1. 모델 학습 기술
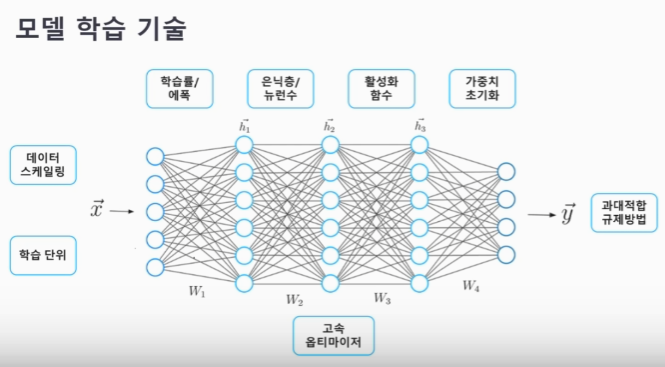
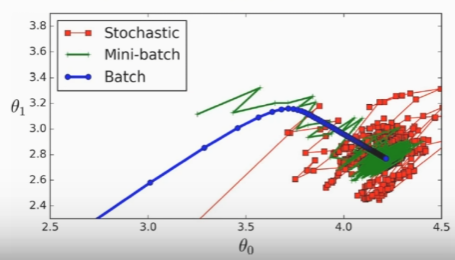
1-1. 학습 단위

1-2. 데이터 스케일링

1-3. 학습률과 에폭

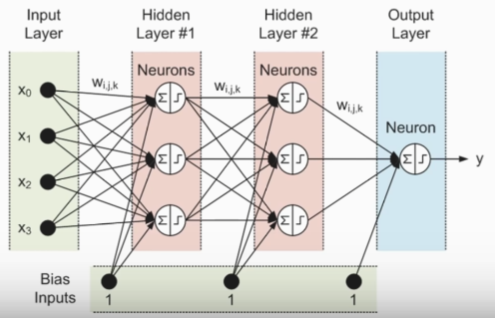
1-4. 은닉층과 뉴런수

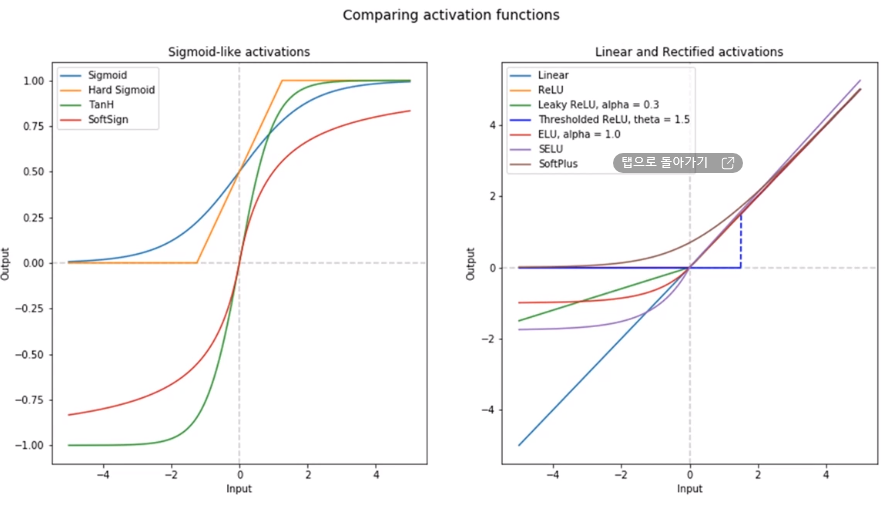
1-5. 활성화 함수

1-6. 가중치 초기화


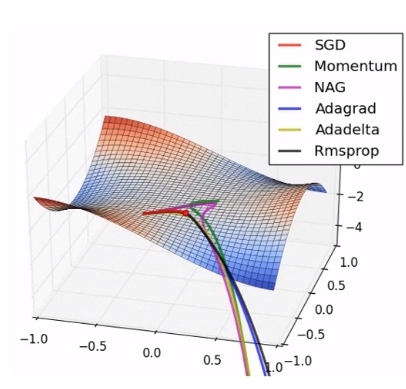
1-7. 옵티마이저
: 모델이 실제값, 예측값 차이를 최소화 하는 역할 수행

정리문제
Q. 모든 데이터를 한 번에 넣고 학습시키는 전체 배치(Full Batch)방식이 있는데 왜 분할하여 넣는 미니 배치(Mini Batch) 방식을 사용하나요?
딥러닝은 많은 양의 데이터를 필요로 하고 모든 데이터를 한 번에 불러와서(load) 학습 시키는 것은 많은 리소스가 낭비되기 때문입니다.
Q. 대표적인 데이터 스케일링 방법인 표준화(Standardization)와 정규화(Normalization)은 어떤 차이가 있나요?
표준화(Standardization)와 정규화(Normalization)는 데이터 전처리 기법으로, 데이터를 모델에 사용하기 전에 스케일을 조정하는 방법입니다. 주로 데이터의 특성 간 스케일을 일정하게 맞추어 모델의 성능을 향상시키거나 학습 속도를 개선하기 위해 사용됩니다.
표준화는 평균이 0이지만 데이터 크기에 대한 제한이 없으며 정규화는 최대, 최소값이 각각 1과 0으로 정해져있습니다.
표준화(Standardization):
평균을 0으로, 표준편차를 1로 만들어 데이터를 조정하는 방법입니다.
주로 Z-score 정규화 방법을 사용하며, 각 데이터에서 평균을 빼고 표준편차로 나누어줍니다.
표준화는 이상치(outlier)에 덜 민감하고, 데이터가 정규분포를 따를 때 좋은 성능을 보입니다.
주로 회귀 분석이나 신경망과 같이 평균과 분산이 중요한 모델에서 사용됩니다.
정규화(Normalization):
데이터의 범위를 [0, 1] 또는 [-1, 1]로 조정하는 방법입니다.
주로 최솟값을 빼고 최댓값과 최솟값의 차이로 나누어줍니다. 또는 데이터의 크기를 유지하면서 범위를 조절합니다.
데이터의 상대적 크기를 비교할 때 사용하며, 이상치에 영향을 받을 수 있습니다.
주로 이미지 처리나 거리 기반 알고리즘 등에서 사용됩니다.
간단히 말해, 표준화는 평균과 표준편차를 사용하여 데이터를 조정하는 반면, 정규화는 최솟값과 최댓값을 사용하여 데이터의 범위를 조정합니다. 데이터의 분포나 사용하는 모델에 따라 어떤 전처리 방법을 선택할지가 달라집니다.
Q. 손실 함수의 최저값에 도달하기 위해선 학습률이 작을 수록 일반적으로 에폭의 수는 어떻게 될까요?
많아집니다. 학습률이 작은 경우 최저값에 도달하기까지 업데이트 횟수가 더 많이 필요하다는 의미이기 때문입니다.
작은 학습률을 사용하면, 각 반복(에폭)마다 모델이 손실 곡선을 따라 천천히 움직이게 됩니다. 이는 손실 함수의 최저값에 점차적으로 가까워지지만, 수렴하는 데 더 많은 반복이 필요할 수 있습니다. 따라서 에폭 수는 증가할 수 있습니다.
그러나 이것은 절대적인 규칙은 아닙니다. 때로는 적절한 학습률과 다른 하이퍼파라미터 설정에 따라 손실 함수의 최저값에 도달하는 데에도 적은 에폭이 필요할 수 있습니다. 또한, 학습률을 너무 낮게 설정하면 최적값에 수렴하지 못하거나 지역 최적값에 갇힐 수도 있습니다.
Q. 활성화함수에는 시그모이드(Sigmiod)계열과 렐루(ReLU)) 두가지 계열로 나뉘는데 두 계열간 어떤 차이가 있나요?
활성화 함수는 신경망의 각 층에서 출력을 결정하는 함수입니다. 시그모이드(Sigmoid) 함수와 렐루(Rectified Linear Unit, ReLU) 함수는 두 가지 주요 활성화 함수 중 하나로, 각각의 특성과 차이가 있습니다.
시그모이드(Sigmoid) 함수:
값의 범위:[0,1], 혹은 [-1,1] 사이에 위치하는 S 모양의 곡선 형태를 가집니다.
특징:
입력값을 0과 1 사이의 값으로 압축합니다. 이는 출력값을 확률로 해석하는데 유용하게 사용됩니다.
그러나 시그모이드 함수는 입력값이 크거나 작을 때 그래디언트(기울기)가 소실되는 문제를 가질 수 있습니다. 이것은 역전파 과정에서 기울기 소실로 인해 학습이 어려워질 수 있음을 의미합니다.
출력값이 양 끝으로 갈수록 그래디언트가 거의 0에 가까워지므로, 그 지점에서는 가중치의 업데이트가 거의 이루어지지 않습니다.
사용: 이진 분류 문제에서 출력층에 주로 사용됩니다.
렐루(Rectified Linear Unit, ReLU) 함수:
값의 범위: 입력값이 0보다 작으면 0으로, 0보다 크면 그대로 반환하는 함수입니다.
특징:
입력값이 양수인 경우 그대로 반환하기 때문에 시그모이드보다 연산 속도가 빠르며, 그래디언트 소실 문제가 덜 발생합니다.
죽은 렐루(dying ReLU) 문제: 입력값이 음수일 때, 그래디언트가 0이 되는 문제가 발생할 수 있습니다. 이 문제를 해결하기 위해 변형된 Leaky ReLU, Parametric ReLU 등이 제안되었습니다.
사용: 주로 은닉층에서 사용되며, 다양한 신경망 모델에서 성능이 좋게 나타나는 경우가 많습니다.
요약하자면, 시그모이드 함수는 출력을 0과 1 사이로 압축하여 확률로 해석하는 데 유용하지만, 그래디언트 소실 문제가 있습니다. 반면 ReLU 함수는 연산이 빠르고 그래디언트 소실 문제가 적지만, 음수 입력값에 대해 0을 출력하며 이로 인해 죽은 렐루 문제가 발생할 수 있습니다. 그러므로 문제의 특성과 데이터에 맞게 적절한 활성화 함수를 선택하는 것이 중요합니다.
Q. 적절한 가중치 초기값을 정해주는 것은 어떤 효과를 가져올 수 있나요?
적절한 가중치 초기값을 선택하는 것은 신경망 학습에 중요한 영향을 미칠 수 있습니다. 올바른 초기화 방법을 사용하면 학습이 빠르고 안정적으로 이루어질 수 있습니다. 몇 가지 효과는 다음과 같습니다:
학습 속도 향상: 적절한 초기화는 신경망이 수렴하는 데 필요한 학습 속도를 높일 수 있습니다. 잘 초기화된 가중치는 처음부터 합리적인 값을 갖기 때문에 모델이 빠르게 수렴할 수 있습니다.
경사 하강법 안정화: 초기값이 잘못되면 기울기 소실 또는 폭주 문제가 발생할 수 있습니다. 적절한 초기화는 이러한 문제를 방지하고, 기울기 소실이나 폭주를 줄여 안정적인 학습을 가능하게 합니다.
지역 최적점 회피: 가중치 초기화 방법은 모델이 지역 최적점에 빠지는 것을 방지할 수 있습니다. 무작위 초기화나 특정 초기화 방법을 통해 다양한 초기 가중치를 시도함으로써, 더 나은 전역 최적점에 도달할 수 있습니다.
규제 효과: 일부 초기화 방법은 가중치를 적절히 제약하여 오버피팅을 줄이는 효과를 가질 수 있습니다.
가중치 초기화는 모델의 성능과 학습 속도에 영향을 미치므로 중요한 부분입니다. 따라서 Xavier 초기화, He 초기화와 같은 효과적인 초기화 방법을 사용하여 모델을 학습시키는 것이 좋습니다.
Q. 옵티마이저의 역할과 목적은 무엇인가요?
옵티마이저(optimizer)는 신경망 모델의 학습 과정에서 사용되는 최적화 알고리즘입니다. 이 알고리즘은 손실 함수의 값을 최소화하기 위해 가중치를 조정하는 방법을 제공합니다.
옵티마이저의 주요 목적은 다음과 같습니다:
가중치 업데이트: 옵티마이저는 가중치를 업데이트하며, 손실 함수를 최소화하는 방향으로 모델을 학습시킵니다. 이 과정은 경사 하강법(Gradient Descent) 알고리즘을 사용하여 이루어집니다.
수렴: 모델이 최적의 가중치를 찾아가는 수렴 과정을 관리합니다. 이 과정에서 옵티마이저는 학습률, 모멘텀 등을 사용하여 손실을 최소화하는 방향으로 이동하며, 최적화를 통해 가중치를 조정합니다.
학습 속도 조절: 학습률(learning rate)과 같은 하이퍼파라미터를 조정하여 학습 과정의 속도와 안정성을 관리합니다. 학습률은 가중치 업데이트에 사용되며, 모델의 성능에 큰 영향을 줍니다.
최적화 기법 적용: 다양한 최적화 알고리즘을 제공하여 모델의 학습을 최적화합니다. Adam, RMSprop, SGD 등 다양한 옵티마이저가 있으며, 각각의 알고리즘은 특정한 학습 환경에 적합한 방법을 제공합니다.
따라서 옵티마이저는 신경망이 학습 데이터로부터 패턴을 학습하고 손실을 최소화하는 방향으로 모델을 조정하는 핵심적인 역할을 합니다. 학습률과 같은 하이퍼파라미터를 튜닝하여 올바른 옵티마이저를 선택하는 것은 모델의 성능을 향상시키는 데 중요합니다.
2. 과소적합과 과대적합
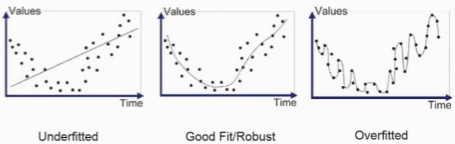
2-1. 과소적합

2-2. 과대적합

3. IMDB 딥러닝 모델 예제
IMDB 데이터셋은 영화 사이트 IMDB의 리뷰 데이터를 모아놓은 것으로
텍스트 분류, 감성 분류를 위해 자주 사용하는 데이터입니다.
데이터셋은 리뷰 텍스트와 레이블로 구성되어 있고,
레이블은 리뷰가 긍정인 경우 1을
부정인 경우 0으로 표시
3-1. 데이터 로드 및 전처리
케라스에서는 IMDB 영화 리뷰 데이터를 imdb.load_data() 함수를 통해 다운로드가 가능.
예제로 사용하는 것이니 num_words는 10000개로만 제한하여 데이터를 로드합니다.
즉, 단어의 인덱스는 0부터 9999까지만 구성됩니다.
train_data의 0번째를 출력해보면 단어들의 인덱스가 출력되는 것을 알 수 있습니다. 그리고 train_label의 0번째를 출력하면 긍정을 의미하는 1이 출력되는 것을 알 수 있습니다.
from keras.datasets import imdb
import numpy as np
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print(train_data[0])
print(train_labels[0])
IMDB의 데이터셋은 인덱스로만 구성되어 있기 때문에
실제 단어들로 변환하기 위해서는 단어 인덱스 딕셔너리를 이용해야하며, imdb.get_word_index() 함수를 통해 얻을 수 있습니다.
아래 word_index 딕셔너리를 확인하실 수 있습니다.
(스크롤 압박😅)
word_index = imdb.get_word_index()
word_index단어 인덱스 딕셔너리를 인덱스 단어 딕셔너리 형태로 역으로 변환시킵니다.
아래 index_word 딕셔너리를 확인하실 수 있습니다.
(스크롤 압박😅)
index_word = dict([(value, key) for (key, value) in word_index.items()])
index_wordimdb.get_word_index() 를 통해 얻은 데이터의 index는
단어 출현 빈도 기준으로 내림차수 정렬되어있습니다.
따라서 아래 코드블럭의 index_word 의 키 값을 바꿔가며
해당 출현 빈도 순에 해당하는 단어를 살펴볼 수 있어요.
# 1 순위의 출현 빈도를 기록한 단어를 출력합니다.
# 키 값의 숫자를 바꿔가며 다른 순위의 단어들도 확인해볼 수 있어요!
index_word[1]'the'
Q. 25번째 단어를 키로 삼아 word_index에 어떤 값(value)가 담겨있는지 확인해 봅시다.
word_25th = index_word[25]
print(word_25th)have
train_data[0]의 각 인덱스에 매핑되는 단어들로 연결하여 하나의 리뷰를 만들어 줍니다.
review = ' '.join([str(i) for i in train_data[0]])
review'1 14 22 16 43 530 973 1622 1385 65 458 4468 66 3941 4 173 36 256 5 25 100 43 838 112 50 670 2 9 35 480 284 5 150 4 172 112 167 2 336 385 39 4 172 4536 1111 17 546 38 13 447 4 192 50 16 6 147 2025 19 14 22 4 1920 4613 469 4 22 71 87 12 16 43 530 38 76 15 13 1247 4 22 17 515 17 12 16 626 18 2 5 62 386 12 8 316 8 106 5 4 2223 5244 16 480 66 3785 33 4 130 12 16 38 619 5 25 124 51 36 135 48 25 1415 33 6 22 12 215 28 77 52 5 14 407 16 82 2 8 4 107 117 5952 15 256 4 2 7 3766 5 723 36 71 43 530 476 26 400 317 46 7 4 2 1029 13 104 88 4 381 15 297 98 32 2071 56 26 141 6 194 7486 18 4 226 22 21 134 476 26 480 5 144 30 5535 18 51 36 28 224 92 25 104 4 226 65 16 38 1334 88 12 16 283 5 16 4472 113 103 32 15 16 5345 19 178 32'
review = ' '.join([index_word.get(i-3, '?') for i in train_data[0]])
review"? this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ? is an amazing actor and now the same being director ? father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for ? and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also ? to the two little boy's that played the ? of norman and paul they were just brilliant children are often left out of the ? list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
텍스트 데이터를 딥러닝 모델의 학습에 사용하기 위해서는
원-핫 인코딩(one-hot encoding)을 이용해 0과 1의 벡터로 변환하여 Dense 레이어를 사용하는 방법이 있고,
그 밖에도 고정 길이를 가지도록 패딩(padding)을 추가하고
임베딩(embedding) 레이어를 사용하는 방법이 있습니다.
이 예제에서는 10000 차원을 가지는 원-핫 인코딩으로
IMDB 데이터를 처리하도록 합니다.
패딩(padding)과 임베딩(embedding)은 자연어 처리(Natural Language Processing, NLP) 분야에서 사용되는 중요한 개념입니다.
패딩(padding):
시퀀스 데이터의 길이를 맞추기 위해 사용되는 기술입니다. 특히, 텍스트나 문장 등의 변수 길이의 시퀀스 데이터를 처리할 때 사용됩니다.
패딩은 주로 시퀀스 데이터의 길이를 통일하기 위해 짧은 시퀀스에 0과 같은 특정한 값으로 채워 넣는 것을 말합니다. 이를 통해 모든 데이터가 동일한 길이를 갖도록 만들어줍니다.
예를 들어, 문장 길이가 다른 데이터셋에서 모든 문장의 길이를 동일하게 만들기 위해 패딩을 사용할 수 있습니다. 이는 대부분의 딥러닝 모델에서 등장하는 고정된 입력 길이를 요구하는 경우에 유용합니다.
임베딩(embedding):
단어나 문장을 벡터 형태로 변환하는 기법입니다. 이는 텍스트 데이터를 숫자로 표현하여 모델이 이해하고 처리할 수 있도록 합니다.
임베딩은 단어나 문장을 저차원의 밀집 벡터(dense vector)로 매핑합니다. 각 차원은 해당 단어나 문장의 의미와 관련된 정보를 포함합니다.
임베딩은 단어 사이의 유사성을 보존하고, 의미적으로 유사한 단어는 벡터 공간에서 가까이 위치하도록 합니다. 이러한 특성은 모델이 텍스트 데이터의 의미를 이해하는 데 도움이 됩니다.
Word2Vec, GloVe, FastText 등은 단어 임베딩을 학습시키는 대표적인 방법들 중 일부입니다.
요약하자면, 패딩은 시퀀스 데이터의 길이를 일치시키기 위해 0 또는 다른 특정한 값으로 채우는 기술이며, 임베딩은 단어나 문장을 고정된 차원의 의미적 벡터로 매핑하여 모델에 입력하기 위한 기술입니다.
def one_hot_encoding(data, dim=10000): # imdb 데이터의 num_words를 10000으로 설정해서 dim도 10000으로 맞춰줍니다.
results = np.zeros((len(data), dim))
for i, d in enumerate(data):
results[i, d] = 1.
return results
x_train = one_hot_encoding(train_data)
x_test = one_hot_encoding(test_data)
print(x_train[0])[0. 1. 1. ... 0. 0. 0.]
IMDB의 레이블은 1은 긍정, 0은 부정으로 정의되어 있는데, 정수형 값을 실수형 값으로 변환을 시켜줍니다.
print(train_labels[0])
print(test_labels[0])1
0
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
print(y_train[0])
print(y_test[0])1.0
0.0
3-2. 모델 구성
이제 실제 IMDB 데이터셋을 학습하고 긍정/부정을 분류할 딥러닝 모델을 정의합니다.
Sequential() 함수를 이용해서 순차적으로 레이어를 추가합니다.
첫번째 레이어는 Dense로 유닛수 16개를 가지고,
input_shape을 (10000, )으로 정의하여
10000 차원의 데이터를 입력으로 받을 수 있게 합니다.
그리고 활성화 함수인 activation은 relu로 사용하고,
레이어의 이름인 name을 input으로 지정합니다.
두번째 레이어도 마찬가지로 Dense로 유닛수 16개를 가지고,
relu 활성화 함수를 사용하고
이름은 hidden으로 지정합니다.
세번째 레이어도 Dense 레이어를 사용하지만,
긍정/부정 결과만 받도록 유닛수는 1개만 가지고,
활성화 함수는 sigmoid를 사용하고,
이름은 output으로 지정합니다.
import tensorflow as tf
from tensorflow.keras import models, layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000, ), name='input'))
model.add(layers.Dense(16, activation='relu', name='hidden'))
model.add(layers.Dense(1, activation='sigmoid', name='output'))3-3. 모델 컴파일 및 학습
이제 정의한 모델을 컴파일을 통해서 옵티마이저인 optimizer는 rmsprop를 사용하고,
손실 함수인 loss는 긍정/부정만 분류하므로 binary_crossentropy를 지정합니다.
그리고 지표인 metrics는 accuracy를 사용합니다.
이제 summary() 함수를 사용해 모델의 구조를 시각화합니다.
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()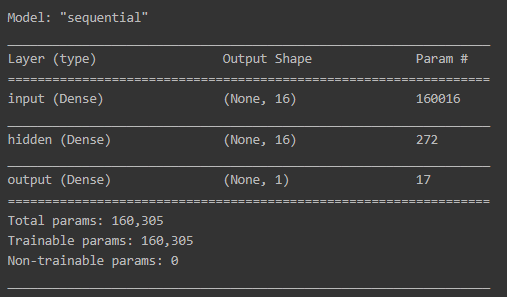
이제 딥러닝 모델을 학습하기 위해 fit() 함수를 실행시킵니다.
학습에 사용되는 데이터로 x_train과 y_train을 지정하고,
에폭 수인 epochs는 20으로 지정하고,
배치 사이즈인 batch_size는 512로 지정합니다.
그리고 검증을 위해서 테스트 데이터인 x_test와 y_test를 지정해줍니다.
history = model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))학습하며 저장된 모델의 지표 결과인 history에서
loss, val_loss, accuracy, val_accuracy를 차트로 시각화합니다.
import matplotlib.pyplot as plt
history_dict = history.history
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(loss) + 1)
fig = plt.figure(figsize=(12, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, loss, color='blue', label='train_loss')
ax1.plot(epochs, val_loss, color='red', label='val_loss')
ax1.set_title('Train and Validation Loss')
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Loss')
ax1.grid()
ax1.legend()
accuracy = history_dict['accuracy']
val_accuracy = history_dict['val_accuracy']
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, accuracy, color='blue', label='train_accuracy')
ax2.plot(epochs, val_accuracy, color='red', label='val_accuracy')
ax2.set_title('Train and Validation Accuracy')
ax2.set_xlabel('Epochs')
ax2.set_ylabel('Accuracy')
ax2.grid()
ax2.legend()
plt.show()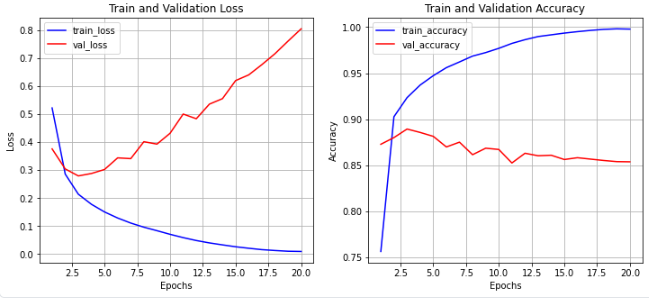
딥러닝 모델의 결과를 살펴보면 val_loss가 점점 증가하는 것을 알 수 있고,
val_accuracy는 점점 감소하는 것을 알 수 있습니다.
즉, 과대적합되어 학습용 데이터셋에 대해서만 모델이 적합하게 된 것을 알 수 있습니다.
