items Top 5 Artists Supercloud Customer Histogram of Users and Purchases Compressed Mode International Call Percentage
27.[ZB] "제로베이스 데이터분석 취업스쿨" (슬) 마무리 후기
"데이터분석취업스쿨 소개페이지"로 바로가기
28.[ZB] FinalProject
\- 거래이력 데이터\*SKU(Stock Keeping Unit) : 재고 관리를 위한 최소 단위 코드 \- 광고 및 투자 내역아마 각 항목에 들인 비용으로 추정<NPS_Stockindex> NPS(고객충성도 지표), Stock Index(주가 지수) 정보 -