[딥러닝CV] 목차
- 컴퓨터 비전 태스트 '상상'해 보기
- 다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기
- CNN 하나씩 이해하기 (1) 1-Channel Convolution
- CNN 하나씩 이해하기 (2) 3-Channel Convolution
- CNN 하나씩 이해하기 (3) Pooling
- 심화된 CNN 구조
7. Transfer Learning 이해하기 - Object Detection
- Segmentation
1. 대규모 모델 학습의 어려움
Q. ImageNet Competition의 결과를 보며 알게 된 특징과 오분류율에 비해 파라미터 수가 어떻게 되었는지 설명해 보세요.
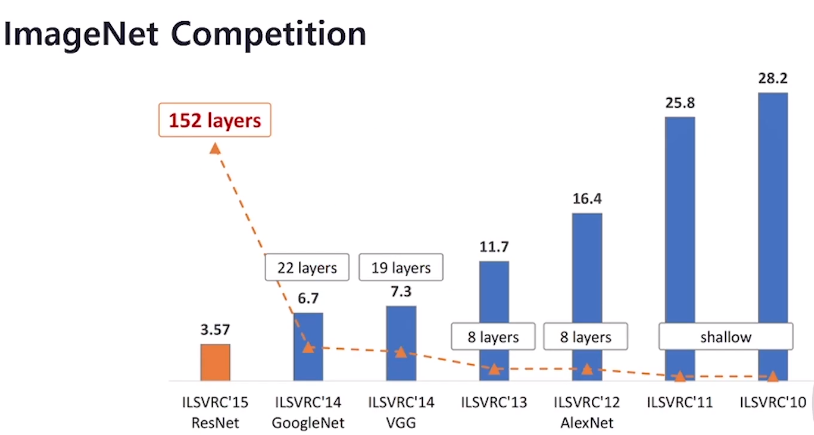
오분류율이 감소함과 동시에,
연산해야 하는 파라미터의 수가 급격하게 증가했습니다.
Q. 우리가 딥러닝 모델을 학습 할 때 데이터를 얼마나 모아야 하는지 어떤 데이터를 모아야 성능을 높일 수 있을지 생각하고 설명해 보세요.
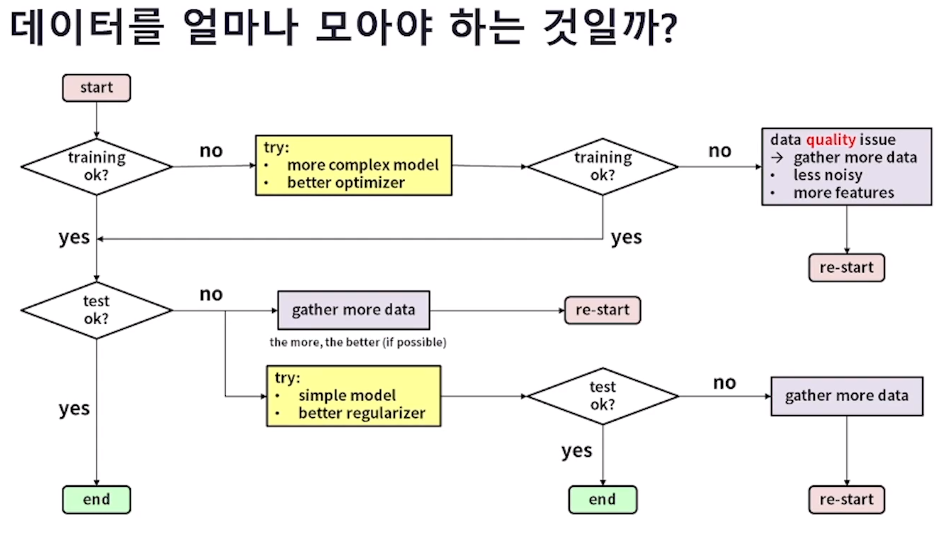
양질의 데이터를 많이 모으는 것이 딥러닝 모델의 성능을 높이는 데 핵심적인 요소입니다.
그러나 질적인 부분을 보완하는 것도 쉽지 않고,
양적인 부분을 보완하는 것도 쉽지 않은 일입니다.
Q. 만약에 데이터도 없고, 연산 비용을 낼 만한 자금도 없고, 시간도 부족할 때, 어떻게 하면 딥러닝 모델을 잘 학습할 수 있을지 설명해 보세요.
위와 같은 경우는 Transfer Learning을 사용하면 됩니다.
그럼 Transfer Learning에 대해서 더 알아보러 가볼까요? 💨
2. Transfer Learning의 아이디어
Q. 딥러닝 모델을 학습할 때, 처음부터 학습하는 것 (training from scratch)과 학습된 모델 이용하는 것 (transfer learning)은 각 어떤 방법이고 어떤 특징이 있는지 설명해 보세요.
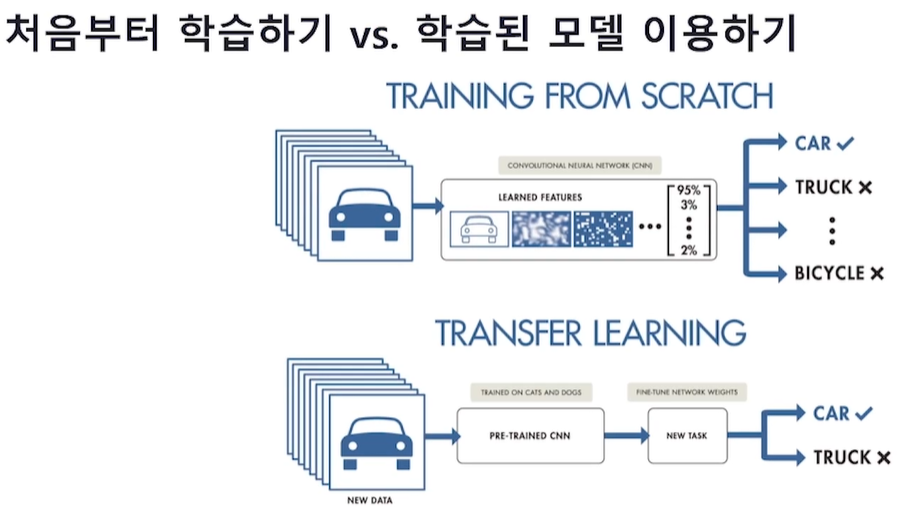
<처음부터 학습하기 (training from scratch)>
• 파라미터 초기화, 학습 등 모든 과정의 코드를 작성하고 실행시킵니다.
• loss 값을 보면서 성능이 좋아질 때까지 모델 학습을 진행합니다.
<학습된 모델 이용하기 (transfer learning)>
• 이미 학습된 모델(pre-trained model)의 파라미터 값들을 가져다 쓰는 것(Knowledge Transfer)입니다.
• 파라미터 전체를 그대로 사용할 수도 있고, 일부 파라미터만 학습시킬 수도 있습니다.
Q. 위의 퀴즈를 통해 Transfer Learning에 대해서 알았습니다. 그럼 Transfer Learning을 사용했을 때 효과는 어떤 것이 있는지 설명해 보세요.
기존에 만들어진(학습된) 모델을 사용하여 새로운 모델을 만들 때,
학습을 빠르게 하며 예측 능력을 더 높일 수 있습니다.
또한, 복잡한 모델일수록 학습시키기 어렵다는 난점을 해결할 수 있으며
학습에 들어가는 연산 비용을 절감할 수 있습니다.
3. Transfer Learning 적용
Q. Layer 별로 Feature Learning의 차이가 발생합니다. input과 가까운 레이어와 input과 멀어지는 레이어는 각각 어떤 부분이 학습되는지 설명해 보세요.
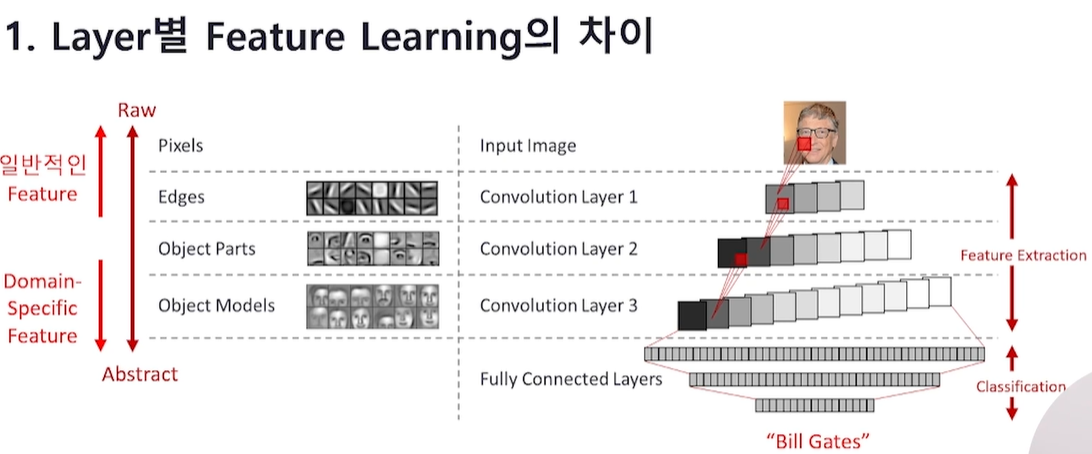
input과 가까운 레이어에서는 Edges가 학습
input과 멀어지는 레이어에서는 Object Models 가 학습
즉,
input과 가까운 레이어에서는
이미지의 단순하고 일반적인 패턴을 인식하는 filter들이 학습됩니다.
레이어가 input과 멀어질수록
복잡하고 task(domain)-specific 한 특성들이 학습됩니다.
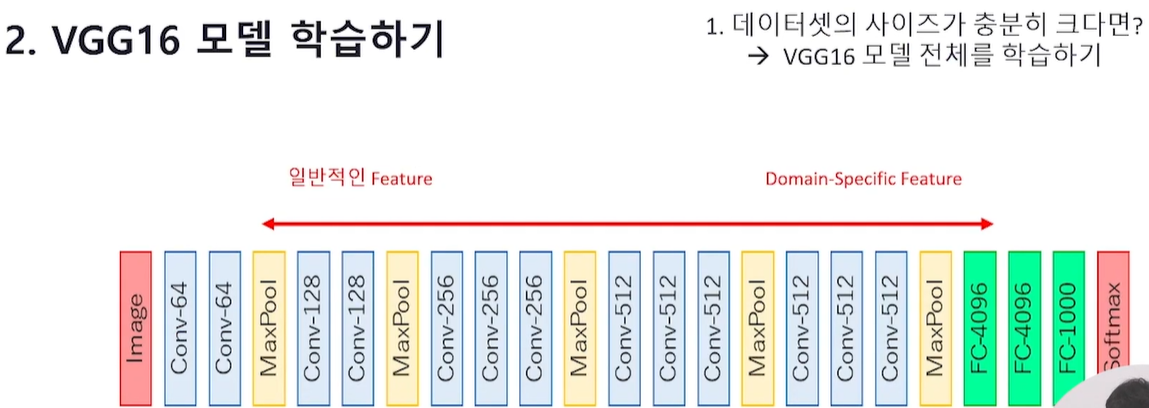
Q. VGG16 모델을 학습할 때 데이터셋의 사이즈에 따라서 어떻게 모델을 학습하면 좋을지 설명해 보세요. (데이터셋의 사이즈가 충분히 클 때, 데이터셋의 사이즈가 작을 때, 데이터셋의 사이즈가 중간 정도일 때)
VGG16 : 16은 연산(parameter learning) 이 필요한 Layer의 수
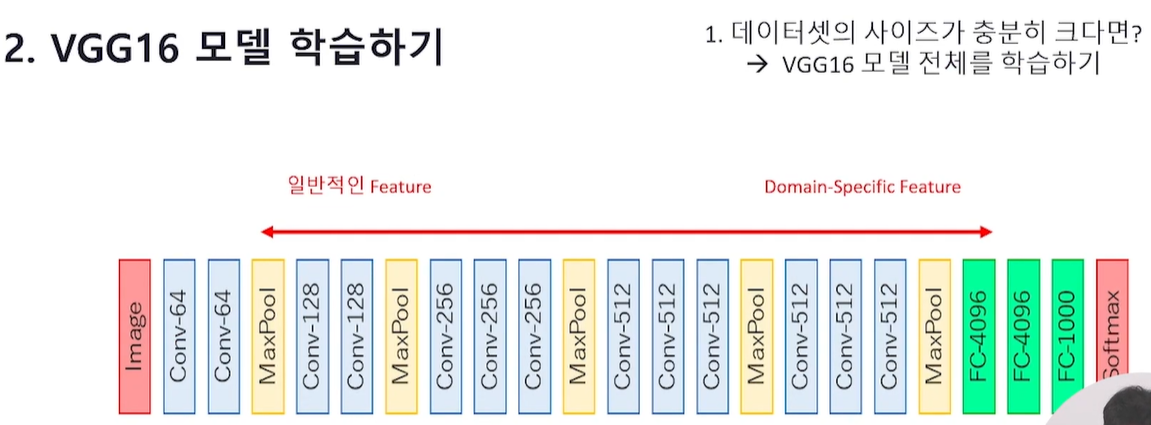
데이터셋의 사이즈가 충분히 크다면
VGG16 모델 전체를 학습하기
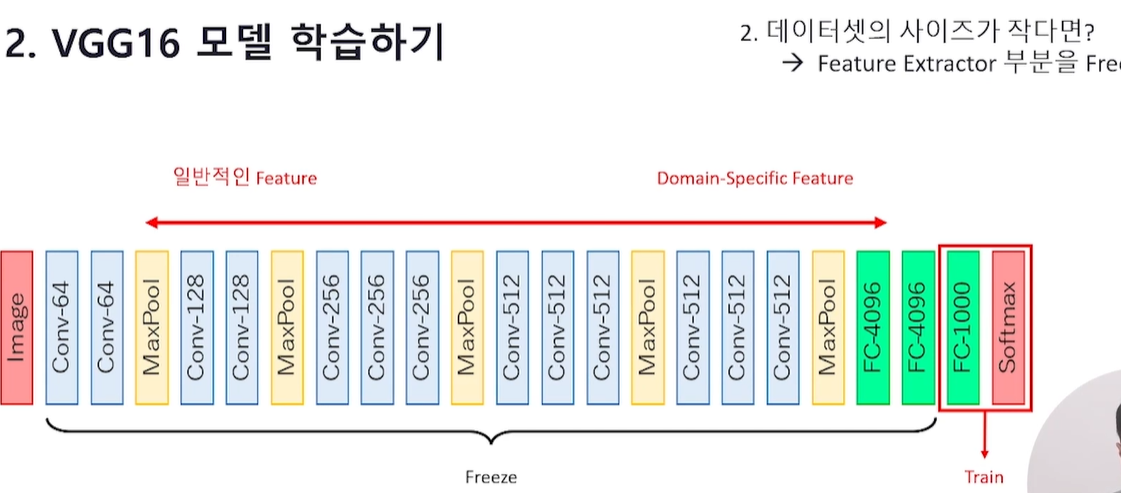
데이터셋의 사이즈가 작다면
Feature Extractor 부분을 Freeze하여 끝 부분만 학습하기
(내가 가진 task 또는 데이터와 관계되는 일부 layer 부분만 학습)
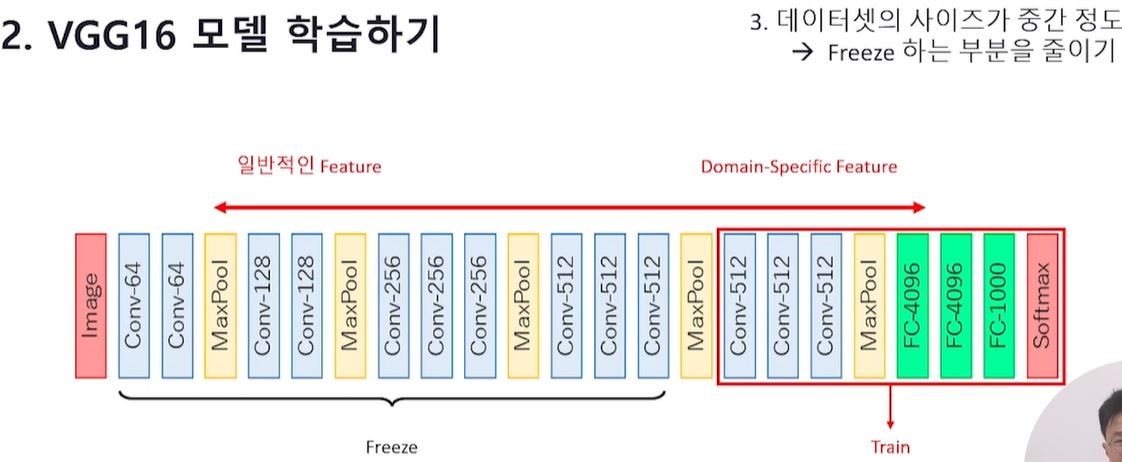
데이터셋의 사이즈가 중간 정도라면
Freeze하는 부분을 줄여서 끝 부분(더 많아짐)을 학습하기
Q. 데이터셋의 유사성과 데이터셋의 사이즈에 따라서 학습방법이 각각 어떻게 달라지는지 설명해 보세요.
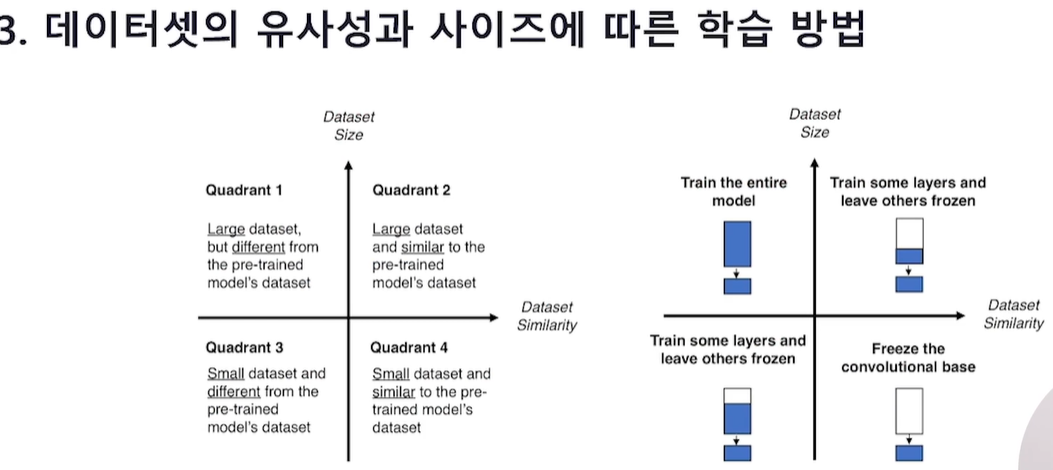
pre-training 하는 데에 썼던 Data (ex. 동물) 와
내가 가진 Data (ex. 초식동물)
사이의 유사성과 사이즈에 따라 학습방법은 달라진다.
가지고 있는 데이터셋의 크기가 작을수록,
pre-training을 진행한 데이터셋과 domain의 유사성이 높을수록
필요한 학습량이 줄어드니 많은 레이어를 freeze 하는 것이 효과적이고
유사성이 낮으면 학습량을 더 필요로 한다.
ResNet50 transfer learning 코드로 살펴보기
준비된 CIFAR-10 small 데이터셋을 실습 폴더에 연결합니다.
!mkdir -p aiffel/cifar_10_small
!ln -s ~/data/cifar_10_small/train/ aiffel/cifar_10_small/train
!ln -s ~/data/cifar_10_small/test/ aiffel/cifar_10_small/test실습에 필요한 라이브러리를 불러옵니다.
각각의 클래스에 해당하는 이미지의 개수를 알아보기 위해, 실습 데이터의 클래스마다 파일 경로를 변수로 정의합니다.
import os
import tensorflow as tf
import matplotlib.pyplot as plttrain_dir='aiffel/cifar_10_small/train'
test_dir='aiffel/cifar_10_small/test'
train_aeroplane_dir= os.path.join(train_dir,'aeroplane')
train_bird_dir=os.path.join(train_dir,'bird')
train_car_dir= os.path.join(train_dir,'car')
train_cat_dir=os.path.join(train_dir,'cat')
test_aeroplane_dir= os.path.join(test_dir,'aeroplane')
test_bird_dir=os.path.join(test_dir,'bird')
test_car_dir= os.path.join(test_dir,'car')
test_cat_dir=os.path.join(test_dir,'cat')각각의 디렉토리에 포함된 파일의 개수를 출력하여 훈련/테스트 데이터셋의 이미지 개수를 알아냅니다.
# 훈련용 데이터셋의 이미지 개수 출력
print('훈련용 aeroplane 이미지 전체 개수:', len(os.listdir(train_aeroplane_dir)))
print('훈련용 bird 이미지 전체 개수:', len(os.listdir(train_bird_dir)))
print('훈련용 car 이미지 전체 개수:', len(os.listdir(train_car_dir)))
print('훈련용 cat 이미지 전체 개수:', len(os.listdir(train_cat_dir)))
# Q. 테스트용 데이터셋의 이미지 개수를 각 디렉토리별로 출력해 보세요.
print('테스트용 aeroplane 이미지 전체 개수:', len(os.listdir(test_aeroplane_dir)))
print('테스트용 bird 이미지 전체 개수:', len(os.listdir(test_bird_dir)))
print('테스트용 car 이미지 전체 개수:', len(os.listdir(test_car_dir)))
print('테스트용 cat 이미지 전체 개수:', len(os.listdir(test_cat_dir)))
데이터 파이프 라인 생성하기
데이터 파이프 라인은 본 과정의 핵심이 아니기 때문에 이런 예제가 있다는 정도만 받아들이시면 됩니다. 😊
데이터를 디렉토리로부터 불러올 때 한번에 가져올 데이터의 수인 batch size를 설정하고, data generator를 생성하여 데이터를 모델에 넣을 수 있도록 합니다.
우선 ImageDataGenerator 객체를 생성하여 데이터 파이프 라인을 만듭니다. train dataset의 generator에는 augmentation이 포함되고, test dataset의 generator는 원본 상태를 유지하고 rescaling만 적용합니다.
### data 파이프 라인 생성
# 데이터를 디렉토리로부터 불러올 때, 한번에 가져올 데이터의 수
batch_size=20
# Training 데이터의 augmentation 파이프 라인 만들기
augmentation_train_datagen = tf.keras.preprocessing.image.ImageDataGenerator( rescale=1./255, # 모든 데이터의 값을 1/255로 스케일 조정
rotation_range=40, # 0~40도 사이로 이미지 회전
width_shift_range=0.2, # 전체 가로 길이를 기준으로 0.2 비율까지 가로로 이동
height_shift_range=0.2, # 전체 세로 길이를 기준으로 0.2 비율까지 가로로 이동
shear_range=0.2, # 0.2 라디안 정도까지 이미지를 기울이기
zoom_range=0.2, # 확대와 축소의 범위 [1-0.2 ~ 1+0.2 ]
horizontal_flip=True,) # 수평 기준 플립을 할 지, 하지 않을 지를 결정
# Test 데이터의 augmentation 파이프 라인 만들기
test_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)Augmentation 파이프라인을 기준으로 디렉토리로부터 데이터를 불러오는 모듈을 만듭니다. train/test dataset의 경로와 이미지 크기 등을 지정하여 train_generator와 test_generator 생성하면 됩니다.
# Augmentation 파이프라인을 기준으로 디렉토리로부터 데이터를 불러 오는 모듈 만들기
train_generator = augmentation_train_datagen.flow_from_directory(
directory=train_dir, # 어느 디렉터리에서 이미지 데이터를 가져올 것인가?
target_size=(150, 150), # 모든 이미지를 150 × 150 크기로 바꿉니다
batch_size=batch_size, # 디렉토리에서 batch size만큼의 이미지를 가져옵니다.
interpolation='bilinear', # resize를 할 때, interpolatrion 기법을 결정합니다.
color_mode ='rgb',
shuffle='True', # 이미지를 셔플링할 지 하지 않을 지를 결정.
class_mode='categorical') # multiclass의 경우이므로 class mode는 categorical
print(train_generator.class_indices)
# Q. Test 데이터 디렉토리로부터 이미지를 불러오는 파이프라인을 완성해 보세요.
# (위의 train_generator와 조건은 동일)
test_generator = test_datagen.flow_from_directory(
directory=train_dir, # 어느 디렉터리에서 이미지 데이터를 가져올 것인가?
target_size=(150, 150), # 모든 이미지를 150 × 150 크기로 바꿉니다
batch_size=batch_size, # 디렉토리에서 batch size만큼의 이미지를 가져옵니다.
interpolation='bilinear', # resize를 할 때, interpolatrion 기법을 결정합니다.
color_mode ='rgb',
shuffle='True', # 이미지를 셔플링할 지 하지 않을 지를 결정.
class_mode='categorical') # multiclass의 경우이므로 class mode는 categorical

Train data의 파이프 라인이 batch size만큼의 데이터를 잘 불러오는 지 확인해 봅시다.
for data_batch, labels_batch in train_generator:
print('배치 데이터 크기:', data_batch.shape)
print('배치 레이블 크기:', labels_batch.shape)
break
바탕이 되는 Pretrained Model(ResNet50)을 불러오고 모델의 구조를 살펴봅시다.
## back bone
conv_base=tf.keras.applications.ResNet50(weights='imagenet',include_top=False)
conv_base.summary()최종 모델을 구성합니다.
input layer와 ResNet50 backbone, fully-connected layer를 연결하여 transfer learning 모델을 만듭니다.
# 최종 모델 구성하기
input_layer = tf.keras.layers.Input(shape=(150,150,3))
x = conv_base(input_layer) # 위에서 불러온 pretrained model을 활용하기
# 불러온 conv_base 모델의 최종 결과물은 Conv2D 연산의 feature map과 동일
# 따라서 최종적인 Multiclass classfication을 하기 위해서는 Flatten을 해야 한다.
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(512, activation='relu')(x)
out_layer = tf.keras.layers.Dense(4, activation='softmax')(x)conv_base는 freeze 시킴으로써 이미 학습된 파라미터 값을 그대로 사용합니다.
conv_base.trainable = False만들어진 모델의 구조를 살펴봅시다.
model = tf.keras.Model(inputs=[input_layer], outputs=[out_layer])
model.summary()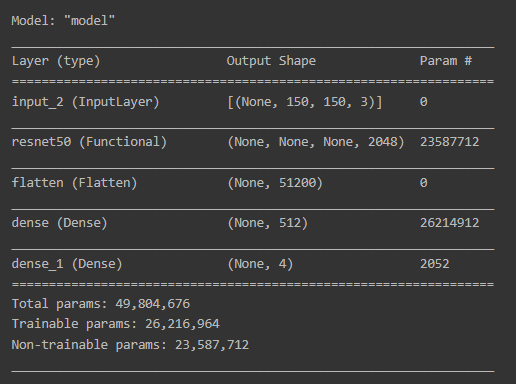
# [Playground] conv_base.trainable의 값을 True와 False로 바꿔가면서
# Trainable params의 값이 어떻게 바뀌나 확인하고 분석해 보세요.
# [[YOUR CODE]]loss function과 optimizer, metric을 설정하고 모델을 컴파일합니다.
loss_function=tf.keras.losses.categorical_crossentropy
optimize=tf.keras.optimizers.Adam(learning_rate=0.0001)
metric=tf.keras.metrics.categorical_accuracy
model.compile(loss=loss_function,
optimizer=optimize,
metrics=[metric])data generator는 입력 데이터와 타겟(라벨)의 batch를 끝없이 반환합니다.
batch가 끝없이 생성되기 때문에, 한 번의 epoch에 generator로부터 얼마나 많은 샘플을 뽑을지 모델에 전달해야 합니다.
만약 batch_size=20이고 steps_per_epoch=100일 경우 (데이터, 라벨)의 쌍 20개가 생성되고, 크기가 20인 batch 데이터를 100번 학습하면 1 epoch이 완료됩니다. 단, 크기 20의 batch 데이터는 매번 랜덤으로 생성됩니다.
일반적으로 (전체 데이터 길이/batch_size)를 steps_per_epoch으로 설정합니다.
history = model.fit(
train_generator,
steps_per_epoch=(len(os.listdir(train_aeroplane_dir)) + len(os.listdir(train_bird_dir)) + len(
os.listdir(train_car_dir)) + len(os.listdir(train_cat_dir))) // batch_size,
epochs=20,
validation_data=test_generator,
validation_freq=1)모델에서 학습한 결과를 hdf5 파일 형식으로 저장하고, 평가 metric들도 따로 저장합니다.
model.save('/aiffel/aiffel/cifar_10_small/multi_classification_augumentation_model.hdf5')
acc = history.history['categorical_accuracy']
val_acc = history.history['val_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
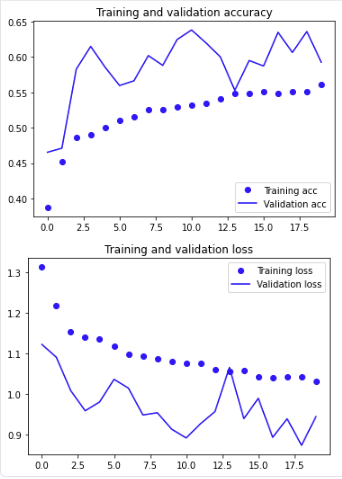
training set과 validation set의 accuracy, loss를 그래프로 확인해봅시다.
# # 학습한 결과 시각화
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()