Iris(붓꽃) 예측모델
설명
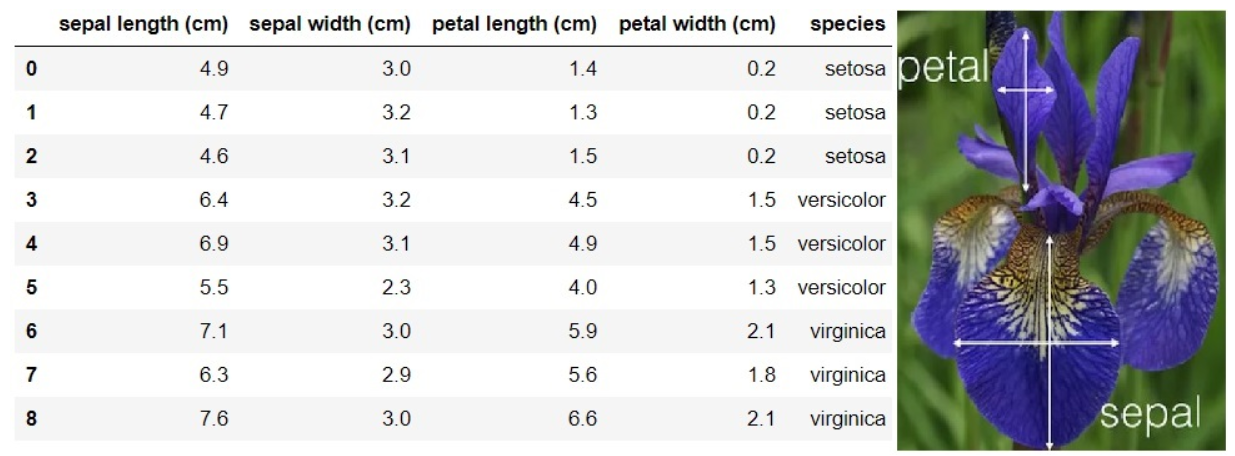
- 아이리스 품종 중 Setosa, Versicolor, Virginica 분류에 대한 로널드 피셔의 1936년 논문에서 사용된 데이터 셋
- 꽃받침(Sepal)과 꽃잎(Petal)의 길이 너비로 세개 품종을 분류
데이터셋 확인하기
- 지난시간에 소개했던 머신러닝 모델을 테스트하기 위한 데이터셋을 제공하는 라이브러리인 scikit-learn에서 내장 데이터셋을 가져온다.
-> 이런 데이터셋을 Toy dataset이라고 한다.- 패키지: sklearn.datasets
- 함수 : load_xxxx()
from sklearn.datasets import load_iris
# scikit-learn에서 내장 데이터셋을 가져온다.
import numpy as np
iris = load_iris()
type(iris)
# 결과 sklearn.utils._bunch.Bunch- key값 확인
iris.keys()
# 결과
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])scikit-learn 내장 데이터셋의 구성
- scikit-learn의 dataset은 딕셔너리 구조의 Bunch 클래스 객체이다.
- keys() 함수로 key값들을 조회
- 구성
- target_names: 예측하려는 값(class)을 가진 문자열 배열
- target: Label(출력데이터)
- data: Feature(입력변수)
- feature_names: 입력변수 각 항목의 이름
- DESCR: 데이터셋에 대한 설명
X = iris['data']
print(type(X), X.shape)
# 결과
<class 'numpy.ndarray'> (150, 4)
np.unique(y, return_counts=True)
# unique는 y에서 중복된 값들을 제거하고, 유일한 값들을 반환
# return_counts=True는 선택적인 매개변수로, 이를 사용하면 고유한 값들의 등장 횟수도 함께 반환
위 데이터 셋을 판다스 데이터프레임으로 구성
df = pd.DataFrame(iris['data'], columns=iris['feature_names'])
df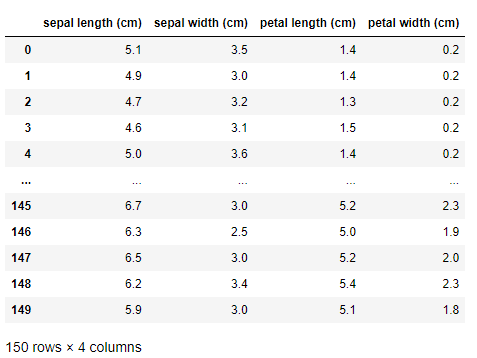
df['target'] = iris['target']
df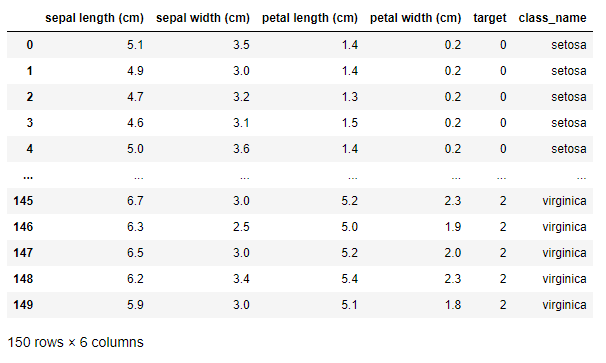
df['class_name'] = df['target'].apply(lambda idx : iris['target_names'][idx])
df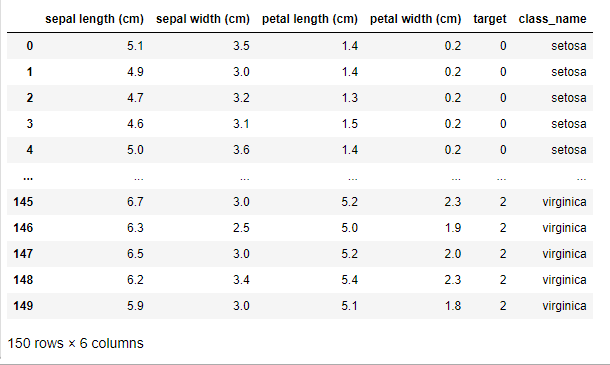
머신러닝을 이용한 예측
- 머신러닝 알고리즘
- 프로그래머가 직접 규칙(패턴)을 만드는 대신 컴퓨터가 데이터를 학습하여 규칙을 자동으로 만들도록 머신러닝을 이용한다.
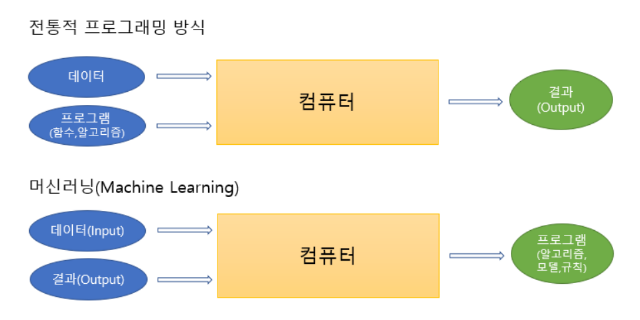
- 프로그래머가 직접 규칙(패턴)을 만드는 대신 컴퓨터가 데이터를 학습하여 규칙을 자동으로 만들도록 머신러닝을 이용한다.
우선 우리는 특징과 정답을 알려주며 학습할 할 것이고 범주안에서 결정하므로 분류알고리즘 중에서도 의사결정나무(Decision Tree) 알고리즘을 이용하여 분류 할 것이다.
=> 결정트리알고리즘은 독립변수의 조건에 따라 종속 변수를 분리한다.
- 결정트리 모델을 이용해 머신러닝 구현
- import 모델
- 모델 생성
- 모델 학습시키기
- 추론
문제 정의
내가 발견한 Iris 꽃받침(Sepal)의 길이(length)와 폭(width)이 각각 5cm, 3.5cm이고 꽃의 꽃잎(Petal)의 길이와 폭은 각각 1.4cm, 0.25cm이 이었다. 이 꽃는 Iris의 무슨 종일까?
# import 모델
from sklearn.tree import DecisionTreeClassifier
X = iris['data']
y = iris['target']
# 모델생성
clf = DecisionTreeClassifier()
# 모델 학습 시키기
clf.fit(X, y) # fit=> 데이터 학습
추론=> 내가 본 Iris꽃의 꽃잎/꽃받침의 길이,너비를 재서 종류를 예측한다.
# 1개 꽃을 추론
new_data = np.array([[5, 3.5, 1.4, 0.25]])
new_data.shape
# 결과 (1, 4)
pred = clf.predict(new_data) # predict=> 예측
pred # 결과 array([0])
# 결과 후처리 : class->class name
iris['target_names'][pred]
# 결과 array(['setosa'], dtype='<U10')setosa 종이 라는 것을 예측할 수 있다.
이 결과가 맞을까?
-
위의 예는 우리가 만든 모델의 성능이 좋은모델인지 나쁜모델인지 알 수 없다.
=> 그래서 전체 데이터 셋을 두개의 데이터셋으로 나눠 하나는 훈련할 때 사용하고 다른 하나는 그 모델을 평가할 때 사용한다. -
데이터셋 분할 시 주의
- 분류 문제의 경우 각 클래스(분류대상)가 같은 비율로 나뉘어야 한다.
-
scikit-learn의 train_test_split() 함수를 이용해 iris 데이터셋 분할
=> train_test_split() : 하나의 데이터셋을 두개의 세트로 분할 하는 함수
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
import numpy as np
iris = load_iris()
X, y = iris.data, iris.target
X.shape, y.shape # 결과 ((150, 4), (150,))
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2,
stratify=y,
shuffle=True,
random_state=0
)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
# 데이터를 분할할 때, 각 분할에 특정한 특징이나 속성을 균등하게 유지하기 위해 사용되는 개념
# 결과 ((120, 4), (30, 4), (120,), (30,))모델생성
clf = DecisionTreeClassifier()모델학습
clf.fit(X_train, y_train)
평가
- 정확도(accuracy)
accuracy_score() 함수 이용
전체 예측한 개수 중 맞춘 개수의 비율
pred = clf.predict(X_test)
pred
# 결과
array([0, 1, 0, 2, 0, 1, 2, 0, 0, 1, 2, 1, 1, 2, 1, 2, 2, 1, 1, 0, 0, 2,
2, 1, 0, 1, 1, 2, 0, 0])
y_test
# 결과
array([0, 1, 0, 2, 0, 1, 2, 0, 0, 1, 2, 1, 1, 2, 1, 2, 2, 1, 1, 0, 0, 2,
2, 2, 0, 1, 1, 2, 0, 0])
np.sum(pred == y_test)/y_test.size
# 결과 0.9666666666666667
accuracy_score(y_test, pred)
# 결과 0.9666666666666667
Hi