Machine Learning(ML) 기초 및 응용
1.머신러닝 개요
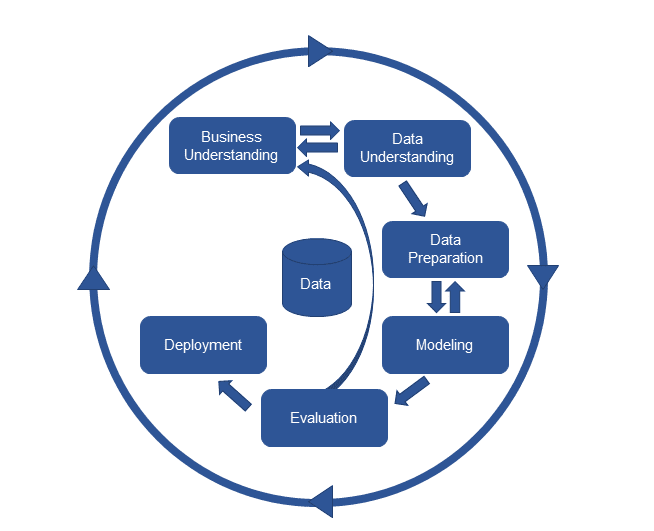
인공지능(AI - Artificial Intelligence)이란기계가 사람의 지능을 모방하게 하는 기술규칙기반, 데이터 학습 기반<Artificial General Intelligence (AGI)>인간이 할 수 있는 모든 지적인 업무를 해낼 수 있는 가상적인
2.머신러닝 분석- Iris Dataset
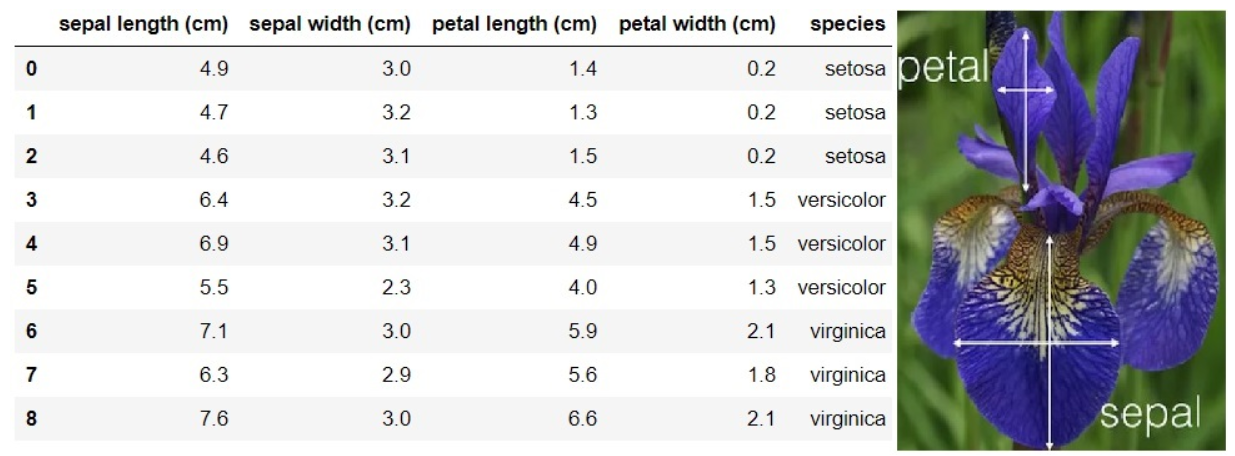
설명아이리스 품종 중 Setosa, Versicolor, Virginica 분류에 대한 로널드 피셔의 1936년 논문에서 사용된 데이터 셋꽃받침(Sepal)과 꽃잎(Petal)의 길이 너비로 세개 품종을 분류지난시간에 소개했던 머신러닝 모델을 테스트하기 위한 데이터셋을
3.데이터셋 나누기와 모델검증
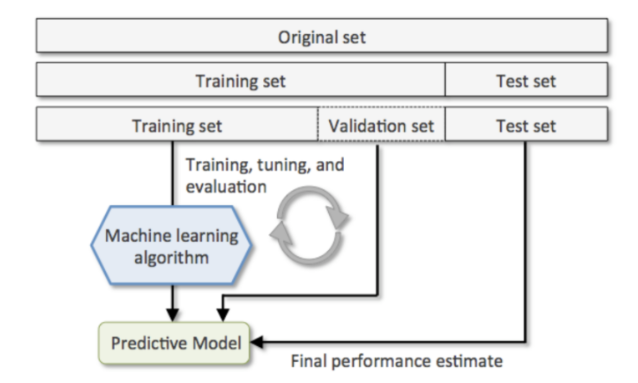
데이터셋(Dataset)Train 데이터셋(훈련/학습 데이터셋)모델을 학습시킬 때 사용할 데이터 셋Validation 데이터셋 (검증 데이터셋)모델의 성능 중간 검증을 위한 데이터셋Test 데이터셋 (평가 데이터셋)모델의 성능을 최종적으로 측정하기 위한 데이터셋Test
4.데이터 전처리
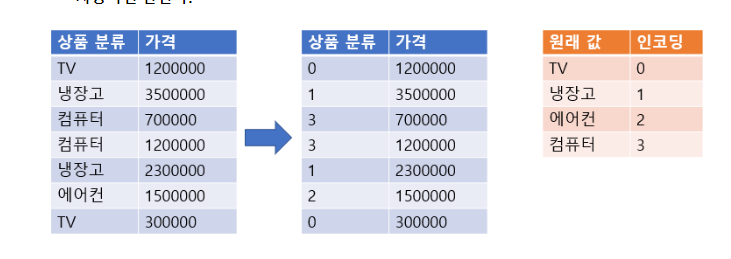
Data 전처리(Data Preprocessing)Raw Data을 학습하기 전에 변경하는 작업이다.목적에 따른 전처리 분류 2가지학습이 가능한 데이터셋을 만들기 위한 전처리 (머신러닝 알고리즘 수식이기때문에 숫자만 처리할 수 있어 결측치, 문자열이 있으면 학습이나
5.평가지표
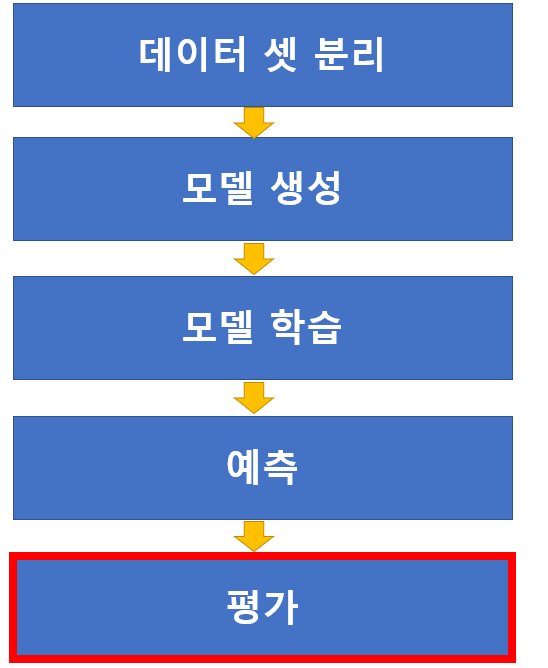
모델의 성능을 평가평과결과에 따라 프로세스를 다시 반복분류 평가 지표1\. 정확도 (Accuracy)2\. 정밀도 (Precision)3\. 재현률 (Recall)4\. F1점수 (F1 Score)5\. PR Curve, AP score6\. ROC, AUC score
6.과적합과 일반화 / Gredserch / pipeline
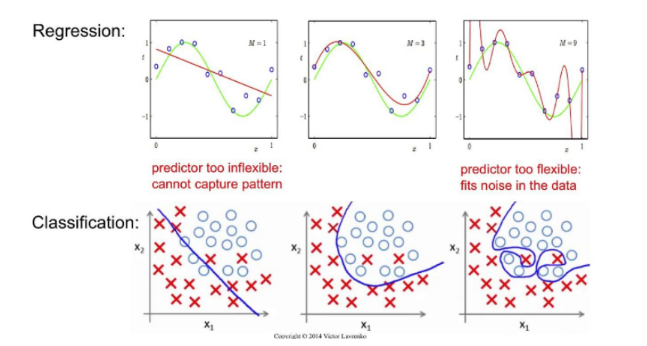
generalization (일반화)모델이 새로운 데이터셋 쉽게말해, 학습시 사용하지 않았던 데이터를 정확히 예측하면 이것을 일반화 되었다고 한다.훈련데이터셋으로 평가한 결과와 테스트데이터셋으로 평가한 결과가 거의 차이가 없고 좋은 평가를 보여준다.Overfitting
7.의사결정트리,랜덤포레스트
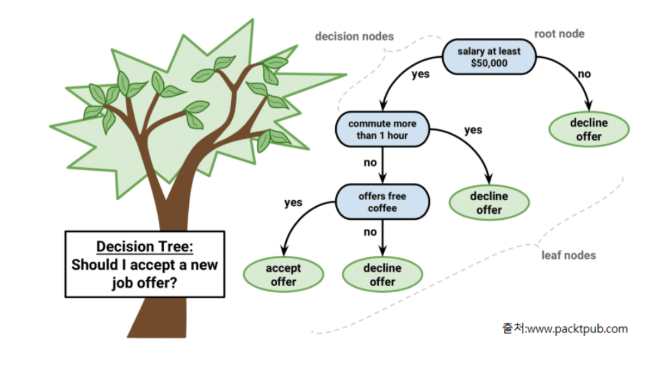
데이터를 잘 분류할 수 있는 질문을 던지면서 대상을 좁혀나가는 방식의 알고리즘이다.ex) 스무고개하위노드는 yes,no 두개로 분기한다.분기를 아무때나하나?분기를 하는 기준이 무엇인가?분기 기준분류: 가장 불순도를 낮출 수 있는 조건을 찾아 분기회귀: 가장 오차가 적은
8.Ensemble(Boosting/ 투표방식-Voting)
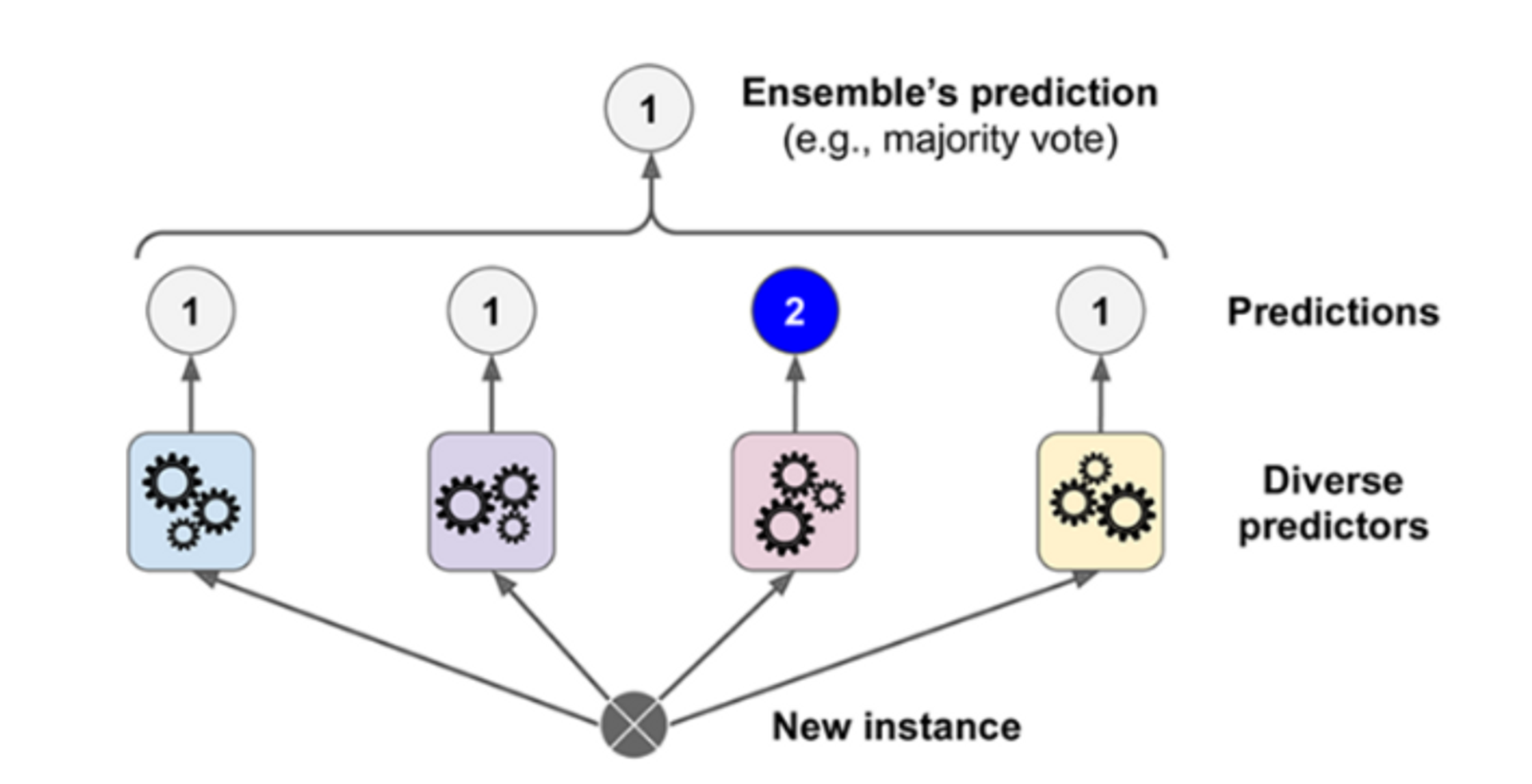
지난 포스팅에서 Ensemble의 정의에 대하여 설명하였지만 다시한번 말하고 가면 이해에 도움이 될까 싶어 간단히 말하고 넘어가겠다.Ensemble모델들이 있고 각자 학습하고 추론해서 취합할때만 합친다. -> 병렬처리가 가능하다.Ensemble의 종류로는 투표방식과 B
9.선형회귀
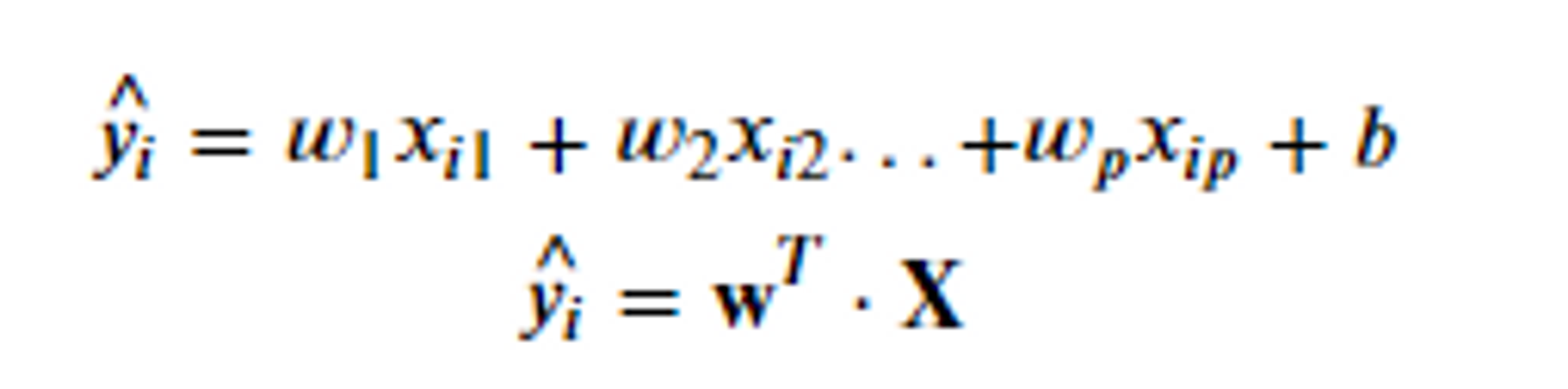
선형회귀는 종속 변수y와 한 개 이상의 독립 변수 x와의 선형 상관 관계를 모델링하는 회귀 분석기법이다.x:몸무게가 많이 나가면 y:키도 증가하더라대략적으로 분포하고 있는 것이 / 이런 선이였고 이것으로 직선의 방정식을 만들어보자.정확하게는 맞추지 못하더라고 오차가 적
10.최적화-경사하강법
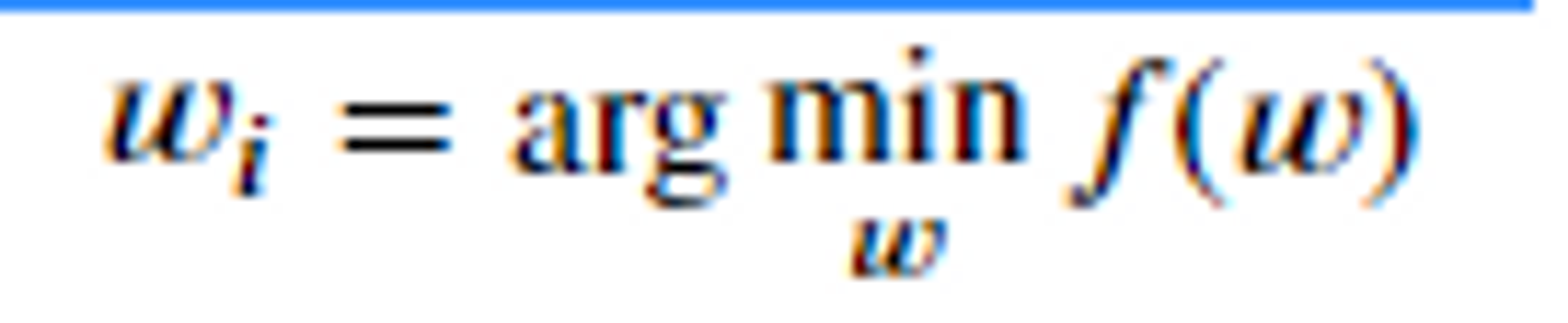
선형회귀 알고리즘을 이용한 이진 분류 모델이다,최적화 (Optimize)모델의 성능을 높여주는 것. → 그러기 위해서는 파라미터를 찾아야한다. 즉, 모델이 예측한 결과와 정답간의 차이(오차)를 가장 적게 만드는 Parameter를 찾는 과정을 최적화라고 한다.함수 f
11.로지스틱 회귀 (LogisticRegression)
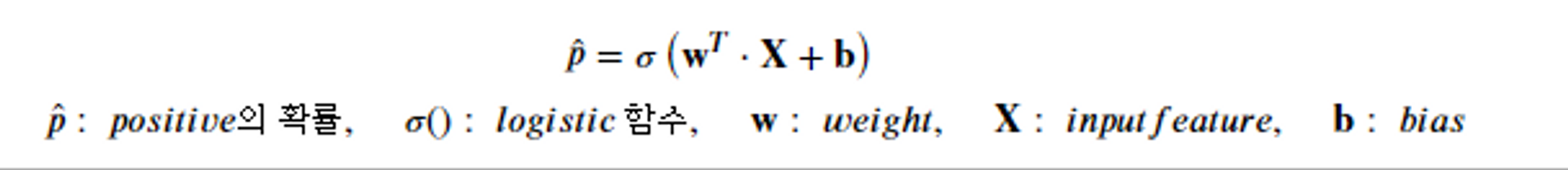
이전 포스팅에서 경사하강법을 설명한 이유는 로지스틱 회귀 (LogisticRegression)에서 경사하강법을 사용하기 때문이다.로지스틱 회귀 (LogisticRegression) = 시그모이드 함수(sigmoid function)선형회귀는 알고리즘을 이용한 이진 분류