[딥러닝CV] 목차
- 컴퓨터 비전 태스트 '상상'해 보기
- 다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기
3. CNN 하나씩 이해하기 (1) 1-Channel Convolution - CNN 하나씩 이해하기 (2) 3-Channel Convolution
- CNN 하나씩 이해하기 (3) Pooling
- 심화된 CNN 구조
- Transfer Learning 이해하기
- Object Detection
- Segmentation
1. Channel이 하나일 때 1-Layer의 Convolution 연산
1-1.
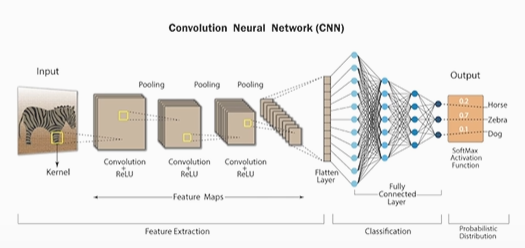
Q. CNN(Convolution Neural Network)의 구조를 설명해 보세요.
CNN 구조는 크게 Feature extraction과 Classification으로 구성됩니다. Input이 들어가면 먼저 Convolution 연산과 Pooling을 여러 번 반복하여 Feature extraction을 한 후 1D 데이터인 flatten layer로 만듭니다. 마지막으로 Fully connected layer(MLP)를 통해 classification을 합니다.
Q. Convolution 연산에 대해서 설명해 보세요.
스트라이드 크기에 따라 커널을 이동하여 오버라이딩(각각 곱해서 더하기) 을 한다.
즉,
Convolution 연산은 Input에 kernel을 over-riding하여 겹쳐지는 숫자를 곱하여 그 값을 더하는 것입니다. stride를 1로 지정하여 Convolution 연산을 반복하면 결과값인 feature map이 나옵니다.
Q. 7x7 Input, 3x3 kernel, stride 1일 때 convolution 연산을 하면 어떤 크기의 feature map이 나오나요?
5x5
Q. 7x7 image의 데이터에 5x5의 필터로 convolution 연산을 했을 때 feature map의 사이즈는 어떻게 되나요? (stride는 1)
3x3
Q. 7x7 image의 데이터에 5x5의 필터로 convolution 연산을 했을 때 feature map의 사이즈는 어떻게 되나요?? (stride는 2)
2x2
Q. 9x9 image의 데이터를 3x3의 필터로 convolution 연산을 두 번 했을 때, 연산의 결과로 나온 최종 feature map의 사이즈는 어떻게 되나요? (stride는 처음에는 2, 두번째에는 1)
2x2,
convolution 연산을 1번 했을 때 feature map의 사이즈는 4x4,
2번째 연산했을 때는 2x2이 나옵니다.
2. Filter 이해
Q. 딥러닝을 컴퓨터 비전 기술에 사용하기 전에 Hand-Crafted filter가 있었습니다. 과거에 사람들이 많은 노력을 들여서 filter를 찾으려고 했었던 이유는 무엇이었을까요? 또한, Hand-Crafted filter의 한계점에 대해서 설명해 보세요.
사람들은 과거 많은 노력을 들여 filter를 찾으려고 했던 이유는 filter를 많이 확보하는 것이 컴퓨터 비전의 성능을 높이는 핵심 경쟁력이기 때문입니다.
Hand-Crafted filter의 한계점은 사람이 직접 많은 노력을 들여 찾아내야 한다는 것이었습니다. 이를 대체해서 나온 것이 현재 우리가 배우고 있는 딥러닝(Deep Learning)이고, Convolution 연산입니다.
2-1. 코드로 Filter와 Convolution 연산 이해하기
이미지에 숨겨져 있는 패턴을 찾아내는 '패턴 추출기'를 만들 수 있을까요? 이미지 분석의 경우에는 'filter'라는 이름의 패턴 추출기를 사용합니다.
2-2. 데이터 확인하기
먼저 이번에 사용할 라이브러리와 고양이 사진을 불러옵시다.
원본 RGB 이미지에는 R, G, B 3개의 채널이 있기 때문에 간단한 실습을 위해 rgb2gray 함수로 이미지를 흑백으로 변환합니다.
# 필요한 모듈 불러오기
import numpy as np
from scipy.signal import convolve2d # 2D convolution 연산
from skimage.io import imread, imshow # 데이터를 이미지로 보여주기
from skimage.color import rgb2gray # RGB 채널값을 가진 이미지 데이터를, 흑백 이미지의 데이터로 변환하기
cat = rgb2gray(imread('data/cat.jpg')) # read image흑백 고양이 사진은 3,266개의 행과 4,899개의 열로 이루어진 1-channel 이미지입니다.
행렬 안에는 0과 1 사이의 값으로 정규화된 픽셀 값이 들어 있습니다.
cat.shape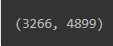
cat
imshow(cat)
filter 적용하기
이미지를 분석할 때, 이미지에 숨겨져 있는 패턴을 찾아내는 '패턴 추출기'를 만들 수 있을까요?
이미지 분석의 경우에는 filter라는 이름의 패턴 추출기를 사용합니다. filter를 고양이 사진에 적용해 봅시다.
먼저 고양이 사진에 적용할 대표적인 세 가지 filter를 정의합니다.
순서대로 Edge Detection, Sharpen, Gaussian Blur filter입니다.
filter는 그냥 봤을 때는 그저 숫자 덩어리이에요. 하지만 filter를 이용해서 convolution 연산을 하게 되면, 이미지 안에 숨겨져 있던 패턴이 드러나게 됩니다. 따라서 이미지 분석에서 중요한 것은 이미지 내에 숨겨진 다양하고 복잡한 패턴을 추출해줄 수 있는 다양한 filter를 만들어 내는 것입니다.
# Edge Detection
edge = np.array([[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1]])
# Sharpen
sharpen = np.array([[0, -1, 0],
[-1, 5, -1],
[0, -1, 0]])
# Gaussian Blur
blur = (1 / 16.0) * np.array([[1., 2., 1.],
[2., 4., 2.],
[1., 2., 1.]])Edge Detection
edge_im = convolve2d(cat, edge, 'valid')
imshow(edge_im)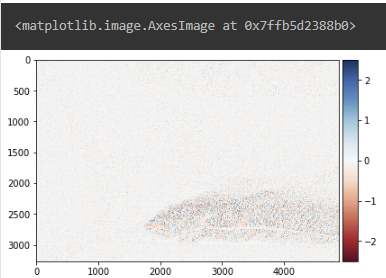
Sharpen
sharp_im = convolve2d(cat, sharpen, 'valid')
imshow(sharp_im)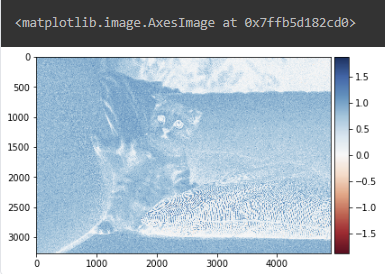
Gaussian Blur
blur_im = convolve2d(cat, blur, 'valid')
imshow(blur_im)
Edge Detection, Sharpen, Gaussian Blur filter의 역할은 무엇인가요?
Edge Detection: 윤곽선을 검출하는 역할을 합니다.
Sharpen: 이미지를 선명하게 만듭니다.
Gaussian Blur filter: 영상을 부드럽게 만듭니다. 영상의 노이즈를 제거할 때 사용하기도 합니다.
3. Channel이 하나일 때, 2개 이상 Layer의 Convolution 연산 (padding)
Q. Input이 7x7이고 kernel size가 3x3일 때. layer을 최대 몇 개까지 쌓을 수 있을까요? 그렇게 생각한 이유도 함께 설명해 보세요.
layer는 최대 3개까지만 쌓을 수 있습니다. 그 이유는 Convolution 연산을 계속해서 진행하게 되면, output의 크기가 줄어들기 때문입니다.
인풋(77) 커널필터(33) = 아웃풋(55)
인풋(55) 커널필터(33) = 아웃풋(33)
인풋(33) 커널필터(33) = 아웃풋(1*1)
Q. hidden layer의 개수가 늘어날수록 다양하고 복잡한 패턴을 찾을 수 있습니다. 어떻게 하면 더 많은 layer를 쌓을 수 있을까요? 어떤 방법을 사용하면 될까요?
더 많은 layer를 쌓을 수 있는 해결책은 padding을 사용하는 것입니다.
padding은 Filter을 적용하기 전에 보존하려는 Feature map 크기에 맞게 입력 Feature Map의 좌우 끝과 상하 끝에 각각 열과 행을 추가한 뒤, 0 값을 채워 입력 Feature map 사이즈를 증가시킵니다.
이런 식으로 padding을 적용하면 깊은 layer를 쌓을 수 있습니다.
Q. input이 5x5이고 kernel size가 3x3일 때 (stride 1), output size는 어떻게 되나요? 여기 조건에서 padding을 적용해 준다는 조건을 추가하면 output size는 어떻게 되나요? (추가 조건을 주기 전과 후의 output size를 비교해 봅시다. 🤗)
stride를 증가시키면 output size는 확 줄어들게 된다.
추가 조건 없이 기본적으로 Convolution 연산을 하면 output size는 3x3가 됩니다. 만약에 padding을 적용해 준다면, input이 7x7로 증가를 하게 되어 그 상태로 Convolution 연산을 하면 output size는 5x5가 됩니다.
두 개의 output size를 비교해 본다면 확실히 padding을 주기 전과 후가 차이가 나는 것을 알 수 있습니다.
Q. 딥러닝을 이용한 이미지 분석의 핵심을 한 문장으로 요약하여 적어보세요.
딥러닝을 이용한 이미지 분석의 핵심은 Convolution 연산을 통해서 이미지의 숨겨진 패턴을 찾는 자동 패턴 추출기인 filter를 학습시키는 것입니다.
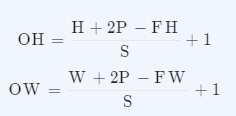
Q. 이전에 직접 계산해 보았던 feature map 크기 연산을 공식으로 작성해 볼까요?
패딩과 스트라이드를 적용하고, 입력데이터와 필터의 크기가 주어졌을 때 출력 데이터의 크기를 구하는 식은 아래와 같이 작성할 수 있습니다.
• (H, W) : 입력 크기(input size)
• (FH, FW) : 필터의 크기(filter size)
• (OH, OW) : 출력 크기(output size)
• P : 패딩(padding)
• S : 스트라이드(stride)
Q. 이미 배운 3개의 filter 외에 다른 filter는 무엇이 있을까요?
Emboss 필터: 입체적인 느낌을 줄 수 있는 필터로, 이미지에서 윤곽을 강조하거나 돋보이게 만들어줍니다.
Sobel 필터: 에지(경계) 검출을 위해 사용되며, 이미지의 밝기 변화가 큰 부분을 감지합니다.
Prewitt 필터: 이미지의 수직 및 수평 에지를 검출하는 데 사용됩니다.
Median 필터: 이미지에서 잡음을 줄이기 위해 사용되며, 각 픽셀 주변의 값들을 중앙값으로 대체하여 부드럽게 만들어줍니다.
Bilateral 필터: 에지를 보존하면서 잡음을 제거하는 데 사용되며, Gaussian 필터와 다르게 가우시안 커널의 위치 및 강도 차이를 보존합니다.
Laplacian 필터: 이미지의 높은 주파수 구성 요소를 검출하여 윤곽을 강조합니다.
이 외에도 다양한 필터가 존재하며, 각각의 필터는 이미지에서 원하는 효과를 얻기 위해 사용됩니다. 이미지 처리 작업에서는 이러한 필터들을 조합하거나 조절하여 원하는 결과를 얻을 수 있습니다.
