[딥러닝CV] 목차
- 컴퓨터 비전 태스트 '상상'해 보기
- 다층 퍼셉트론(Multi-Layer Perceptron) 구조 복습하기
- CNN 하나씩 이해하기 (1) 1-Channel Convolution
- CNN 하나씩 이해하기 (2) 3-Channel Convolution
- CNN 하나씩 이해하기 (3) Pooling
6. 심화된 CNN 구조 - Transfer Learning 이해하기
- Object Detection
- Segmentation
1. Inception Module(Naïve Version) - “GoogLeNet”
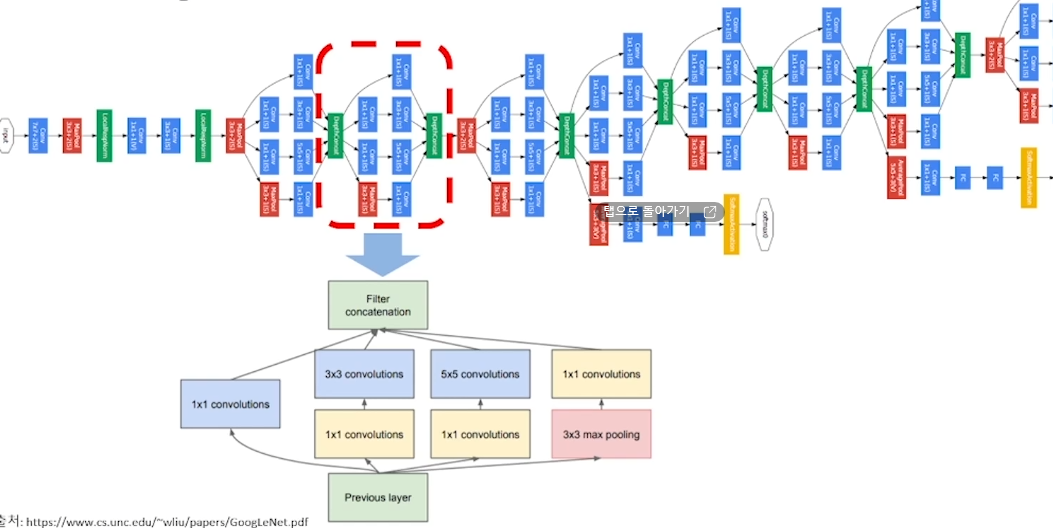
이러한 과정에서 빨간박스 부분이 Inception Module
Q. GoogLeNet에서는 vanishing gradient의 문제를 해결하기 위해 어떤 방법을 사용했는지 설명해 보세요.
우리가 좋은 성능을 얻기 위해서는 딥러닝 구조를 깊게 만들어야 합니다. 하지만 딥러닝 구조를 깊게 하면 vanishing gradient의 문제(input에 가까이 갈수록 loss 전달이 안 됨)가 발생합니다.
GoogLeNet은 vanishing gradient의 문제를 해결하기 위해 Inception Module을 사용했습니다.
Q. GoogLeNet은 독특한 모델 구조를 가지고 있습니다. 이러한 GoogLeNet의 아이디어는 어떤 것이었는지 설명해 보세요.
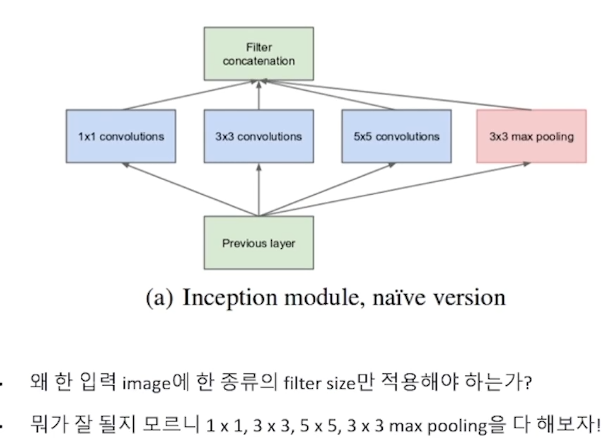
• 왜 한 입력 image에 한 종류의 filter size만 적용해야 하는가?
• 뭐가 잘 될지 모르니 1 x 1, 3 x 3, 5 x 5, 3 x 3 max pooling을 다 해보자!
• 큰 사이즈의 Receptive Field(over-riding 되는 영역) 가 제공하는 장점(큰 특징 추출, 연산이 빠름)은 수용하면서 파라미터의 수를 줄일 수 있는 구조를 만들자.
(Receptive Field가 큰 것 = kernel 사이즈가 큰 것)
적절한 커널의 필터 사이즈와 Pooling(down sampling)을 고민해서 찾아내기보다는 여러 사이즈의 필터들을 한꺼번에 결합하는 방식을 제공하였고, 논문(Going deeper with convolutions)에서는 이를 Inception module로 지칭하였습니다.
Q. GoogLeNet은 Inception module끼리 어떻게 연결되게 만들어 주는 지 설명해 보세요. 또한, 여러 개의 Inception module을 연결했을 때의 장점에 대해서 설명해 보세요.
꼭 하나의 커널이 아닌 여러 사이즈의 커널을 사용하는 동시에
pooling의 down-sizing 기능까지 같이 쓸 수 있다.
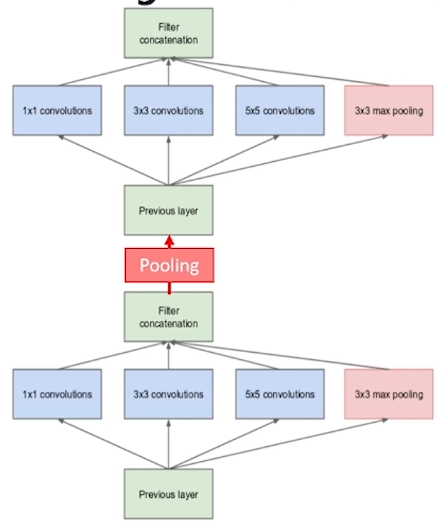
GoogLeNet은 Inception module들을
Pooling을 통해 연속적으로 이어서 (쌓는 방식으로) 구성되었습니다.
여러 사이즈의 필터들이 서로 다른 공간 기반으로 Feature들을 추출하고,
이를 결합하면서 보다 풍부한 Feature Extractor layer의 구성이 가능합니다.
1-1. Naïve Inception module from scratch
인셉션 모듈을 만드는 데 필요한 라이브러리를 불러옵니다.
# 인셉션 모듈을 만드는 데에 필요한 모듈 불러오기
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.utils import plot_model # 모델 시각화# Naïve Inception 블록을 만들기 위한 함수
def naive_inception(input_layer, conv1_filter, conv3_filter, conv5_filter):
# 1x1 사이즈의 kernel을 이용한 convolution2d layer
conv1 = keras.layers.Conv2D(conv1_filter, (1,1), padding='same', activation='relu')(input_layer)
# Q. 3x3 사이즈의 kernel을 이용한 convolution2d layer를 만들어 보세요.
conv3 = keras.layers.Conv2D(conv3_filter, (3,3), padding='same', activation='relu')(input_layer)
# Q. 5x5 사이즈의 kernel을 이용한 convolution2d layer를 만들어 보세요.
conv5 = keras.layers.Conv2D(conv5_filter, (5,5), padding='same', activation='relu')(input_layer)
# 3x3 max pooling layer (데이터의 가로 세로를 3x3로 살펴보고 가장 큰 값만 뽑아낸다)
pool = keras.layers.MaxPooling2D((3,3), strides=(1,1), padding='same')(input_layer)
# 위에서 언급한 4개의 layer 통해서 나온 feature map들을 모두 concatenation 한다.
out_layer = keras.layers.Concatenate()([conv1, conv3, conv5, pool])
return out_layerinput layer를 정의해주고, naïve Inception 블록도 하나 생성합니다.
input_data = keras.layers.Input(shape=(256, 256, 3))
naive_inception_out = naive_inception(input_data, 64, 128, 32)
print(naive_inception_out)
input layer와 naïve Inception 블록을 연결해서 모델을 만듭니다.
# 모델 만들기
model = keras.models.Model(inputs=input_data, outputs=naive_inception_out)
# 생성한 모델의 구조 확인하기
model.summary()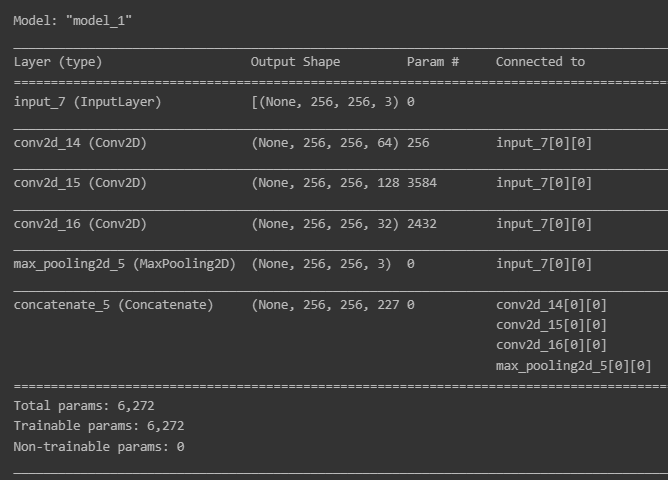
tensorflow.keras.utils 라이브러리의 plot_model 함수로 모델의 구조를 시각화할 수 있습니다.
# 모델 구조 시각화하기
plot_model(model, show_shapes=True, to_file='naive_inception_module.png')
2. Inception Module(1 x 1 convolution) - “GoogLeNet”
<<복습>>
1D : Vector
2D : Metrix
3D~: Tensor
Input의 channel 수 = Filter의 channel 수
Filter 자체의 개수 = Output의 channel 수 = Feature Map 수
2-1. (1 x 1 convolution) Filter (주황) 사용의 장점
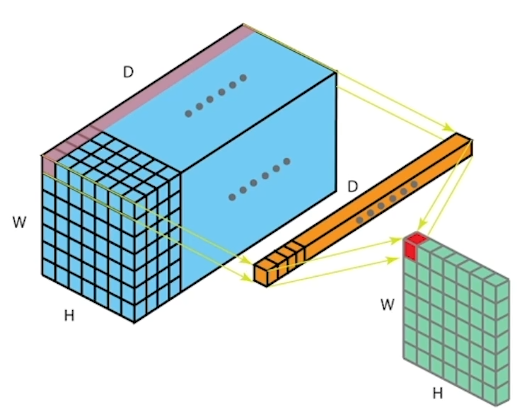
주황색(1 x 1 x 10) Filter : Input Tensor(이미지) 의 channel 수가 10개이니 Filter의 Channel 수도 10개
그 주황색이 (왼쪽) 보라색 위치에 들어가서 연산을 시작한다.
해당하는 값들을 곱하고 모두 더한 값은 (오른쪽) 자주색 한 칸에 들어가게 된다.
이렇게 쭉 conv2D 연산을 하게 되면
(7 x 7 x 10) -> (1 x 1 x 10) -> (7 x 7 x 1 )
가로 세로 채널 커널 가로 세로 채널
10개였던 채널이 output에서 1개의 채널로 줄었다.
즉, Feature map의 depth(채널수)를 감소시켜 연산량을 감소시켰다.
연산량을 감소시켰다는 것의 의미는?
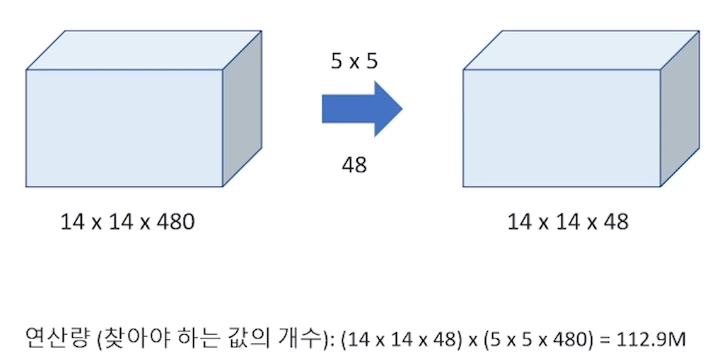

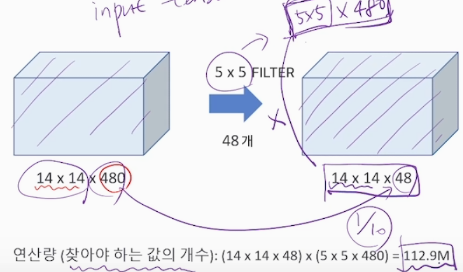
이 때, 14X14 가 그대로 유지되는 이유 : 5X5 Filter 할 때 padding으로 적절히 조절
Q. Depth가 깊은 Input tensor에 동일한 channel 수를 가진 1 x 1 filter를 conv2D 연산을 하면 feature map의 channel이 어떻게 되는지 설명해 보세요. 1 x 1 Filter을 사용했을 때의 장점에 대해서 설명해 보세요.



Depth가 깊은 Input tensor에 동일한 channel 수를 가진 1 x 1 filter를
conv2D 연산을 하면 feature map의 channel 은 1개가 된다.
즉 10개의 channel을 1개의 channel로 압축시키는 것이다.
1 x 1 filter를 사용하면 channel 수를 줄이기 때문에 연산량도 감소하고,
활성화 함수를 2번 사용하여 비선형성을 강화시킨다는 장점이 있다.
Q. GoogLeNet에서는 Inception Module 이후, Global Average Pooling을 사용했습니다. Global Average Pooling이 무엇인지 설명해 보세요.

(일반적인 풀링 기법은 최댓값(Max Pooling)을 사용하여 특징 맵의 각 영역에서 가장 큰 값을 추출하여 정보를 압축하는데 반해,)
Global Average Pooling은 전체 feature map의 평균(Average)값을 뽑아 pooling을 한 것을 의미합니다. 또한, Global Average Pooling은 parameter가 추가로 필요하지 않습니다.
전형적으로 CNN의 마지막 부분에서 사용되며,
최종 특징 맵에서 Global Average Pooling을 적용한 후에는
일반적으로 완전 연결 레이어(Dense Layer) 등의 분류기에 주입됩니다.
이를 통해 CNN은 입력 이미지에 대한 특징을 추출하고 이를 기반으로 이미지의 클래스를 분류할 수 있게 됩니다.
Global Average Pooling은 압축된 특징 표현, 파라미터 수 감소 그리고 과적합을 방지하는 특징이 있다.
Q. 엄청나게 깊은 네트워크에서 vanishing gradient 문제가 발생합니다.
이 문제를 해결하기 위해 GoogLeNet을 만든 사람들은 Auxiliary classifier를 모델에 덧붙였습니다.
Auxiliary classifier을 통해서 가질 수 있는 효과에 대해서 설명해 보세요.
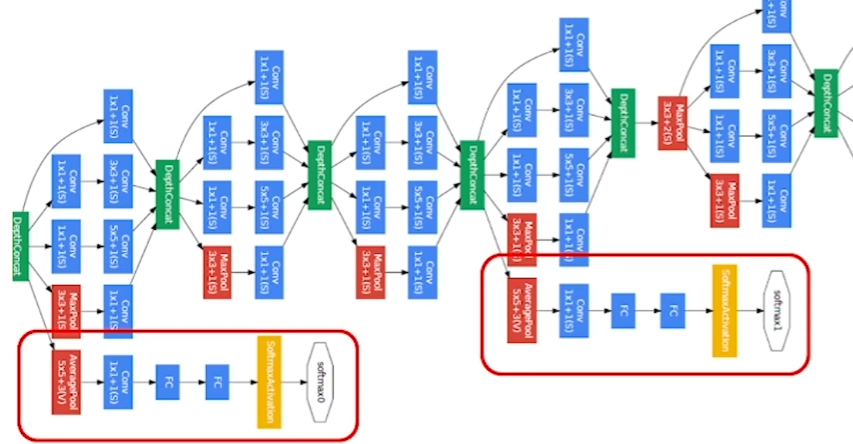
Auxiliary classifier(가짜 분류기) 를 모델에 2개를 붙여 결과적으로 loss를 맨 끝뿐만 아니라 중간에서도 구하기 때문에 기울기를 역전파 시킬 수 있었습니다.
대신 결과에 지나치게 영향을 주는 것을 막기 위해 auxiliary classifier의 loss에는 0.3을 곱하였습니다. 그리고 실제로 테스트하는 과정에서는 auxiliary classifier를 제거하고, 맨 끝의 softmax만을 사용하였습니다.
이는 주로 딥러닝 모델에서 추가적인 손실 함수를 도입하여 학습하는 과정에서의 효과를 높이는 데 사용되며 과적합 방지, 특징 추출 및 학습에 도움 등이 되는 효과가 있다.
즉, 가짜 분류기는 일반적으로 전체 네트워크에서 별도의 가중치를 가지고 있으며, 보조 손실 함수를 통해 학습된다.
2-2. Inception module (with 1x1 convolution)
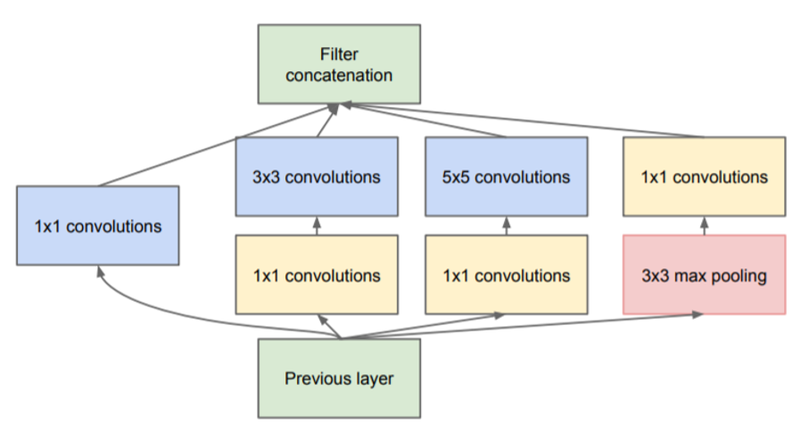
Inception module을 만드는 데 필요한 라이브러리를 불러옵니다.
# 인셉션 모듈을 만드는 데에 필요한 모듈 불러오기
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.utils import plot_model # 모델 시각화# Inception 블록을 만들기 위한 함수
def inception(input_layer, conv1_filter, conv3_in, conv3_out, conv5_in, conv5_out, pooling_out):
# 1x1 사이즈의 kernel을 이용한 convolution2d layer
conv1 = keras.layers.Conv2D(conv1_filter, (1,1), padding='same', activation='relu')(input_layer)
# 3x3 사이즈의 kernel을 이용한 convolution2d layer
conv3 = keras.layers.Conv2D(conv3_in, (1,1), padding='same', activation='relu')(input_layer) # Naive 버전과 가장 차별화되는 부분: 1x1 convolution
conv3 = keras.layers.Conv2D(conv3_out, (3,3), padding='same', activation='relu')(conv3)
# Q. 5x5 사이즈의 kernel을 이용한 convolution2d layer 를 만들어 보세요.
conv5 = keras.layers.Conv2D(conv5_in, (1,1), padding='same', activation='relu')(input_layer)
conv5 = keras.layers.Conv2D(conv5_out, (5,5), padding='same', activation='relu')(conv5)
# 3x3 max pooling layer (데이터의 가로 세로를 3x3로 살펴보고 가장 큰 값만 뽑아낸다)
pool = keras.layers.MaxPooling2D((3,3), strides=(1,1), padding='same')(input_layer)
pool = keras.layers.Conv2D(pooling_out, (1,1), padding='same', activation='relu')(pool)
# 위에서 언급한 4개의 layer 통해서 나온 feature map들을 모두 concatenation 한다.
out_layer = keras.layers.Concatenate()([conv1, conv3, conv5, pool])
return out_layerinput layer를 정의하고 Inception 블록을 생성합니다.
input_data = keras.layers.Input(shape=(256, 256, 3))
inception_out = inception(input_data, 64, 96, 128, 16, 32, 32)print(inception)
# 모델 만들기
model = keras.models.Model(inputs=input_data, outputs=inception_out)
# 생성한 모델의 구조 확인하기
model.summary()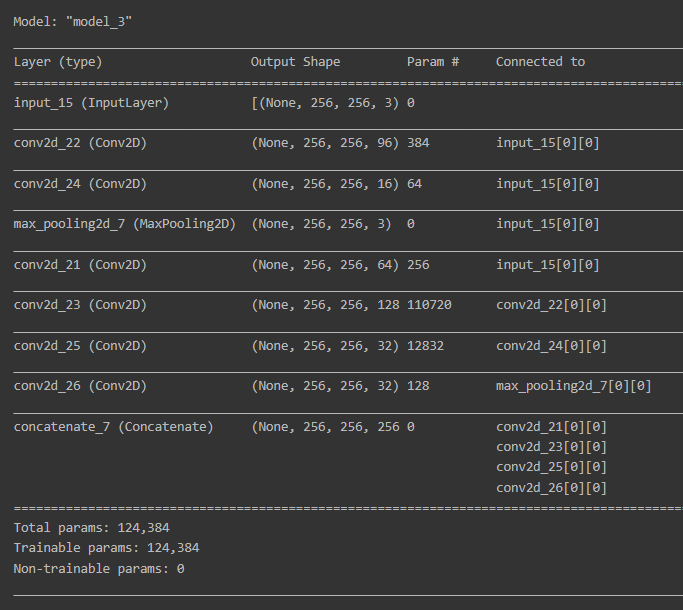
plot_model 함수로 모델의 구조를 시각화합니다.
# 모델 구조 시각화하기
plot_model(model, show_shapes=True, to_file='inception.png')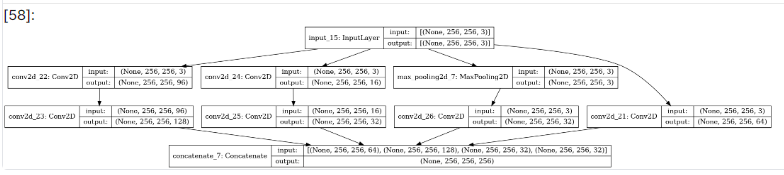
3. Skip Connection(ResNet)
Q. GoogLeNet은 Vanishing gradient의 문제를 해결하기 위해 Inception Module을 사용했습니다. ResNet은 어떤 것을 사용해서 이 문제를 해결하려고 했는지 설명해 보세요.
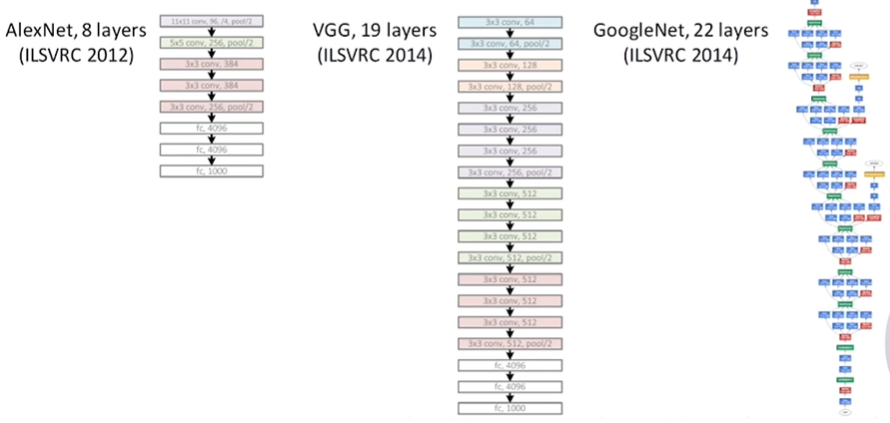
레이어가 깊어지면서 생기는 Vanishing gradient 문제를 해결하기 위해
(Vanishing gradient는 error가 Back-propagation이 안 되는 것.)
ResNet은 Skip Connection이라고 하는 residual learning을 통해 문제를 해결.
Q. Residual Learning: Skip Connection을 통해서 얻을 수 있는 것은 무엇인지 설명해 보세요.
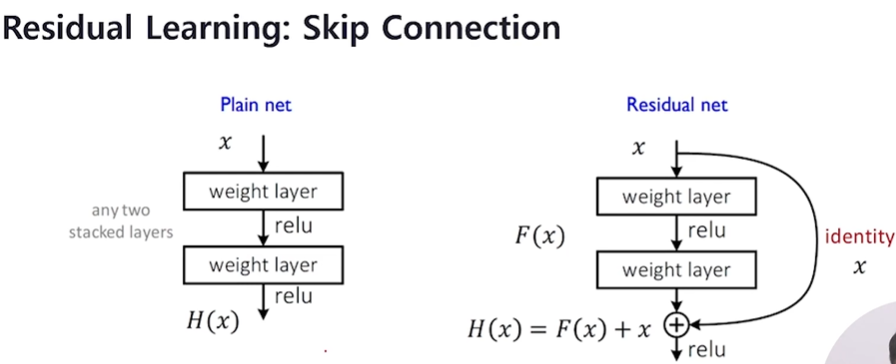

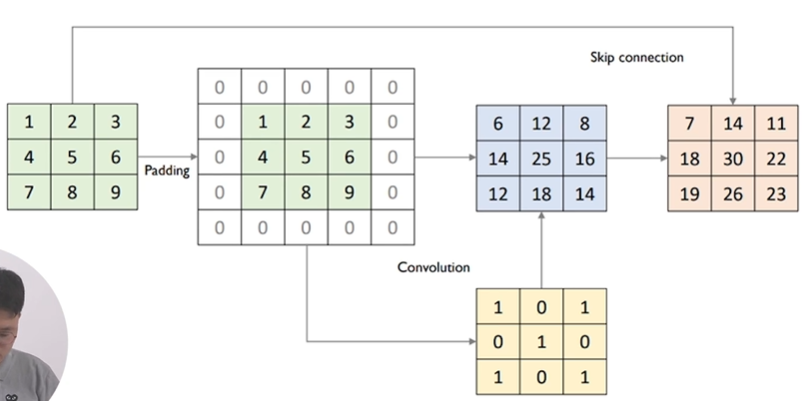
Residual Learning은 일정 시점마다 input x 자체를 skip connection을 통해 연결합니다.
이로 인해 backpropagation을 할 때 Identitiy mapping을 통해 loss 값이 변함 없이 전달되기 때문에 Gradient flow가 원활하게 이루어집니다.
따라서 모델을 깊게 쌓는 것에 대한 부담이 줄어듭니다.
그래서 Vanishing gradient의 문제를 해결할 수 있어
Skip Connection을 gradient “highway”라고 부르기도 합니다.
3-1. skip connection 코드 살펴보기
먼저 필요한 라이브러리를 불러옵니다.
# 모델을 만드는 데에 필요한 모듈 불러오기
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras.utils import plot_model # 모델 시각화skip connection이 구현된 함수 residual_module을 정의합니다.
residual_module을 정의할 때 주의점은
skip connection을 구성하기 위해서
connection을 통해서 합해지는 feature map들의
가로x세로x채널 사이즈가 맞아야 한다는 것입니다.
def residual_module(input_layer, n_filters):
merge_input = input_layer
# if문에서는 채널 사이즈가 동일한지 확인하고, 만일 동일하지 않다면 1x1 convolution을 통해서 채널 사이즈를 맞춰 준다.
if input_layer.shape[-1] != n_filters:
merge_input = keras.layers.Conv2D(n_filters, (1,1), padding='same', activation='relu')(input_layer) # n_filter로 채널 사이즈를 맞춰 준다.
# Conv2D layer
conv1 = keras.layers.Conv2D(n_filters, (3,3), padding='same', activation='relu')(input_layer)
# Conv2D layer
conv2 = keras.layers.Conv2D(n_filters, (3,3), padding='same', activation='linear')(conv1)
# Add를 통해서 skip connection을 구현하는 부분
out_layer = keras.layers.Add()([conv2, merge_input])
out_layer = keras.layers.Activation('relu')(out_layer)
return out_layerinput layer를 정의하고 residual module을 생성합니다.
input = keras.layers.Input(shape=(256, 256, 3))
residual_out = residual_module(input, 64)print(residual_out)
input layer와 residual module을 연결해서 모델을 만듭니다.
model = keras.models.Model(inputs=input, outputs=residual_out)
model.summary()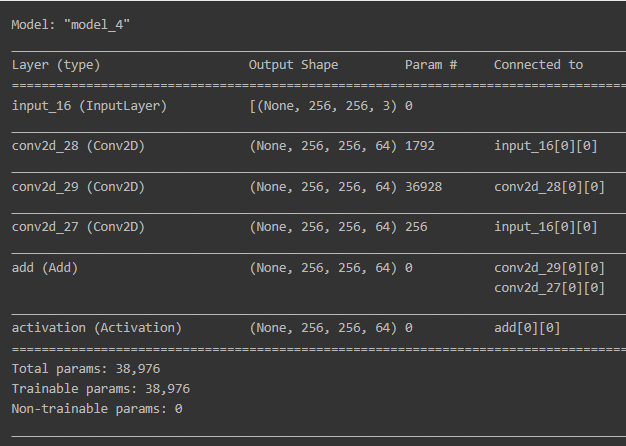
plot_model 함수로 모델의 구조를 시각화합니다.
plot_model(model, show_shapes=True, to_file='residual_module.png')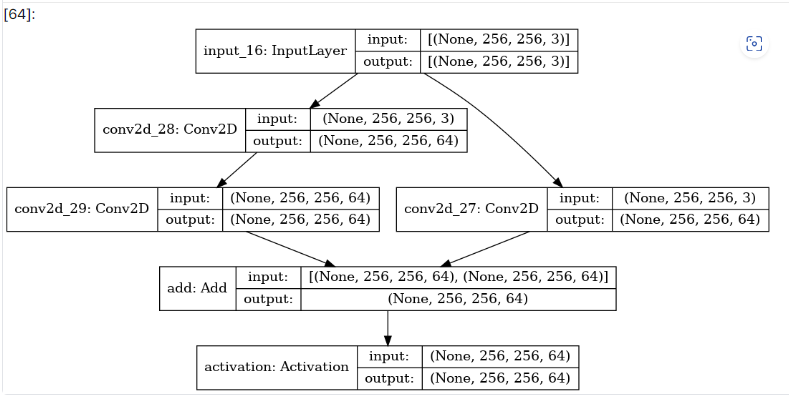
마무리
Q. 심화된 CNN 구조의 핵심은 어떤 것이며 이를 통해 발생할 수 있는 문제는 어떤 것이 있었는지 설명해 보세요.
심화된 CNN 모델의 핵심은 모델의 깊이를 늘이는 데에 있습니다. 깊이를 늘리는 데 가장 큰 문제는 Vanishing gradient입니다. 따라서 Vanishing gradient를 해결할 수 있는 구조를 만드는 것이 CNN 모델 발전의 핵심입니다.
Q. Skip connection을 모델에 적용하면 어떤 효과를 주는지 설명해 보세요.
Skip connection은 깊은 모델에서 error backpropagation이 원활하게 이루어지도록 만듭니다. 그래서 skip Connection을 gradient “highway”라고 부르기도 합니다.
