해석
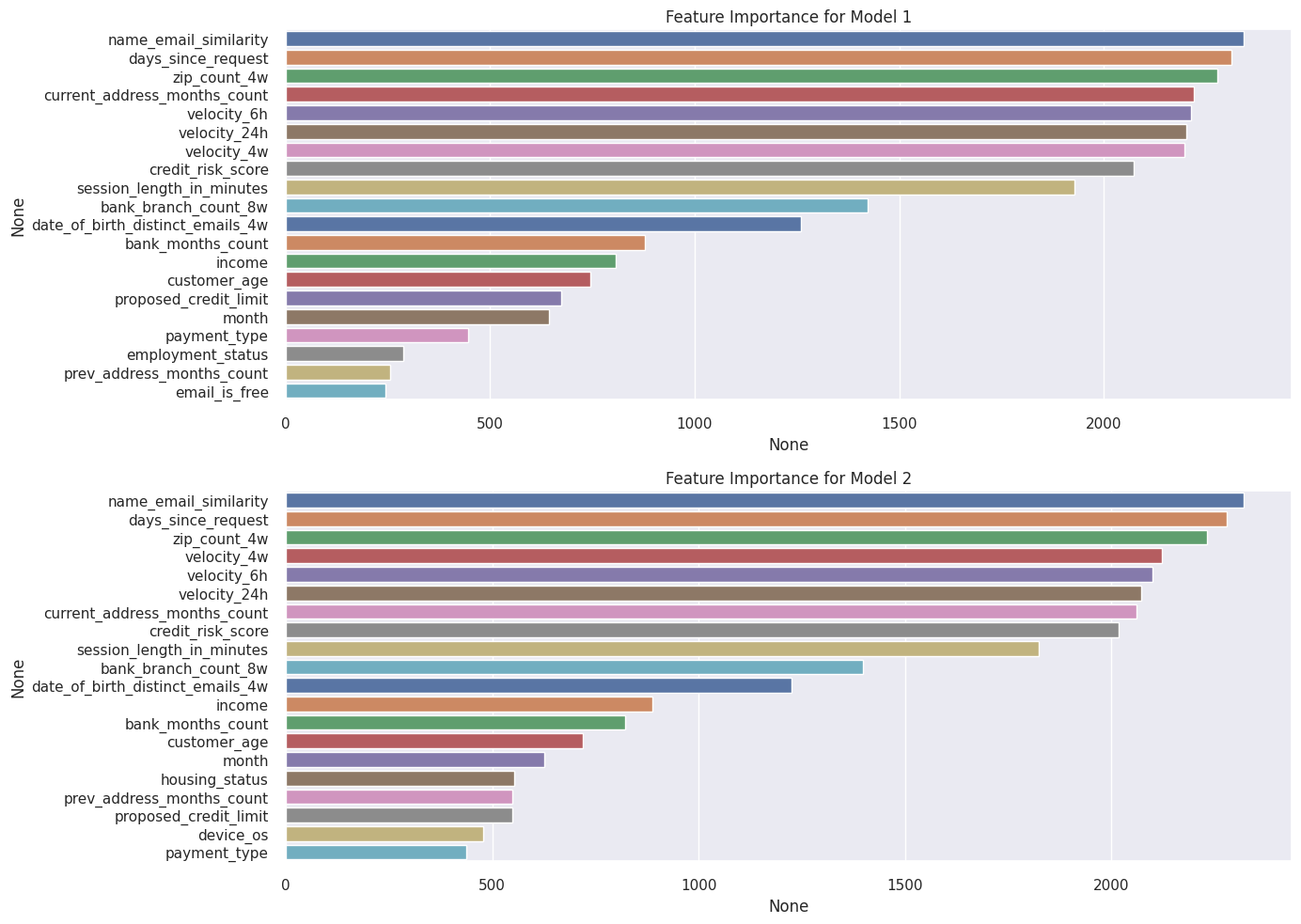
1. Feature Importance
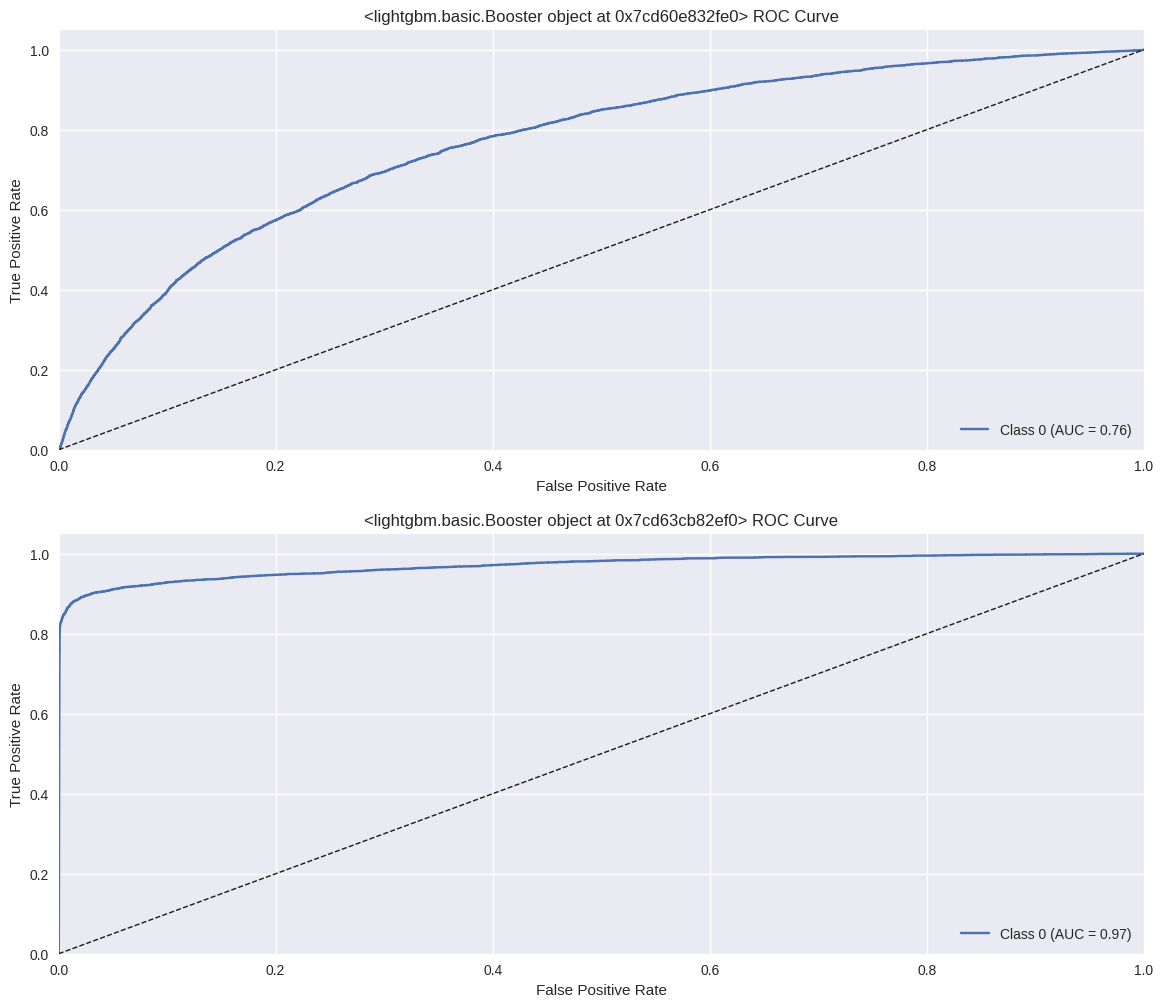
2. ROC Curve
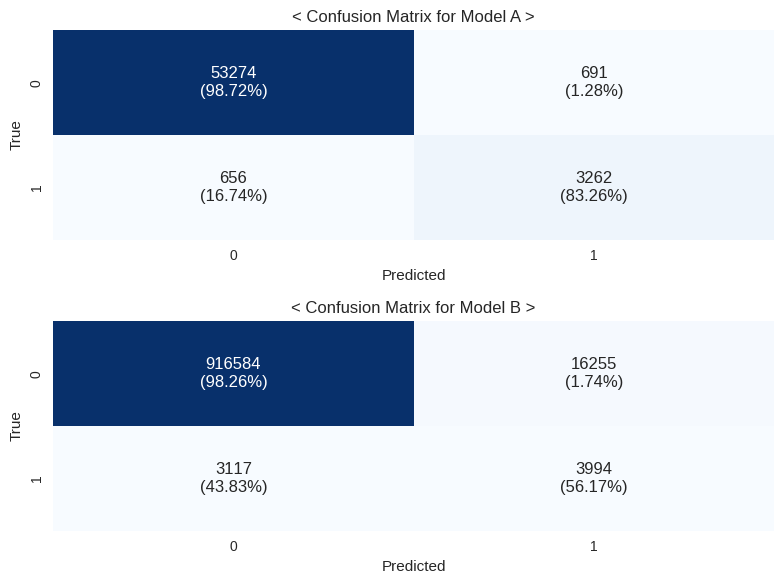
3. Confusion Matrix
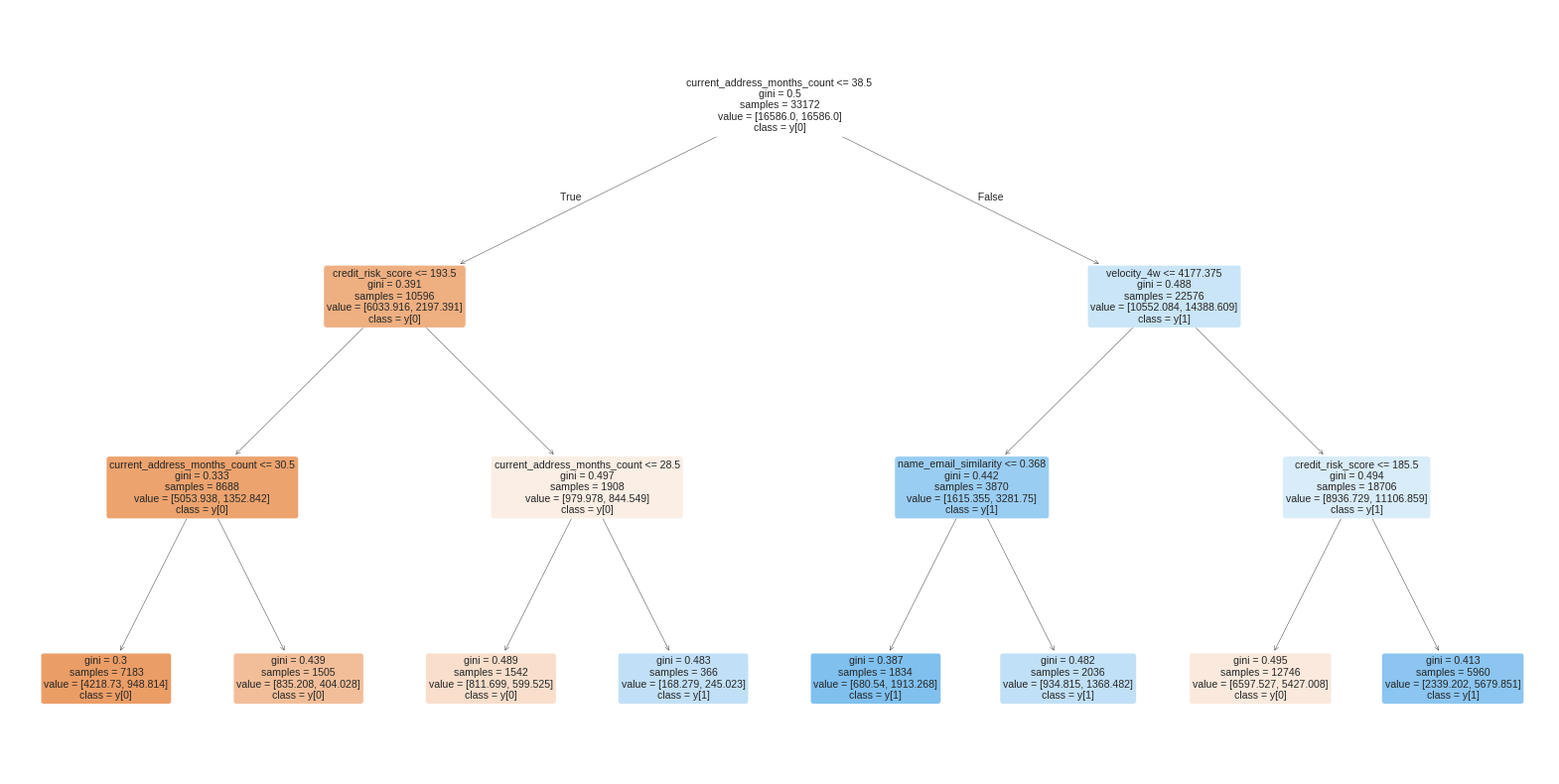
4. Decision Tree
: 성능이 잘 나오지는 못하였으나 rule extraction을 참고하여 action을 추출해보았다.
Accuracy: 0.7050524538767635
Classification Report:
precision recall f1-score support
0 0.87 0.74 0.80 6611
1 0.35 0.55 0.43 1682
accuracy 0.71 8293
macro avg 0.61 0.65 0.62 8293
weighted avg 0.76 0.71 0.73 8293
|--- current_address_months_count <= 38.50
| |--- credit_risk_score <= 193.50
| | |--- current_address_months_count <= 30.50
| | | |--- class: 0
| | |--- current_address_months_count > 30.50
| | | |--- class: 0
| |--- credit_risk_score > 193.50
| | |--- current_address_months_count <= 28.50
| | | |--- class: 0
| | |--- current_address_months_count > 28.50
| | | |--- class: 1
|--- current_address_months_count > 38.50
| |--- velocity_4w <= 4177.38
| | |--- name_email_similarity <= 0.37
| | | |--- class: 1
| | |--- name_email_similarity > 0.37
| | | |--- class: 1
| |--- velocity_4w > 4177.38
| | |--- credit_risk_score <= 185.50
| | | |--- class: 0
| | |--- credit_risk_score > 185.50
| | | |--- class: 1결론
각각의 군집 A와 B에 대한 모델 A, B에 대하여 해석해보았다.
두 모델에서 높은 Feature Importance를 가진 feature은 순서만 조금 다를 뿐 동일하였다.
['name_email_similarity', 'days_since_request', 'zip_count_4w', 'current_address_months_count',
'velocity_6h', 'velocity_24h', 'velocity_4w', 'credit_risk_score', 'session_length_in_minutes']
Feature Importance가 눈에 띄게 감소하는 영역을 제외한 상위 9개의 feature을 통해 Decision Tree를 만들고자 한다.
ROC Curve를 통해 모델 B의 AUC값이 0.97임을 확인했다.
Confusion Matrix를 통해 각 군집 전체에 대하여 fraud 계좌를 알맞게 예측한 경우와, 일반계좌이나 모델이 fraud 계좌로 예측한 경우의 수를 확인했다.
알맞게 예측한 경우는 각각 3262건 (83.26%), 3994(56.17%)으로 전체 데이터셋에 대하여 7256(65.79%)만큼 이다.
후자의 경우, 모델의 예측에 따라 은행이 주의해서 볼 계좌로 분류해볼 수 있다.
이는 각각 691(1.28%), 16255(1.74%)으로 전체 데이터셋에 대하여 16946 (1.71%)만큼이다.
Decision Tree에서는 높은 Accuracy와 f1-score을 얻지 못하였고, 각 노드의 불순도가 높으나
depth가 낮은 rule로부터 주의 계좌에 대하여 어떤 사항을 확인할 지 참고할 수 있다.Storyline (수정 및 추가)
개요
다양한 사기가 만연해지는 요즈음 큰 재산피해를 야기하는 은행 및 금융 사기에 관한 데이터를 다뤄보려 한다. 그 중 저작권이 있는 실제 데이터이며, 변종의 데이터셋을 가진 데이터를 선택해 EDA와 모델링까지 진행하고자 한다. 유용한 정보를 통해 인사이트를 도출하고, 시각화하는 능력을 향상시킬 뿐 아니라 분류 모델링 능력을 향상시킬 수 있고, 더 나아가 다른 사기 분야에 대하여서도 활용할 수 있을것이라 생각한다.
데이터 전처리
데이터 전처리 과정 중에, 데이터 명세에 결측치가 -1이라고 명시되어 있으나 그 밖의 음수값이 많은 컬럼이 있어 드랍하였다.(’intended_balcon_amount’) 이외 다른 컬럼에 대하여 명시된 결측치는 개수가 극히 적고, 신규 계좌일 경우 결측치가 발생할 수 있다고 여겨 따로 처리하지 않고 진행하였다.
Data EDA -1
31개의 컬럼 중 범주형 변수를 가진 컬럼, 숫자 형식으로 되어 있으나 범주형 변수와 같은 컬럼, 그리고 연속형 변수를 가진 컬럼으로 분류하여 데이터 EDA를 진행하였다. 각 컬럼에 대하여 전체 사기계좌 비율 이상인 클래스를 확인하고서, 3차원 플랏을 통해 군집을 찾고자 하였다. 이 중 범주형 변수를 가진 컬럼으로부터 전체 사기 계좌 중 높은 점유율을 가지며, 전체 계좌에 대한 사기 계좌의 확률에 비해 높은 확률로 사기 계좌인 군집을 발견하였다. housing_status = ‘BA’ & device_os = ‘windows’ - 군집A 내 사기 계좌 = 전체 사기 계좌의 36% - 군집A 내 사기 계좌 비율 = 6.7% ( 전체 데이터셋 사기 계좌 비율 = 1.1% ) 먼저 군집A에 대하여 이진분류 모델링을 설계했다.
Modeling -1
다양한 모델을 사용해 모델을 탐색한 결과, TabNet과 lightGBM 모델을 중점으로 발전시켜나가기로 하였다. 전체 데이터 수(1000k)에 비해 사기 계좌 데이터 수(10k)가 적기 때문에 일반 계좌에 대하여 데이터 샘플링을 해보거나, 모델 판단 시 loss를 f1-score로 보기로 하였다. 실제로 모델 테스트 중 사기 계좌에 대하여 언더샘플링하면 f1-score이 좋아진다는 사실을 발견하였다. 먼저 TabNet모델을 설계하는 중에 파라미터 조정을 통해서도 f1-score이 0.48 이상으로 좋아지지 않는 것 같아 lightGBM 모델을 사용해보기로 했다. lightGBM을 사용하였을 때, 가장 먼저 전체 데이터에 대한 모델의 경우 사기계좌에 대한 f1-score가 0.3이어서, 언더샘플링을 해보았다. 일반 계좌에 대하여 다양한 비율로 샘플링을 하여 학습시켰고, 테스트는 전체 데이터에 대하여 진행하였다. 모델을 통하여 군집A fraud의 87.6%를 검출했다. 이것은 전체 fraud의 31.1%이다.
Data EDA -2
먼저 분류한 군집 A을 제외한 데이터셋을 가지고 한 번 더 EDA를 진행한다. 위와 동일하게 변수의 성질에 따라 컬럼을 분류해 분석하였다. 그 결과 군집 B를 발견했다. 'has_other_cards' == 0 & 'keep_alive_session' == 0 - 군집B 내 사기 계좌 = 전체 사기 계좌의 59.34% - 군집B 내 사기 계좌 비율 = 2.1% ( 전체 데이터셋 사기 계좌 비율 = 1.1% ) 군집B에 대하여 이진분류 모델링을 설계했다.
Modeling -2
위의 모델링을 참고하여 lightGBM 모델을 발전시켰다. 먼저 하이퍼 파라미터 최적화를 진행 후, 언더 샘플링을 통해 적절한 비율로 샘플링하였다. 이후 샘플링된 데이터에 대하여 하이퍼 파라미터 최적화를 한 번 더 진행하였다. 진행 중에 threshold값에 따라 fraud=1의 f1-score이 높아지는 것을 볼 수 있었다. 모델을 통하여 군집B fraud의 72.6%를 검출했다. 이것은 전체 fraud의 43.1%이다.
해석
각각의 군집 A와 B에 대한 모델 A, B에 대하여 해석해보았다. - 두 모델에서 높은 Feature Importance를 가진 feature은 순서만 조금 다를 뿐 동일하였다. ['name_email_similarity', 'days_since_request', 'zip_count_4w', 'current_address_months_count', 'velocity_6h', 'velocity_24h', 'velocity_4w', 'credit_risk_score', 'session_length_in_minutes'] Feature Importance가 눈에 띄게 감소하는 영역을 제외한 상위 9개의 feature을 통해 Decision Tree를 만들고자 한다. - ROC Curve를 통해 모델 B의 AUC값이 0.97임을 확인했다. - Confusion Matrix를 통해 각 군집 전체에 대하여 fraud 계좌를 알맞게 예측한 경우와, 일반계좌이나 모델이 fraud 계좌로 예측한 경우의 수를 확인했다. 알맞게 예측한 경우는 각각 3262건 (83.26%), 3994(56.17%)으로 전체 데이터셋에 대하여 7256(65.79%)만큼 이다. 후자의 경우, 모델의 예측에 따라 은행이 주의해서 볼 계좌로 분류해볼 수 있다. 이는 각각 691(1.28%), 16255(1.74%)으로 전체 데이터셋에 대하여 16946 (1.71%)만큼이다. - Decision Tree에서는 높은 Accuracy와 f1-score을 얻지 못하였고, 각 노드의 불순도가 높으나 depth가 낮은 rule로부터 주의 계좌에 대하여 어떤 사항을 확인할 지 참고할 수 있다. 위의 Tree의 경우 위험 계좌에 대하여 'current_address_months_count'의 값이 38.50이하인지부터 확인해나갈 수 있다.
