
리팩토링 계기
졸업 요건을 검증하는 기능은 단순한 사칙연산이 아닙니다. 학번(입학년도)별, 학과별, 이수 구분(전공필수, 전공선택, 교양 등)별로 서로 다른 규칙이 적용되어야 하며, 재수강/포기 과목 처리와 같은 성적 필터링 로직까지 포함되어야 합니다.
초기 개발 단계에서는 이 모든 로직을 하나의 거대한 SQL(CTE, Common Table Expression)로 처리했습니다. 하지만 서비스가 고도화되면서 '거대 쿼리'가 가진 유지보수의 한계와 성능적 비효율을 마주하게 되었습니다.
이번 글에서는 유지보수가 불가능한 수준의 CTE 쿼리를 비즈니스 로직 단위로 분해(Decomposition)하고, Java 애플리케이션 레벨에서 조합하는 방식으로 리팩토링한 과정을 공유합니다.
1. 문제 상황: 모든 것을 해결하려 했던 "God Query"
초기 버전의 GraduationQueryRepository는 말 그대로 DB에 모든 책임을 전가하는 구조였습니다.
졸업 요건 조회, 수강 이력 조회, 재수강 필터링, 그리고 이수 구분별 학점 집계까지 하나의 쿼리(getStudentAreaProgress)에서 수행했습니다. 이를 위해 WITH문(CTE)을 중첩하여 사용했습니다.
기존 코드 (Legacy)
// GraduationQueryRepository.java (Before)
public List<AreaProgressDto> getStudentAreaProgress(...) {
String sql = """
WITH raw_courses AS ( ... ), -- 1. 수강 이력 조회 및 재수강 필터링
latest_courses AS ( ... ), -- 2. 최신 성적만 추출
area_requirements AS ( ... ), -- 3. 학과/입학년도별 졸업 요건 조회
aggregated_progress AS ( ... ) -- 4. 요건과 성적 JOIN 및 집계
SELECT ... FROM aggregated_progress ...
""";
// ... 쿼리 실행 및 매핑
}이 방식의 문제점
- 디버깅의 어려움: 특정 학생의 졸업 요건이 잘못 계산되었을 때, 이것이 "요건 데이터 문제"인지, "수강 이력 필터링 문제"인지, "JOIN 실수"인지 파악하기 위해 100줄이 넘는 SQL을 눈으로 따라가야 했습니다.
- 캐싱 불가: 졸업 요건(
area_requirements)은 자주 변하지 않는 데이터임에도, 쿼리 내부에 강결합되어 있어 별도로 캐싱할 수 없었습니다. 매 요청마다 DB I/O가 발생했습니다. - 확장성 부족: 로직 변경(예: 편입생 요건 추가 등)이 필요할 때마다 SQL 쿼리를 수정해야 했으며, 이는 사이드 이펙트 발생 확률을 높였습니다.
2. 해결 전략: "DB는 데이터만, 로직은 애플리케이션에서"
저는 이 거대한 쿼리를 3개의 논리적 단계로 분해했습니다.
- 졸업 요건 조회 (Requirements): 해당 학생이 만족해야 할 기준표를 가져옵니다. (캐싱 가능)
- 수강 이력 조회 (Courses): 학생이 실제로 수강한 과목 리스트를 가져옵니다.
- 매칭 및 집계 (Aggregation): 위 두 데이터를 Java 애플리케이션 메모리 상에서 비교하고 계산합니다.
아키텍처 변화 (Mermaid Diagram)
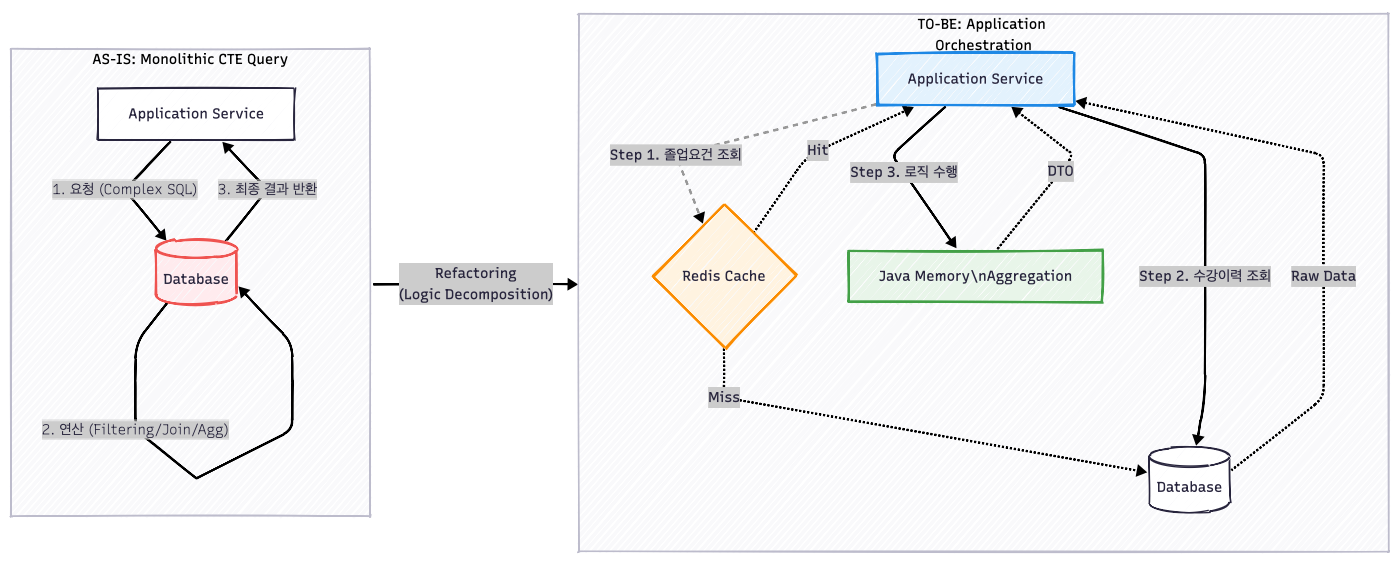
이 구조의 핵심은 "변하는 데이터(수강 이력)"와 "변하지 않는 데이터(졸업 요건)"를 분리한 것입니다.
3. 코드 구현 (Refactoring)
Step 1. 졸업 요건 조회 및 캐싱 적용
졸업 요건은 학과(departmentId)와 입학년도(admissionYear)에 따라 결정되는 정적 데이터입니다. 이를 별도 메서드로 분리하고 Redis 캐싱을 적용할 수 있는 구조를 만들었습니다.
// GraduationQueryRepository.java
/* 졸업 요건 조회 (단순 조회 쿼리) */
public List<AreaRequirementDto> getAreaRequirements(Long departmentId, Integer admissionYear) {
String sql = """
SELECT area_type, required_credits, ...
FROM department_area_requirements
WHERE department_id = :departmentId AND admission_year = :admissionYear
""";
// ... 결과 반환
}
/* 캐싱 로직 적용 */
public List<AreaRequirementDto> getAreaRequirementsWithCache(Long deptId, Integer admissionYear) {
// 1. 캐시 조회
List<AreaRequirementDto> cached = academicCache.getGraduationRequirements(deptId, admissionYear);
if (cached != null) return cached;
// 2. DB 조회 및 캐시 저장
List<AreaRequirementDto> result = getAreaRequirements(deptId, admissionYear);
academicCache.setGraduationRequirements(deptId, admissionYear, result);
return result;
}Step 2. 유효 수강 이력 조회
CTE의 복잡한 로직 중 하나였던 '재수강 제거' 및 '최신 성적 필터링' 로직을 별도의 쿼리로 분리했습니다. DISTINCT ON을 활용해 깔끔하게 최신 이력만 가져옵니다.
public List<CourseInternalDto> getLatestValidCourses(UUID studentId) {
String sql = """
SELECT DISTINCT ON (c.course_code, co.faculty_division_name) ...
FROM student_courses sc
...
WHERE sc.grade NOT IN ('F', 'R') -- F학점, 재수강 삭제된 과목 제외
ORDER BY c.course_code, co.year DESC, co.semester DESC ...
""";
// ...
}Step 3. Java 레벨에서의 집계 (Aggregation)
이제 확보된 두 데이터를 Java의 Stream과 Collection을 활용해 조합합니다. SQL의 GROUP BY가 수행하던 역할을 Java 코드가 대신하며, 훨씬 명시적이고 디버깅하기 쉬워졌습니다.
public List<AreaProgressDto> getStudentAreaProgress(UUID studentId, Long departmentId, Integer admissionYear) {
// 1. 졸업 요건 조회 (캐시 활용)
List<AreaRequirementDto> requirements = getAreaRequirementsWithCache(departmentId, admissionYear);
// 2. 수강 이력 조회
List<CourseInternalDto> completedCourses = getLatestValidCourses(studentId);
// 3. 이수 구분에 따라 과목 그룹핑 (Map<AreaType, List<Course>>)
Map<String, List<CourseInternalDto>> coursesByArea = completedCourses.stream()
.collect(Collectors.groupingBy(CourseInternalDto::getAreaType));
List<AreaProgressDto> result = new ArrayList<>();
// 4. 요건별 달성 현황 계산 (Loop)
for (AreaRequirementDto req : requirements) {
List<CourseInternalDto> taken = coursesByArea.getOrDefault(req.areaType(), Collections.emptyList());
// 학점 합계 계산
int earnedCredits = taken.stream().mapToInt(CourseInternalDto::getCredits).sum();
// DTO 생성 및 리스트 추가
result.add(new AreaProgressDto(..., req.requiredCredits(), earnedCredits, ...));
}
return result;
}4. 리팩토링의 성과
1) 로직의 가시성 확보 및 유지보수성 증대
기존에는 로직을 검증하기 위해 복잡한 SQL 실행 계획을 분석해야 했지만, 이제는 Java 코드의 Breakpoint를 통해 데이터가 어떻게 필터링되고 계산되는지 직관적으로 확인할 수 있게 되었습니다.
2) 캐싱 포인트 확보를 통한 성능 최적화
가장 큰 성과는 캐싱 전략의 고도화입니다.
- Before: 쿼리 전체 결과만 캐싱 가능. (학생별로 키가 다름 → 히트율 낮음)
- After:
졸업 요건이라는 중간 데이터를 캐싱. (학과/입학년도가 같은 학생들은 모두 캐시 공유 → 히트율 대폭 상승)
실제 부하 테스트 결과, Redis 캐시가 적용된 상태에서 졸업 요건 계산 속도는 평균 893ms에서 32ms로 약 96% 단축되었습니다. (상세한 성능 측정 결과는 쿼리 튜닝 포스팅 링크에서 다룹니다.)
3) 유연한 확장성
CTE 방식에서는 불가능했던 복합적인 비즈니스 로직을 추가하기 쉬워졌습니다. 예를 들어, 특정 학번의 경우 "전공 선택 학점이 부족하면 교양 학점에서 차감한다"와 같은 예외 로직이 필요할 때, SQL을 뜯어고칠 필요 없이 Java의 if-else 로직으로 안전하게 구현할 수 있게 되었습니다.
마무리
"DB 쿼리 한 방이 가장 빠르다"는 통념이 있지만, 복잡한 비즈니스 로직이 DB에 숨어버리는 순간 유지보수의 재앙이 시작됩니다.
이번 리팩토링은 단순히 쿼리를 쪼개는 작업을 넘어, 애플리케이션이 주도권을 가지고 로직을 제어하는 구조로 전환했다는 데에 의의가 있습니다. 덕분에 척척학사 서비스는 더 복잡한 졸업 요건에도 유연하게 대응할 수 있는 단단한 백엔드 구조를 갖추게 되었습니다.
