[딥러닝CV] 목차
- 컴퓨터 비전 태스트 '상상'해 보기
2. 다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기 - CNN 하나씩 이해하기 (1) 1-Channel Convolution
- CNN 하나씩 이해하기 (2) 3-Channel Convolution
- CNN 하나씩 이해하기 (3) Pooling
- 심화된 CNN 구조
- Transfer Learning 이해하기
- Object Detection
- Segmentation
1. 다층 퍼셉트론(MLP) 복습
Q. 딥러닝(Deep Learning) 구조의 핵심은 무엇인가요?
딥러닝 구조의 핵심은 여러 개의 hidden layer로 인해 학습기(learner)가 deep 하다는 것입니다.
Q. 뉴런의 작동 방식은 크게 세 부분으로 나눠서 볼 수 있습니다. 뉴런이 어떻게 동작하는지 세 부분으로 나눠서 설명해 보세요.
수용 → 조합 → 경계값/조건에 따라 전달
뉴런은 계속해서 신호를 받아서 조합(sum) 하고, 특정 threshold(경계값)를 넘어서면 “fire(발산, 전달)” 합니다.
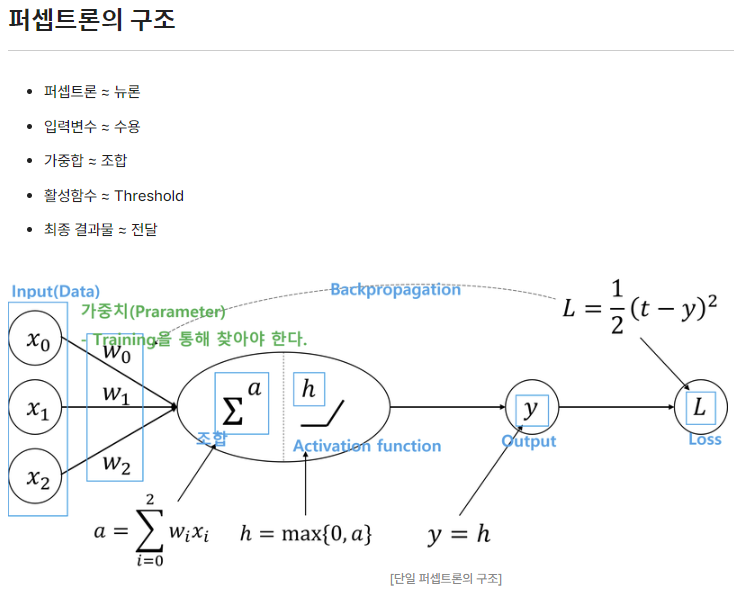
Q. 퍼셉트론은 단일 뉴런의 작동 원리를 모사한 것입니다. 뉴런과 퍼셉트론을 비교해서 설명해 보세요.
뉴런은 역치를 넘는 자극에 대해서만 다른 뉴런으로 정보를 전달하지만
퍼셉트론은 입력변수의 값들에 대한 가중합을 활성함수를 적용하여 최종 결과물을 생성하여 전달하게 된다.
Q. MLP 모델 구조를 보면 여러 개의 hidden layer로 이뤄져 있는 것을 알 수 있습니다. 이것들은 Representation learning을 수행한다고 말할 수 있습니다. 이때 Representation learning은 무엇을 의미하고, 또 다른 말로 어떻게 부를 수 있는지 설명해 보세요.
인풋 데이터를 히든 레이어를 통해 비틀어 더 다양하고 복잡하게 (구분하는) 패턴을 찾는 것
패턴추출기라고도 불린다.
Representation learning은 Representation을 통해서 원래 데이터가 존재하는 공간을 변경하는 것을 의미합니다. 정리해서 설명하자면, Representation learning은 Training 하는 과정에서 parameter를 계속해서 변형하여 task를 수행하는 데에 가장 적합한 공간구조를 Representation을 합니다.
Representation learning은 Pattern Extractor(패턴 추출기) Feature Extractor라고 부릅니다. 이는 MLP 모델이 가진 큰 장점이라고 말할 수 있으며, 어떻게 하면 Feature Extractor를 잘 만들 수 있을까가 딥러닝 모델을 만들 때 핵심이 됩니다.
2. MLP 모델로 이미지 분류
2-1. MNIST 데이터 살펴보기
먼저 필요한 라이브러리를 import하고
tf.keras.datasets.mnist.load_data() 함수를 이용해
MNIST 데이터셋을 불러옵니다.
import sys
import tensorflow as tf
import numpy as np# MNIST 데이터셋 불러오기
(X_train, Y_train), (X_test, Y_test) = tf.keras.datasets.mnist.load_data()
# shape 확인하기
print(X_train.shape) # 28 x 28의 이미지가 60,000장
print(Y_train.shape) ## [ 5, 1, 2, 3, 4, 4, .... ]
print("학습셋 이미지 수 : %d 개" % (X_train.shape[0]))
print("테스트셋 이미지 수 : %d 개" % (X_test.shape[0]))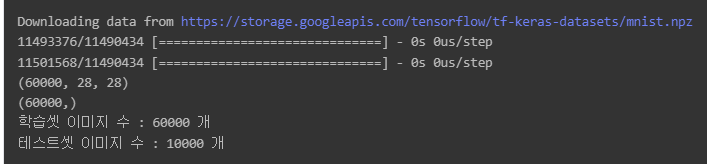
MNIST 데이터가 어떻게 생겼는지 확인해볼까요?
# MNIST 데이터를 시각화하기
import matplotlib.pyplot as plt
print(Y_train[0])
plt.imshow(X_train[0], cmap='Greys') # 흑백 이미지로 확인
plt.show()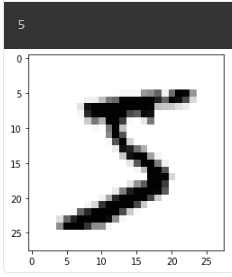
MNIST 데이터는 위와 같이 이미지처럼 나타낼 수 있지만 사실은 2차원 배열에 픽셀 값이 저장되어 있는 형태입니다. 즉 0과 255 사이의 정수로 구성된 데이터입니다.
# 데이터를 직접 들여다보기
for x in X_train[0]:
for i in x:
sys.stdout.write('%d\t' % i)
sys.stdout.write('\n')2-2. MLP 구조 만들기
MLP(Multi Layer Perceptron)의 입력 데이터는 기본적으로 벡터 형태입니다.
X_train은 28 x 28 크기의 MNIST 데이터 60,000개가 모여 있는 배열이기 때문에, 각각의 데이터를 (28, 28) 크기의 행렬(2차원)에서 길이가 28x28=784인 벡터(1차원)로 변형시켜야 합니다. X_test에 포함된 데이터도 reshape() 함수를 사용하여 크기를 바꿔줍시다.
# MLP 구조에 적절한 input의 형태로 변형하기
## reshape()을 사용하여 2차원의 데이터를 1차원으로 변형
## 1차원으로 변형함과 동시에 Normalization
X_train = X_train.reshape(X_train.shape[0], 784).astype('float32') # 28 x 28= 784
X_test = X_test.reshape(X_test.shape[0], 784).astype('float32')데이터셋 행렬의 크기를 다시 확인해봅시다.
print(X_train.shape)
print(X_test.shape)(60000, 28, 28)에서 (60000, 784)로 변형된 것을 확인할 수 있습니다.
label의 경우 현재 0~9의 정수 값을 가지고 있습니다.
이 값들을 분류 문제에 맞게 one-hot vector로 만들어줍시다.
Y_train, Y_test의 shape을 다시 보면
길이가 10인 벡터 60,000개(test는 10,000개)가
묶인 형태로 바뀐 것을 확인할 수 있습니다.
원-핫 인코딩은 "단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식이며, 이렇게 표현된 벡터를 원-핫 벡터(One-Hot vector)"라고 합니다.
# Label 값을 One-hot encoding 하기
# Multi-Class Classfication이므로 keras.utils.to_categorical을 사용
Y_train = tf.keras.utils.to_categorical(Y_train)
Y_test = tf.keras.utils.to_categorical(Y_test)print(Y_train.shape)
print(Y_test.shape)
print(Y_train[0])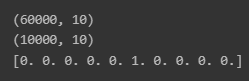
본격적으로 MLP 모델을 만들어봅시다.
모델을 만드는 여러 가지 방법이 있지만 여기서는 Functional API로 만들어 봅시다.
이번에 구현할 모델은 input layer와 두 개의 hidden layer, 그리고 output layer로 구성되어 있습니다.
특히 output layer는 특별한 task를 수행하는데,
이 경우에는 10개의 class를 분류 (multi-class classification)하는 것입니다.
만약 output layer의 perceptron이
회귀 문제에서와 같이 실수 출력 값을 가진다면
수행하고자 하는 분류 task에 적절하지 않습니다.
왜냐 하면 분류 문제에서 label 값은 one-hot vector로 인코딩되고,
이것은 특정 클래스에 속할 확률이 1이라고 해석될 수 있기 때문입니다.
그러므로 10개의 perceptron에서 나온 출력을 확률 값으로 만들기 위해
활성화 함수로 softmax를 사용해야 합니다.
# 모델 설계하기
input_layer = tf.keras.layers.Input(shape=(784,)) # input layer, input의 사이즈에 맞게 shape을 지정하는 것이 중요
x = tf.keras.layers.Dense(512, activation='relu')(input_layer) # hidden layer 1, 512개의 perceptron으로 구성된 fully connted layer, activation 함수는 relu
x = tf.keras.layers.Dense(512, activation='relu')(x) # hidden layer 2
# 분류해야 하는 class 0~9 (10개) -> 따라서 최종 layer의 perceptron은 10개
out_layer= tf.keras.layers.Dense(10, activation='softmax')(x)
model = tf.keras.Model(inputs=[input_layer], outputs=[out_layer])
model.summary()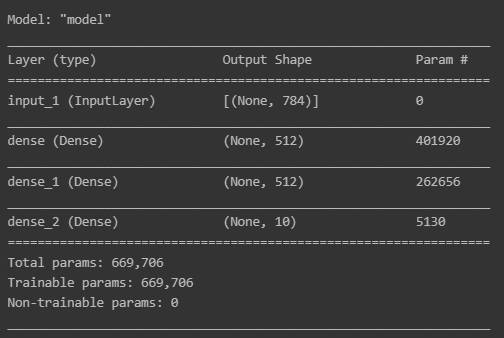
모델의 loss 함수, optimizer, metric을 설정하고 모델을 compile해줍시다.
loss=tf.keras.losses.categorical_crossentropy
optimizer = tf.keras.optimizers.Adam(learning_rate = 0.001)
metric=tf.keras.metrics.categorical_accuracy
model.compile(loss = loss,
optimizer = optimizer,
metrics = [metric])2-3. MLP 모델 Training 하기
model.fit() 함수를 이용하여 모델 학습을 시작합니다.
# validation_data 옵션으로 테스트 데이터만 넣어주어서 검증 데이터 분류가 가능
history = model.fit(X_train, Y_train, validation_split=0.2, epochs=30, batch_size=1000, verbose=1)
print(history.history.keys())training loss와 validation loss를 확인해봅시다.
# Training loss 확인하기
loss = history.history['loss']
print(loss)
2-4. 학습된 모델의 성능 확인하기
model.evaluate() 함수에 test 데이터를 입력시켜서 모델의 정확도를 확인하고,
학습이 진행되면서 training loss와 test loss가 어떻게 변하는지
그래프를 그려서 확인해봅시다.
# Test 데이터를 통해서 정확도 확인하기
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, Y_test)[1]))
# 그래프로 표현
x_len = np.arange(len(val_loss))
plt.plot(x_len, val_loss, marker='.', c="red", label='validation loss')
plt.plot(x_len, loss, marker='.', c="blue", label='training loss')
# 그래프에 그리드를 주고 레이블을 표시
plt.legend(loc='upper right')
# plt.axis([0, 20, 0, 0.35])
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()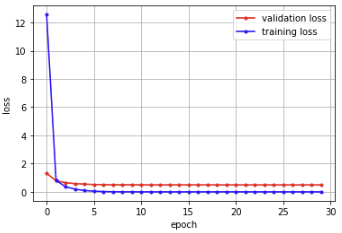
코드 풀면 이런 그래프 나옴
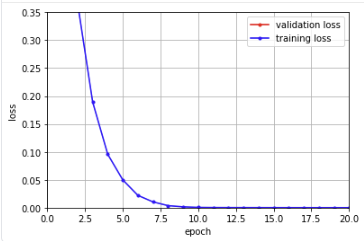
Training loss과 test loss가 모두 아주 낮은 것을 확인할 수 있습니다.
따라서 학습한 모델이 매우 좋은 예측 성능을 보일 것으로 예상할 수 있습니다.
3. MLP 모델의 한계
3-1. MLP 모델의 한계를 코드로 확인
원본 데이터를 살짝 변형했을 때 MLP 구조가 이미지를 잘 인식하는지 실펴 보겠습니다.
원본 데이터를 변형해서 MLP 구조의 성능 테스트하기
이번 스텝에서 사용할 OpenCV 라이브러리와 MNIST 데이터를 불러옵시다. 참고로 OpenCV 라이브러리는 이미지 데이터를 다루는 데에 매우 효과적인 도구들을 갖추고 있는 모듈입니다.
# OpenCV 모듈 불러오기
import cv2
# 다시 한번 MNIST 데이터를 불러오기
import sys
import tensorflow as tf
import numpy as np
(X_train, Y_train), (X_test, Y_test) = tf.keras.datasets.mnist.load_data()이전 스텝에서 확인했던 것처럼, 원본 MNIST 데이터는 다음과 같이 생겼습니다.
# MNIST 데이터가 어떻게 생겼는지 확인.
print(X_train.shape)
print(Y_train.shape)
print("학습셋 이미지 수 : %d 개" % (X_train.shape[0]))
print("테스트셋 이미지 수 : %d 개" % (X_test.shape[0]))이번에는 MNIST 데이터에 장난을 조금 쳐보겠습니다.
OpenCV의 함수들을 이용해서
MNIST 이미지에 회전 변환과 이동 변환(선형 변환)을 적용합니다.
선형 변환을 위해서 변환 매트릭스를 먼저 구하고,
이미지에 변환 매트릭스를 적용해 봅시다.
즉 원본 이미지에 선형 변환 매트릭스를 곱하여 원본 이미지를 변환하는 것입니다.
# 이미지 회전 변환 메트릭스 구하기
M= cv2.getRotationMatrix2D((20, 25), 20, 1) ## 회전 변환 Matrix 생성
# 이미지 이동 변환 메트릭스 구하기
M[0, 2] = M[0, 2] + 3
M[1, 2] = M[1, 2] + 3
# 이미지 변환 메트릭스 적용
test_image = cv2.warpAffine(X_train[5], M, (28, 28)) ## image에 matrix 곱변환된 이미지는 다음과 같습니다.
plt.imshow(test_image, cmap='Greys')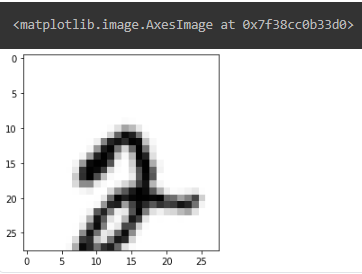
MLP 모델은 변환된 이미지도 분류를 잘 할 수 있을까요?
이전 스텝에서와 같이 이미지의 shape을 바꿔주고 모델에 넣어줍니다.
# MLP의 input 데이터를 넣어주기 위해 1x784 형태로 reshape하고 normalization
test_image_reshape = test_image.reshape(1, 784).astype('float64')
Y_prediction = model.predict(test_image_reshape)index = np.argmax(Y_prediction) # 10개의 class가 각 확률 값으로 나오기 때문에 가장 높은 값을 가진 인덱스를 추출
value = Y_prediction[:, index]
plt.imshow(test_image, cmap='Greys')
plt.xlabel("prediction: "+str(index)+" " +str(value), fontsize=20)
plt.show()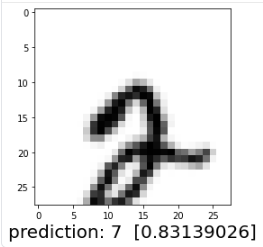
분명히 숫자 2를 나타낸 이미지였지만 간단한 변환을 적용했더니
모델은 데이터를 다른 숫자로 잘못 인식했습니다.
즉 MLP로 학습한 모델은 이미지 분류기로서는 robust classifier가 아니라는 것을 알 수 있습니다.
MLP를 이용해서 이미지를 분류하는 데에는 뭔가 문제가 있는 것 같습니다.
분명히 이전에 학습한 결과는 test loss가 매우 낮았으므로
분류 성능이 좋아야 하는데, 왜 이런 결과를 보이는 걸까요?
Q. MNIST dataset을 가지고 MLP 모델에 적용해 보았습니다. MLP 모델에 데이터 셋을 적용하려면 data 구조를 어떻게 변경해야 하는지 설명해 보세요.
MNIST dataset은 28 x 28 사이즈로 784 pixel의 2D 이미지입니다. 이를 MLP 모델에 적용하기 위해서는 2차원 데이터 1차원 구조로 변경시켜야 합니다.
2D(Dimension)를 1D(Dimension)로 변경하는 법은 각각의 열의 값을 1차원의 값(28개의 노드)으로 만들어 줍니다. 1열부터 28열까지 동일한 과정을 진행하면 784개의 값이 MLP에 들어가게 됩니다.
Q. 2차원의 이미지(고양이)를 1차원의 구조로 바꾸면 고양이라고 할 수 있을까요? 🐈❓
하나의 픽셀의 의미는 주변 픽셀과의 관계를 통해서 결정되기 때문에 2차원 이미지를 1차원의 구조로 바꾸면 숨겨져 있던 패턴의 정보가 사라집니다. 따라서 1차원의 구조로 바꾼 것만을 보고는 고양이라고 이야기를 하기는 어렵게 됩니다. 🐈🚫
Q. 하나의 픽셀은 하나의 픽셀만을 가지고 정보와 의미를 파악할 수 있을까요?
앞에 배운 것처럼 하나의 픽셀만을 가지고 정보와 의미를 파악할 수 없습니다. 픽셀의 정보와 의미를 파악하기 위해서는 주변(상하좌우) 픽셀과의 관계에 의해서 결정됩니다.
Q. MLP 모델 구조의 핵심을 한 줄로 요약해 봅시다.
MLP 모델 구조의 핵심은 데이터 안에 숨겨진 패턴을 Representation을 통해서 찾는 것입니다.
Q. MLP 모델로 이미지 분류를 하기 위해서는 2차원의 이미지를 1차원으로 변형해야 했습니다. 이때, 발생하는 문제점은 어떤 것인지 설명해 봅시다.
이미지 차원을 변형하면, 이미지 데이터가 가진 정보를 잃게 됩니다.
