CNN
CNN - 합성곱 신경망 (Convolutional Neural Network)
- 주로 컴퓨터 비전(이미지, 동영상관련 처리)에서 사용되는 딥러닝 모델로 convolution레이어를 이용해 데이터의 특징을 추출하는 전처리 작업을 포함시킨 신경망(Neural Network) 모델이다.
- 연상방식 ⇒ 특징추출하는 방식을 선형회귀 방식을 하지 않고 convolution연산을 해주는Convolution layer 사용
- Convolution layer에서 나온 결과물을 feature maps이라고 한다.
- CNN은 이미지, 영상 데이터 처리에 사용
CNN 응용되는 다양한 Computer Vision 영역
- 이미지,영상 데이터를 이해하고 해석하는 것을 Computer Vision이라고 한다.
-
Computer Vision
- 이미지 처리, 패턴 인식, 객체 감지, 분류, 추적, 세그멘테이션 등과 같은 작업을 수행하는 알고리즘과 기술을 개발하고 적용하는 것이 목표
- 인공지능, 로봇, 자율주행, 의료 진단, 보안 시스템 등 다양한 분야에서 활용
- 세그멘테이션(Segmentation): 입력 이미지를 서로 다른 영역이나 객체로 구분하여 픽셀 단위로 분류하는 과정을 거친다. 이를 통해 이미지나 영상에서 특정 객체나 영역을 정확하게 식별하고 분리할 수 있다.
-
이미지 분류
- 입력된 이미지가 어떤 라벨에 대응되는지 이미지에 대한 분류를 처리
- 쉽게 말해 해당 이미지가 어떤 이미지를 말하는것인지 분류해주는 것 ex) 개, 고양이
-
물체 검출
- 이미지 안의 물체들의 위치를 찾고 어떤 물체인지 분류하는 작업을 한다.
- 물체 검출 방법 2가지
- Localization : 이미지안에서 하나의 Object의 위치와 class를 분류
- Dection: 이미지 안의 여러개의 Object의 위치와 Class를 분류

- 세분화(**Image Segmentation**)
- 이미지를 입력받아 픽셀별로 분류하는 것이다.
- 세분화 방법 2가지
- 의미기반세분화(Semantic segmentation):
- 클래스 단위로 구분 → 같은 클래스는 같은 것으로 구분
- 인스턴스 기반 세분화(Instance segmantation);
- 객체 단위로 구분 → 동일한 클래스라도 다른 객체일 경우 다른 것으로 구분
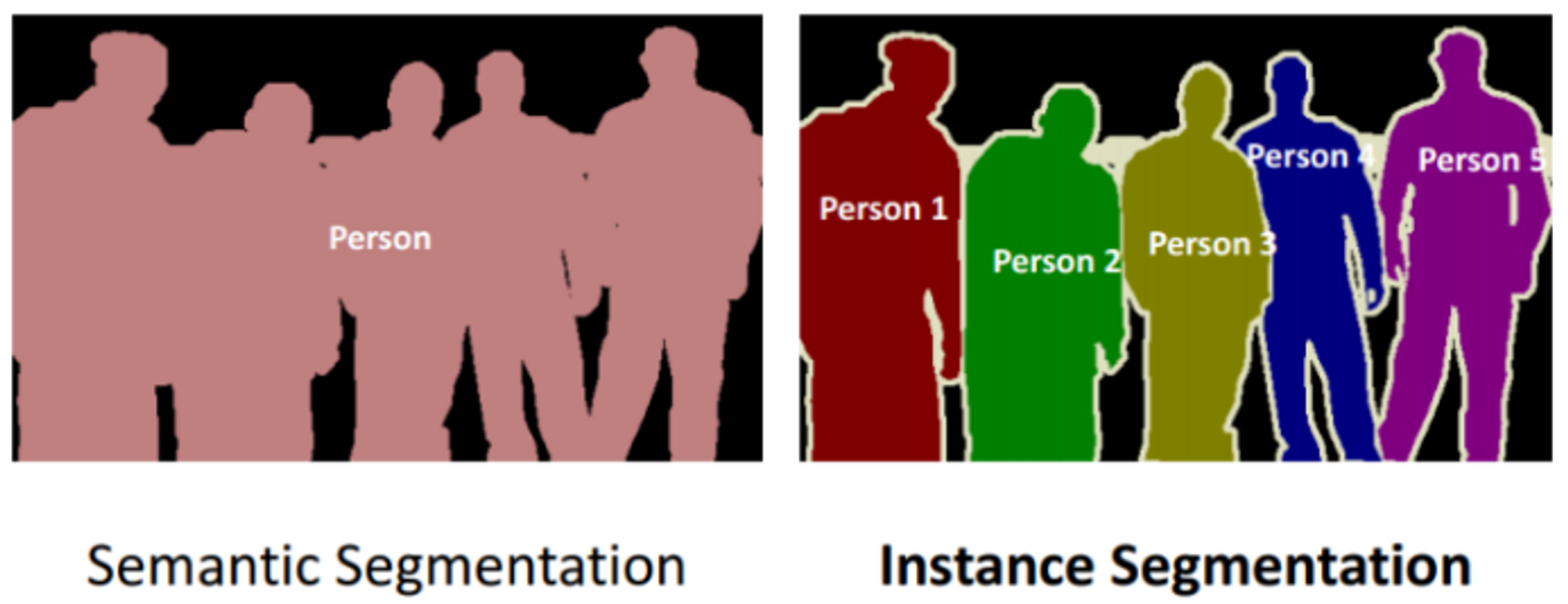
<정리>
Classification, Localization, Object Detection, Segmentation 가장 대표적인 컴퓨터 비전이다.
- 세분화(**Image Segmentation**)
-
Image Captioning
- 이미지에 대한 설명문을 자동으로 생성
- input은 이미지인데 출력은 text이다.
-
Super Resolution
- 저해상도의 이미지를 고해상도의 이미지로 변환
-
Neural Style Transfer
-
입력이미지 + 스타일 이미지 = 새로운 이미지를 생성 —> 이미지 스타일 변경하는 것이다.
ex) 사진을 피카소 그림스타일로 변경 등..
-
-
Text Dectection & OCR
- Text Dectection: 이미지안에서 텍스트를 찾는것.
- OCR: 글자들이 어떤 글자인지 실제 글자를 찾는것,
-
특징점 검출(Keypoint Detection)
- 인간의 특징점(**Keypoint**)들을 추정한다.
- 특징점 검출 방법3가지
- Human Pose estimation, Face keypoint detection, Hand detection
but
Computer Vision은 사람과 컴퓨터가 보는 이미지의 차이가 있다.
컴퓨터가 보는 이미지는 0~255사이의 숫자로 이루어져 있다.(행렬)
- Computer Vision이 어려운 이유
- 배경과 대상이 비슷해서 구별이 안되는 경우
- 같은 종류의 대상도 형태가 너무 많다.
- 대상이 가려져 있는 경우
- 같은 class에 다양한 형태가 있다.
이렇게 다양한 대상을 숫자로 이루어진 행렬로 패턴을 찾아내야 하기 때문에 이미지,영상을 다루는 Computer Vision이 어렵다.
- 기존의 전통적인 이미지 처리 방식과 딥러닝의 차이
- Handcrafted Feature (전통적인 영상처리 방식)
- 분류하려고 하는 이미지의 특징들을 사람이 직접 찾아서 만든다. (Feature Exctraction)
- 미처 발견하지 못한 특징을 가진 이미지는 분류하지 못해 성능이 떨어진다.
- 사람이 특징을 찾는 것이므로 많은 Feature Ectraction이 어렵다.
- End to End learning (딥러닝)
- 이미지의 특징 추출부터 추론까지 자동으로 학습시킨다.
- Handcrafted Feature (전통적인 영상처리 방식)
이때 딥러닝모델을 사용 시 이미지부분은 특징추출하는 부분에서는 선형회귀방식이 아닌 Convolution을 사용하는 것이다.
CNN(Convolution Neural Network)
- 구성
- 이미지로 부터 부분적 특성을 추출하는 Feature Extracion 부분과 분류를 위한 추론 부분으로 나눈다.
- Feature Extraction 부분에 이미지 특징 추출에 성능이 좋은 Convolution Layer를 사용
- • Feature Exctraction : Convolution Layer 사용
- • 추론 : Dense Layer (Fully connected layer) 등을 사용
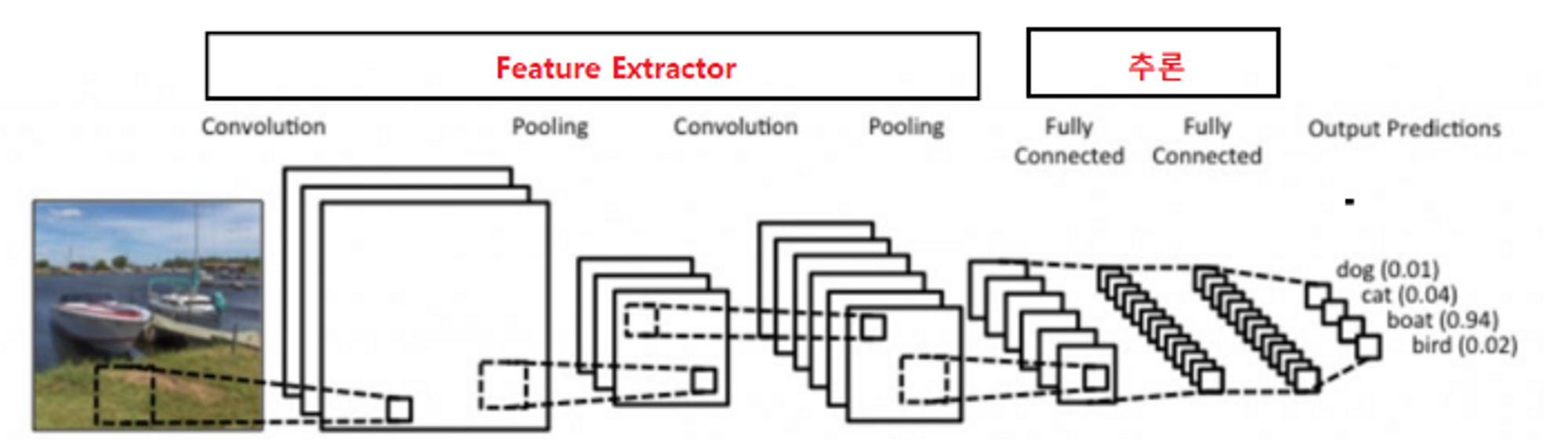
- 영상처리에서 Feature Exctractor를 Dense Layer사용했을 때 문제점
-
Dense layer(Fully connected layer)는 이미지의 공간적(spatial) 구조를 학습하는 것이 어렵다.
-
dnase layer은 일차원으로 변경해야한다. → 같은 형태가 전체 이미지에서 위치가 바뀌었을때 다른 값으로 인식하게 된다.
-
이미지를 input으로 사용하면 weight의 양이 너무 크다. ex) 28X28행렬 ⇒ 784개의 픽셀 → 유닛 하나당 784개 weight 필요
→ weight가 많으면 학습 대상이 많은 것이므로 학습하기가 그만큼 어려워진다.
-
500 * 500 픽셀 이미지의 경우
-
흑백은 Unit(노드) 하나당 500 * 500 = 250000 개 학습 파라미터(가중치-weight) → 파라미터가 많으면 최적화할 대상 또한 증가한다.
-
그래서 이러한 문제점을 해결하기 위해 등장한게 Convolution(합성곱) 연산이다.
Convolution(합성곱) 연산이란
- Convolution Layer는 Convolution(합성곱) 연산을 하는 것들로 이루어져 있다.
- 2*3+8x5+3X1+7X2 (내적)
- 합성곱 연산은 input data와 weight간의 가중합을 구할 때 한번에 구하지 않고 작은 크기의 Filter를 이동시키면서 가중합을 구한다.
- 연산하는 방법 2가지
1D Convolution 연산d
→ 연산할 배열이 1차원인 경우
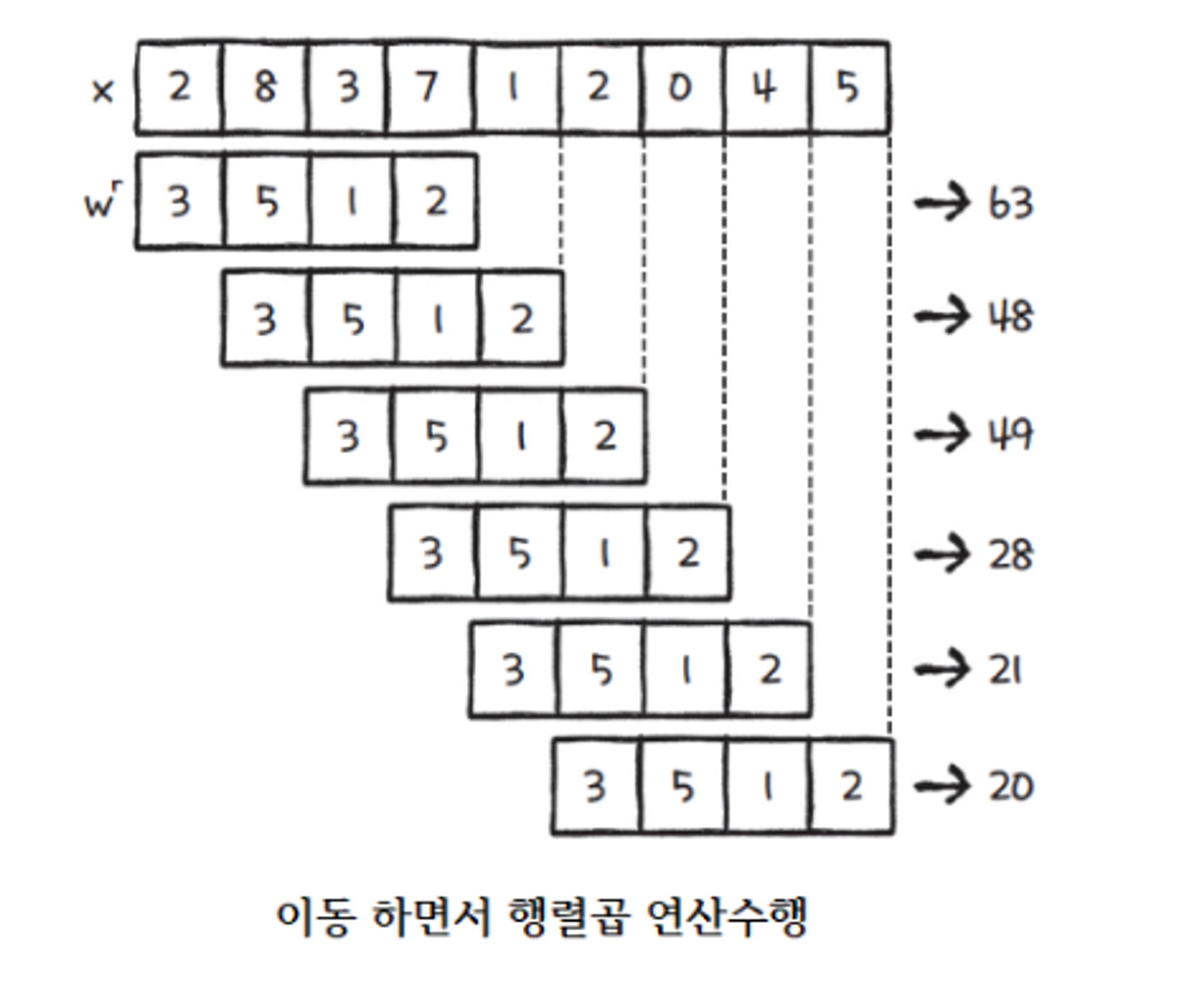
⇒ 63은 4개의 영역에 대해서 특성을 찾은 것이고, 48은 또다른 4개의 특성을 찾은 것이다. → 즉, 63만큼의 특성이 있는 것이고 21만큼의 특성이 있다는 것이다. → 3,5,1,2만큼 어디에서 특성이 많고 적은지 알 수 있다.
쉽게말해 한번에 전체의 가중치를 구해서 진행하는 연산방식이 아닌 특성을 부분적으로 뽑아내어 연산하는 방식을 사용하는 것이다.
**2D Convolution 연산**
→ 연산할 배열이 2차원인 경우
- 이미지안에서 특성을 찾는 것이다.
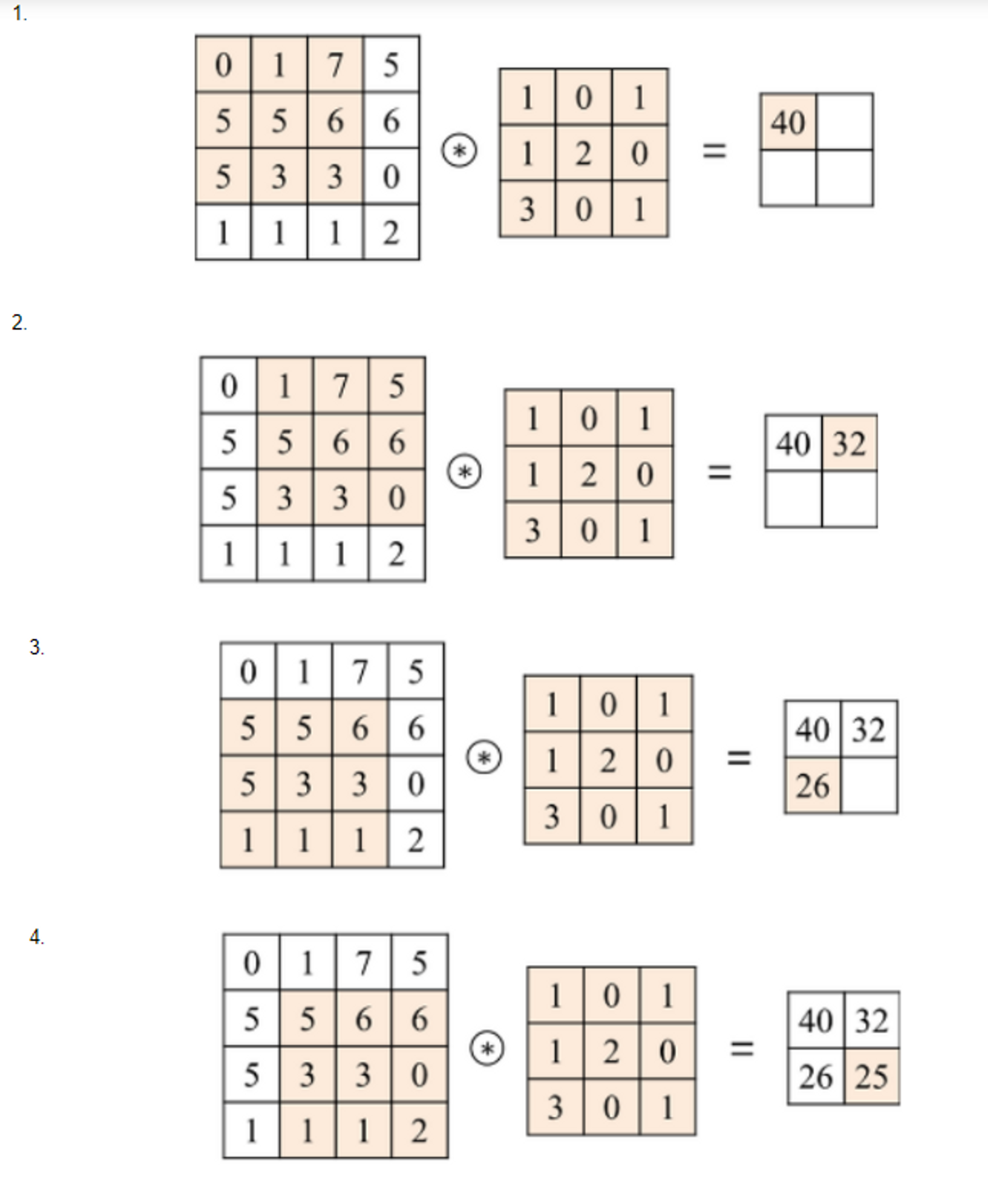
⇒ 결과 2X2배열이 생성된다.
⇒ 그중 특성이 가장많은 것은 40이다.
- Feature(특성) 추출과 합성곱
위의 그림에서
해당 부분들을 Filer(Kernel)이라고 한다.
- Filter(Kernel)
- 이미지와 합성곱 연산을 통해 Feature(패턴)들을 추출한다.
필터와 부분 이미지의 합성곱 결과가 값이 나온다는 것은 그 부분 이미지에 필터가 표현하는 이미지특성이 존재한다는 것이다.
지금까지 CNN을 학습하기 위해 기존방식의 합성곱방식에 대하여 알아보았다.
다시말하면
기존 Hand craft 방식은 이미지의 특성을 잘 찾을 수 있는 Filter를 사람이 만들었다.
하지만
CNN은 이 Filter를 데이터 학습을 통해 만든다.
내가 데이터 줄게 너가 알아서 학습하면서 Filter를 랜덤으로 변경해가면서 특성을 알맞게 찾아! 하는것.
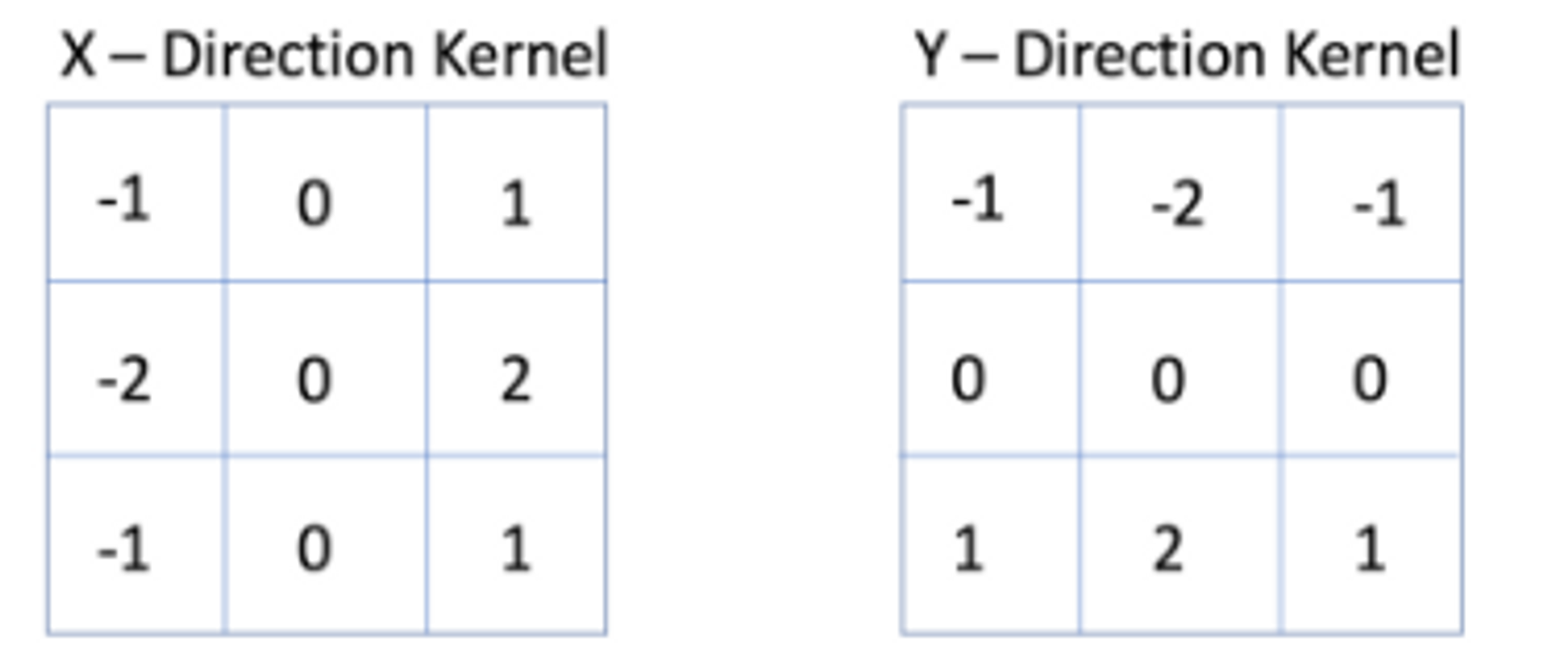
- Hand Craft 방식의 Filter

1) 영상으로 부터 윤곽선 특성(Edge Feature)을 찾는다.
- X-Direction Kernel: 이미지에서 수평 윤곽선(edge)를 찾는다.
- Y-Direction Kernel: 이미지에서 수직 윤곽선(edge)를 찾는다.
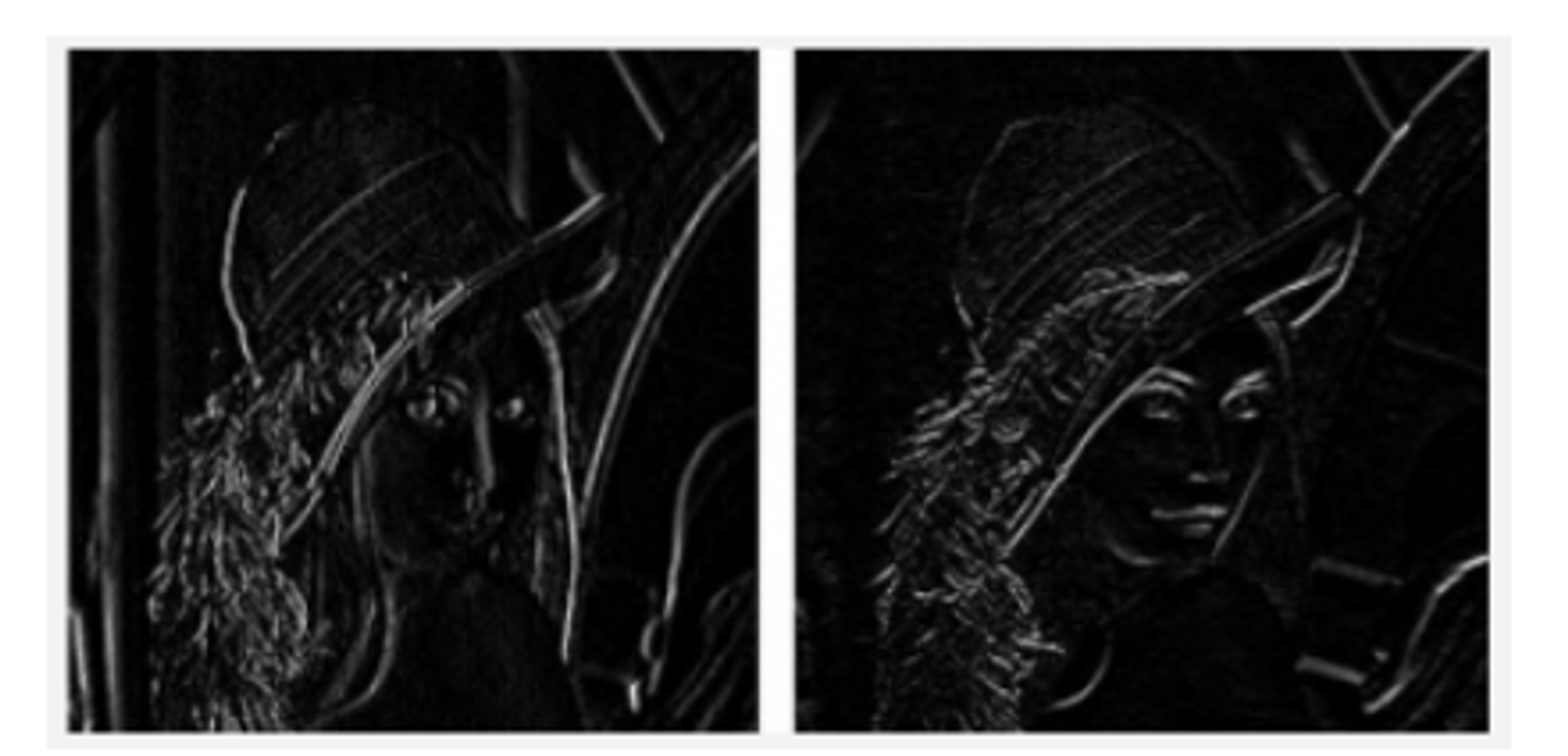
⇒ 윤곽선만 잘 찾아도 특성을 추출해서 사용할 수 있는데 이것이 위의 윤곽선 특성(Edge Feature)을 찾는 것이였다. 이것을 이제 학습을 통해 찾는 다는 것이다. (Filter찾는 방법)
Deep Learning(CNN)에서의 Filter
- Convolution Layer는 특성을 추출하는 Filter(Kernel)들로 구성되어 있다.
- **Convolution Layer도 여러층을 쌓는다.**
- 입력층(Bottom)과 가까운 Convolution 레이어일 수록 input image의 작은 영역에서의 특징들을 찾는다. → 이미지의 엣지나 경계선등 일반화가 쉬운 이미지의 기초적인 표현을 찾는다.
- 출력층(Top)과 가까운 Convolution 레이어일 수록 input image의 넒은(큰) 영역에서의 특징들을 찾는다. → 일반화가 곤란한 구체적인 이미지의 표현을 찾는다.
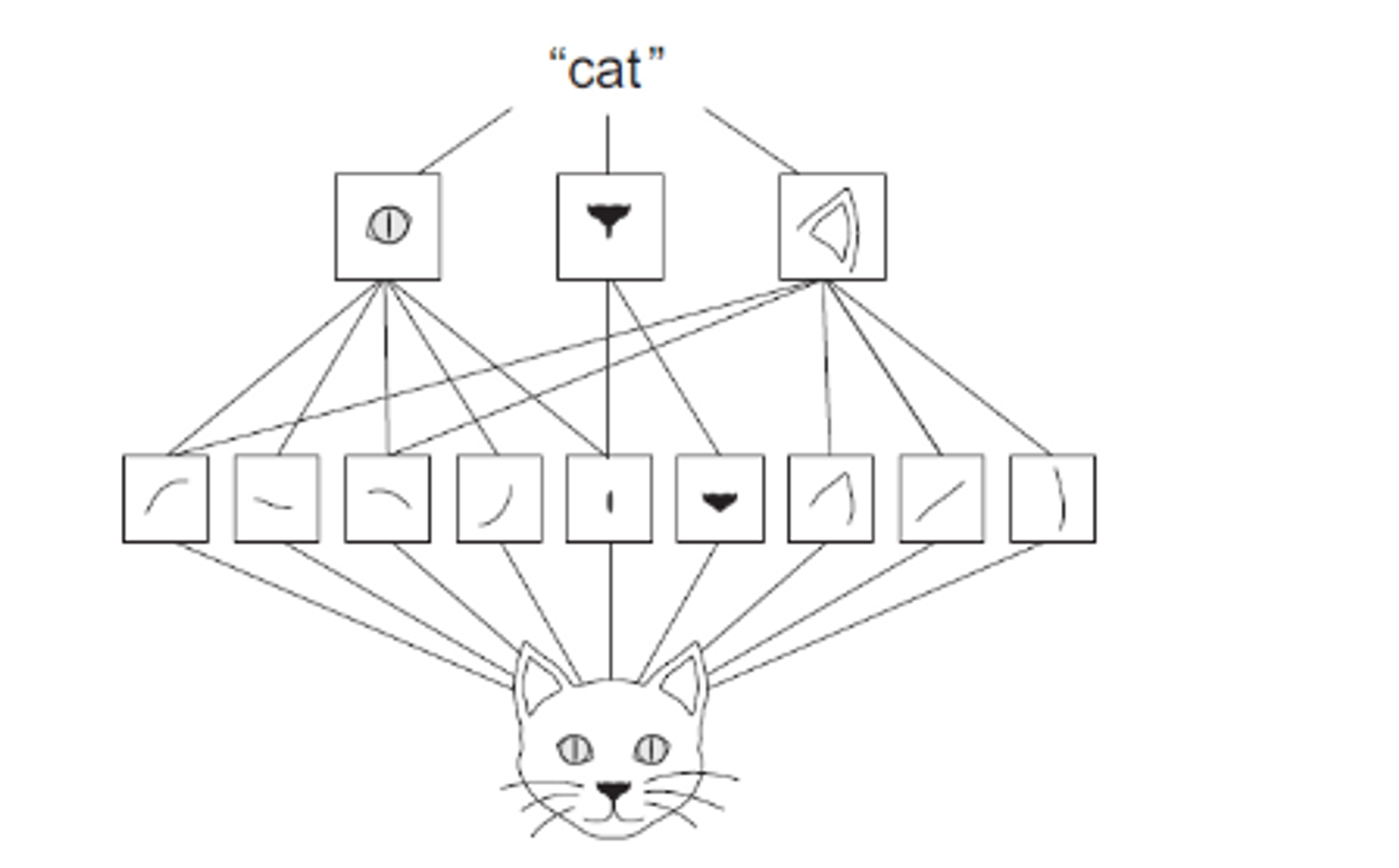
그럼 Convolutional Layer 생성 및 작동방식에 대하여 알아보자.
Convolutional Layer 생성 및 작동방식
- **tensorflow.keras.layers.Conv1D 사용 → 1차원 배열**
- **tensorflow.keras.layers.Conv2D 사용 → 2차원 배열**
- Convolutional Layer에서 Convolutional연산을 하는 것들을 filter(kernel)이라고한다. → Convolutional Layer안에 filter(kernel)이 여러개 있다.
- Convolutional Layer Hyper parameter
- filters
- 레이어를 구성하는 filter(kernel)의 개수. Feature map output의 깊이가 된다.
- 원본input size와는 상관이 filter의 크기를 설정한다. (영향받지 않음)
- kernel_size
- Filter의 크기(height, width) → 보통 홀수 크기로 잡는다.
- 필터의 채널은 Layer의 input의 채널과 동일하게 자동으로 설정된다.
- padding
- input tensor의 외곽에 특정 값(보통 0)들 둘러 싼다.
- input size와 Convolutiona연산 후의 outputsize를 동일하게 해주기 위해 inputsize를 키워주는것.
- stride
- 연산시 Filter의 이동 크기
- filters
- Feature Map
- Convolutional Layer 연산 후의 결과물이다.
- Feature map의 개수는 Filter당 한개가 생성된다. → Filter 가 10개이면 Feature map더 10개
- Feature map의 크기(shape)는 Filter의 크기(shape), Stride, Padding 설정에 따라 달라진다.
좀 더 자세하게 보자.
- Input shape
- (데이터개수, height, width, channel)
- Height: 세로 길이(열) | Width: 가로 길이(행) | Channel: 하나의 data를 구성하는 행렬의 개수 (이미지에서의 배열은 (열,행)순서이다.)
- Channel
- 하나의 데이터가 몇 개의 값으로 구성되어 있는지 나타낸다.
- 이미지가 흑백일 경우: Chennel이 1개 있다.
- 이미지가 컬러일 경우: RGB의 각 이미지로 구성되어 3개의 행렬로 구성 ex) (28,28,3)→ 28열28행인 Chennel이 3개 있다.
- Feature map : 특성개수
- 특성개수는 Chennel이라고 한다. ex_ 특성개수는 5개가 된다.
- Channel
- Height: 세로 길이(열) | Width: 가로 길이(행) | Channel: 하나의 data를 구성하는 행렬의 개수 (이미지에서의 배열은 (열,행)순서이다.)
Convolution연산을 하는데 Chennel들과 filter의 연산값을 합친다. 이것이Feature maps → 다음 Convolutional Layer의 input으로(channel) 들어간다.
전체적이 로직을 그림으로 살펴보자
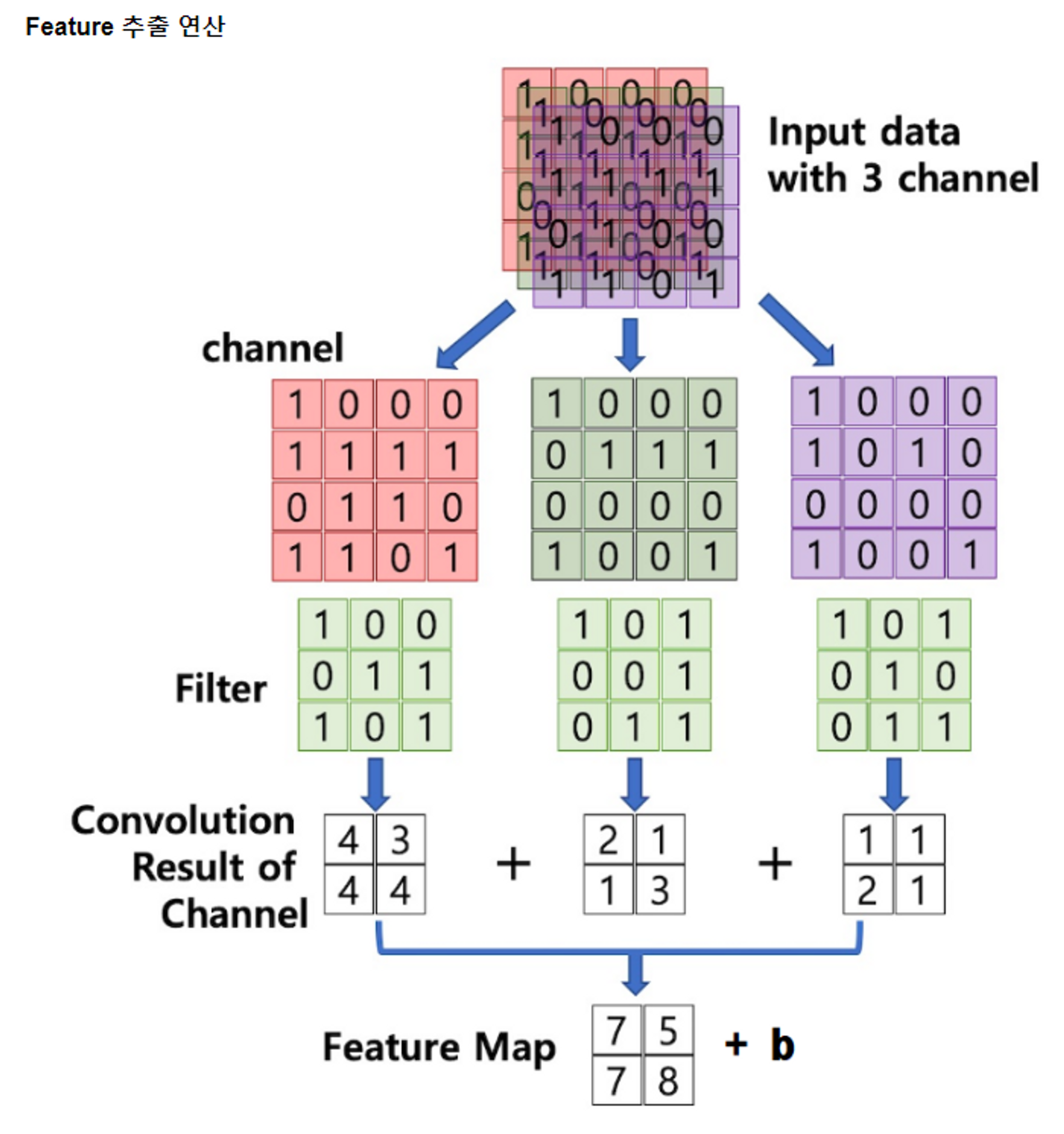
지금까지는 feature map의 계산방법이었다.
이제는 height와 width의 크기를 맞춰주는 padding에 대하여 알아보자.
Padding
- 이미지 가장자리의 픽셀은 convolution 계산에 상대적으로 적게 반영된다. → 그럼 외각에 픽셀을 추가해서 안쪽의 픽셀로 만들어 연산되는 수를 맞춰주자.
- 이미지 가장자리를 0으로 둘러싸서 가장자리 픽셀에 대한 반영 횟수를 늘림 → • 0으로 둘러싸는 것을 ZeroPadding이라고 한다.
- Padding을 이용해 Feature map의 size를 조절할 수 있다.
- Conv2D의 padding 속성 2가지
- valid padding
- Padding을 적용하지 않고 Output의 크기가 줄어든다.
- 만약 이동하려는 나머지 픽셀이 이동크기가 안된다면 버린다.
- same padding
- Input과 output의 이미지 크기가 동일하게 되도록 padding 수를 결정
- 만약 이동하려는 나머지 픽셀이 이동크기가 안된다면 버리지 않는다.
- valid padding
Strides
- Filter(Kernel)가 한번 Convolution 연산을 수행한 후 옆 혹은 아래로 얼마나 이동할 것인가를 설정
- (가로이동크기, 세로이동크기) 를 지정 만약 stride=3일경우 한번 Convolution 연산을 수행한 후 3칸씩 옆으로 이동 → eature map의 너비와 높이가 3배수로 다운샘플링 되었음을 의미
- convolution layer에서는 일반적으로 1을 지정
여기까지가 convolution layer이다.
이제 convolution layer후 붙이는 것이 있다. 이것이 Pooling Layer이다.
Max Pooling Layer
- Pooling Layer
- 영역에 대푯값을 추출하는 것이다.
- Pooling Layer의 목적은 이미지의 사이즈를 줄이는 것이다.(downsampling효과)
- 연산량을 줄이기 위함이다.
convolution layer의 filter의 size를 늘리면 그만큼 widght가 늘어나고 최적화해야할 widght가 늘어난 것이므로 성능이 떨어지고 오래걸리게 된다.
그래서
Max Pooling Layer
- 영역의 최댓값을 추출하는 것이다.
- 찾은 특성 중 일부의 정보손실이 발생하게 된다. → 하지만 이미지영역쪽으로 보면 큰 손실은 아니다.
- Average보다는 MAX가 더 대푯값을 잘 뽑는다.
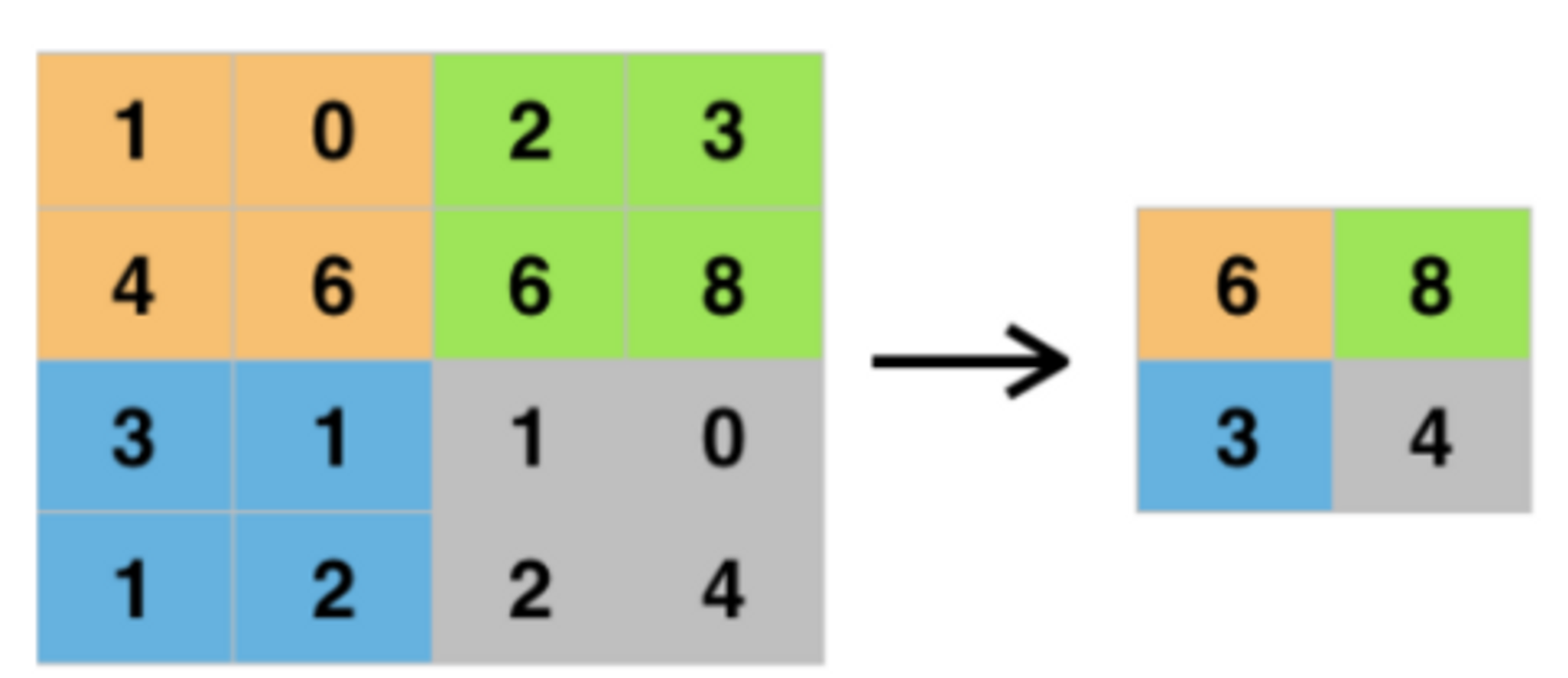
size를 줄이는 것은 더 큰 영역을 보기위해서이다. channel과 filter을 늘리는 것은 많은 특성보려고 하는 것이다.
추론기
- 해결하려는 문제에 맞춰 Layer를 추가한다.
- Dense layer를 많이 사용했으나 지금은 Convolution layer를 사용하기도 한다.
- Feature Extractor와 추론 layer를 모두 Convolution Layer로 구성한 Network를 Fully Convolution Network(FCN)이라고 한다. → 이때 1차원으로 변경해야한다.(Flatten())

정말 유익한 글이었습니다.