1. 기존 설계의 문제점: 단일 트랜잭션의 부작용
척척학사의 포털 데이터 동기화 과정은 학생 정보, 학과, 전체 학기별 학업 이력 및 수강 기록 등 방대한 데이터를 가져와 서비스 도메인 모델로 매핑하는 복잡한 단계를 거칩니다.
이 데이터들은 학기라는 단위로 연결되어 있어, 트랜잭션을 분리할 경우 데이터의 일부만 업데이트되거나 누락되는 데이터 정합성 문제가 발생할 우려가 있었습니다.
따라서, 모든 데이터가 완벽하게 반영되거나, 아니면 아예 반영되지 않아야 했습니다.
이를 지키기 위해 포털 데이터 동기화 과정의 모든 로직을 하나의 @Transactional로 묶어 데이터 무결성을 보장하고자 했습니다.
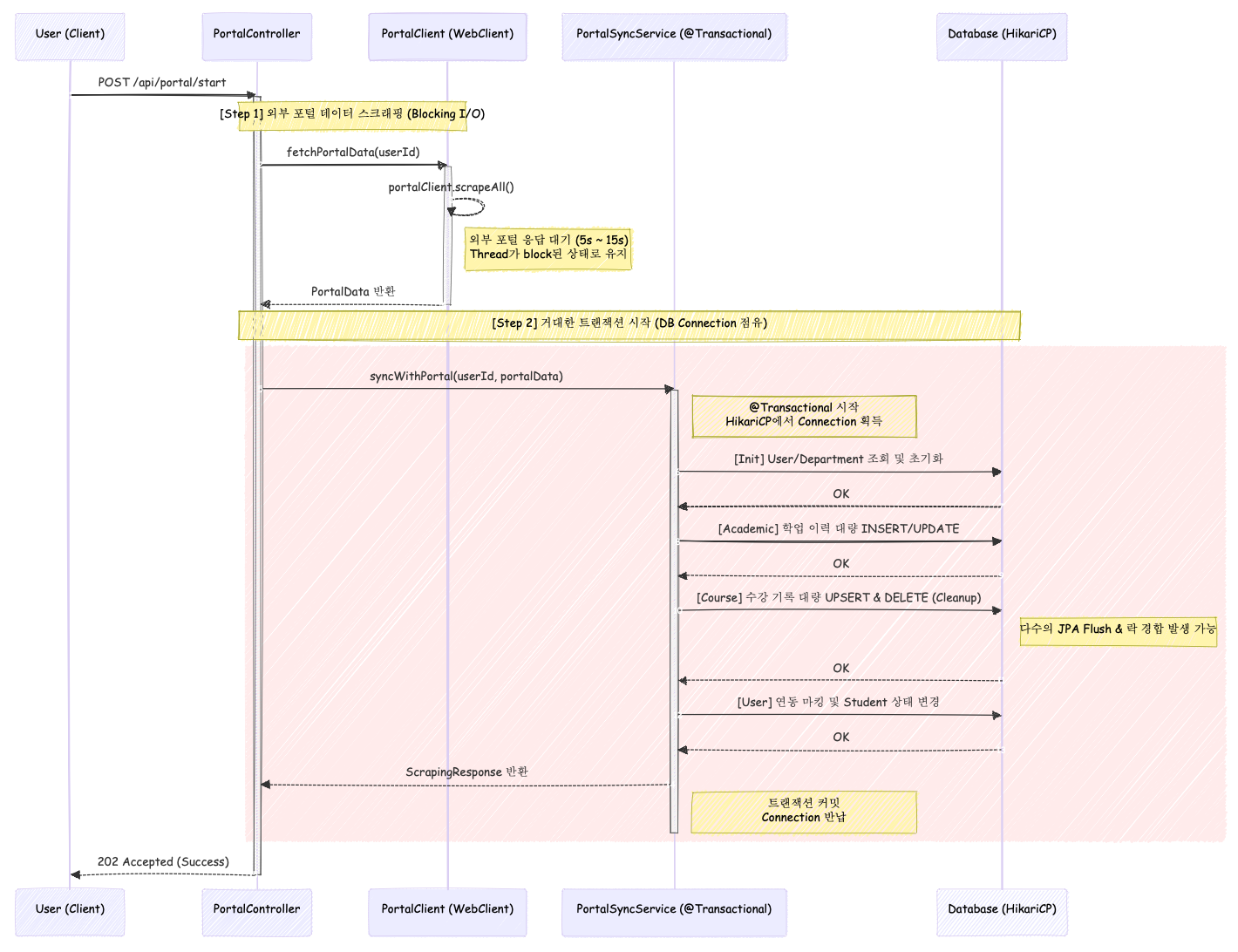
하지만 이러한 선택에는 두 가지 치명적인 기술적 부채가 존재합니다.
-
스레드 기아(Thread Starvation) (Blocking I/O): 외부 포털 데이터를 스크래핑하는 단계는 WebClient를 사용하고 있지만, 내부 로직상 결과를 기다려야 하는 동기적 구조(
.block())로 처리되어 애플리케이션 스레드가 차단됩니다.
문제는 스크래핑 서버의 응답 속도에 따라 짧게는 5초에서 길게는 15초까지 애플리케이션 스레드가 차단된 채 아무런 일도 하지 못하고 대기하게 된다는 점이었습니다. -
긴 호흡의 트랜잭션과 리소스 점유: 스크래핑이 완료된 후 시작되는
@Transactional로직 역시 문제였습니다. 수천 줄의 학업 이력을 한 번에saveAll하고 기존 수강 기록을 정리하는 과정을 DB 커넥션을 획득한 채 매우 긴 시간 동안 리소스를 점유하게 됩니다.
초기 사용자 환경에서는 동시 접속자가 적어 이 구조가 큰 문제가 되지 않았습니다.
그러나 서비스가 성장하며, 특정 시기에 사용자가 몰리면서 트래픽 과부하가 발생하며 문제가 될 여지가 존재했습니다.
2. 데이터 계측을 통한 병목 지점 파악
분석 관점: 특정 상황(트래픽 급증)에서 이론적 결함이 어떻게 시스템을 마비시키는지 실제 계측 데이터로 증명합니다.
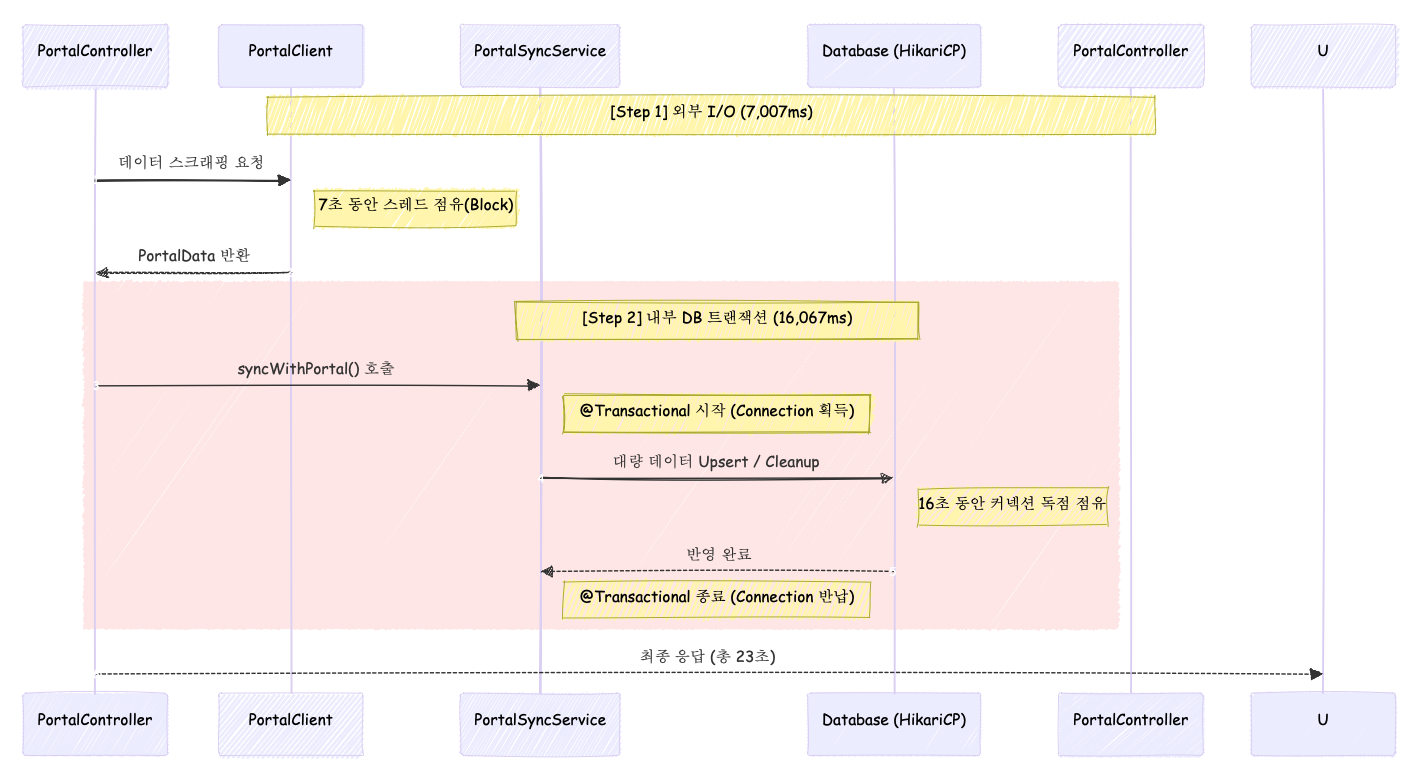
2.1 단일 요청의 타임라인 분석
가설로만 존재하던 병목을 확인하기 위해, 단일 요청의 흐름을 추적하여 로그(Loki)에 기록된 실제 소요 시간을 계측했습니다.
long t0 = LogTime.start();
// ... 로직 수행 ...
long tookMs = LogTime.elapsedMs(t0);
// 외부 I/O (포털 스크래핑)
log.info("[BIZ] portal.fetch.done took_ms={}", tookMs);
// 내부 I/O (DB 동기화 반영)
log.info("[BIZ] portal.sync.done took_ms={}", tookMs);- 외부 I/O (포털 스크래핑): 7,007ms (약 7초)
[BIZ] portal.fetch.done took_ms=7007
- 내부 I/O (DB 동기화 반영): 16,067ms (약 16초)
[BIZ] portal.sync.done took_ms=16067
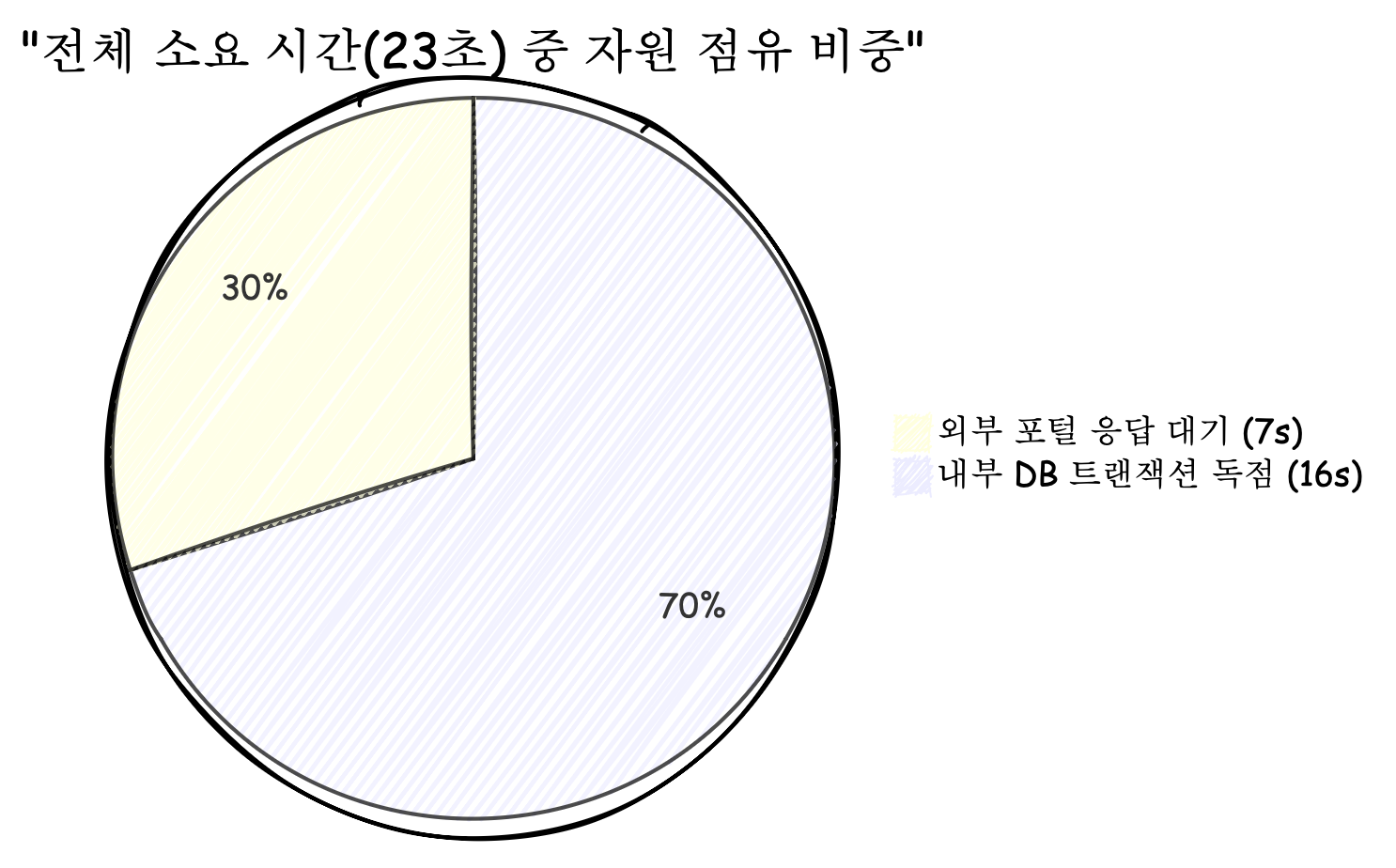
계측 결과는 기존 가설보다 심각했습니다. 외부 시스템의 응답을 기다리는 시간보다, 내부 DB 트랜잭션 내에서 데이터를 처리하는 시간이 2배 이상 길었습니다.
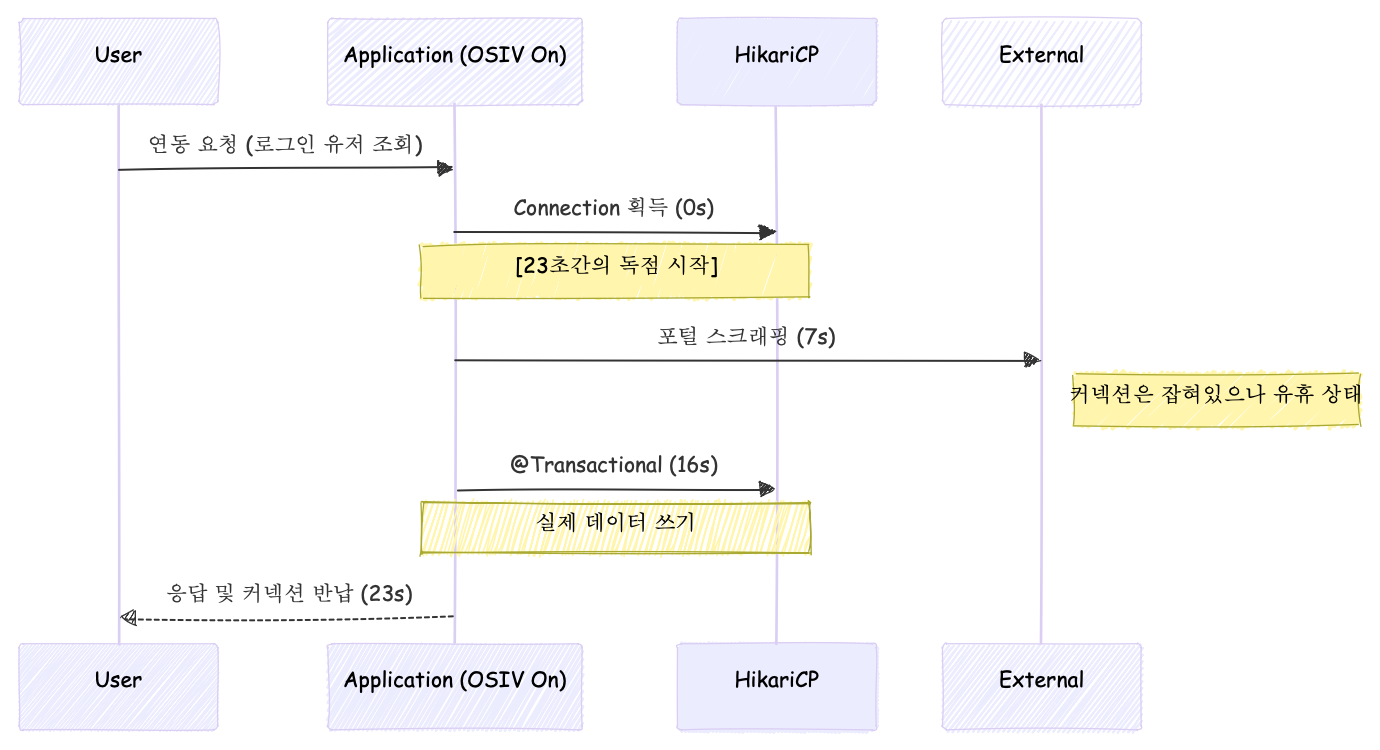
단 한 명의 사용자를 처리하기 위해 DB 커넥션을 무려 16초 동안 독점하고 있었으며, 이 기간 동안 히카리 풀(HikariCP)의 자원은 Lock 상태에 빠지게 됩니다.
사실 OSIV 설정으로 인해 16초가 아닌 23초 동안 독점하고 있었습니다.
이러한 극단적인 리소스 점유는 트래픽이 조금만 몰려도 연쇄 장애의 원인이 됩니다.
- 스레드 기아: 외부 포털 응답을 기다리는 7초 동안 톰캣 스레드가 묶입니다.
- 커넥션 풀 고갈: 스크래핑 직후 시작되는
@Transactional로직이 16초 동안 커넥션을 점유합니다. 단순히 DB 작업뿐만 아니라, OSIV 설정으로 인해 앞선 7초의 스크래핑 단계부터 커넥션이 조기에 획득되고 있었습니다. 결과적으로 단 한 명의 사용자가 DB 커넥션을 무려 23초(7s + 16s) 동안 독점하게 됩니다. - 대기열 폭발: 뒤이어 들어온 요청들은 커넥션을 받지 못하고 Pending 상태로 쌓이며
Connection Acquire Latency가 폭증합니다. - 서비스 붕괴: 설정된
Connection Timeout(5s)을 초과하여ConnectionTimeoutException이 발생, 전체 서비스가 응답 불능 상태에 빠집니다.
2.2 부하 테스트: 동시 사용자(VUs) 50명, 외부 포털 지연 7초 재현
이러한 극단적인 리소스 점유가 실제 트래픽 환경에서 어떤 문제를 가지는지 확인하기 위해, k6를 활용한 부하테스트를 진행했습니다.
- 테스트 조건: 동시 사용자(VUs) 50명, 외부 포털 지연 7초 재현
- 결과: 성공률 0%, 에러율 100%. 단 50명의 동시 요청만으로도 전체 서비스가 마비되었습니다.
// k6 실행 결과 요약
checks_succeeded...: 0% 0 out of 386
http_req_duration....: avg=7.31s max=34.54s p(95)=12.31s
http_req_failed......: 100.00% 386 out of 386386번의 요청 중 성공(202)은 0건이며, 모든 요청이 504/500 에러를 반환했습니다
특히
http_req_duration의 p(95)가 12.31초를 기록하며 대부분의 유저가 응답 불능 상태에 빠졌음을 보여줍니다.
모니터링 시스템에 기록된 지표를 확인해보겠습니다.
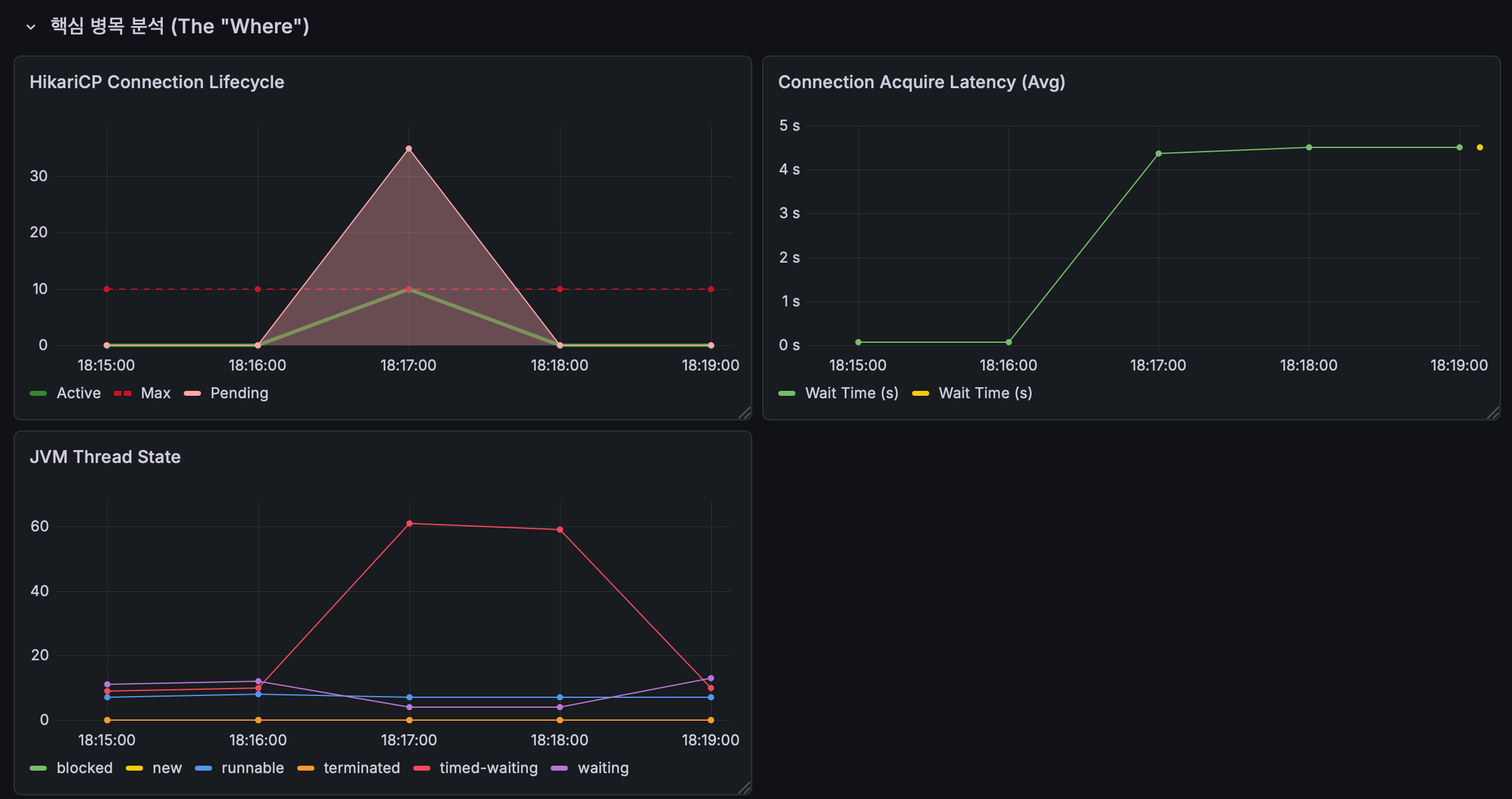
-
HikariCP Connection Lifecycle: 커넥션 풀(10개)이 가득 찬 상태에서 커넥션을 얻지 못한 요청들(Pending, 분홍색)이 40개까지 치솟았습니다. 이는 전체 요청의 80%가 DB 작업 대기열에서 고립되었음을 의미합니다.
-
Connection Acquire Latency: 커넥션 획득 대기 시간이 설정된 Timeout(5s)에 도달했습니다. 대기열의 유저들은 로직을 수행하기도 전에 모두 타임아웃 판정을 받습니다.
-
JVM Thread State: Timed-waiting 상태의 스레드가 60개 이상으로 폭증했습니다. 외부 I/O를 동기적으로 기다리는 7초 동안 서버의 스레드 자원까지 마비되었음을 증명합니다.
2.3. 장애 로그 분석 (Loki)
Grafana Loki를 통해 추출한 서버 로그는 다음과 같습니다.
ERROR 2026-02-05 09:16:33.378
[http-nio-8080-exec-26] ERROR o.h.e.jdbc.spi.SqlExceptionHelper -
HikariPool-ChukChuk - Connection is not available, request timed out after 5000ms. 단순히 비즈니스 로직이 실패한 것이 아니라, DB 커넥션이라는 핵심 자원이 16초간 점유(Lock)됨으로써 서버가 들어오는 모든 요청을 거부하게 된 것입니다.
선행 작업이 커넥션을 반납하기 전에 후행 요청들의 대기 시간(5s)이 만료되면서 발생하는 전형적인 자원 격차 장애입니다
3. 트랜잭션 범위가 가용성에 미치는 영향 분석
분석 관점: 트랜잭션 범위를 유한 자원의 점유 시간(Cost) 관점에서 분석하고, 시스템 처리율에 미치는 영향을 분석합니다.
3.1. 처리율의 수학적 붕괴
일반적인 @Transactional은 메서드 시작과 동시에 DB 커넥션을 획득하고 종료 시점에 반납합니다. 이 과정에서의 시스템 처리율은 아래 수식으로 결정됩니다.
- 현재 아키텍처 (동기식 구조): 7초(Fetch) + 16초(Sync) = 23초 점유
- 이상적인 아키텍처 (비동기/분리 구조): 순수 DB 쓰기 작업만 포함 = 0.1초 미만 점유
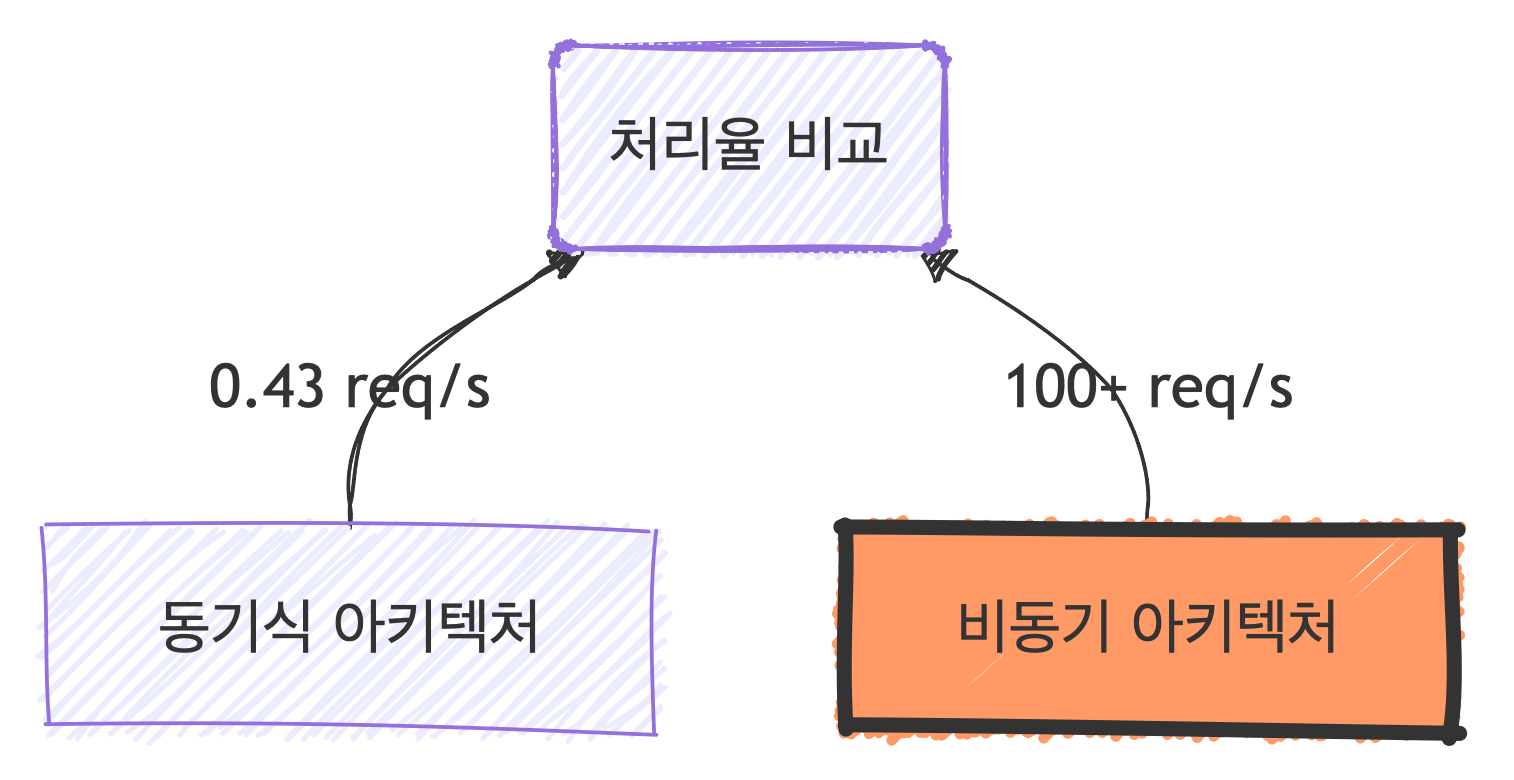
10개의 커넥션으로 낼 수 있는 결과의 차이
결론: 단지 트랜잭션 내에 외부 I/O와 무거운 연산을 포함했다는 이유만으로, 시스템의 잠재적 처리 능력을 약 232배() 스스로 제한하고 있었습니다.
3.2. 비즈니스 프로세스(Work) vs 데이터 정합성(Transaction)
프로세스 전체를 하나의 트랜잭션으로 묶는 행위는 네트워크의 불확실성을 데이터베이스의 안정성 영역으로 강제 결합하는 설계적 오류입니다.
| 구분 | 비즈니스 프로세스 (Work) | 데이터 정합성 단위 (Transaction) |
|---|---|---|
| 자원 성격 | CPU, Memory, Network I/O (가변적) | DB Connection (한정적 자원) |
| 실패 영향 | 재시도 가능 (Idempotent) | 원자성 보장 (Atomic) |
| 점유 비용 | 시스템 전체에 미치는 영향 미비 | 매우 높음 (시간에 비례하여 풀 고갈) |
내부 I/O의 16초는 비즈니스 로직을 수행하는 시간이 아니라, 커넥션이라는 유한한 자원을 인질로 잡고 다른 요청의 진입을 막은 시간입니다. 트랜잭션의 경계는 데이터 보호의 범위를 넘어 시스템 가용성의 경계가 되어야 합니다.
3.3. 트랜잭션은 설계 문제 분석
부하 테스트에서 확인된 Connection Acquire Latency의 폭증은 트랜잭션 설계가 잘못되었음을 알리는 정량적 지표입니다.
- 자원의 기회비용 산출: 커넥션 1개를 16초 동안 사용하는 행위는, 0.1초짜리 트랜잭션 160개를 처리할 수 있는 시간적 자원을 단 1명의 유저가 독점하는 것과 같습니다.
- 보호 대상의 재정의: 트랜잭션은 워크플로우 전체를 보호하는 도구가 아닙니다. 오직 더 이상 쪼갤 수 없는 데이터 변경의 순간만을 보호해야 합니다.
4. 아키텍처 개선 방향 및 대안 비교
분석 관점: 각 대안이 시스템 가용성()과 데이터 무결성() 사이에서 지불해야 하는 기회비용을 정량적으로 평가하고 최적의 경로를 결정합니다.
4.1. 대안별 기술적 비교 분석
고려할 수 있는 3가지 선택지를 가용성, 일관성, 구현 복잡도 관점에서 비교했습니다.
| 대안 | 핵심 전략 | 장점 (Gain) | 리스크 (Risk) |
|---|---|---|---|
| A. 단일 트랜잭션 | 모든 로직을 @Transactional 하나로 묶음 | 완벽한 원자성 (All-or-Nothing) | 가용성 붕괴: 커넥션 16s 독점으로 인한 시스템 마비 |
| B. 단계별 분리 | 비즈니스 단계마다 트랜잭션 경계를 분리 | 커넥션 회전율(Pool Rotation) 향상 | 데이터 미아: 중간 단계 실패 시 부분 성공 상태로 남음 |
| C. 비동기 + 상태 머신 | 이벤트 발행 후 즉시 응답, 백그라운드 처리 | 최대 가용성: 커넥션 점유 시간 0.1s 미만 | 복잡성 증가: 최종적 일관성 관리 및 재시도 로직 필요 |
4.2. 트랜잭션 전파 속성(Propagation)은 대안이 될 수 있을까?
분석 과정에서 REQUIRES_NEW와 같은 전파 속성 변경을 통해 부모 트랜잭션과 분리하여 가용성을 확보하는 방안을 검토했습니다. 하지만 이는 다음과 같은 이유로 근본적인 해결책이 될 수 없음을 확인했습니다.
- 물리적 점유 시간의 보존: 전파 속성은 트랜잭션 간의 '관계'를 설정할 뿐, 우리가 해결해야 할 물리적 작업 시간(16s) 자체를 줄여주지 못합니다.
- 데드락(Deadlock) 위험: 히카리 풀 크기가 제한적인 상황(10개)에서, 부모 트랜잭션이 커넥션을 잡은 채
REQUIRES_NEW로 새 커넥션을 요청하면 풀 전체가 고갈되어 시스템 전체가 영구 정지(Deadlock)될 위험이 매우 높습니다.
4.3. 최종 결정: 가용성을 위한 복잡도의 수용
부하 테스트 데이터는 가용성이 없는 일관성은 무의미하다는 결론을 도출하게 했습니다. 사용자가 접속조차 할 수 없는 시스템에서 데이터의 원자성을 논하는 것은 무의미하기 때문입니다.
따라서 대안 C(비동기 큐 + 상태 머신)를 최종 선택했습니다. 이를 통해 얻고자 하는 가치는 다음과 같습니다.
- 커넥션 점유의 즉시 해제: 요청 즉시 트랜잭션을 시작하지 않고 이벤트를 발행함으로써, DB 커넥션 점유 시간을 '찰나'로 줄입니다.
- 회복력(Resilience) 확보:
PENDING,SUCCESS,FAIL상태를 관리하는 상태 테이블을 도입하여, 비동기 처리 중 장애가 발생하더라도 유저가 상태를 인지하고 재시도할 수 있는 구조를 설계합니다. - 시스템 확장성: 외부 포털의 응답 속도 지연이 우리 서비스의 API 가용성에 영향을 미치지 않도록 아키텍처적 결합도를 분리합니다.
5. 비동기 작업 큐와 상태 머신 도입
분석 관점: 선택한 해결책의 구현 디테일과 다중 서버 환경에서의 동시성 제어 및 회복력 설계
5.1. 비동기 큐 구현을 위한 세 가지 선택지
비동기 처리를 구현함에 있어, 시스템 규모와 인프라 비용을 고려한 세 가지 대안을 검토했습니다.
| 구분 | In-Memory | DB-Based (선택) | External MQ |
|---|---|---|---|
| 기술 스택 | Spring @Async, Event | RDB (sync_job table) | RabbitMQ, Kafka, Redis |
| 장점 | 구현 속도 최상, 비용 제로 | 트랜잭션 일관성, 높은 신뢰성 | 무한한 확장성, 고가용성 |
| 단점 | 서버 재시작 시 데이터 휘발 | 폴링(Polling) 지연 가능성 | 인프라 관리 및 운영 비용 발생 |
Kafka나 RabbitMQ는 훌륭한 대안이지만, 현재 척척학사 프로젝트의 규모에서 별도의 메시지 브로커를 운영하는 것은 과도한 인프라 비용과 관리 공수를 발생시킨다고 판단했습니다.
대신 RDB 기반의 큐를 선택하여 다음과 같은 실질적인 이득을 얻고자 했습니다.
- 원자적 상태 전환: 유저의 연동 요청 정보와 Job 생성 처리를 하나의 DB 트랜잭션으로 묶어 데이터의 유실 없는 비동기 핸도버를 보장했습니다.
- 비용 효율성 및 운영 편의성: 추가 인프라 구축 없이 기존의 PostgreSQL을 활용하여 애플리케이션과 DB만으로 완결성 있는 비동기 구조를 구축했습니다.
- 가시성 확보: 별도의 모니터링 툴 없이도 SQL만으로 현재 진행 중인 작업의 상태(
PENDING,SUCCESS,FAIL)를 즉시 파악하고 대응할 수 있는 환경을 선호했습니다.
@Configuration
public class AsyncConfig {
@Bean(name = "portalTaskExecutor")
public TaskExecutor portalTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(3);
executor.setMaxPoolSize(7);
executor.setQueueCapacity(50);
executor.setThreadNamePrefix("portal-sync-");
// 큐가 꽉 찰 경우, API 스레드가 직접 처리하게 하여 유입 속도를 제한(Backpressure)
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
}메인 서비스의 스레드 기아를 방지하기 위해, 연동 작업만을 위한 독립적인 스레드 풀을 구축했습니다.
5.2. 상태 머신(State Machine)을 통한 작업 생명주기 관리
단순히 실행하는 것이 아니라, 작업의 각 단계를 sync_job 테이블의 current_phase로 세분화 하여 추적 가능성을 확보했습니다.

- INITIALIZED: 연동 요청 접수 및 Job 생성.
- PROCESSING: 워커가 작업을 점유하여 외부 포털 스크래핑(7s) 및 DB 동기화(16s) 수행 중.
- SUCCESS / FAIL: 작업 완료 또는 예외 발생 시 최종 상태 기록.
- RESUMING: 중단된 작업을 마지막 성공 지점부터 다시 시작하는 단계.
@Async("portalTaskExecutor")
public void handleSyncEvent(SyncStartEvent event) {
// 1. 작업 점유 (Short TX) -> 커넥션 즉시 반납
Long jobId = syncService.claimJob(event.getUserId());
// 2. 외부 I/O (No TX) -> 7초간 커넥션 점유 없음
PortalData data = portalScraper.fetch(event.getUserId());
// 3. 데이터 저장 (Short TX) -> 16초 점유 후 반납
syncService.saveResults(jobId, data);
}5.3. 다중 인스턴스 환경에서의 경합 상태(Race Condition) 해결
서버 인스턴스가 2대 이상으로 확장될 경우, 동일한 작업을 여러 스케줄러가 중복으로 낚아채는 중복 실행 리스크가 발생합니다.
이를 방지하기 위해 세 가지 방어 전략을 구축했습니다.
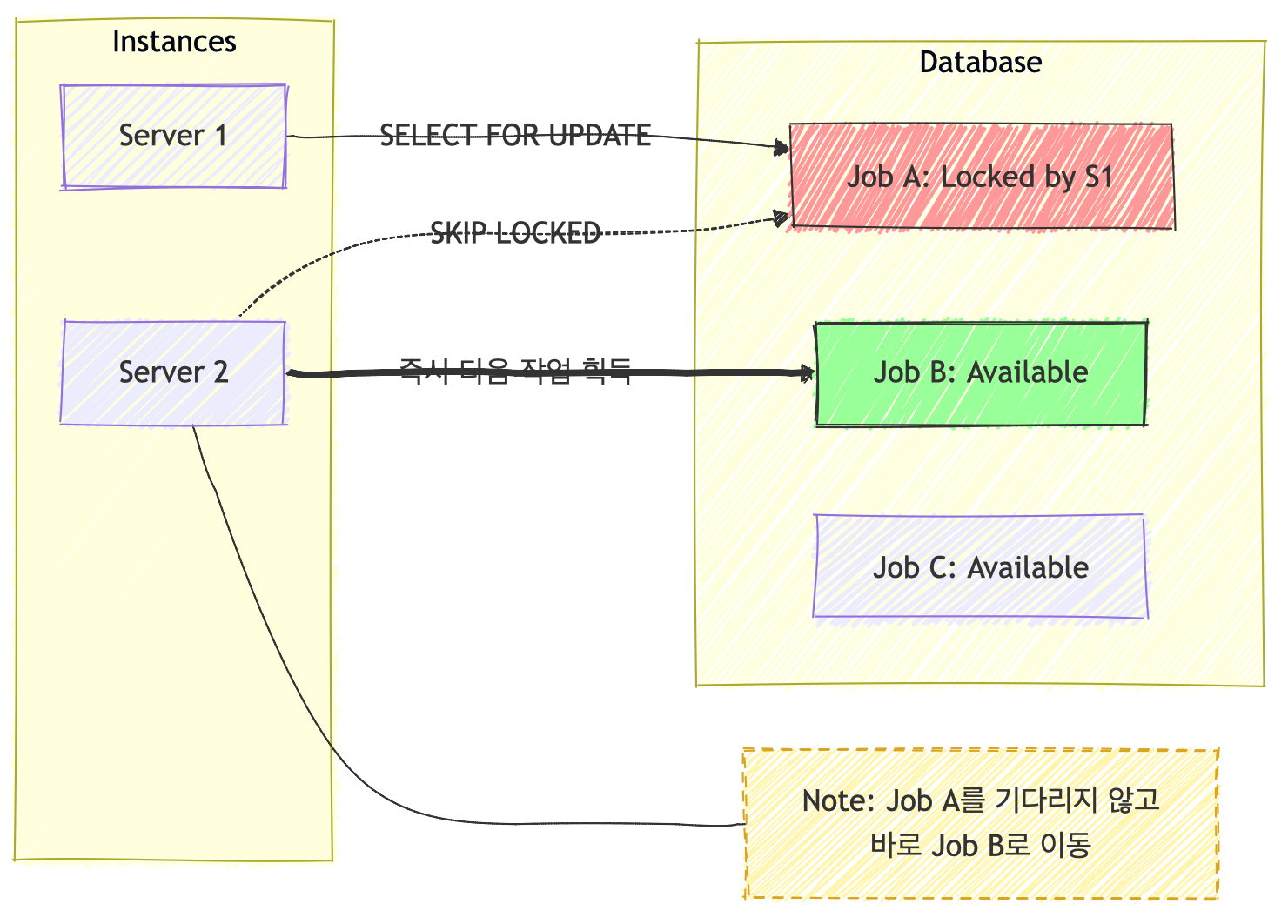
비관적 락(FOR UPDATE)과 경합 회피 (SKIP LOCKED)
- 일반적인 비관적 락은 앞선 서버의 작업이 끝날 때까지 다른 서버를 대기하게 만들어 다시 병목을 유발합니다. 이를 해결하기 위해
SELECT ... FOR UPDATE SKIP LOCKED쿼리를 사용합니다.
public interface SyncJobRepository extends JpaRepository<SyncJob, Long> {
@Query(value = "SELECT * FROM sync_job j " +
"WHERE j.status = 'INITIALIZED' " +
"ORDER BY j.created_at ASC LIMIT 5 " +
"FOR UPDATE SKIP LOCKED", nativeQuery = true)
List<SyncJob> findJobsToRecover();
}- 작동: 특정 서버가 작업 A를 점유 중이라면, 다른 서버는 대기하지 않고 해당 로우를 건너뛰어 다음 가용 작업을 즉시 찾아갑니다.
- 효과: 서버 확장 시 선형적인 처리량 향상을 보장합니다.
원자적 상태 전환 (Atomic Status Update)
- 작업을 조회함과 동시에 상태를
PROCESSING으로 업데이트하여, 이중 점유를 차단합니다.
애플리케이션 레벨의 멱등성(Idempotency) 보장
- 만약의 사태로 중복 실행되더라도 데이터가 오염되지 않도록, DB의 Unique 제약 조건을 활용한
UPSERT로직과 상태 체크 로직을 강제하여 시스템의 견고함을 더했습니다.
5.4. 최종 흐름 요약: 사용자 요청부터 백그라운드 완료까지
모든 설계 요소가 결합된 전체 데이터 동기화 프로세스의 흐름입니다. 사용자에게는 즉각적인 제어권을 반환하고, 한정된 자원인 DB 커넥션은 실제 작업이 일어나는 순간에만 효율적으로 점유하도록 설계했습니다.
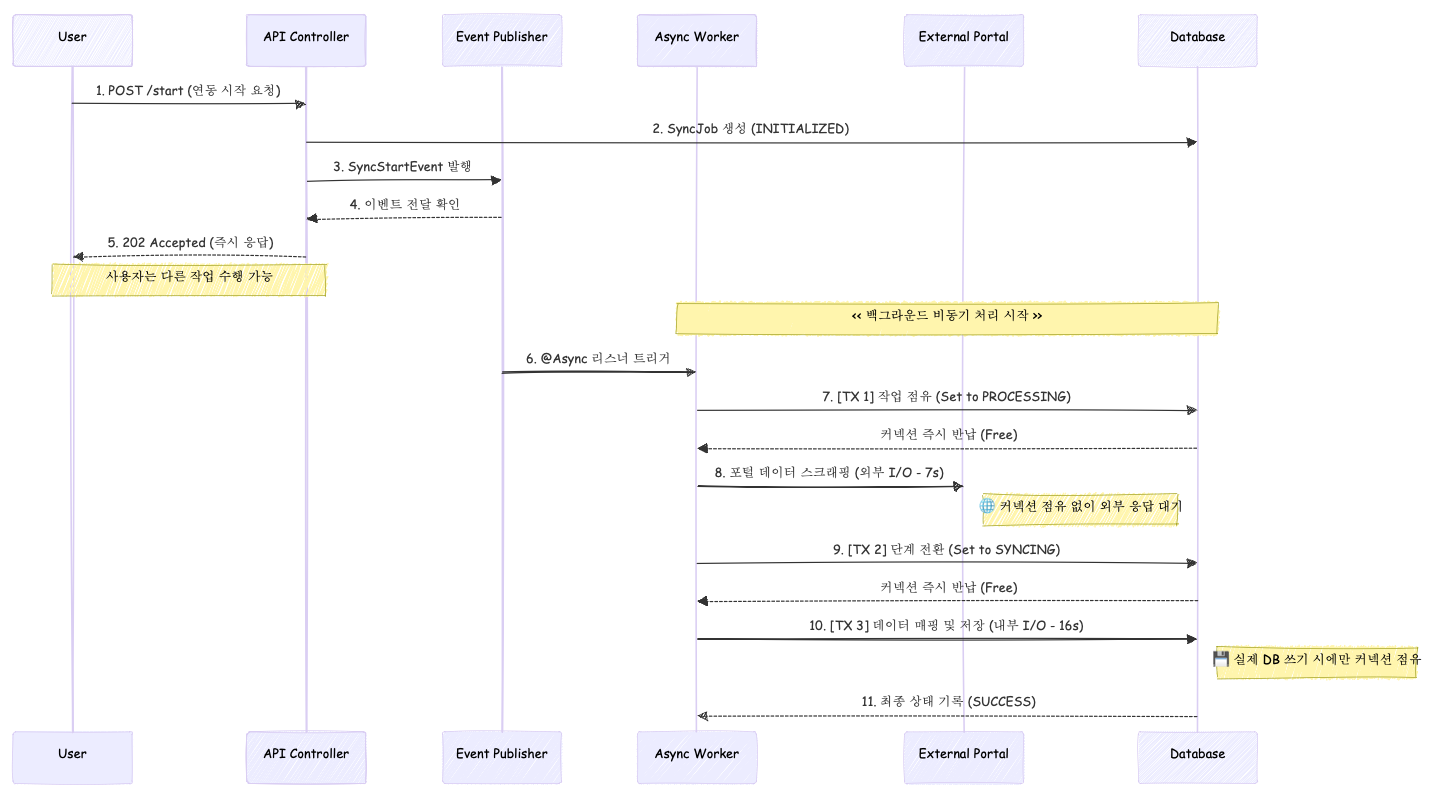
이 구조를 통해 기존 23초 동안 묶여 있던 DB 커넥션을 실제 데이터가 저장되는 16초 구간으로만 한정 지었으며, 특히 네트워크 지연이 심한 외부 I/O 구간(7초)에서 커넥션을 완벽히 해제하여 시스템 전체를 가용성을 확보했습니다.
5.5. 결과: 가용성과 성능의 Sweet Spot을 찾아서
비동기 전환 후, 시스템은 더 이상 외부 포털의 응답 속도에 가용성을 잡히지 않게 되었습니다. 단순히 비동기로 변경하는 것에 끝나는 것이 아니라, 리소스 가용량에 따른 점진적 튜닝을 통해 최적의 저점을 도출했습니다.
CASE A: 안전성 우선 (Core 3 / MAX 7 / Queue 50)
우선 최소한의 자원(3개 스레드)만 사용하여 메인 서비스의 가용성을 100% 보장했습니다.
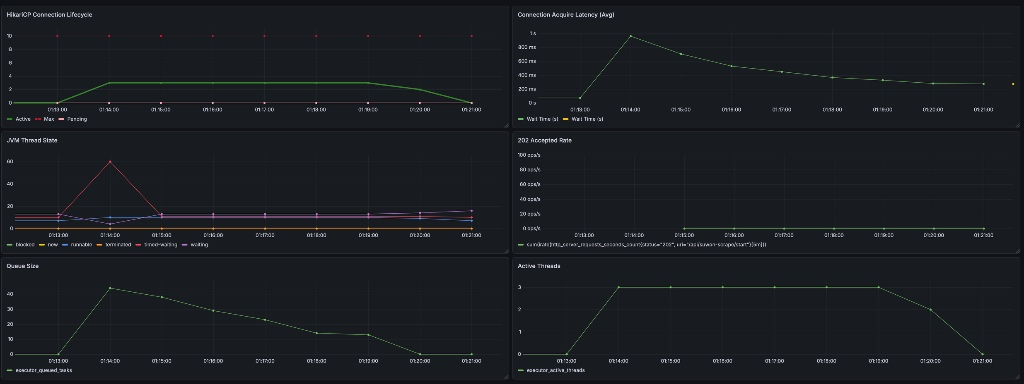
계측 결과:
-
HikariCP Connection Lifecycle: 활성 커넥션(Active, 초록색)이 정확히 3개에서 수평을 유지합니다. 이는 50개의 요청이 몰려와도 워커가 설정된 Core 사이즈(3)만큼만 자원을 점유하며, 나머지 7개의 커넥션을 일반 유저를 위해 완벽히 보존하고 있음을 증명합니다.
-
Connection Acquire Latency: 요청 초기 burst 구간에서 약 1s의 피크를 기록한 뒤 빠르게 안정화됩니다. 기존의 5s 타임아웃 장애와 비교하면, 커넥션 획득 대기 시간이 80% 이상 개선되었습니다.
-
Queue Size & Active Threads: Active Threads가 3개로 고정된 상태에서, 처리하지 못한 요청들이 Queue(대기열)에 최대 47개까지 쌓였다가 순차적으로 해소되는 자원 격리의 모습을 보여줍니다.
-
JVM Thread State: Timed-waiting 상태(빨간색)가 약 60개까지 튀어 오르는데, 이는 비동기 스레드들이 외부 I/O(Fetch) 단계에서 안전하게 대기하고 있음을 나타냅니다.
Job 소요 시간을 분석하기 위해 최초 요청과 최종 요청을 비교했습니다.
| 측정 항목 | Case A 결과 |
|---|---|
| 최초 요청 ~ 최종 완료 | 2026-02-06 16:12:49 ~ 16:19:43 |
| 총 소요 시간 | 413.8초 (약 6분 54초) |
| 초당 처리량 (TPS) | 약 0.12 jobs/s |
Case A의 경우에는 총 처리 시간이 약 414초가 걸렸습니다.
이번에는 보수적으로 잡은 Core를 7로 설정한 뒤 동일한 조건에서 테스트하겠습니다.
Case B: 처리량 최적화 모드 (Core 7 / Max 7 / Queue 50)
시스템 가용 자원 내에서 워커 스레드를 풀가동하여 사용자 대기 시간을 최소화했습니다.
k6 부하 테스트 실행 로그 (Case B)
# 50 VUs, 1 iterations per VU 발사 결과
checks_total.......: 100 17.158103/s
checks_succeeded...: 50.00% 50 out of 100
✓ Success (202) : 100% — ✓ 50 / ✗ 0 # 전원 성공
http_req_failed....: 0.00% 0 out of 50 # 에러율 0%
http_req_duration..: avg=4.26s p(95)=5.52s # 제어된 지연 발생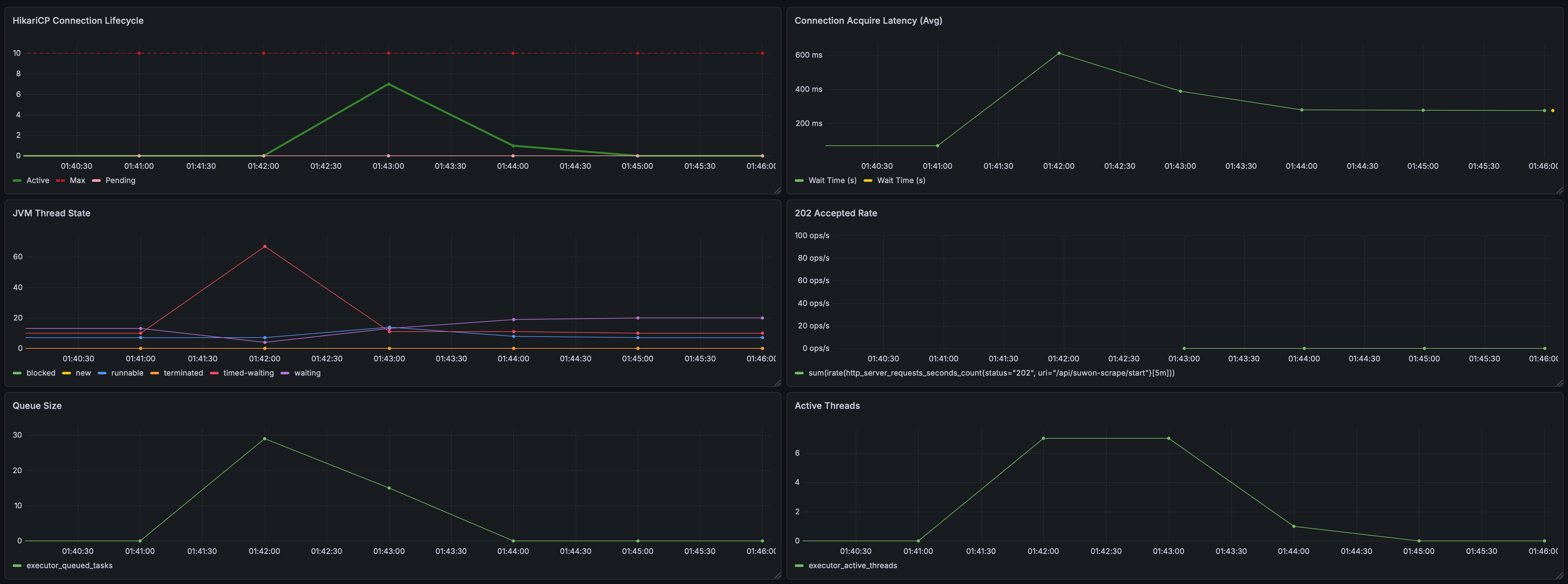
계측 결과:
-
HikariCP Connection Lifecycle: 활성 커넥션이 최대 7개까지 사용됩니다. Case A보다 더 많은 자원을 투입하여 병렬 처리량을 끌어올렸음에도 불구하고, 대기열(Pending)은 발생하지 않아 시스템의 안정성이 유지되고 있습니다.
-
Connection Acquire Latency: 피크 수치가 약 500ms 수준으로 Case A 대비 절반으로 줄어들었습니다. 더 많은 스레드가 작업을 빠르게 소화하면서 전체적인 커넥션 순환 속도가 향상된 결과입니다.
-
Queue Size & Active Threads: 시작과 동시에 Active Threads가 7개를 기록합니다. 덕분에 큐에 쌓이는 최대 작업 수가 30개 수준으로 낮아졌으며, 대기열이 해소되는 기울기가 Case A보다 훨씬 가파른 것을 확인할 수 있습니다.
| 측정 항목 | Case B 결과 | 개선율 |
|---|---|---|
| 최초 요청 ~ 최종 완료 | 2026-02-06 16:40:32 ~ 16:43:44 | - |
| 총 소요 시간 | 192.5초 (약 3분 12초) | 약 53.5% 단축 |
| 초당 처리량 (TPS) | 약 0.26 jobs/s | 약 216% 향상 |
Case B의 경우 Case A 대비 총 소요 시간은 약 53.5%가 단축되었고, 초당 처리량은 약 2배가량 상승한 것을 확인할 수 있었습니다.
6. 마치며: 가용성과 정합성 사이의 균형
이번 리팩터링은 단순히 코드를 비동기로 바꾼 것을 넘어, 유한한 자원을 어떻게 효율적으로 배분할 것인가에 대해 고민한 과정이었습니다.
모든 로직을 하나의 트랜잭션으로 묶어 '데이터 원자성'을 지키려 했던 고집이 오히려 시스템 전체를 마비시키는 독이 됨을 배웠습니다. 결과적 일관성(Eventual Consistency)을 수용하고 이를 상태 머신으로 보완했을 때, 비로소 시스템은 외부 장애에도 무너지지 않는 견고함을 가질 수 있었습니다.
corePoolSize나 QueueCapacity 같은 설정값들은 감이 아닌 지표로 결정되어야 합니다. Grafana 대시보드에서 스레드와 큐가 실시간으로 움직이는 것을 관측하며 최적의 Sweet Spot을 찾아낸 경험은, 측정할 수 없다면 개선할 수 없다는 원칙을 체감하게 해주었습니다.
비동기 환경에서 예외는 발생하지 않아야 할 것이 아니라 당연히 발생할 수 있는 상황으로 간주해야 합니다. 상태 테이블을 통해 작업의 단계를 기록하고, 멱등성(Idempotency)이 보장된 재시도 로직을 구축함으로써 안전하게 실패하고 투명하게 복구되는 구조를 완성할 수 있었습니다.
