Ensemble
지난 포스팅에서 Ensemble의 정의에 대하여 설명하였지만 다시한번 말하고 가면 이해에 도움이 될까 싶어 간단히 말하고 넘어가겠다.
- Ensemble
- 모델들이 있고 각자 학습하고 추론해서 취합할때만 합친다. -> 병렬처리가 가능하다.
Ensemble의 종류로는 투표방식과 Boosting방식이 있는데 이중 투표방식에는 Bagging과 Voting이 있다.
Bagging은 같은 유형의 알고리즘들을 조합하되 각각 학습하는 데이터는 다르게 하였다.
반면
이번에 할 Voting은 서로다른 종류의 알고리즘들을 결합한것이다.
Ensemble - Boosting Model
Boosting
- 단순하고 약한 학습기(Weak Learner)들을 결합해서 보다 정확하고 강력한 학습기(Strong Learner)를 만드는 방식.
- 쉽게 말하면 앞에 있는 애들이 못찾으면 뒤에서 찾는다.
- 즉, 약한 학습기들은 앞 학습기가 만든 오류를 줄이는 방향으로 학습한다.
Boosting의 종류에는 Boosting에서 사용할 수 있는 모델 중 하나로 GradientBoosting 모델이 있다.
-
GradientBoosting
- 개별 모델로 Decision Tree를 사용한다.
- depth가 깊지 않은 트리를 사용한다. → 이러한 트리들끼리 연결해서 이전 트리의 오차를 보정해 나가는 방식
- 앞 모델이 틀린 오차를 학습하여 전체 오차를 줄이도록 학습
- 트리들이 모여 전체 성능을 높이는 것이 기본 아이디어
- 분류와 회귀 둘다 지원하는 모델 (GradientBoostingClassifier, GrandientBoostingRegressor)
- 트리기반 모델의 특성상 희소한 고차원 데이터에서는 성능이 안 좋은 단점
- 평균추정 → 각데이터의 오차(잔차)를 구한다. → 첫번째 모델은 평균+ 0.1 X 오차 → 두번째 모델은 x값을 바탕으로 첫번째모델을 통해 나온 오차를 이용한다. (평균 + 0.1 X 오차)
-
학습 후 새로운 데이터 예측
- 생성된 트리모델들을 거치면서 마지막에 출력된 결과가 예측 값이 된다.
-
주요 파라미터
- Boosting Model모델의 트리 구성 시 각각의 decision tree가 복잡한 모델이 되지 않도록 한다.
- learning rate
- 너무 크면 보정이 강하여 복잡한 모델을 만들어 과대적합가능성 있다.
- 값이 너무 작으면 보정이 약해서 모델의 복잡도를 줄인다. 성능자체는 낮아질 수 있다.
- n_estimators
- dicision tree의 개수를 지정한다.
- 많을 수록 복잡한 모델이 된다.
- n_iter_no_change, validation_fraction
- validation_fraction에 지정한 비율만큼 n_iter_no_change에 지정한 반복 횟수동안 검증점수가 좋아 지지 않으면 훈련을 조기 종료
- 보통 max_depth를 낮춰 decision tree의 복잡도를 낮춰서 5가 넘지 않도록 보통은 2~3정도로 설정한다. 그리고 n_estimators를 학습할때 사용할 가용시간, 메모리 한도를 맞춰서 크게 설정하여 적절한 learning_rate을 찾는다.
<예제를 통해 살펴보자!>
from dataset import get_breast_cancer_dataset
(X_train, X_test, y_train, y_test), feature_names = get_breast_cancer_dataset()
X_train.shape, X_test.shape((426, 30), (143, 30))
from sklearn.ensemble import GradientBoostingClassifier # 앙상블- 분류 -> 추론해나가자
gbc = GradientBoostingClassifier(random_state=0)
gbc.fit(X_train, y_train)
pred_train = gbc.predict(X_train)
pred_test = gbc.predict(X_test)
proba_train = gbc.predict_proba(X_train) # 확률로 추론했다.
proba_test = gbc.predict_proba(X_test)
from metrics import print_metrics_classification
print_metrics_classification(y_train, pred_train, proba_train[:, 1], "Trainset")
print_metrics_classification(y_test, pred_test, proba_test[:, 1], "Testset")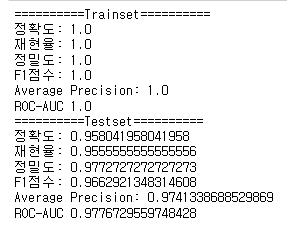
import pandas as pd
fi = pd.Series(gbc.feature_importances_, index=feature_names)
fi.sort_values(ascending=False)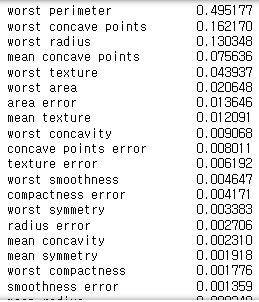
learning rate 변화에 따른 성능변화
import time
max_depth = 1
n_estimators = 10000
lr = 0.0001
# lr = 0.01
# lr = 0.1
gbc2 = GradientBoostingClassifier(n_estimators=n_estimators,
learning_rate=lr,
max_depth=max_depth,
random_state=0)
s = time.time()
gbc2.fit(X_train, y_train)
e = time.time()
pred_train2 = gbc2.predict(X_train)
pred_test2 = gbc2.predict(X_test)
print(f"lr: {lr}, n_estimator: {n_estimators}, 학습시간:{e-s}초")
print_metrics_classification(y_train, pred_train2, title="Trainset")
print_metrics_classification(y_test, pred_test2, title="Test set")
GradientBoosting기반으로 Gradient Boost의 단점인 느린수행시간을 해결하고 과적합을 제어할 수 있는 규제들을 제공하여 성능을 높여 분산환경에서도 실행할 수 있도록 구현 나온 모델로 XGBoost(Extra Gradient Boost)가 있다.
-
XGBoost (Extream Gradient Boost)
- 극단적인 모델이다.
- 속도가 느리다. -> → XGBoost도 느리긴하지만 Gradient Boost보다는 났다.
- Scikit-learn에는 없고 독립적인 XGboost 모듈을 쓴다. -> 설치가 필요하다.
- 설치방법
=> 앞에 !를 붙이면 쥬피터에서 명령프롬프트를 쓴다는 것.
!pip install xgboost
튜피터 터미널 or 일반터미널에서는
pip install xgboost
- 설치방법
-
XGBoost을 사용한 두가지 개발 방법
둘중 래퍼 XGBoost에 대하여 살펴보겠다.
- Scikit-learn 래퍼 XGBoost
- XGBoost를 Scikit-learn프레임워크와 연동할 수 있도록 개발됨.
- Scikit-learn의 Estimator들과 동일한 패턴으로 코드를 작성가능
- GridSearchCV나 Pipeline 등 Scikit-learn이 제공하는 다양한 유틸리티들을 사용할 수 있다.
- XGBClassifier: 분류
- XGBRegressor : 회귀
- 주요 매개변수
- learning_rate : 학습률, 보통 0.01 ~ 0.2 사이의 값 사용
- n_estimators : week tree 개수
- Decision Tree관련 하이퍼파라미터들
<예제로 살펴보자!>
from xgboost import XGBClassifier, XGBRegressor
xgb = XGBClassifier(n_estimators=1000, learning_rate=0.01, max_depth=1, random_state=0)
xgb.fit(X_train, y_train)
feature importance
fi = pd.Series(xgb.feature_importances_, index=feature_names)
fi.sort_values(ascending=False
print_metrics_classification(y_train, xgb.predict(X_train), title="train set")
print_metrics_classification(y_test, xgb.predict(X_test), title="test set")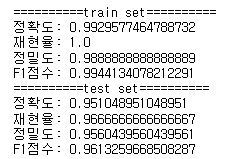
# 회귀
from dataset import get_boston_dataset
X_train, X_test, y_train, y_test = get_boston_dataset()
xgb_reg = XGBRegressor(n_estimators=1000, learning_rate=0.01,
max_depth=2, random_state=0)
xgb_reg.fit(X_train, y_train)
fi = pd.Series(xgb_reg.feature_importances_, index=X_train.columns)
fi.sort_values(ascending=False)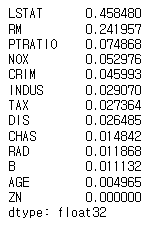
from metrics import print_metrics_regression
# 평가
print_metrics_regression(y_train, xgb_reg.predict(X_train), title="train set")
print_metrics_regression(y_test, xgb_reg.predict(X_test), title="test set")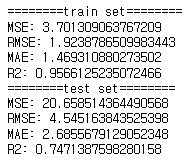
-
Ensemble - Voting 방식
- 또다른 방식의 투표방식(개별적으로 학습 및 추론하고 결합해서 결론내는 것.)
- 서로 다른 종류의 알고리즘들을 결합하여 다수결 방식으로 최종 결과를 출력한다.
-
Voting의 유형(분류)
-
비슷한 성능을 내면서 서로 다른 예측하는 것이 많은 모델들을 묶어줄 때 성능이 올라간다.
-
hard voting
- 다수의 추정기가 결정한 예측값들 중 많은 것을 선택한 방식
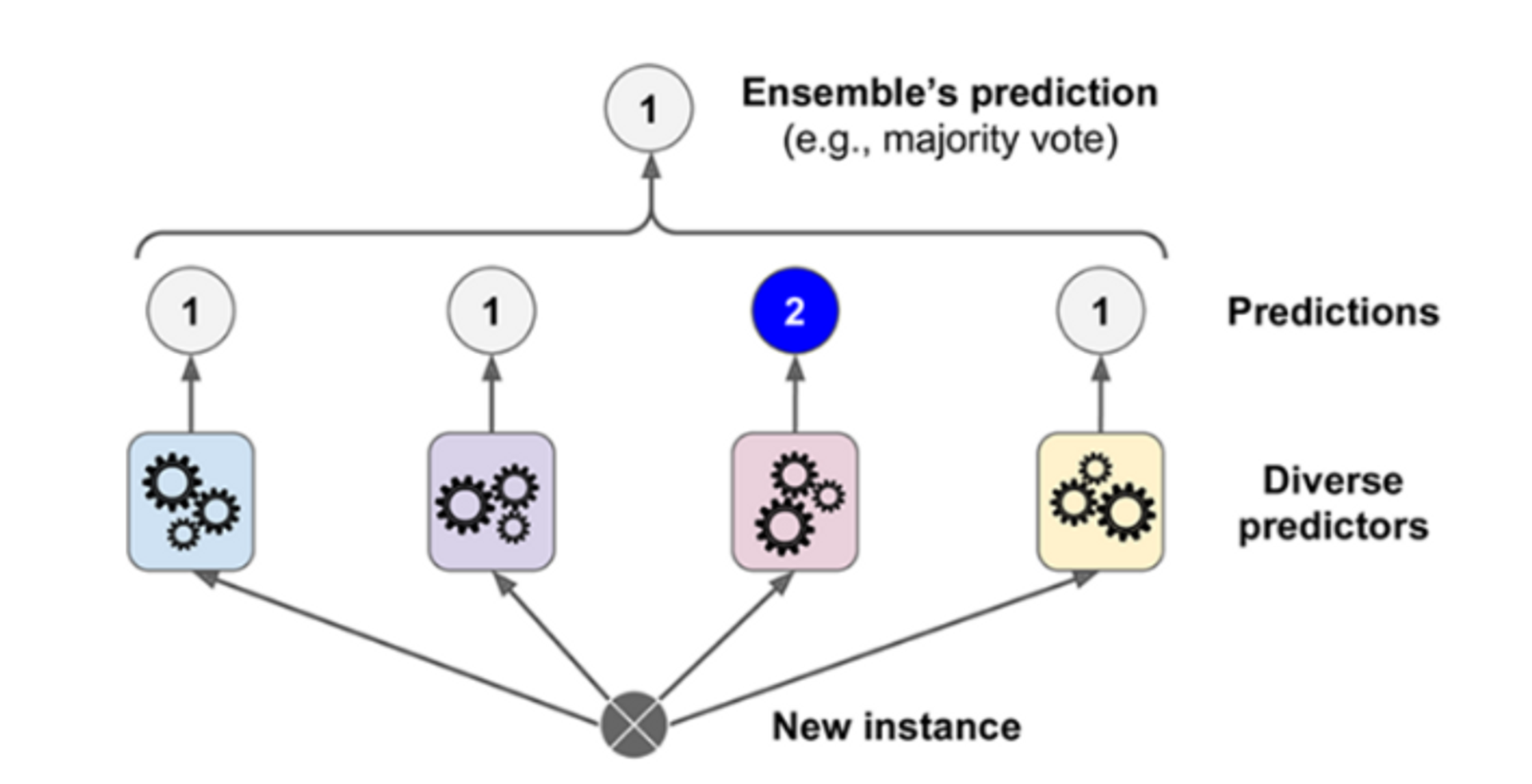
- 다수의 추정기가 결정한 예측값들 중 많은 것을 선택한 방식
-
soft voting → 더 성능이 좋다.
- 다수의 추정기에서 각 레이블별 예측한 확률들의 평균을 내서 높은 레이블의 값을 결과값으로 선택하는 방식
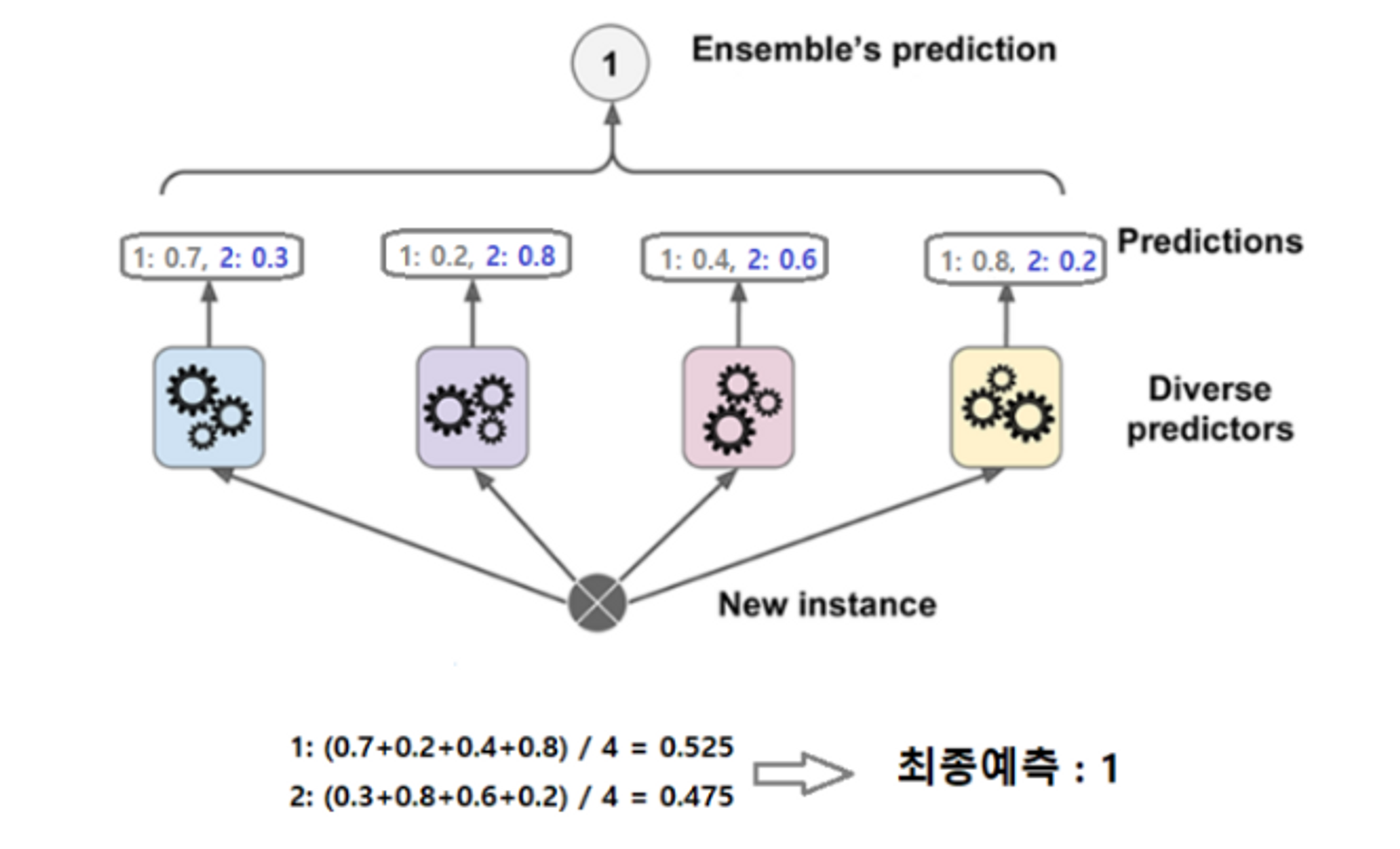
- 다수의 추정기에서 각 레이블별 예측한 확률들의 평균을 내서 높은 레이블의 값을 결과값으로 선택하는 방식
-
-
VotingClassifier 클래스 이용
- 학습 후 성능이 좋았던 모델들을 모아서 VotingClassifier 클래스는 다시한번 테스트하는 것이다. → 1번2,번모델에서는 틀리지만 3번모델에서는 잘나올 수 있기때문이다.
- 매개변수
- estimators : 앙상블할 모델들 설정. ("추정기이름", 추정기) 의 튜플을 리스트로 묶어서 전달
=> [("모델이름", 모델객체), ...] - voting: voting 방식.
=> "hard"(기본값), "soft" 지정
- estimators : 앙상블할 모델들 설정. ("추정기이름", 추정기) 의 튜플을 리스트로 묶어서 전달
<예제로 살펴보자!>
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from xgboost import XGBClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from dataset import get_breast_cancer_dataset
from metrics import print_metrics_classification
(X_train, X_test, y_train, y_test), feature_names = get_breast_cancer_dataset()
# 각 모델의 Hyper parameter는 최적의 성능을 내도록 튜닝한 값들 이라는 가정.
# Voting 앙상블 모델에 추가하는 모델들은 가장 좋은 성능을 내는 Hyper parameter를 가진
# (튜닝이기 끝난) 모델을 사용한다.
knn = Pipeline(steps=[('scaler', StandardScaler()),
('knn', KNeighborsClassifier(n_neighbors=5))])
svm = Pipeline(steps=[("scaler", StandardScaler()),
("svm", SVC(random_state=0, probability=True))])
rfc = RandomForestClassifier(n_estimators=200, max_depth=3, random_state=0)
xgb = XGBClassifier(n_estimators=500, learning_rate=0.01, max_depth=1, random_state=0)
model_list = [
("knn", knn),
("svm", svm),
("RandomForest", rfc),
("XGBoost", xgb)
]
# 모델이 test set에 대해 **추정한 결과를** 저장할 변수.
# 즉, 모델이 추정한 결과를 저장할 변수
test_predict_dict = {} # key: 모델이름, value: test set에 대한 추정한 label값.
for name, model in model_list:
model.fit(X_train, y_train)
pred_train = model.predict(X_train)
pred_test = model.predict(X_test)
test_predict_dict[name] = pred_test # test set 추정결과를 dic에 추가.
print_metrics_classification(y_train, pred_train, title=f"{name}-Train set")
print_metrics_classification(y_test, pred_test, title=f"{name}-Test set")
print()
# test set 기준 SVM이 성능이 제일 좋은 것을 알 수 있다.
각각의 모델들끼리 추론한 값들끼리의 상관관계를 보자.
# 테스트 결과가 있는 딕셔너리를 데이터프레임화한다.
import pandas as pd
df = pd.DataFrame(test_predict_dict)
df.head()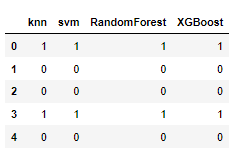
df.corr()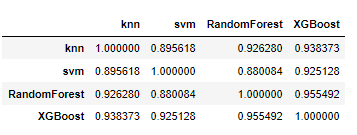
# Ordered Dictionary 형태로 묶어준다.
estimators = [
("svm", svm),
("knn", knn),
("random forest", rfc)
]
# hard voting # voting 방식 생략 시 hard voting하겠다는 것.
voting = VotingClassifier(estimators=estimators)
voting.fit(X_train, y_train)
print_metrics_classification(y_test, voting.predict(X_test), title='test set')
# 결과를 보면 성능이 올라가지않고 더 떨어진것을 볼 수 있다.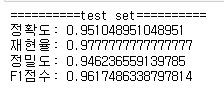
# soft voting- 확률로
voting = VotingClassifier(estimators=estimators, voting="soft")
voting.fit(X_train, y_train)
print_metrics_classification(y_test, voting.predict(X_test), title='test set')
# hard보다 성능이 좋게 나온다.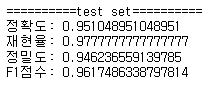
svm.predict_proba(X_test[:5])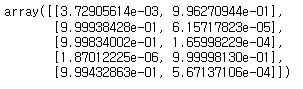
knn.predict_proba(X_test[:5])
rfc.predict_proba(X_test[:5])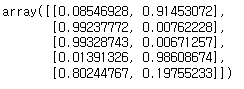
<voting하기 좋은 모델>
- 분류 모델들이 추정한 결과의 상관관계가 높은 모델을 Voting 방식 앙상블에 포함시키는 것은 바람직 하지 않다.
- 상관관계가 높다는 것은 두 모델이 비슷한 예측을 한다는 것이다. 같은 예측을 하는 모델들을 모아서 추론하는 것은 의미가 없다.
A B C
⇒ 예측한 label이 모두 동일하면 묶어서 테스트하는 의미가 없다.
⇒ 성능을 최대로 올린 모델들 끼리 서로 대답을 다르게 하는 것이 좋다.
즉, Voting방식(다수결 투표방식)의 앙상블은 각각 좋은 성능을 내지만 다른 예측을 하는 다양한 모델을 모아서 하는 것이 좋다. 대부분의 모델들이 동일한 예측을 만든다면 새로운 모델을 추가해 얻는 이득이 적기 때문이다.
다양하게 ex)
- 상관관계 분석

kim과 svm의 상관관계 / kim과 random 상관관계
- Voting의 유형(회귀)
- 각모델이 값을 추론하면 그 값들의 평균으로 최종 결과를 사용
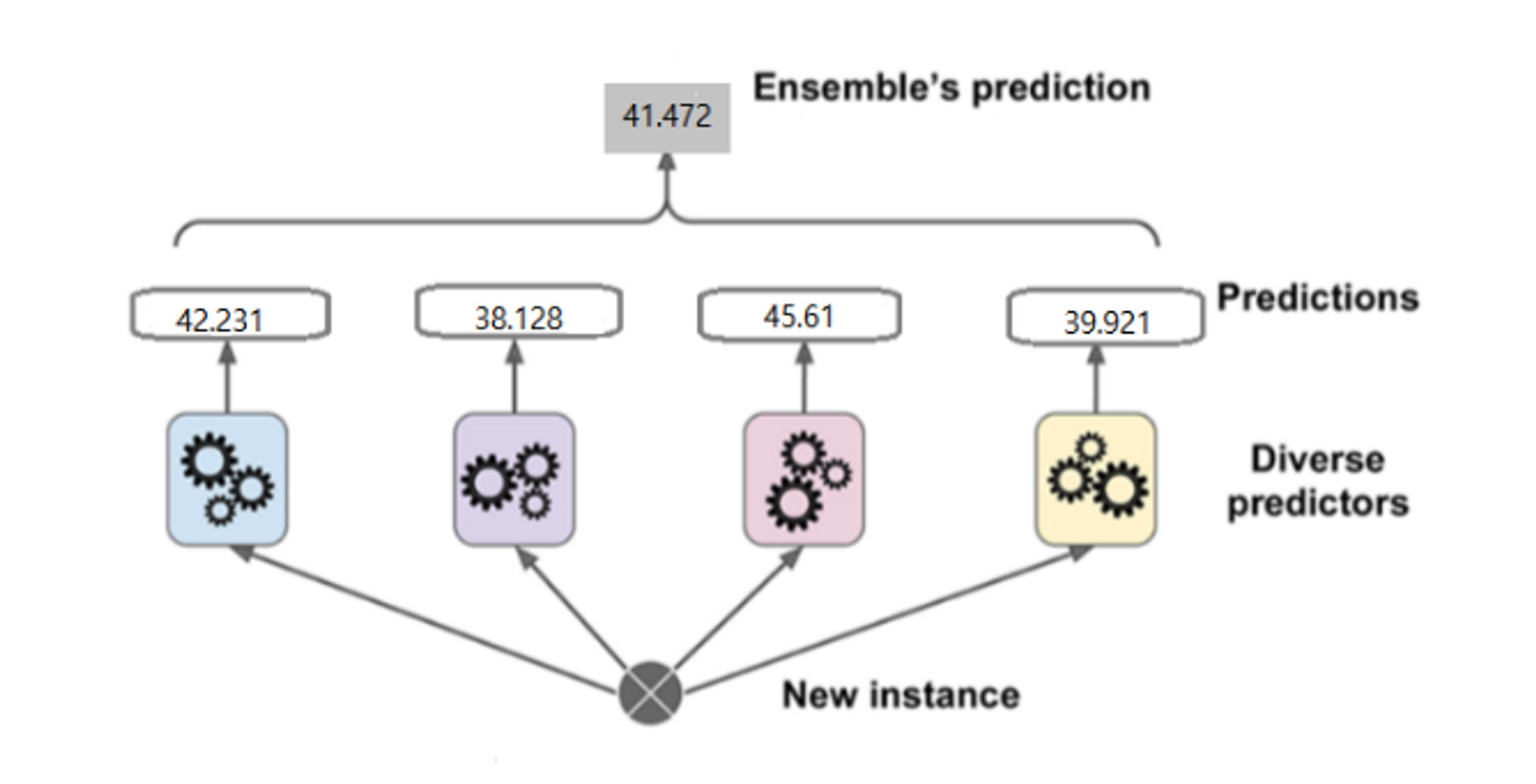
- 각모델이 값을 추론하면 그 값들의 평균으로 최종 결과를 사용
- VotingRegressor 클래스 이용
- 매개변수
- estimators : Ensemble할 모델들 설정. ("추정기이름", 추정기) 의 튜플을 리스트로 묶어서 전달
<예제로 살펴보자!>
from dataset import get_boston_dataset
X_train, X_test, y_train, y_test = get_boston_dataset()
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import VotingRegressor
from sklearn.pipeline import make_pipeline
lr = make_pipeline(StandardScaler(), LinearRegression()) # make_pipeline : 이름을 생략할 수 있다. 알아서 클래스의 이름을 따서 만듬.
rfr = RandomForestRegressor(max_depth=3, random_state=0)
knn = make_pipeline(StandardScaler(), KNeighborsRegressor(n_neighbors=5))
from metrics import print_metrics_regression
model_list = [
('Linear Regression', lr),
('Random Forest', rfr),
('KNN', knn)
]
for name, model in model_list:
model.fit(X_train, y_train)
pred_train = model.predict(X_train)
pred_test = model.predict(X_test)
print_metrics_regression(y_train, pred_train, f"{name} - trainset")
print_metrics_regression(y_test, pred_test, f"{name} - testset")
print()
# Random Forest의 오차가 가장 적은 것을 알 수 있다.
voting_reg = VotingRegressor(estimators=model_list)
# 재학습
voting_reg.fit(X_train, y_train)
print_metrics_regression(y_test, voting_reg.predict(X_test))
