tf.data Moduel
- tenserflow에서는 딥러밍 모델에 적용하기 전에 파이프라인을 만들 수 있도록 tf.data모듈을 제공한다.
- 모델 학습/평가를 위한 데이터셋을 제공(feeding)하기 위한 모듈이다.
- raw dataset 에서 입력을 위한 전처리, 배치 크키, shuffling등을 한번에 처리할 수 있게 한다.
- tf.data.Dataset에서는 여러가지 클래스들을 제공한다.
tf.data 구성요소
- Dataset 생성
- raw dataset을 지정 (Loading)후 from_tensor_slices()등을 사용해 데이터셋을 만든다.
- 제공 데이터 전처리
-
map(함수): Dataset이 제공하는 원소를 처리해서 변환된 원소를 제공하도록 한다.
- 함수: 원소를 어떻게 변환할 지 정의한 함수를 매개변수로 전달
-
filter(함수): Dataset이 제공하는 원소중 특정 조건을 만족하는(True)인 원소들만 제공한다.
- 함수: 원소가 특정조건을 만족하는지 여부를 확인하는 로직을 정의한 함수를 매개변수로 전달
- 데이터 제공 설정 관련
- batch(size): 학습/평가시 한번에 제공할 데이터의 양(batch size) 지정
- drop_remainder: True인 경우 남은 데이터의 수가 batch size보다 작으면 수시 False인 경우 남은 데이터까지 모두 취급한다.
- drop되는 데이터는 다르 에폭을 반복 시 사용한다.
- shuffle(buffer 크기): dataset의 원소들의 순서를 섞는다.
- 섞는 공간의 크기로 데이터보다 크거나 같으면 완전셔플, 데이터보다 공간의 크기가 작으면 일부만 가져와서 완전셔플이 안된다.
- repeat(count): 전체 데이터를 한번 다 제공한 뒤 다시 데이터를 제공한다.(반복)
- count: 몇번 제공할지 반복 횟수
<Dataset 예제>
import tensorflow as tf
import numpy as np
raw_data1 = np.arange(10)
dataset = tf.data.Dataset.from_tensor_slices(raw_data1)
print(type(dataset))
for data in dataset:
print(data)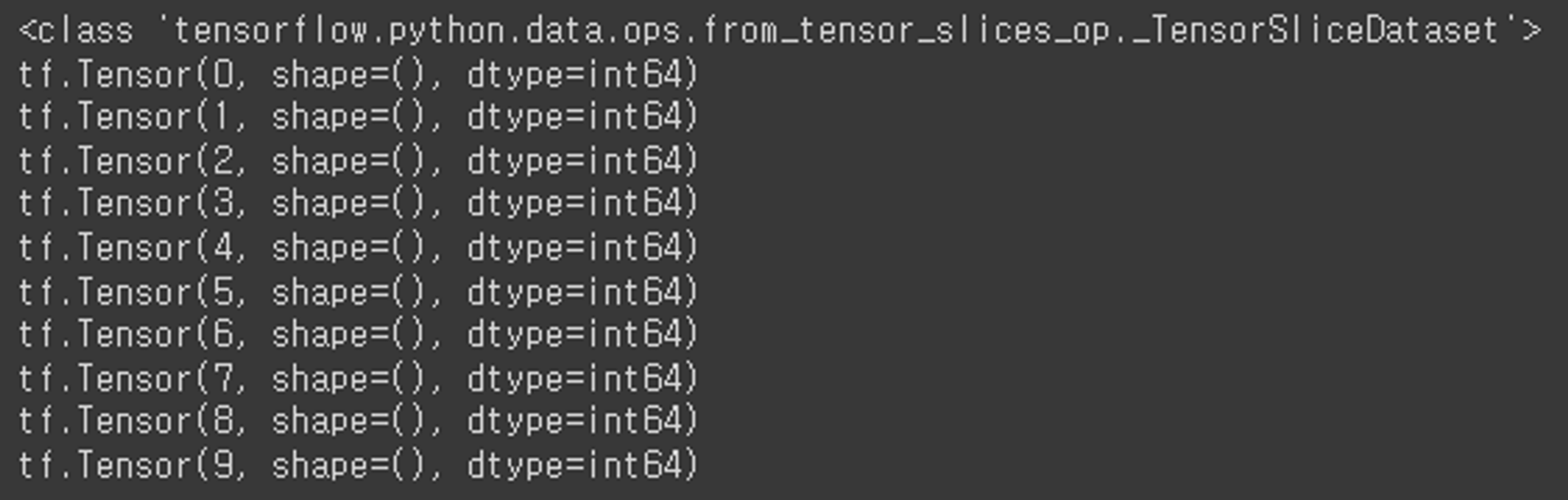
# take(개수): 지정한 개수만큼의 데이터만 제공
for data in dataset.take(5):
print(data)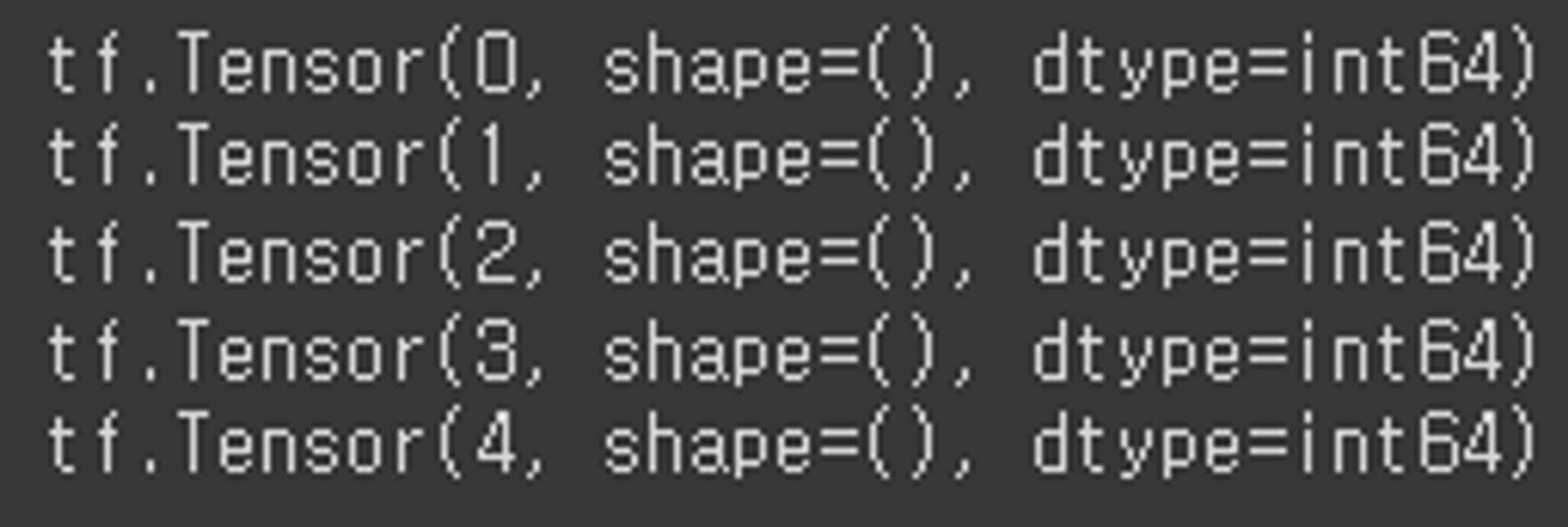
<x, y 묶어서 제공-두개 이상의 데이터 셋을 Tuple로 묶는 예시>
import tensorflow as tf
import numpy as np
raw_data1 = np.arange(10)
raw_data2 = np.arange(10, 20)
print(raw_data1, len(raw_data1)) # X (input)
print(raw_data2, len(raw_data2)) # y (output)
dataset2 = tf.data.Dataset.from_tensor_slices((raw_data1, raw_data2))
for data in dataset2.take(4):
print(data)
for x, y in dataset2:
print(x, y, sep=' ====== ')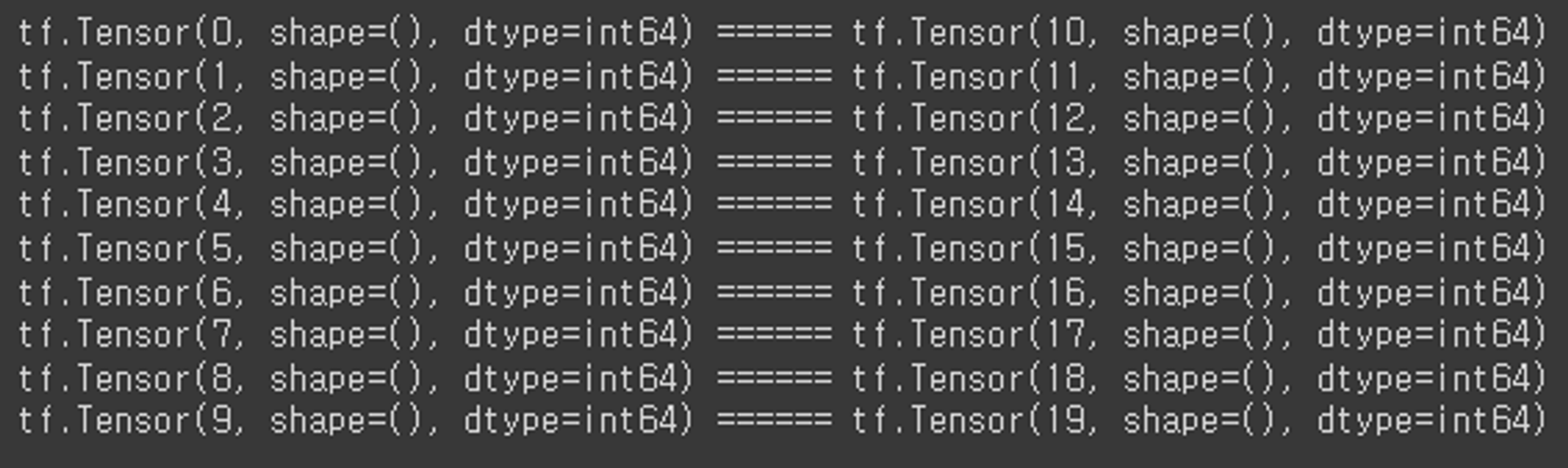
- shuffle
import tensorflow as tf
import numpy as np
raw_data1 = np.arange(10)
dataset = tf.data.Dataset.from_tensor_slices(raw_data1)
dataset3 = dataset.shuffle(10)
print(type(dataset3))
for data in dataset3:
print(data)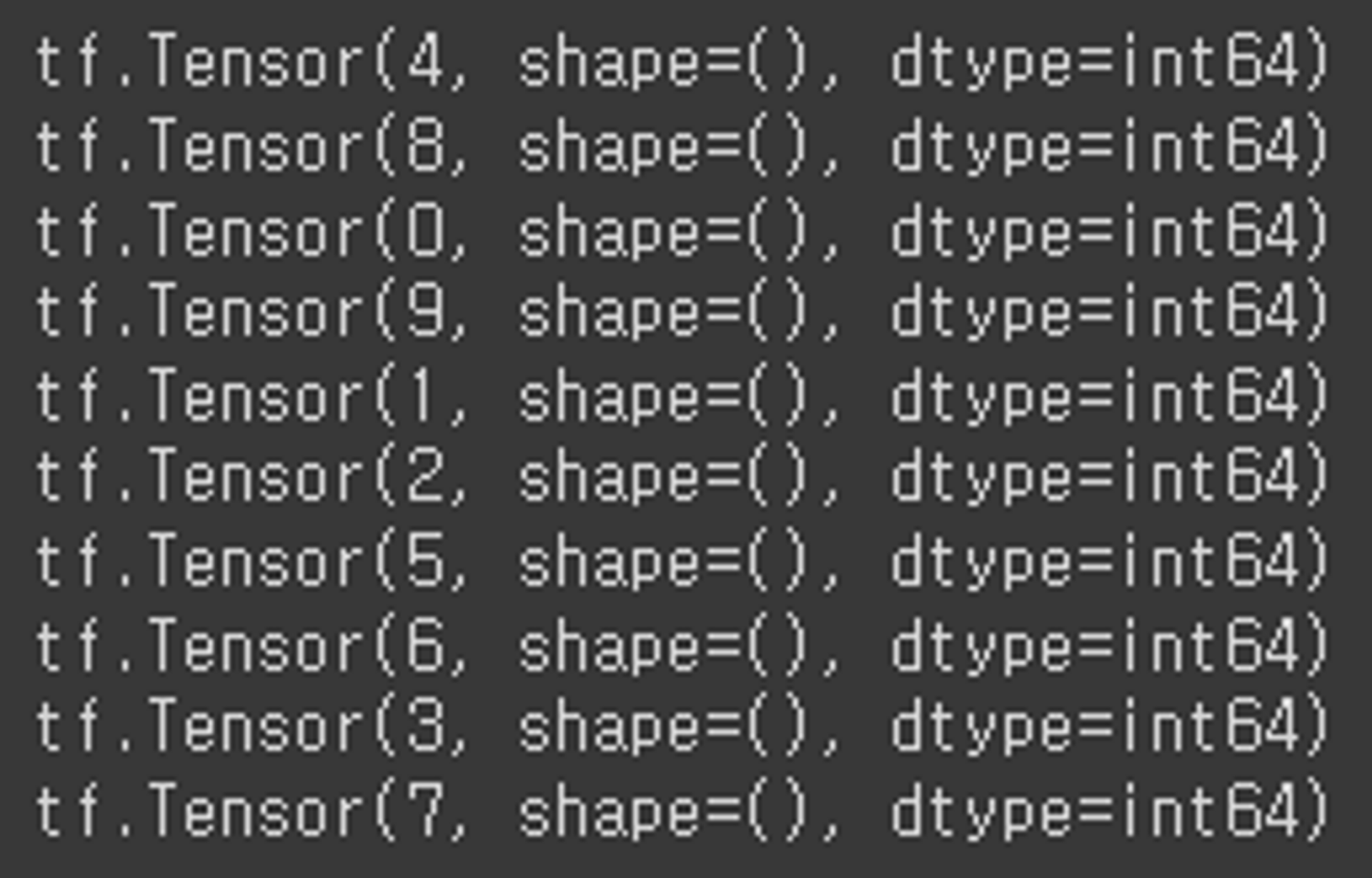
- batch
import tensorflow as tf
import numpy as np
raw_data1 = np.arange(10)
dataset = tf.data.Dataset.from_tensor_slices(raw_data1)
dataset4 = dataset.batch(5)
print(type(dataset4))
for data in dataset4:
print(data)
dataset5 = dataset.batch(3, drop_remainder=True)
for data in dataset5:
print(data)
- repeat
dataset6 = dataset.repeat(2)
print(type(dataset6))
for data in dataset6:
print(data)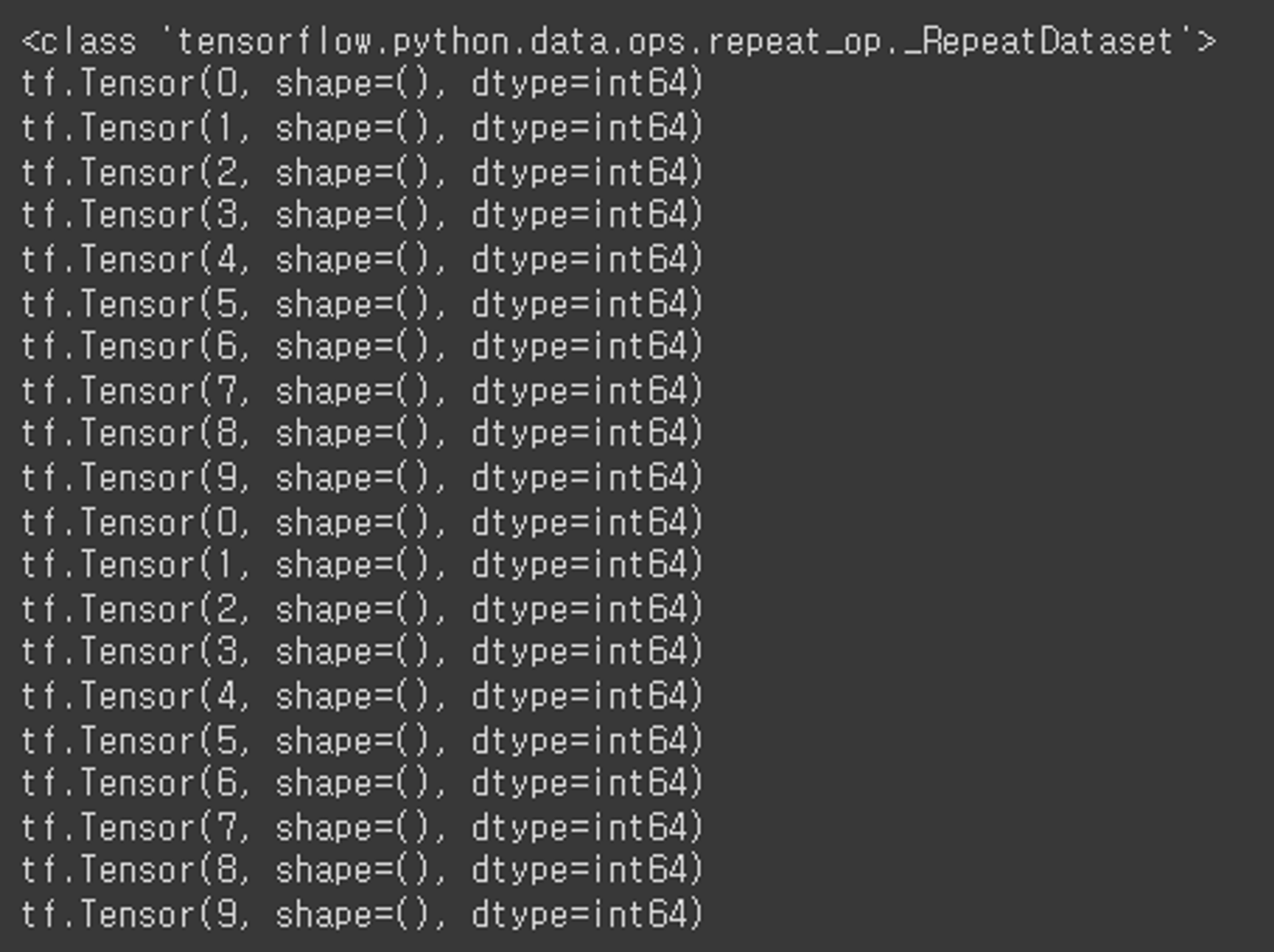
<1~3번을 합친예제>
dataset7 = tf.data.Dataset.from_tensor_slices(raw_data1).shuffle(10).batch(3).repeat(3)
for data in dataset7:
print(data)
- map
import tensorflow as tf
import numpy as np
raw_data1 = np.arange(10)
raw_data2 = np.arange(10, 20)
dataset = tf.data.Dataset.from_tensor_slices(raw_data1)
dataset8 = dataset.map(lambda x: x * 2)
print(type(dataset8))
for data in dataset8:
print(data)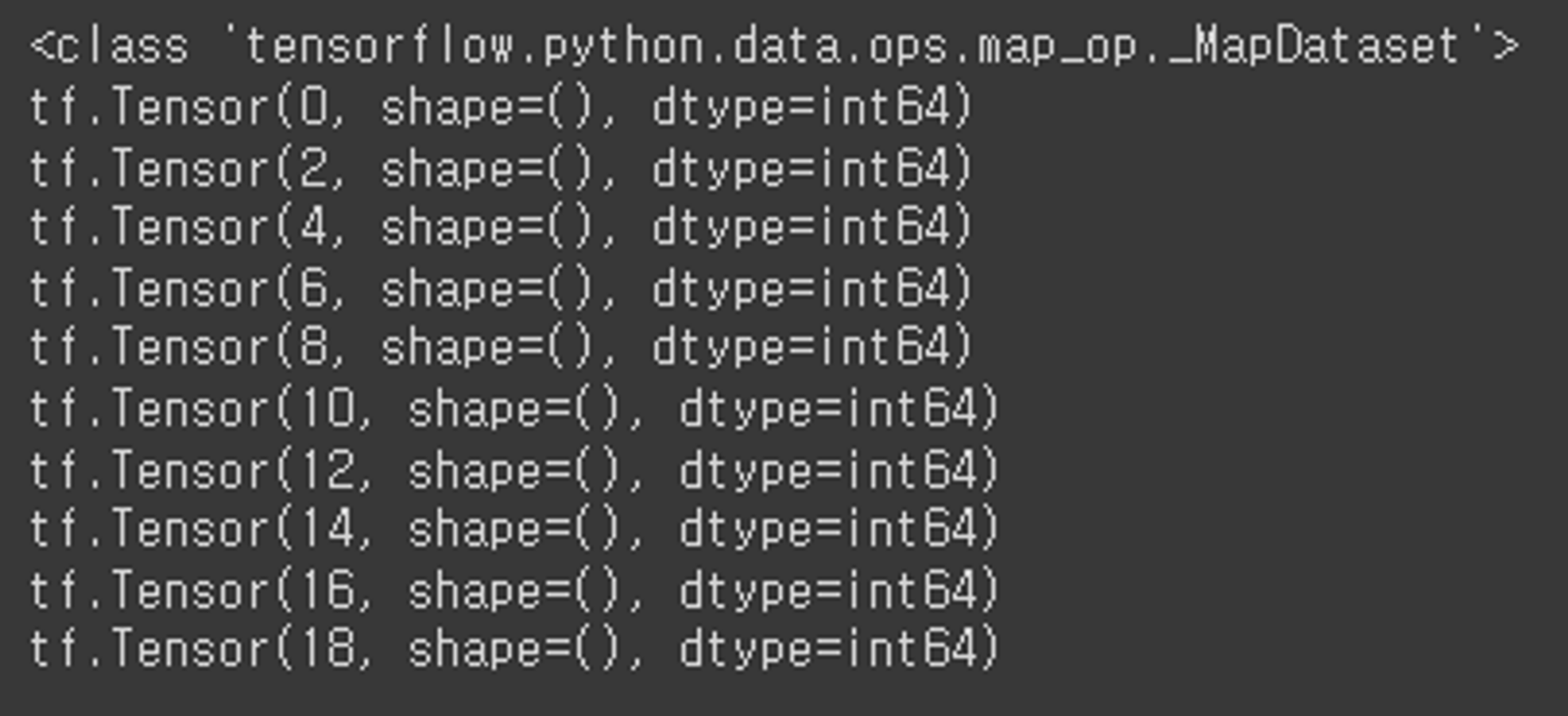
def map_func(x, y): # raw_data1: x, raw_data2: y
return x ** 2, y
dataset9 = dataset2.map(map_func)
for x, y in dataset9:
print(x, y)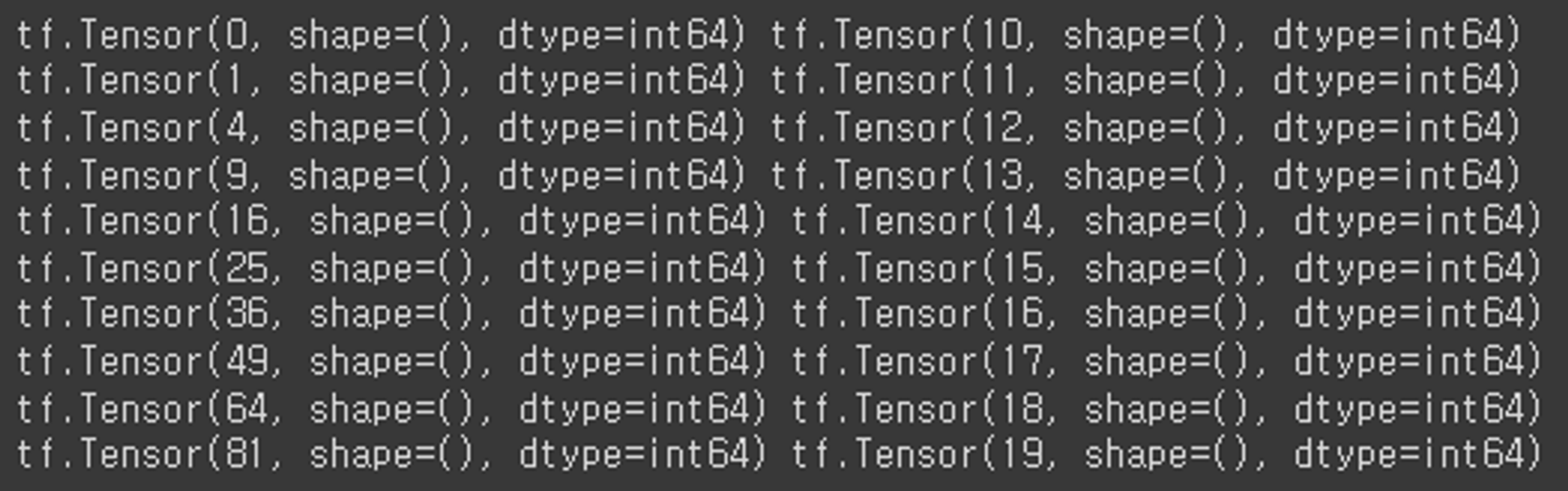
- filter
import tensorflow as tf
import numpy as np
raw_data1 = np.arange(10)
dataset = tf.data.Dataset.from_tensor_slices(raw_data1)
def filter_func(x):
return x % 2 == 0 # 2의 배수인지 여부를 반환
dataset11 = dataset.filter(filter_func)
print(type(dataset11))
for data in dataset11:
print(data)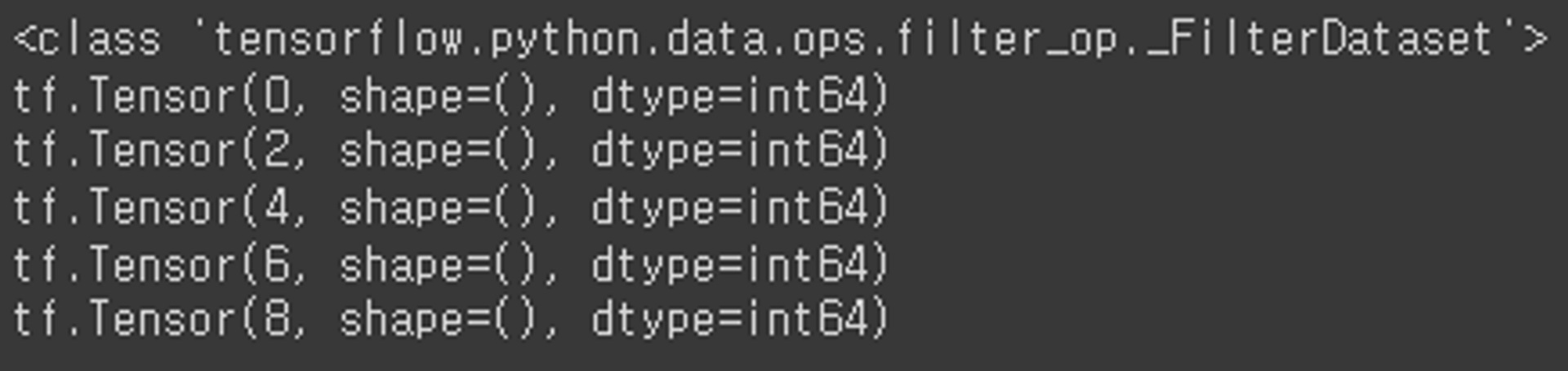
문제 유형별 MLP 네트워크
Regression(회귀)
- 보스턴 주택가격 dataset은 다음과 같은 속성을 바탕으로 해당 타운 주택 가격의 중앙값을 예측하는 문제.
CRIM: 범죄율
ZN: 25,000 평방피트당 주거지역 비율
INDUS: 비소매 상업지구 비율
CHAS: 찰스강에 인접해 있는지 여부(인접:1, 아니면:0)
NOX: 일산화질소 농도(단위: 0.1ppm)
RM: 주택당 방의 수
AGE: 1940년 이전에 건설된 주택의 비율
DIS: 5개의 보스턴 직업고용센터와의 거리(가중 평균)
RAD: 고속도로 접근성
TAX: 재산세율
PTRATIO: 학생/교사 비율
B: 흑인 비율
LSTAT: 하위 계층 비율
Target
MEDV: 타운의 주택가격 중앙값(단위: 1,000달러)
<모델 구현>
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
# 랜덤 시드 설정
tf.random.set_seed(0)
np.random.seed(0)
random.seed(0)
# 데이터 로드 및 전처리
(train_X, y_train), (test_X, y_test) = keras.datasets.boston_housing.load_data()
scaler = StandardScaler()
X_train = scaler.fit_transform(train_X)
X_test = scaler.transform(test_X)
# 데이터셋 준비
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train)).shuffle(X_train.shape[0]).batch(N_BATCH, drop_remainder=True)
test_dataset = tf.data.Dataset.from_tensor_slices((X_test, y_test)).batch(N_BATCH_VAL)
# 모델 구성
def get_model_boston(lr=0.01):
model = keras.Sequential()
model.add(layers.Dense(units=32, activation='relu', input_shape=(13, )))
model.add(layers.Dense(units=16, activation='relu'))
model.add(layers.Dense(units=8, activation='relu'))
model.add(layers.Dense(units=1))
model.compile(optimizer=keras.optimizers.Adam(learning_rate=lr), loss='mse')
return model
model_boston = get_model_boston()
# 딥러닝 모델의 구조 확인
model_boston.summary()
# train_dataset 생성->X, y를 제공
hist = model_boston.fit(train_dataset,
epochs=N_EPOCH,
validation_data=test_dataset
)
# 학습 결과 시각화
plt.plot(hist.epoch, hist.history['loss'], label='Train set')
plt.plot(hist.epoch, hist.history['val_loss'], label='Validation set')
plt.title('에폭별 MSE loss')
plt.legend()
plt.show()
# 테스트 데이터셋으로 손실 값 계산
loss = model_boston.evaluate(test_dataset)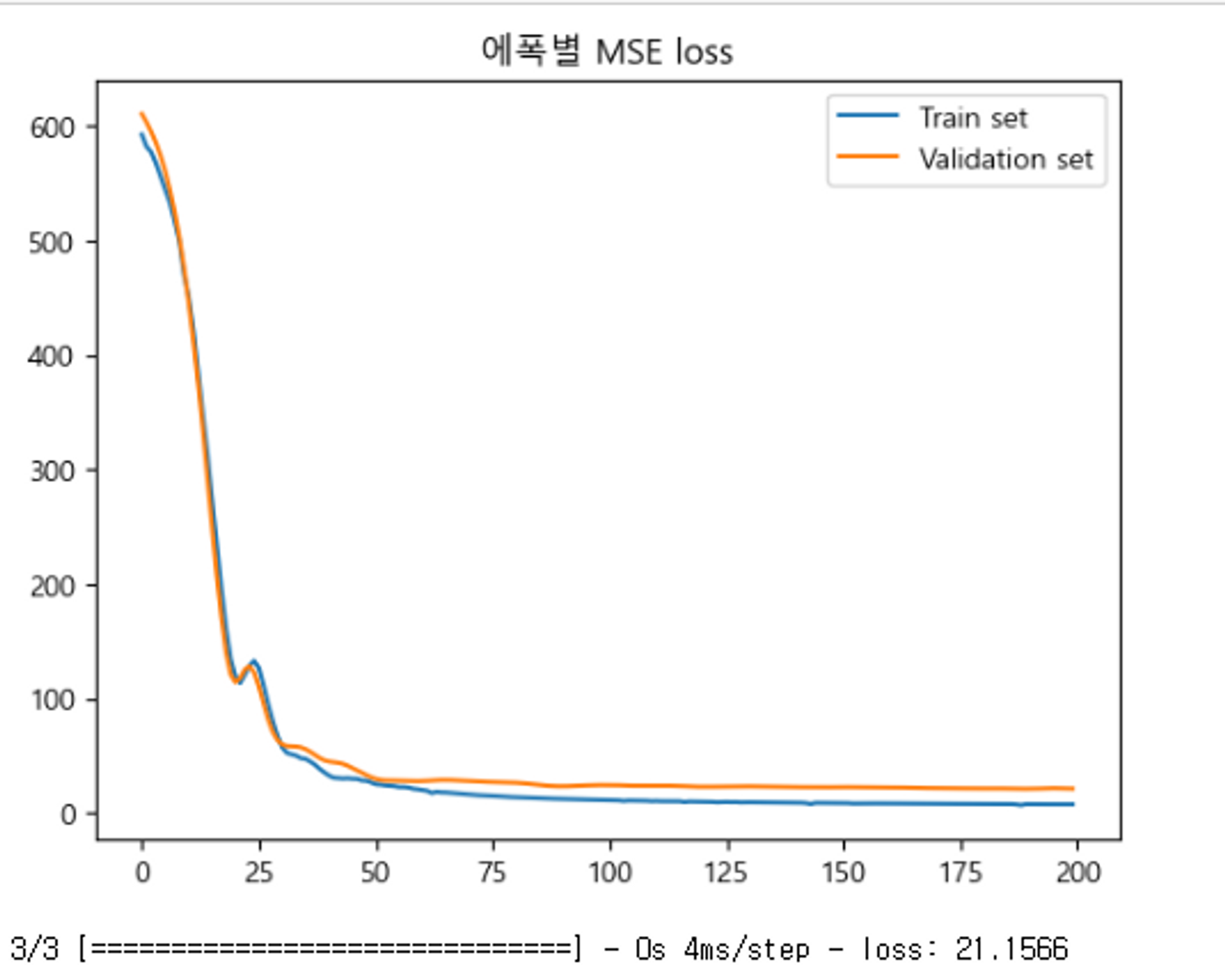
분류(Classification)
- Fashion MNIST Dataset - 다중분류(Multi-Class Classification) 문제
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, models, optimizers
import numpy as np
import matplotlib.pyplot as plt
import os
import random
# seed 값 설정
random.seed(0)
np.random.seed(0)
tf.random.set_seed(0)
# class index -> class name
class_names = np.array(['T-shirt/top', 'Trousers', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'])
# Fashion MNIST 데이터셋 로드
(train_image, y_train), (test_image, y_test) = keras.datasets.fashion_mnist.load_data()
train_image.shape, y_train.shape, test_image.shape, y_test.shape
# Train/Validation 데이터셋 분할
from sklearn.model_selection import train_test_split
train_image, val_image, y_train, y_val = train_test_split(train_image, y_train, test_size=0.2, stratify=y_train, random_state=0)
train_image.shape, val_image.shape
# 이미지 시각화
cnt = 15 # 확인할 이미지 개수 (5의 배수)
plt.figure(figsize=(7, 7))
for i in range(cnt):
plt.subplot(5, int(cnt/5), i+1) # 5행, cnt/5열
plt.imshow(train_image[i], cmap='Greys') # gray: 0-black, 255-white, Greys: 0-white, 255-black
label = class_names[y_train[i]]
plt.title(label)
plt.tight_layout()
plt.show()
# 하이퍼파라미터 변수
LEARNING_RATE = 0.001 # 학습률
N_EPOCH = 20 # 에폭 수
N_BATCH = 1000 # 배치 사이즈
# 데이터 전처리 (스케일링)
X_train = train_image.astype('float32') / 255.0
X_val = val_image.astype('float32') / 255.0
X_test = test_image.astype('float32') / 255.0
# 데이터 크기 및 범위 확인
print(train_image.min(), train_image.max())
print(X_train.min(), X_train.max())
# 데이터 크기 확인
X_train.shape, X_val.shape, X_test.shape
# 레이블 확인
y_train[:10]
=> 위의 코드에서 출력이 되지않은 부분들도 있다는 것을 염두해주길바란다. 만약 하나하나의 출력값의 궁금하다면 코드를 분리해서 실행시켜보는 것을 추천한다.
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train)) \
.shuffle(X_train.shape[0]).batch(N_BATCH, drop_remainder=True)
val_dataset = tf.data.Dataset.from_tensor_slices((X_val, y_val)).batch(N_BATCH)
test_dataset = tf.data.Dataset.from_tensor_slices((X_test, y_test)).batch(N_BATCH)
len(train_dataset), len(val_dataset), len(test_dataset)
def get_model_fashion(lr=0.01):
model = keras.Sequential() # 빈 모델 생성
# 모델에 layer들 추가
# input: (28,28) ==> 2차원 Dense layer는 입력으로 1차원 배열을 받는다. 2차원을 1차원으로 변환: Flatten layer
model.add(layers.Flatten(input_shape=(28, 28)))
# hidden layer
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
# output layer
model.add(layers.Dense(10, activation='softmax', name='output'))
# 컴파일
model.compile(optimizer=optimizers.Adam(learning_rate=lr),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
model_fashion = get_model_fashion(LEARNING_RATE)
model_fashion.summary()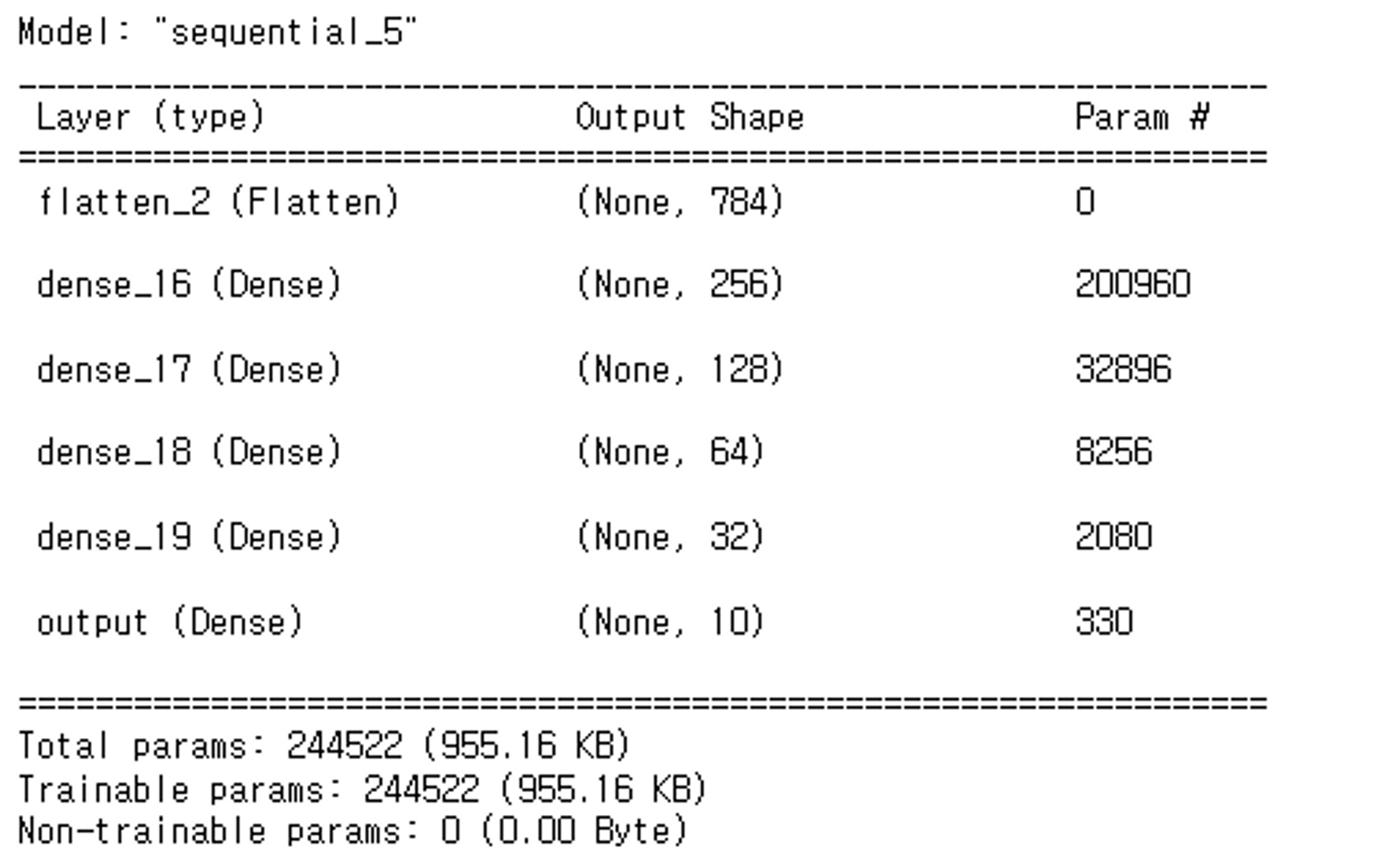
keras.utils.plot_model(model_fashion, show_shapes=True)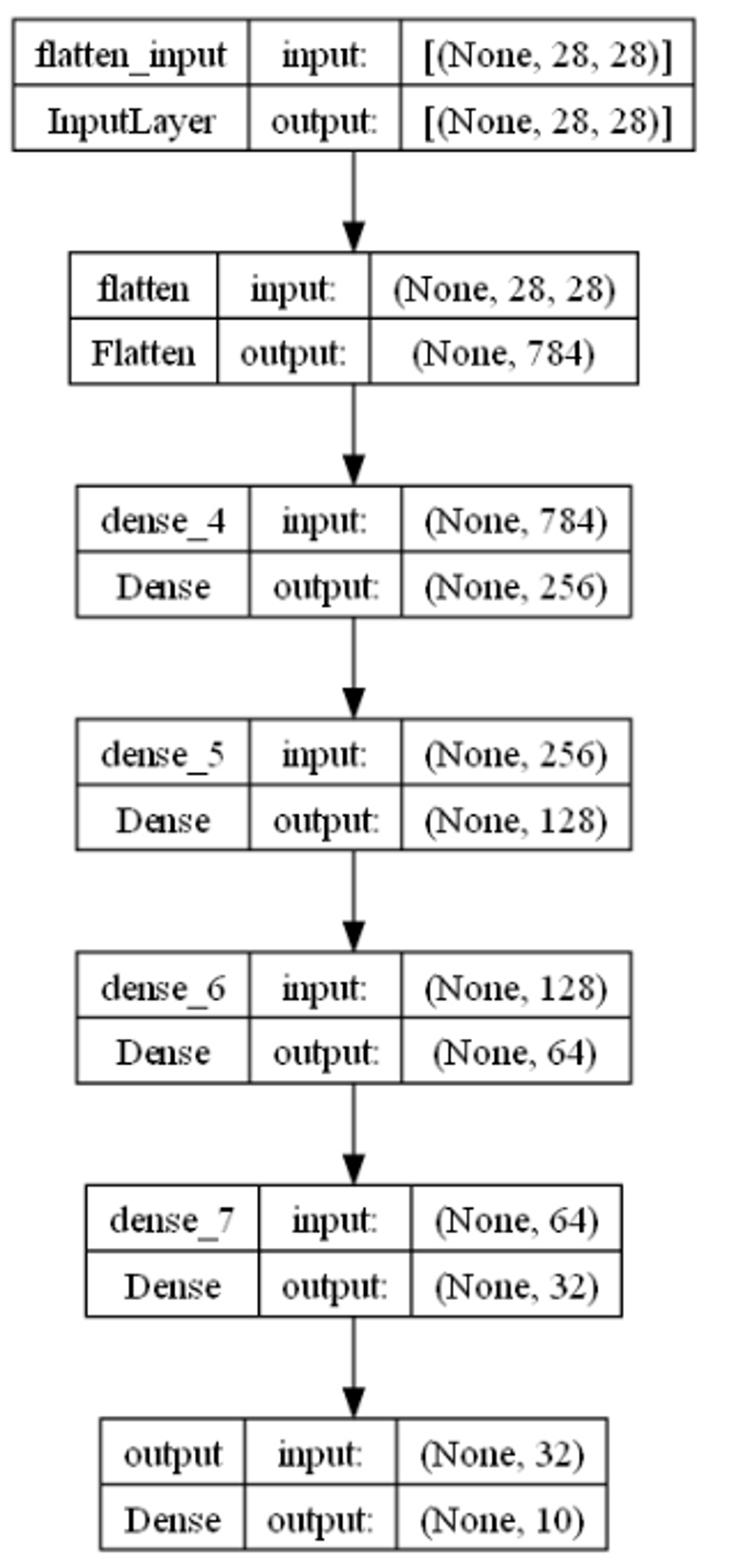
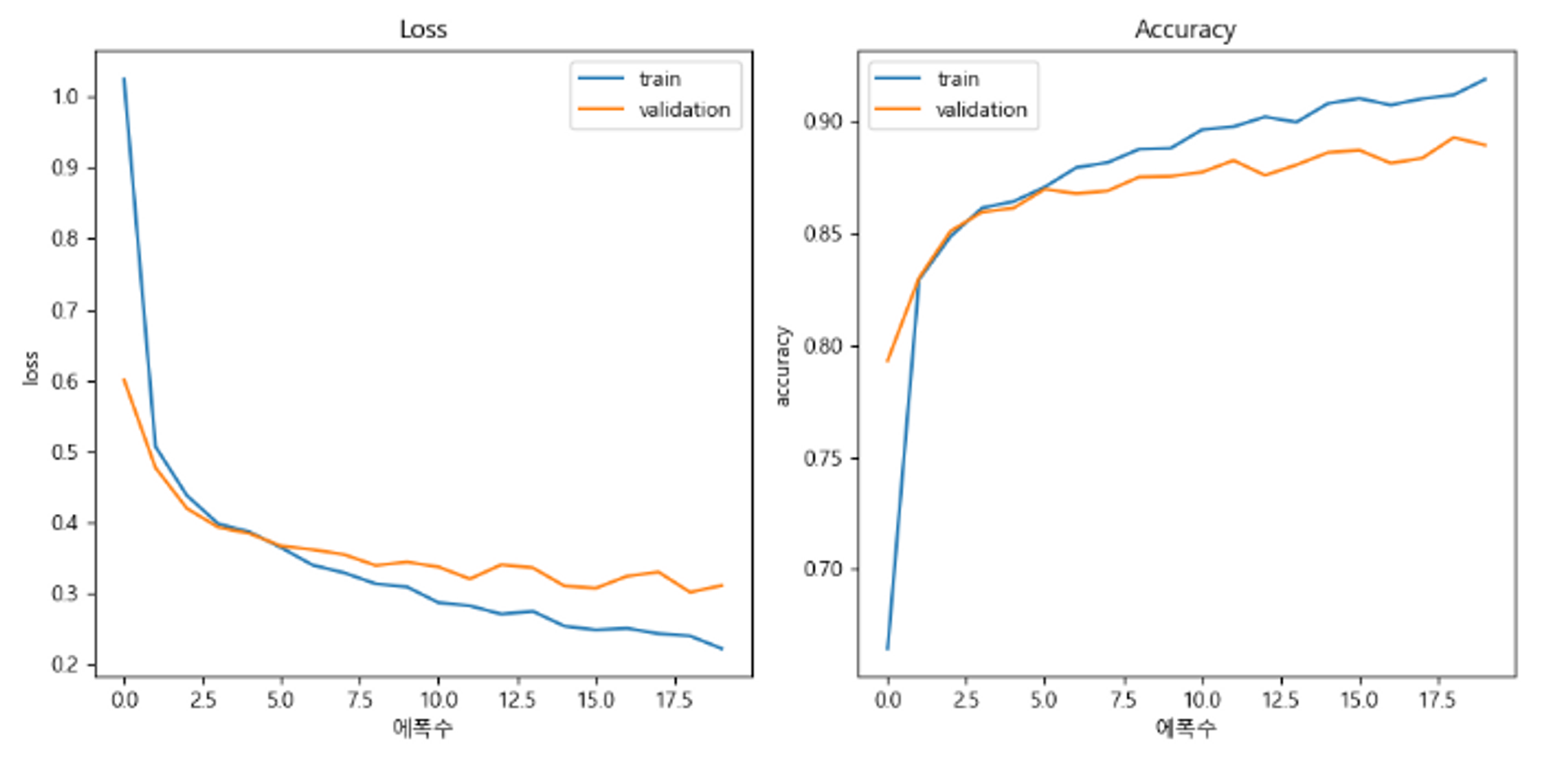
hist = model_fashion.fit(train_dataset, epochs=N_EPOCH, validation_data=val_dataset)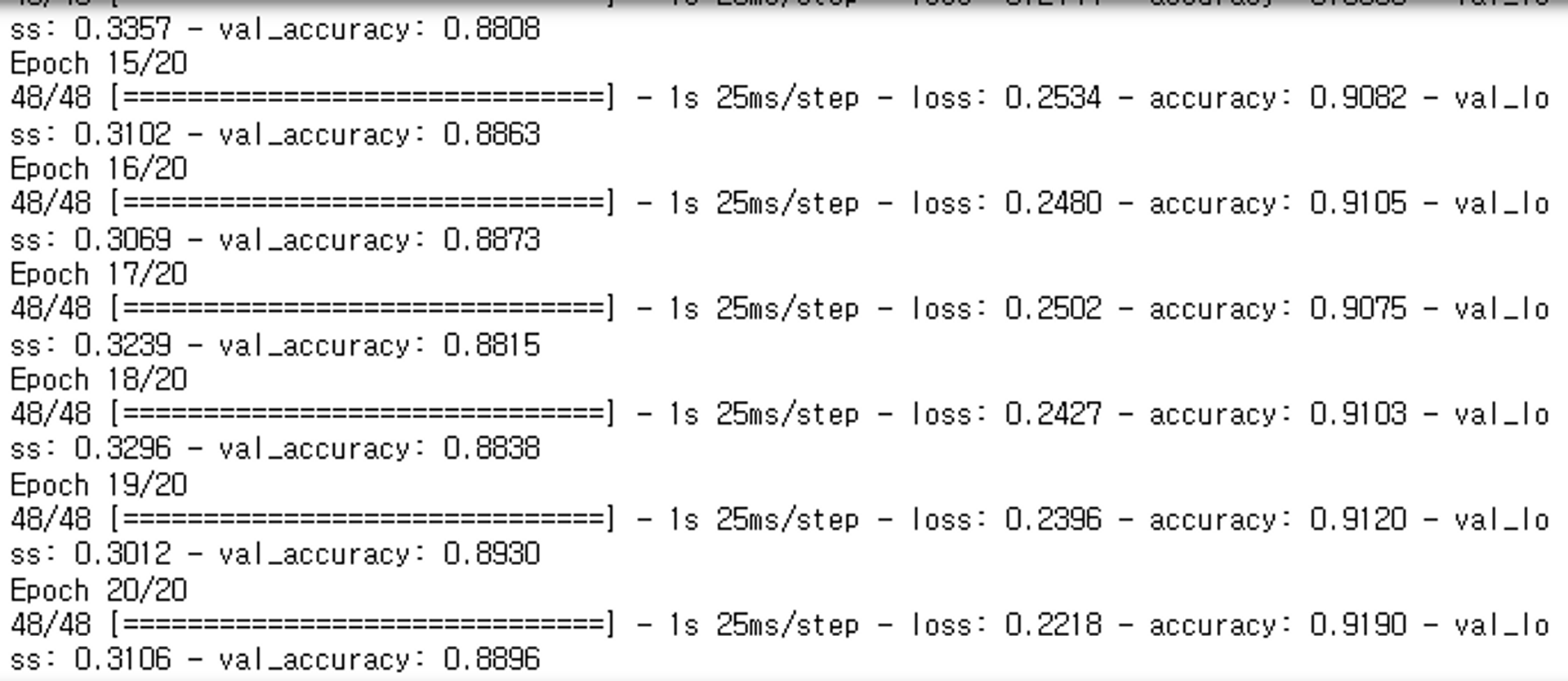
hist = model_fashion.fit(train_dataset, epochs=20, validation_data=val_dataset)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(hist.epoch, hist.history['loss'], label='train')
plt.plot(hist.epoch, hist.history['val_loss'], label='validation')
plt.title('Loss')
plt.xlabel('에폭수')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(hist.epoch, hist.history['accuracy'], label='train')
plt.plot(hist.epoch, hist.history['val_accuracy'], label='validation')
plt.title('Accuracy')
plt.xlabel('에폭수')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.show()
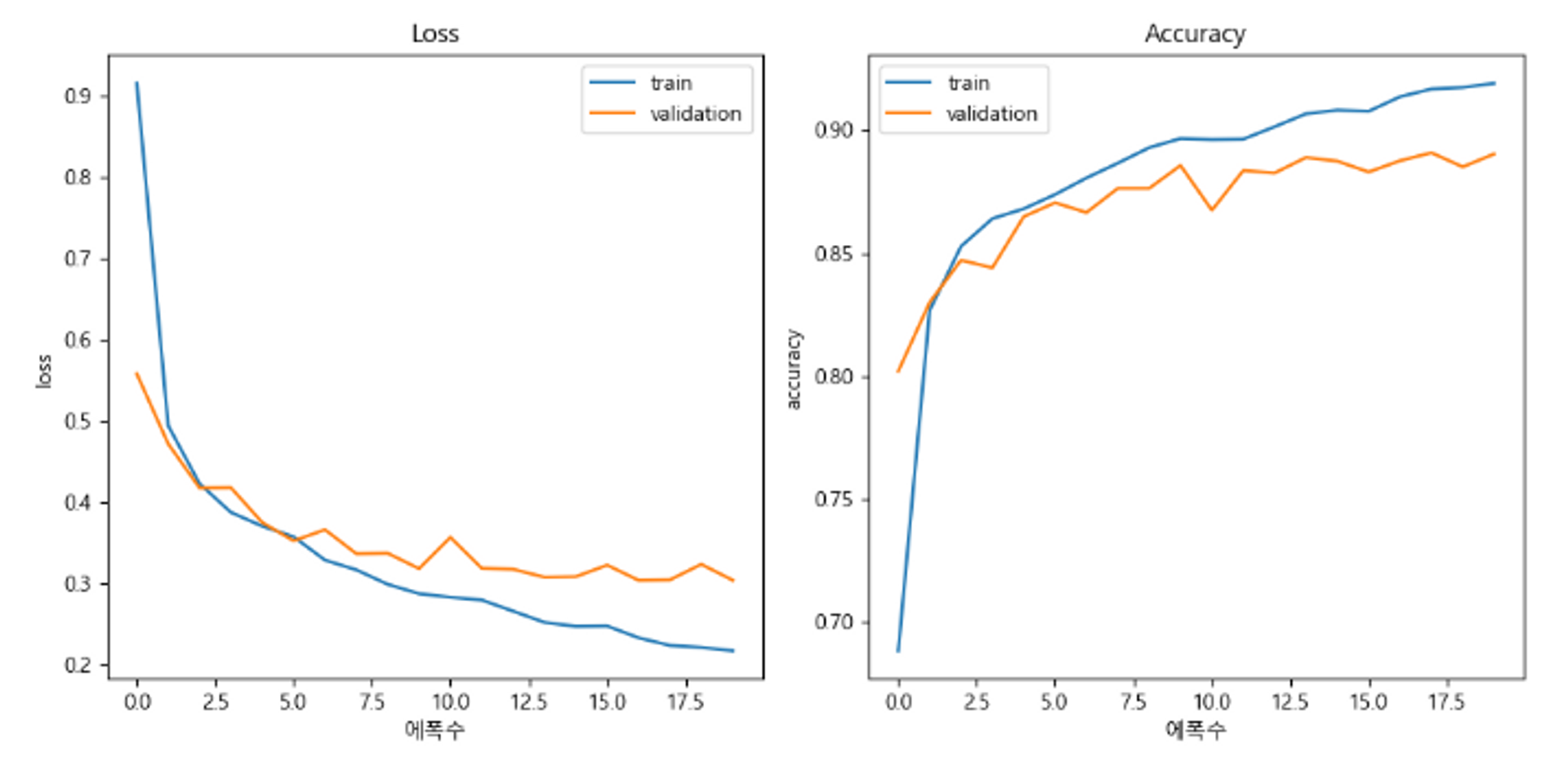
model_fashion2 = get_model_fashion(LEARNING_RATE)
hist = model_fashion2.fit(train_dataset, epochs=20, validation_data=val_dataset)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(hist.epoch, hist.history['loss'], label='train')
plt.plot(hist.epoch, hist.history['val_loss'], label='validation')
plt.title('Loss')
plt.xlabel('에폭수')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(hist.epoch, hist.history['accuracy'], label='train')
plt.plot(hist.epoch, hist.history['val_accuracy'], label='validation')
plt.title('Accuracy')
plt.xlabel('에폭수')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.show()
# test set
loss, acc = model_fashion2.evaluate(test_dataset)
print(f"Loss: {loss}, Accuracy: {acc}")


Hi
정말 잘 읽었습니다, 고맙습니다!