의사결정나무(Decision Tree)
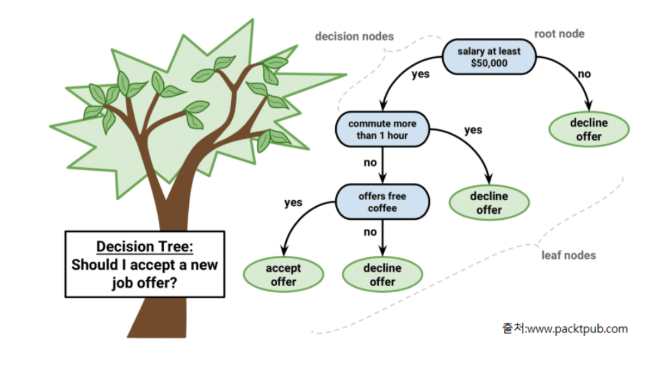
- 데이터를 잘 분류할 수 있는 질문을 던지면서 대상을 좁혀나가는 방식의 알고리즘이다.
ex) 스무고개 - 하위노드는 yes,no 두개로 분기한다.
분기를 아무때나하나?
분기를 하는 기준이 무엇인가?
- 분기 기준
- 분류: 가장 불순도를 낮출 수 있는 조건을 찾아 분기
- 회귀: 가장 오차가 적은 조건을 찾아 분기
- 다음포스팅에서 다루겠지만 앙상블기반 알고리즘인 랜덤 포레스트와 많은 부스팅(Boosting)기반 앙상블 모델들의 기반 알고리즘으로 사용된다.
근데 잠깐
순도(purity)/불순도(impurity)가 뭔데?
- 서로 다른 종류의 값들이 섞여 있는 비율
- 한 종류(class)의 값이 많을수록 순도가 높고 불순도는 낮다.
그럼 이제 의사결정트리에서 사용되는 용어에 대해 알아보자.
- Root Node : 시작 node
- Decision Node (Intermediate Node): 중간 node
- Leaf Node(Terminal Node) : 마지막 단계(트리의 끝)에 있는 노드로 최종결과
앞의 포스팅에서 과대적합과 일반화에 다뤘었던 것을 기억해보자.
여기에서도 과대적합(Overfitting) 문제가 발생할 수 있다.
- 과대적합(Overfitting)
- 모든 데이터셋이 분류되어 불순도가 0이 될때까지 분기해 나간것이다.
- Root에서 부터 하위 노드가 많이 만들어 질 수록 모델이 복잡해져 과대적합이 발생
- 과대적합을 막기 위해서는 적당한 시점에 하위노드가 더이상 생성되지 않도록 해야 한다.
=> 이것을 가지치기(Pruning)라고 한다.
의사결정트리에서 사용하는 최적의 성능을 찾기위한 하이퍼파라미터가 있다.
- 하이퍼파라미터
- max_depth: 트리의 최대 깊이(질문단계)
- max_leaf_nodes: 개수 제한 없다.
- min_samples_leaf: leaf가 될 수 있는 최소 데이터 수(이정도 있으면 leaf노드야)
- max_features: 지정한 개수의 Feature(특성)만 사용**
- min_samples_split: 분할 하기 위해 필요한 최소 샘플 수를 정의
ex) 10개보다 적으면 분할 x, 10보다 크면 분할 - criterion (분류/ 회귀): 각 노드의 불순도 계산 방식을 정의한다.
분류: gini(기본값) / 회귀:squared_error(기본값)
컬럼들의 중요도도 조회할 수 있다.
- Feature(컬럼) 중요도
- featureimportances 속성
- 전처리 단계에서 input data 에서 중요한 feature들을 선택할 때 decision tree를 이용
개념은 이제 이해가 되었다면 예제를 보자.
Wine Dataset을 이용하여 color를 분류할 것이다.
데이터셋: Wine Dataset
- features(와인 화학성분들):
- fixed acidity : 고정 산도
- volatile acidity : 휘발성 산도
- citric acid : 시트르산
- residual sugar : 잔류 당분
- chlorides : 염화물
- free sulfur dioxide : 자유 이산화황
- total sulfur dioxide : 총 이산화황
- density : 밀도
- pH : 수소 이온 농도
- sulphates : 황산염
- alcohol : 알콜
- quality: 와인 등급 (A>B>C)
- target - color
- 0: white, 1: red
import pandas as pd
wine = pd.read_csv('data/wine.csv')
wine.shape결과: (6497, 13)
데이터셋의 정보를 확인해보자.
wine.info()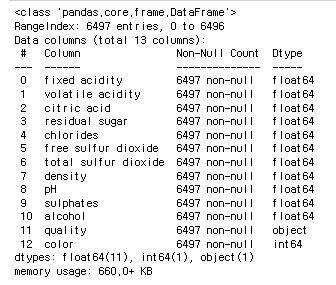
이번에는 0,1로 이루어져서 target으로 분리할 color의 0,1개수를 검색해보자.
wine['color'].value_counts(normalize=True)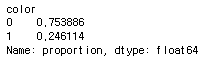
자 그럼 데이터셋 사용에 앞서 어떤 식으로 이루어져있는지 확인했으니 본격적으로 시작해보자.
- 범주형: Label Encoding, 연속형: Feature Scaling을 하지 않는다.
- 선형계열 모델(예측시 모든 Feature들을 한 연산에 넣어 예측하는 모델)일 경우
- 범주형: One Hot Encoding, 연속형: Feature Scaling을 한다.
# 1. X, y 분리
X = wine.drop(columns='color')
y = wine['color']
X.shape, y.shape결과: ((6497, 12), (6497,))
# 2. quality를 Label Encoding 처리
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(['A', 'B', 'C']) # 리스트 학습
X['quality'] = le.transform(X['quality']) # 변환
# 확인
X["quality"].value_counts()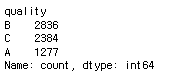
에서
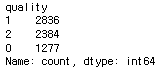
로 변환되었다.
from sklearn.model_selection import train_test_split, GridSearchCV, RandomizedSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
from graphviz import Source
from metrics import print_metrics_classification
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, stratify=y, random_state=0)
tree = DecisionTreeClassifier(random_state=0)
tree.fit(X_train, y_train)
# depth, level을 조회
tree.get_depth() 결과: 13
# leaf node의 개수
tree.get_n_leaves() 결과: 55
X_train이 1일때로 조회
print_metrics_classification(y_train,
tree.predict(X_train),
tree.predict_proba(X_train)[:, 1],
"Train set 평가결과")
print_metrics_classification(y_test,
tree.predict(X_test),
tree.predict_proba(X_test)[:, 1],
"Testset 평가결과") 
test set이 train set보다는 성능이 떨어지지만 0.9대로 좋은 성능을 나타낸다.
# graphviz를 이용해 tree 구조 시각화
graph = Source(export_graphviz(tree, #학습한 DecisionTree 모델
feature_names=X_train.columns,
class_names=["White", "Red"],
rounded=True,
filled=True
))
graph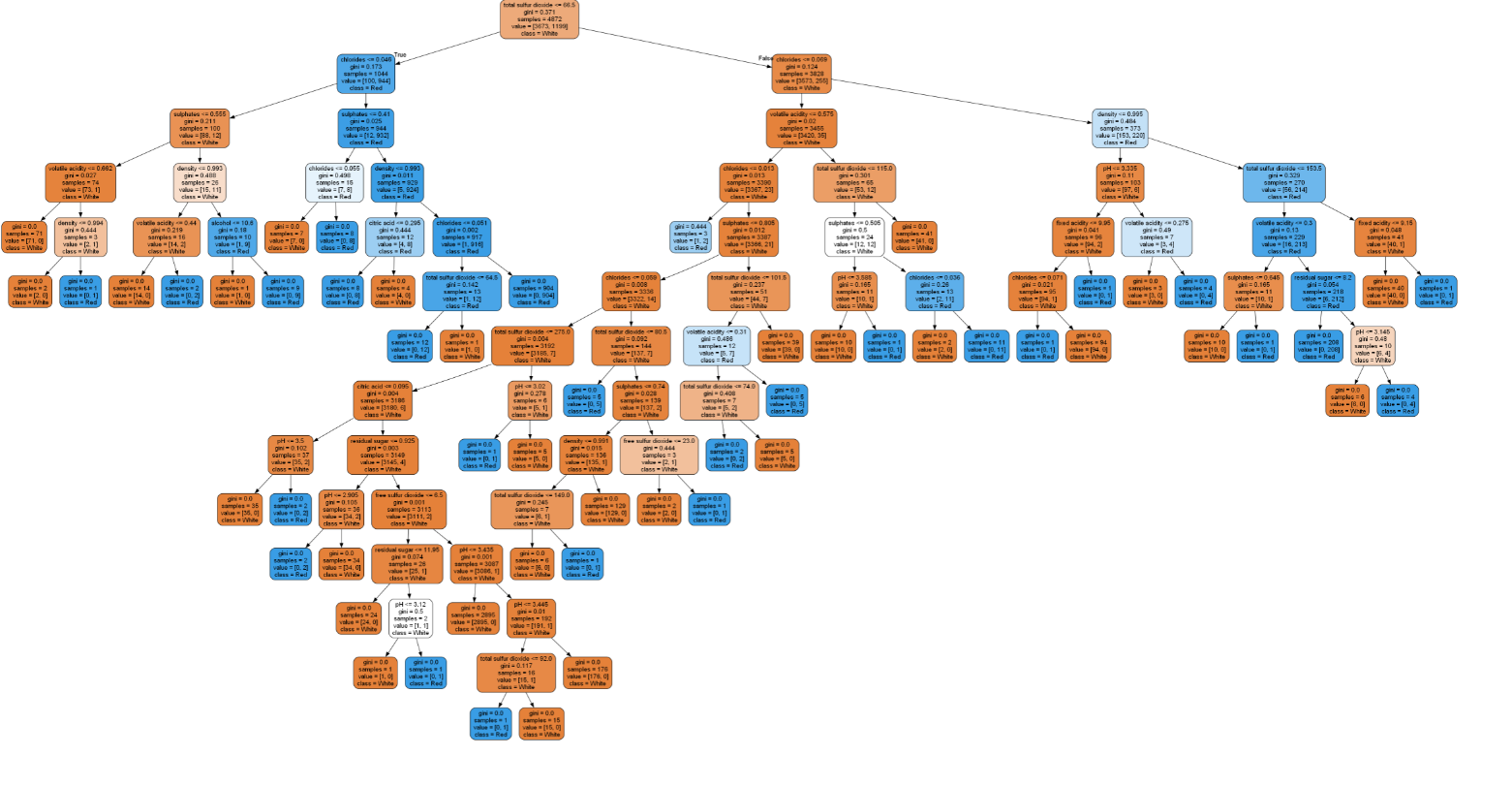
# 각 feature(컬럼)의 중요도 (점수)
fi = pd.Series(tree.feature_importances_, index=X.columns)
fi.sort_values(ascending=False)
total sulfur dioxide과 chlorides 중요도가 높은 것을 확인 할 수 있다.
# GridSearch를 이용해 최적의 파라미터 조회
params = {
"max_depth":range(1, 14),
"max_leaf_nodes":range(10, 34),
"min_samples_leaf":range(10, 1000, 50),
"max_features":range(1, 13)
}
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=0),
params, scoring='accuracy', cv=5, n_jobs=-1, n_iter=60)
gs.fit(X_train, y_train)
print("best score:", gs.best_score_)
print("best param:", gs.best_params_)best score: 0.9696222818933291
best param: {'min_samples_leaf': 110, 'max_leaf_nodes': 22, 'max_features': 9, 'max_depth': 3}
best_model = gs.best_estimator_
fi = pd.Series(best_model.feature_importances_, index=X.columns)
fi.sort_values(ascending=False)
최적의 파라미터로 구한 total sulfur dioxide과 chlorides 중요도가 더 높은 것을 확인할 수 있다.
graph = Source(export_graphviz(best_model,
feature_names=X.columns,
class_names=["White", "Red"], filled=True, rounded=True))
graph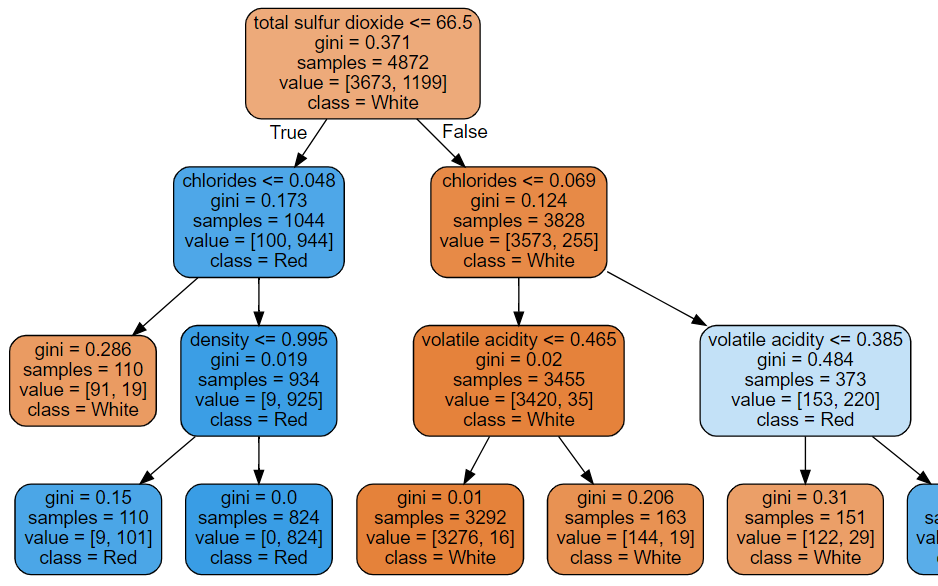
Ensemble(앙상블)
-
하나의 모델만을 학습시켜 사용하지 않고 여러 모델을 학습시켜 결합하는 방식으로 문제를 해결하는 방식이다.
-
개별로 학습한 여러 모델을 조합해 과적합을 막고 일반화 성능을 향상시킬 수 있다.
-
앙상블의 종류(투표방식 / 부스팅)
-
투표방식(Bagging / Voting)
- 여러개의 추정기가 낸 결과들을 투표를 통해 최종 결과를 내는 방식
- Bagging
=> 같은 유형의 알고리즘들을 조합하되 각각의 학습하는 데이터는 다르게 한다.
(Random Forest가 Bagging을 기반) - Voting
=> 서로 다른 종류의 알고리즘들을 결합한다.
-
부스팅(Boosting)
- 약한 학습기들을 결합해서 보다 정확하고 강력한 학습기를 만든다.
- 뒤의 학습기들은 앞의 학습기가 찾기 못한 부분을 추가적으로 찾는다.
-
투표방식 중의 하나인 같은 유형의 알고리즘들을 조합하되 각각의 학습하는 데이터는 다르게하는 Bagging 방식을 기반으로 하는 Random Forest (랜덤포레스트)에 대하여 알아보자.
-
Random Forest (랜덤포레스트)
- Decision Tree를 기반으로 한다.
- 다수의 Decision Tree를 사용해서 성능을 올린 앙상블 알고리즘의 하나
- 처리속도가 빠르며 성능도 높은 모델로 알려져 있다.
- 모든 DecisionTree들은 같은 구조를 가지게 한다.
- 학습시 모든 Decision Tree들이 서로 다른 데이터셋으로 학습하도록 Train dataset으로 부터 생성한 DecisionTree개수 만큼 sampling 한다.
- Sampling된 데이터셋들은 전체 피처중 일부만 랜덤하게 가지게 한다.
- 각 트리별로 예측결과를 내고 분류의 경우 그 예측을 모아 다수결 투표로 클래스 결과를 낸다.
- 회귀의 경우는 예측 결과의 평균을 낸다.
-
주요 하이퍼파라미터
- n_estimators: DecisionTree 모델의 개수
- max_features: 각 트리에서 선택할 feature의 개수
- Tree의 최대 깊이, 가지를 치기 위한 최소 샘플 수 등 Decision Tree에서 과적합을 막기 위한 파라미터들을 랜덤 포레스트에 적용가능하다.
