과적합과 일반화
- generalization (일반화)
- 모델이 새로운 데이터셋 쉽게말해, 학습시 사용하지 않았던 데이터를 정확히 예측하면 이것을 일반화 되었다고 한다.
- 훈련데이터셋으로 평가한 결과와 테스트데이터셋으로 평가한 결과가 거의 차이가 없고 좋은 평가를 보여준다.
- Overfitting(과적합)
- 모델이 훈련 데이터에 대한 예측성능은 너무 좋지만 일반성이 떨어져 새로운 데이터(테스트 데이터)에 대해서 성능이 좋지않은 것 -> 쉽게말해 train데이터는 성능이 좋지만 test데이터는 성능이 좋지 못한것이다.
- 이는 모델이 훈련 데이터 셋의 특징을 너무 과하게 맞춰서 학습 되었기 때문에 일반적으로 나타나지 않을 특징들까지학습되어 새로운 데이터셋에 대한 예측성이 떨어진것이다.
- Underfitting(과소적합)
- 모델이 훈련데이터와 테스트 데이터셋 모두에서 성능이 안좋은 것을 말한다.
- 이는 모델이 데이터에 대하여 충분한 학습을 못해 데이터셋의 일반적인 패턴들을 다 찾아내지 못해서 발생한 것이다.
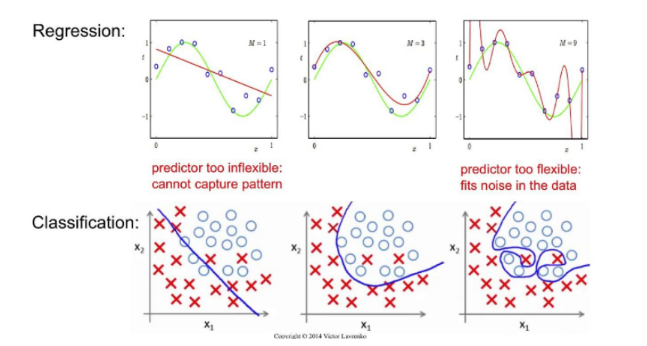
다음은 Underfitting 과 Overfitting의 예시이다.
-
회귀(Regression): train에 맞추려고 하다보니 빨간선처럼 이상한 함수가 만들어 졌다.
-
분류(Classification): train과 vallidation모두 성능이 좋지 못하다. 이상치 몇개를 무시하여 선을 만들어도 train성능은 좋아져도 test성능은 좋지않다.
<정리>
너무 과하게 맞추거나 너무 안맞추는 것은 좋지않으니 일반적인 특성들을 맞출 수 있도록 하는게 가장 best이다.
그럼 이런 Underfitting 과 Overfitting이 일어나는 원인은 무엇일까?
-
Overfitting(과대적합)의 원인
- 학습 데이터양에 비해 모델이 너무 복잡한 경우 발생
해결방법1: 데이터 양을 늘린다.
해결방법2: 모델을 좀더 단순하게 만든다.- 사용한 모델보다 단순한 모델을 사용하도록 할 수있다.
- 이러한 모델들의 복잡도를 변경할 수 있도록 규제와 관련된 하이퍼파라미터를 이용해 조절한다.
- 학습 데이터양에 비해 모델이 너무 복잡한 경우 발생
-
Underfitting(과소적합)의 원인
- 데이터의 양에 비해 모델이 너무 단순한 경우 발생
- 해결방법1: 좀더 복잡한 모델을 사용하도록 한다.
- 해결방법2: 모델이 제공하는 규제 하이퍼파라미터를 조절한다.
- 데이터의 양에 비해 모델이 너무 단순한 경우 발생
위에서 언급되는 규제 하이퍼파라미터란 무엇이길래 원인을 해결하는 방법으로 언급이 되는 것일까?
- 규제 하이퍼파라미터란?
- 모델의 복잡도를 규제하는 하이퍼파라미터로 Overfitting이나 Underfitting이 일어난 경우 이 값을 조정하도록 하여 모델이 일반화가 되도록 도와주는 것이다.
- 하이퍼파라미터란?
- 하이퍼파라미터 (Hyper Parameter)
=> 모델의 성능에 영향을 끼치는 파라미터 값으로 모델 생성시 사람이 직접 지정해 주는 값(파라미터) - 하이퍼파라미터 튜닝(Hyper Parameter Tunning)
=> 모델의 성능을 가장 높일 수 있는 하이퍼파라미터를 찾는 작업이다. - 파라미터(Parameter)
=> 머신러닝에서 파라미터는 모델이 데이터 학습을 통해 직접 찾아야 하는 값을 말한다.
- 하이퍼파라미터 (Hyper Parameter)
개념정리는 됐다! 이제 예제를 보자.
규제 하이퍼파라미터(모델의 문제를 조정)를 하기 위해서는 모델이 oerfitting이 났는지 underfitting이 났는지 알아한다.
1) 데이터셋을 정하고 분리
2) 모델 선정 후 모델링
from sklearn.datasets import load_breast_cancer # 유방암데이터셋
from sklearn.model_selection import train_test_split # 데이터셋 분리
data = load_breast_cancer()
X, y = data.data, data.target
# 데이터셋 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)- Decision Tree 복잡도 제어(규제 파라미터)
- Decision Tree 모델을 복잡하게 만드는 것은 노드가 너무 많이 만들어 지는 것이다.
- 노드가 많이 만들어 질수록 훈련데이터 셋은 Overfitting된다.
=> 그러므로 적절한 시점에서 생성을 중단해야한다. - 모델의 복잡도 관련 주요 하이퍼파라미터
- max_depth: 트리의 최대 깊이
- max_leaf_nodes : 리프노드 개수
- min_samples_leaf : leaf 노드가 되기위한 최소 샘플수
- 노드가 많이 만들어 질수록 훈련데이터 셋은 Overfitting된다.
- Decision Tree 모델을 복잡하게 만드는 것은 노드가 너무 많이 만들어 지는 것이다.
3) 최적의 하이퍼파라미터 찾기
3-1 최적의 max_depth 찾기
from sklearn.tree import DecisionTreeClassifier # 모델선정 - 분류-범주형
from sklearn.metrics import accuracy_score # 평가방법
# max_depth: None(default)-모든 leaf node들의 gini 계수가 0이 될때까지(하나의 노드에 하나의 클래스만 있을때 까지) 분기
max_depth_candidate = [1, 2, 3, 4, 5, None]
# 검증 결과를 담을 리스트
train_acc_list = []
test_acc_list = []
# 모델링
for max_depth in max_depth_candidate:
# 객체생성
tree = DecisionTreeClassifier(max_depth=max_depth, random_state=0)
# 학습
tree.fit(X_train, y_train)
# 판정
pred_train = tree.predict(X_train)
pred_test = tree.predict(X_test)
#평가
train_acc_list.append(accuracy_score(y_train, pred_train))
test_acc_list.append(accuracy_score(y_test, pred_test))모델링 결과확인
import pandas as pd
result_df = pd.DataFrame({
"train":train_acc_list,
"test":test_acc_list
}, index=max_depth_candidate)
result_df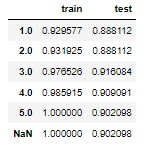
각 깊이 별로 train set,test set의 정확도를 알 수 있다.
그럼 여기서 max_depth는?
result_df.plot()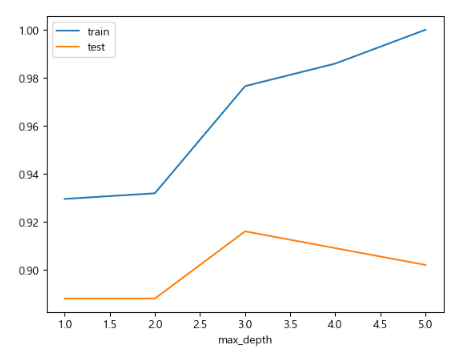
위의 DataFrame을 line plot로 나타낸 결과 train과 test set 결과가 모두 적당한 3이 최적의 max_depth(트리의 최대 깊이)인 것을 알 수 있다.
!여기서 잠깐!
최적의 파라미터 (max_depth)를 찾기 위해 항상 결과를 담을 리스트를 만들고 모델링결과를 리스트에 담아서 계속확인해야할까?
Grid Search 를 이용한 하이퍼파라미터 튜닝 자동화
- 가장 좋은 성능을 내는 최적의 하이퍼파라미터를 찾는 방법이다.
- 하이퍼파라미터 후보들은 모든 조합을 테스트해 모델 성능을 가장 좋게 만드는 값을 찾는다.
<종류>
(Grid Search 방식 / Random Search 방식)
1. Grid Search 방식
-
sklearn.model_selection.GridSearchCV 사용
-
시도해볼 하이퍼파라미터들을 지정하면 모든 조합에 대해 교차검증 후 제일 좋은 성능을 내는 조합을 찾아준다.
-
적은 조합의 경우는 괜찮지만 시도할 하이퍼파라미터와 값들이 너무 많아지면 시간이 많이 걸린다.
-
GridSearch 매개변수 결과조회
- Initializer 매개변수
- estimator: 모델객체 지정
- params : 하이퍼파라미터 목록(후보)을 dictionary로 전달
- scoring: 평가 지표
=> 생략시 분류는 accuracy, 회귀는 𝑅2를 기본 평가지표로 설정 - refit: best parameter를 정할 때 사용할 평가지표
=> scoring에 여러개의 평가지표를 설정한 경우 refit을 반드시 설정 - cv: 교차검증시 fold 개수
- n_jobs: 사용할 CPU 코어 개수 (None:1(기본값), -1: 모든 코어 다 사용)
-
메소드
- fit(X, y): 학습
- predict(X): 제일 좋은 성능을 낸 하이퍼파라미터 조합으로 재학습(refit)한 모델로 predict()
- predict_proba(X): 분류문제에서 class별 확률을 반환
=> 제일 좋은 성능을 낸 하이퍼파라미터 조합으로 재학습(refit)한 모델로 predict_proba() 호출
-
결과조회
- fit() 후에 호출
- cvresults: 파라미터 조합별 평가 결과를 Dictionary로 반환
- bestparams: 가장 좋은 성능을 낸 parameter 조합을 반환
- bestestimator: 가장 좋은 성능을 낸 모델을 반환
- bestscore: 가장 좋은 점수 반환
-
그럼 이제 예시를 통해서 확인해보자!
테스트셋은 위에서 사용한 테스트셋을 사용한다.
from sklearn.model_selection import GridSearchCV ##Gridsearch 자동화 시 전부테스트할때 사용
from sklearn.tree import DecisionTreeClassifier # 테스트모델은 DecisionTree모델을 사용
# 모델생성
tree = DecisionTreeClassifier(random_state=0)
# 파라미터 후보 딕셔너리
# key: 파라미터이름, value: 후보 리스트
params = {
"max_depth":[1,2,3,4,5], # range(1,6)도 가능
"max_leaf_nodes":[3,4,5,6,7,8,9,10]
}
# 5 * 8
gs = GridSearchCV(tree, # 하이퍼파라미터를 찾을 대상 모델객체
params, # 하이퍼파라미터 후보 딕셔너리
scoring="accuracy", # 평가지표(분류: accuracy가 기본.)
cv=4, # cross validation의 fold 개수.
n_jobs=-1 # 사용할 cpu개수. -1: 다사용.
)# 하이퍼파라미터 찾기(자동화모델에 학습)
gs.fit(X_train, y_train)
=> search안에 DecisionTree 객체를 넣어서 최적의 하이퍼파라미를 찾는데 이때 하이퍼파라미터를 찾기위한 분리된 데이터셋을 넣어 학습시킨다.
## 결과 조회
### 가장 성능 좋은 조합의 하이퍼파라미터가 무엇인지 알려준다.
gs.best_params_
# 결과
{'max_depth': 2, 'max_leaf_nodes': 4}
### best_params_ 모델의 평가점수가 얼마가 나왔는지
gs.best_score_
#결과
0.9248809733733028
# best_params_로 재학습시킨 모델
best_model = gs.best_estimator_
best_model
=> 이렇게 GridSerch로 성능이 가장좋은 파라미터를 찾아 찾은 최적의파라미터로 재학습하기 위해 best_model에 저장한다.
그럼 최적의 모델을 제대로 찾은게 맞는지 확인해 보자.
from sklearn.metrics import accuracy_score
### best model 로 최종 평가
pred_test = best_model.predict(X_test)
accuracy_score(y_test, pred_test)
# 결과
0.8881118881118881
테스트모델로 검증한 결과와 학습시켰던 자동화객체에 testset을 넣고 테스트한 결과를 비교해본다.
pred_test2 = gs.predict(X_test)
accuracy_score(y_test, pred_test2)
# 결과
0.8881118881118881<결론>
동일한 결과가 나온것을 확인할 수 있고 최적의 파라미터를 잘찾은 것을 알 수 있다.
- Random Search 방식
-
klearn.model_selection.RandomizedSearchCV 사용
-
GridSeach와 동일한 방식으로 사용
-
단, 모든 조합을 테스트하지않고 랜덤하게 몇개의 조합을 선택하여 테스트한다.
-
Initializer 매개변수
- estimator: 모델객체 지정
- param_distributions: 하이퍼파라미터 목록을 dictionary로 전달 '파라미터명':[파라미터값 list] 형식
- n_iter: 전체 조합중 몇개의 조합을 테스트 할지 개수 설정
- scoring: 평가 지표
- refit: best parameter를 정할 때 사용할 평가지표. Scoring에 여러개의 평가지표를 설정할 시 필수.
- cv: 교차검증시 fold 개수.
- n_jobs: 사용할 CPU 코어 개수 (None:1(기본값), -1: 모든 코어 다 사용)
-
메소드
- fit(X, y): 학습
- predict(X): 제일 좋은 성능을 낸 모델로 추론한다. (값을 반환)
- predict_proba(X): 분류문제에서 class별 확률을 반환 => 제일 좋은 성능을 낸 모델로로 추론
-
결과 조회 속성
- fit() 후에 호출
- cvresults: 파라미터 조합별 평가 결과를 Dictionary로 반환
- bestparams: 가장 좋은 성능을 낸 parameter 조합을 반환
- bestestimator: 가장 좋은 성능을 낸 모델을 반환
- bestscore: 가장 좋은 점수 반환
-
예제로 확실하게 알아보자!
from sklearn.model_selection import RandomizedSearchCV
import numpy as np
tree3 = DecisionTreeClassifier(random_state=0)
params3 = {
"max_depth":range(1, 6),
"max_leaf_nodes":range(3, 31),
"max_features":np.arange(0.1, 1.1, 0.1) # 학습시 사용할 컬럼의 비율
}
rs = RandomizedSearchCV(tree3, # 모델
params3, # 하이퍼파라밑터 후보
n_iter=60, # 테스트해볼 조합의 개수.
scoring="accuracy",
cv=4,
n_jobs=-1
)
rs.fit(X_train, y_train) # 찾기
print("best score:", rs.best_score_)
print("best parameter:", rs.best_params_)
# 결과
best score: 0.9530285663904072
best parameter: {'max_leaf_nodes': 25, 'max_features': 0.4, 'max_depth': 5}- 여기서 나아가 찾은 최적의 하이퍼파라미터에서 그근처의 값들을 이용하여 더욱세분화해서 더 좋은 파라미터를 찾아보자.
# RandomizedSearch에 찾은 하이퍼파라미터를 기준으로 그 근처의 값들을 좀더 세분화해서 찾는다.
# 세분화해서 찾기.
params4 = {
"max_leaf_nodes":[24, 25, 26, 17, 28],
"max_depth":[2, 3, 4],
"max_features":[0.2, 0.3, 0.4, 0.5, 0.6] # 학습시 지정한 비율의 feature만 사용.
}
gs4 = GridSearchCV(DecisionTreeClassifier(random_state=0),
params4,
scoring='accuracy',
cv=4,
n_jobs=-1)
gs4.fit(X_train, y_train)
### 결과 확인
print(gs4.best_score_)
print(gs4.best_params_)
# 결과
0.9553650149885382
{'max_depth': 3, 'max_features': 0.4, 'max_leaf_nodes': 24}
# 재학습
bm = gs4.best_estimator_
pred_test = bm.predict(X_test)
accuracy_score(y_test, pred_test)
# 결과
0.9230769230769231파이프라인 (Pipeline)
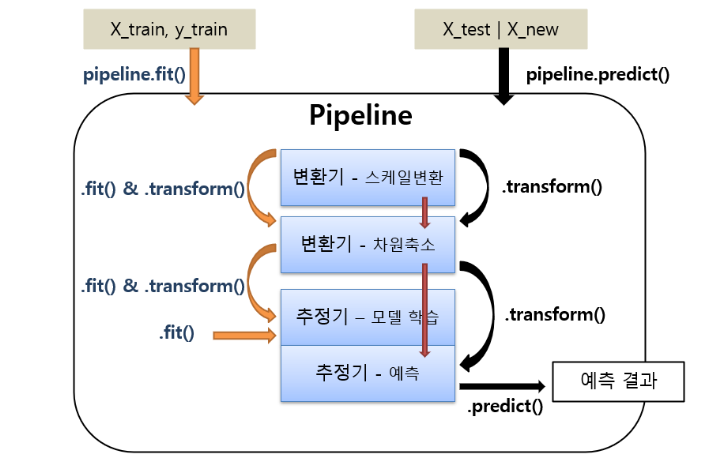
- 여러 단계의 머신러닝 프로세스(전처리단계, 모델생성, 학습)처리 과정을 설정하여 한번에 처리되도록 한다.
- 파이프라인은 여러개의 변환기와 마지막에 변환기 또는 추정기를 넣을 수 있다.
<파이프라인 종류>
- 전처리 작업을 하는 파이프라인
- 변환기들로만 구성된다.
- 전체 프로세스 파이프 라인
- 마지막에 추정기를 넣는다.
!여기서 잠깐!
변환기가 뭐고 추정기가 뭔데??
변환기(Estimator): 데이터를 학습하고 머신러닝 알고리즘(모델)들을 구현한 클래스이다.
fit(), predict()
추정기(Transformer): 데이터를 전처리하는 클래스들로 데이터셋의 값을 변환한다.
fit(), transform() fit_transform()
다시이어서 파이프라인으로 ~
- pipeline 생성
- (이름, 변환기)를 리스트로 묶어서 전달
- 마지막에는 추정기가 올 수 있다.
- pipeline을 이용한 학습
- pipeline.fit()
- 변환기의 순서대로 fit_transform()이 실행된 후 결과가 다음 단계로 전달되는데 마지막단계에서는 fit()만 호출하면 된다. (마지막이 추정기 일때 사용)
- pipeline.fit_transform()
- fit()과 동일하나 마지막 단계에서도 fit_transform()이 실행된다.
- 전처리 작업 파이프라인(모든단계가 변환기)일때 사용
- 마지막이 추정기일 경우
- predict(X), predict_proba(X)
- 추정기를 이용해서 X에 대한 결과를 추론
- 모델 앞에 있는 변환기들을 이용해서 transform() 그 처리결과를 다음 단계로 전달
- pipeline.fit()
이건 예제를 봐야 이해가 확실이 되겠다.
빨리 예제를 보자.
from sklearn.datasets import load_breast_cancer # 데이터 셋 로드
from sklearn.model_selection import train_test_split, GridSearchCV # 테스트셋을 나누기, 시도해볼 하이퍼파라미터 전체시도
from sklearn.preprocessing import StandardScaler # 전처리
from sklearn.svm import SVC # 모델선정
from sklearn.pipeline import Pipeline # 파이프라인
# 1. 데이터 로드
X, y = load_breast_cancer(return_X_y=True) # 데이터와 레이블을 한번에 X,y에 할당하는 부분
# 2. 데이터셋 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
# 3. 파이프라인 정의
# 리스트로 작성(이름, 생성할 객체)
steps = [
("scaler", StandardScaler()), # 첫번째 프로세스 (전처리)
("svm", SVC(random_state=0)) # 두번째 프로세스 (사용모델)
]
# 파이프라인 생성
pl = Pipeline(steps, verbose=True) # 리스트를 대입
# verbose=True는 작업의 진행 상황을 자세하게 출력하고, verbose=False는 출력하지 않는다는 것을 의미
# verbose: 실행 로그(기록)을 출력 => 어떤 단계를 실행하고 있는지, 실행에 걸린 시간 등을 출력
# 파이프라인에 넣어서 모델생성 및 학습
pl.fit(X_train, y_train)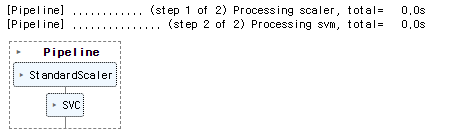
# 추론
pred_train = pl.predict(X_train) # 여기서는 학습한것을 기반으로 변환해서 predict한다.
pred_test = pl.predict(X_test)
# 평가
from sklearn.metrics import accuracy_score # 평가지표
accuracy_score(y_train, pred_train), accuracy_score(y_test, pred_test)
# 결과
(0.9929577464788732, 0.958041958041958)-
GridSearch에서 Pipeline사용
- Grid안에 pipeline을 넣으면 된다.
- 하이퍼파라미터 지정시 파이프라인 프로세스이름__하이퍼파라미터 형식으로 저장한다.
<순서>
- Pipeline 생성
- GridSearchCV의 estimator에 pipline 등록
여기에서 PCA를 사용하는데 그 이유는?
PCA를 Pipeline에 포함시키는 이유는 데이터의 차원을 축소하여 모델의 복잡성을 줄이고 예측 성능을 향상시키기 위해서이며, Pipeline은 데이터 전처리와 모델 학습을 효율적으로 처리하고 모델 튜닝을 수행하는 데 도움을 주기때문이다.
from sklearn.decomposition import PCA #차원 축소 -> feature를 줄여준다.
pca = PCA(n_components=2) # feature를 몇개로 줄일지 -> feature extraction
# train을 학습 및 변환하여 차원축소해서 저장
X_trained_pca = pca.fit_transform(X_train)
X_trained_pca.shape
# 결과
(426, 2) # 2개로 Feature이 축소된것을 확인할 수 있다.한번 시각화하여 데이터들이 어떻게 분포되어있는지 확인해 보자. (산점도 사용)
import matplotlib.pyplot as plt
plt.scatter(X_trained_pca[:, 0], X_trained_pca[:, 1], alpha=0.2)
plt.show()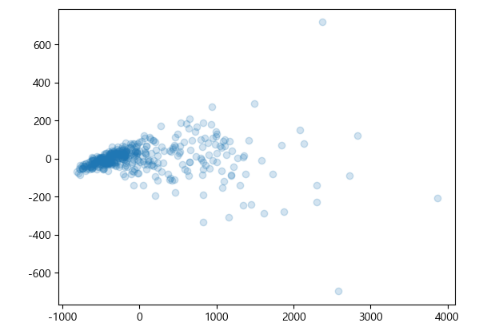
GridSearh에 넣기 전에 데이터셋의 차원을 PCA를 통해 축소하였으니 이제 파이프라인을 생성하자.
# 1. 파이프라인 생성
steps = [
("scaler", StandardScaler()), # 전처리
("pca", PCA()), # 전처리(차원축소)
("svm", SVC(random_state=0)) # 모델링
]
pl2 = Pipeline(steps, verbose=True)# 2. GridSearchCV생성
# key: 하이퍼파라미터 이름 (파이프라인에등록한이름__하이퍼파라미터이름)
# value: 후보-리스트
params = {
"pca__n_components":[5, 10, 15, 20, 25],
"svm__C":[0.001, 0.01, 0.1, 0.5, 1],
"svm__gamma":[0.001, 0.01, 0.1, 0.5, 1]
}
gs = GridSearchCV(pl2, # pipeline
params,
scoring='accuracy',
cv=4,
n_jobs=-1
)
gs.fit(X_train, y_train)
# 최적의 하이퍼파라미터 확인
gs.best_params_
# 결과
{'pca__n_components': 5, 'svm__C': 1, 'svm__gamma': 0.1}
# 최적의 하이퍼파라미터의 accuracy
gs.best_score_
# 결과
0.9765914300828777
# 가장좋은 것으로 재학습
best_model = gs.best_estimator_
# 해당 모델로 다시 학습 및 추론
pred_test = best_model.predict(X_test)
accuracy_score(y_test, pred_test)
# 결과
0.9440559440559441지금까지는 데이터셋의 컬럼들이 모두 같은 전처리를 사용했다. 그런데 항상 같은 전처리를 사용하지 않을때도 있다.
그럼 데이터셋의 컬럼들마다 다른 전처리를 해야 하는 경우에는 어떻게 해야할까?
바로
ColumnTransformer를 사용한다.
ColumnTransformer
-
데이터셋의 컬럼들(Feature)마다 다른 전처리를 해야하는 경우 사용한다.
-
연속형 feature => Feature scaling을 범주형은 one hot encoding이나 labelencoding을 해야한다.
-
하나의 데이터셋을 구성하는 feature(커럼들)에 대해 서로 다른 전처리 방법이 필요할 때 개별적으로 나눠서 처리하는 것은 좋지않다.
- 번거롭다.
- 전처리방식을 저장할 수 없다.
- Pipeline을 구성하여 한번에 처리할 수 없다.
=> 그런데 ColumnTransformer를 사용하면 feature별로 어떤 전처리를 할지 정의할 수 있다.
-
sklearn.compose.ColumnTransformer 이용
- 매개변수
- transformer: list of tuple - (name, transformer, columns)로 구성된 tuple들을 리스트로 묶어 전달
- remainder='drop' : 지정한지 않은 컬럼을 어떻게 처리할지 여부
=> drop"(기본값): 제거한다.
=> passthrough: 남겨둔다.
- 매개변수
-
sklearn.compose.make_column_transformer 이용
- ColumnTransformer를 쉽게 생성할 수 있도록 도와주는 utility 함수
- 매개변수
- transformer: 가변인자. (transformer, columns 리스트)로 구성된 tuple을 전달
- remainder='drop' : 지정한지 않은 컬럼을 어떻게 처리할지 여부
=>"drop"(기본값): 제거한다.
=> "passthrough": 남겨둔다. - 반환값: ColumnTransformer
예제를 통해 이해하기!
아래는 실습을 위한 데이터 프레임 생성과정이다.
1. 데이터 프레임 생성
import pandas as pd
import numpy as np
df = pd.DataFrame({
"gender":['남성', '여성', '여성', '여성', '여성', '여성', '남성', np.nan], # 범주형
"blood_type":["B", "B", "O", "AB", "B", np.nan, "B", "A"], # 범주형
"tall":[183.21, 175.73, np.nan, np.nan, 171.18, 181.11, 168.83, 193.99], # 연속형
"weight":[82.11, 62.45, 52.21, np.nan, 56.32, 48.93, 63.64, 102.38] # 연속형
}) # 4개의 컬럼을 줌
df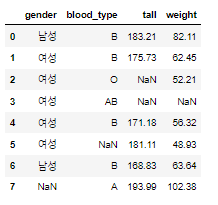
- 결측치 처리 + 학습 +변환
# 서로다른 전처리 쉽게할 수 있도록 , ColumnTransformer를 쉽게 생성할 수 있도록 도와주는 것.
from sklearn.compose import ColumnTransformer, make_column_transformer
from sklearn.impute import SimpleImputer # 결측치 처리
from sklearn.preprocessing import OneHotEncoder, StandardScaler # 범주형전처리, 연속형전처리
from sklearn.pipeline import Pipeline # 파이프라인
# 결측치 처리 - 범주형: 최빈값, 연속형: 평균
imputer_tf = ColumnTransformer([
("category_imputer", SimpleImputer(strategy="most_frequent"), ["gender", "blood_type"]),
("continuous_imputer", SimpleImputer(strategy="mean"), ["tall", "weight"])
],)
# 학습
imputer_tf.fit(df)
# 변환 된 feature의 이름.
imputer_tf.get_feature_names_out()
# 결과
array(['category_imputer__gender', 'category_imputer__blood_type',
'continuous_imputer__tall', 'continuous_imputer__weight'],
dtype=object)
# 변환
result = imputer_tf.transform(df)
result
# 결과
array([['남성', 'B', 183.21, 82.11],
['여성', 'B', 175.73, 62.45],
['여성', 'O', 179.00833333333335, 52.21],
['여성', 'AB', 179.00833333333335, 66.86285714285714],
['여성', 'B', 171.18, 56.32],
['여성', 'B', 181.11, 48.93],
['남성', 'B', 168.83, 63.64],
['여성', 'A', 193.99, 102.38]], dtype=object)- 전처리
# 번주형-원핫인코딩, 연속형-standardScaling
preprocess_tf = ColumnTransformer([
("ohe", OneHotEncoder(), [0,1]),
('scaler', StandardScaler(), [2,3]) # ndarray의 경우 feature index번호로
], remainder='passthrough')
# remainder='passthrough': 변환기가 적용되지 않은 열을 그대로 유지할 수 있다.
# 여기 코드에서는 모든 열ㅇ르 적용했지때문에 지워도 달라지는 것은 없다.
# 학습
preprocess_tf.fit(result) # 결측치처리한 겂 넣기
preprocess_tf.get_feature_names_out()
# 결과
array(['ohe__x0_남성', 'ohe__x0_여성', 'ohe__x1_A', 'ohe__x1_AB', 'ohe__x1_B',
'ohe__x1_O', 'scaler__x2', 'scaler__x3'], dtype=object)
# 변환
result2 = preprocess_tf.transform(result)
result2
# 결과
array([[ 1. , 0. , 0. , 0. , 1. ,
0. , 0.57840648, 0.92550488],
[ 0. , 1. , 0. , 0. , 1. ,
0. , -0.4512993 , -0.26786139],
[ 0. , 1. , 0. , 0. , 0. ,
1. , 0. , -0.88943161],
[ 0. , 1. , 0. , 1. , 0. ,
0. , 0. , 0. ],
[ 0. , 1. , 0. , 0. , 1. ,
0. , -1.07765777, -0.63995372],
[ 0. , 1. , 0. , 0. , 1. ,
0. , 0.28931796, -1.08852832],
[ 1. , 0. , 0. , 0. , 1. ,
0. , -1.40116159, -0.19562813],
[ 0. , 1. , 1. , 0. , 0. ,
0. , 2.06239422, 2.15589828]])
- pipeline 생성
# 파이프라인 으로 묶기
preprocess_pipeline = Pipeline([
("imputer", imputer_tf),
("preprocess", preprocess_tf)
])
preprocess_pipeline.fit_transform(df)
# 결과
array([[ 1. , 0. , 0. , 0. , 1. ,
0. , 0.57840648, 0.92550488],
[ 0. , 1. , 0. , 0. , 1. ,
0. , -0.4512993 , -0.26786139],
[ 0. , 1. , 0. , 0. , 0. ,
1. , 0. , -0.88943161],
[ 0. , 1. , 0. , 1. , 0. ,
0. , 0. , 0. ],
[ 0. , 1. , 0. , 0. , 1. ,
0. , -1.07765777, -0.63995372],
[ 0. , 1. , 0. , 0. , 1. ,
0. , 0.28931796, -1.08852832],
[ 1. , 0. , 0. , 0. , 1. ,
0. , -1.40116159, -0.19562813],
[ 0. , 1. , 1. , 0. , 0. ,
0. , 2.06239422, 2.15589828]])- GridSearch적용
####### GridSearch적용
from sklearn.tree import DecisionTreeClassifier # 모델선정
from sklearn.model_selection import GridSearchCV # 가장좋은 하이퍼파라미터 찾기
# 연속형 파이프라인 생성
num_preprocess = Pipeline([
("imputer", SimpleImputer()), ########## mean, median 적용
("scaler", StandardScaler())
])
# 범주형 파이프라인 생성
cate_preprocess = Pipeline([
("imputer", SimpleImputer(strategy="most_frequent")),
("ohe", OneHotEncoder(handle_unknown="ignore"))
])
# 연속형과 범주형 묶기
preprocessor = ColumnTransformer([
("categorical", cate_preprocess, ['gender', "blood_type"]),
("continuous", num_preprocess, ['tall', 'weight']),
])
# 묶은 것을 포함하여 적용할 모델과 새로운 파이프라인 생성
pl = Pipeline([
('preprocess', preprocessor),
('model', DecisionTreeClassifier(random_state=0))
])
# => 4번에서 한 과정이지만 보통 범주형, 연속형으로 나눠 pipeline을 생성 후 ColumnTransformer로 묶어주는 전략을 많이 쓴다.
# GridSearch 파라미터 후보 딕셔너리
# key: 파라미터이름, value: 후보 리스트
param = {
"preprocess__continuous__imputer__strategy":["mean", "median"],
"model__max_depth":range(2, 5)
}
y = [1, 0, 0, 0, 1, 1, 1, 0] # 가상의 데이터
# GridSearchCV객체 생성
gs = GridSearchCV(pl, param, scoring='accuracy', cv=3, verbose=True)
# 헉습
gs.fit(df, y)
# 추론
gs.predict(df)
# 결과
array([1, 1, 0, 0, 1, 1, 1, 0])
# 남성과 Nan이였던 부분은 0으로 여성은 1로 표현된것을 알 수 있다.